










एक टिकाऊ डेटा मॉडल डिज़ाइन करने के लिए केवल एकता और संबंधों को मैप करने से अधिक आवश्यकता होती है। यह डेटा के समय के साथ कैसे विकसित होता है, इसकी समझ की आवश्यकता होती है। पारंपरिक एंटिटी रिलेशनशिप डायग्राम (ERD) में, हम अक्सर एक निश्चित समय पर एक रिकॉर्ड की स्थिति को दर्ज करते हैं। हम वेतन का वर्तमान मूल्य, उपयोगकर्ता की सक्रिय स्थिति या उत्पाद की नवीनतम कीमत को स्टोर करते हैं। हालांकि, व्यापार बुद्धिमत्ता और नियामक सुसंगतता के लिए अक्सर यह जानना आवश्यक होता है कि वर्तमान में क्या सच है, बल्कि अतीत में क्या सच था।
यहीं समय संबंधी डेटा मॉडलिंग बातचीत में आती है। यह एक स्थिर स्कीमा को एक गतिशील इतिहास ट्रैकर में बदल देती है। अपने ERD में सीधे समय के आयामों को एकीकृत करके, आप सुनिश्चित करते हैं कि प्रत्येक परिवर्तन को दस्तावेज़ित, लेखा-जोखा और प्रश्न करने योग्य रूप से रखा जाता है, बिना उन परिवर्तनों के समय के संदर्भ को खोए बिना। यह मार्गदर्शिका समय-संवेदनशील डेटाबेस प्रणालियों के निर्माण के लिए आवश्यक संरचनात्मक तकनीकों का अध्ययन करती है।
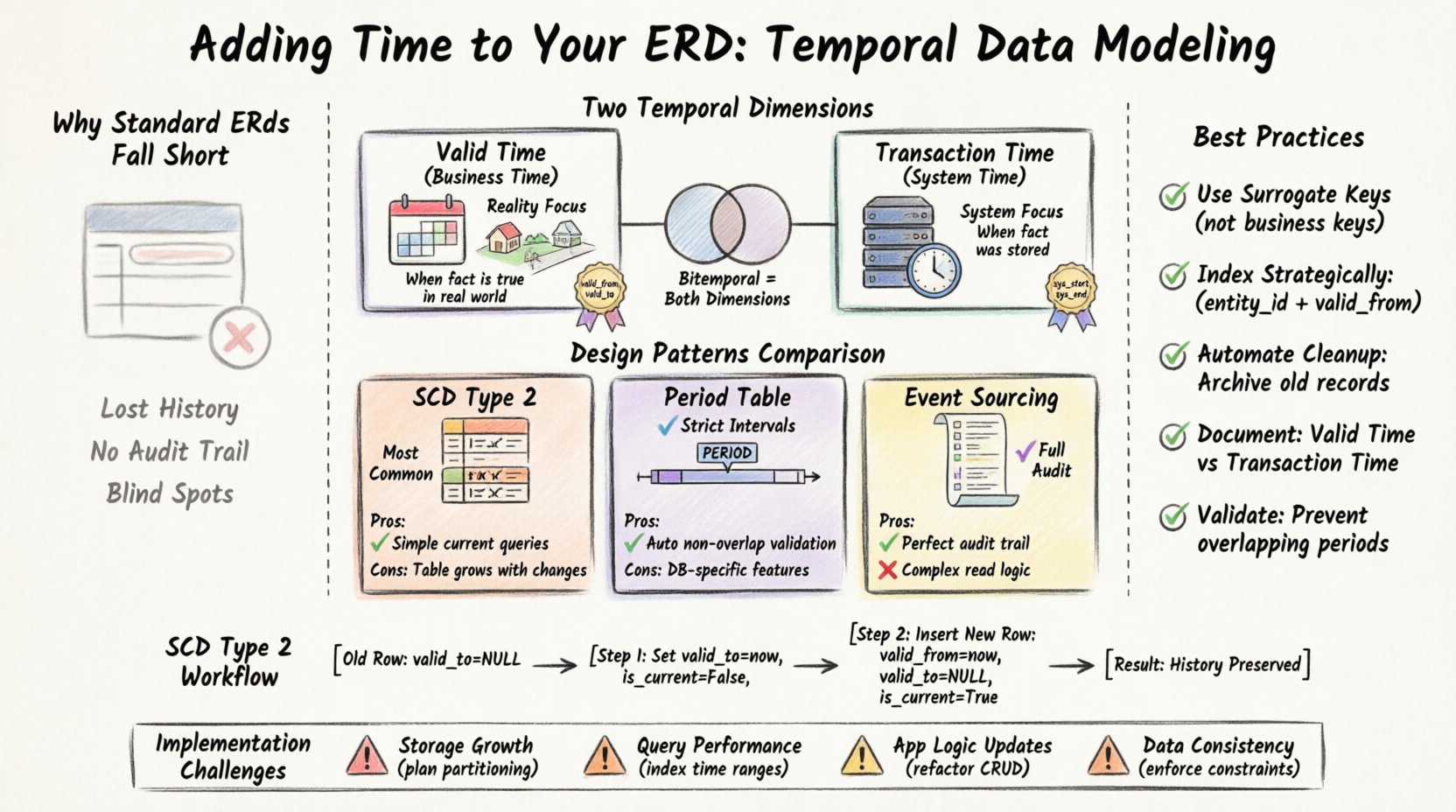
ऐतिहासिक डेटा के लिए मानक ERD क्यों अपर्याप्त हैं 📉
एक पारंपरिक ERD वर्तमान स्थिति पर ध्यान केंद्रित करता है। जब एक रिकॉर्ड को अपडेट किया जाता है, तो पुराना मान आमतौर पर ओवरराइट कर दिया जाता है। जब तक कि यह सरल ऑपरेशनल प्रणालियों के लिए काम करता है, यह विश्लेषणात्मक आवश्यकताओं के लिए महत्वपूर्ण अंधेरे बिंदु पैदा करता है। एक ऐसे परिदृश्य को ध्यान में रखें जहां आपको पिछले पांच वर्षों के लिए एक ग्राहक के बिलिंग इतिहास को पुनर्निर्मित करने की आवश्यकता हो। एक मानक तालिका केवल वर्तमान पता या वर्तमान सदस्यता स्तर ही दिखा सकती है।
समय संबंधी मॉडलिंग के बिना, आपके सामने कई चुनौतियां आती हैं:
- संदर्भ का नुकसान: आप नहीं जान सकते कि कीमत में परिवर्तन वास्तविक दुनिया में वास्तव में कब लागू हुआ था, बल्कि जब इसे प्रणाली में दर्ज किया गया था।
- लेखा-जोखा की जटिलता: अलग लेखा-जोखा लॉग तालिका बनाने के लिए हाथ से ट्रिगर कार्यान्वयन की आवश्यकता होती है और प्रत्येक लेखन कार्य में अतिरिक्त भार डालती है।
- प्रश्न करने में कठिनाई: समय रेखा को पुनर्निर्मित करने के लिए अक्सर जटिल जॉइन या सेल्फ-जॉइन की आवश्यकता होती है, जो बनाए रखने और अनुकूलित करने में कठिन होती है।
- डेटा अखंडता: स्पष्ट समय सीमाओं के बिना, बड़े पैमाने पर अपडेट के दौरान ऐतिहासिक डेटा को गलती से ओवरराइट करना आसान होता है।
समय को स्कीमा में सीधे एम्बेड करके, आप इतिहास ट्रैकिंग की जिम्मेदारी को एप्लीकेशन लॉजिक से डेटा संरचना में स्थानांतरित करते हैं।
समय संबंधी आयामों को समझना ⏳
समय के प्रभावी रूप से मॉडलिंग के लिए, आपको डेटाबेस में समय के अलग-अलग तरीकों के बीच अंतर करना होगा। विचार करने योग्य दो मुख्य आयाम हैं: वैध समय और लेनदेन समय। सही मॉडलिंग तकनीक चुनने के लिए इस अंतर को समझना निर्णायक है।
1. वैध समय (व्यापार समय)
वैध समय उस अवधि का प्रतिनिधित्व करता है जब एक तथ्य वास्तविक दुनिया में सच होता है। यह डेटाबेस प्रणाली से स्वतंत्र है। उदाहरण के लिए, यदि किसी कर्मचारी का विभाग 1 जनवरी को सेल्स से इंजीनियरिंग में बदल गया, तो इंजीनियरिंग नियुक्ति के लिए वैध समय उस तारीख से शुरू होता है, चाहे एचआर प्रबंधक ने इसे प्रणाली में कब टाइप किया हो।
- फोकस: वास्तविकता।
- उपयोग के मामले: ऐतिहासिक रिपोर्टिंग, सुसंगतता लेखा-जोखा, पिछली स्थितियों को पुनर्निर्मित करना।
- विशेषताएं: आमतौर पर
वैध_सेऔरवैध_तकसमय टैग।
2. लेनदेन समय (प्रणाली समय)
लेनदेन समय यह ट्रैक करता है कि एक तथ्य डेटाबेस में कब संग्रहीत किया गया था। इसका पूरी तरह से प्रणाली द्वारा प्रबंधन किया जाता है। यदि कोई उपयोगकर्ता आज किसी रिकॉर्ड को संपादित करता है, तो लेनदेन समय उस विशिष्ट क्षण को रिकॉर्ड करता है। यदि रिकॉर्ड को हटा दिया जाता है, तो लेनदेन समय सुनिश्चित करता है कि प्रणाली को पता चले कि यह सक्रिय सेट में दिखाई देना कब बंद हुआ।
- फोकस: प्रणाली संचालन।
- उपयोग केस: डेटा समस्याओं का निराकरण, एक विशिष्ट क्षण पर प्रणाली की स्थिति समझना, रोलबैक क्षमता।
- विशेषताएँ: आमतौर पर डेटाबेस इंजन द्वारा स्वचालित रूप से प्रबंधित किया जाता है जैसे कि
सिस्टम_शुरुआतऔरसिस्टम_समाप्ति.
3. द्विसमयावधि डेटा
जब आपको वैध समय और लेनदेन समय दोनों की आवश्यकता होती है, तो आप एक द्विसमयावधि तालिका बना रहे होते हैं। यह समयावधि मॉडलिंग का सबसे व्यापक रूप है। इससे आप ऐसे प्रश्न पूछने की अनुमति मिलती है, जैसे, “2023 के 1 मार्च को प्रणाली को वास्तविक दुनिया की स्थिति के बारे में 1 जनवरी, 2023 को क्या विश्वास था?”
समय-जागरूक स्कीमा के लिए डिज़ाइन पैटर्न 🛠️
एक एरडी के भीतर समय-आधारित डेटा के कार्यान्वयन के लिए कई आर्किटेक्चरल पैटर्न हैं। चयन आपके प्रश्न पैटर्न और स्टोरेज सीमाओं पर निर्भर करता है।
धीरे-धीरे बदलने वाले आयाम (SCD) प्रकार 2 पैटर्न
यह डेटा वेयरहाउसिंग में ऐतिहासिक ट्रैकिंग के लिए सबसे आम तकनीक है। एक पंक्ति को अपडेट करने के बजाय, आप एक नए संस्करण पहचानकर एक नई पंक्ति डालते हैं। पुरानी पंक्ति को निष्क्रिय चिह्नित कर दिया जाता है।
- मुख्य जोड़:
सरोगेट_की(नए संस्करण से जोड़ने के लिए) औरसक्रिय_हैफ्लैग। - लाभ: एक फ़िल्टर का उपयोग करके वर्तमान रिकॉर्ड खोजने के लिए सरल प्रश्न।
- नुकसान: तालिका बदलावों के साथ रैखिक रूप से बढ़ती है। एक पंक्ति को हटाने के लिए सभी पिछले संस्करणों को अपडेट करना या उन्हें चिह्नित करना आवश्यक होता है।
अवधि तालिका पैटर्न
इस दृष्टिकोण में, समय को दो अलग-अलग कॉलम के बजाय एक अवधि प्रकार के रूप में संग्रहीत किया जाता है। आमतौर पर आधुनिक डेटाबेस इंजन इसका स्वाभाविक समर्थन करते हैं। इससे यह सुनिश्चित किया जाता है कि अवधियाँ एक-दूसरे को ओवरलैप न करें।
- मुख्य जोड़: एक
अवधिडेटा प्रकार सीमा। - लाभ: अतिव्यापी समय सीमाओं के स्वचालित निर्बाधन।
- कमजोरी: विशिष्ट डेटाबेस विशेषताओं की आवश्यकता होती है जो सभी प्रणालियों में उपलब्ध नहीं हो सकती हैं।
घटना स्रोत पैटर्न
वर्तमान स्थिति को संग्रहीत करने के बजाय, आप घटनाओं के क्रम को संग्रहीत करते हैं। स्थिति को इन घटनाओं को दोहराकर पुनर्निर्मित किया जाता है। यह बहुत विस्तृत है लेकिन पढ़ने में गणनात्मक रूप से महंगा हो सकता है।
- मुख्य जोड़: एक केवल जोड़ने वाली लॉग तालिका।
- लाभ: पूर्ण लेखा परीक्षण ट्रेल; कभी भी कोई डेटा हटाया नहीं जाता है।
- कमजोरी: जटिल पढ़ने की तर्कधारा; स्थिति पुनर्निर्माण तुरंत नहीं होता है।
विस्तार से SCD प्रकार 2 दृष्टिकोण 🔄
अधिकांश उद्यम एप्लिकेशनों के लिए, SCD प्रकार 2 जटिलता और उपयोगिता के बीच सबसे अच्छा संतुलन प्रदान करता है। आइए देखें कि इसका ERD संरचना में कैसे अनुवाद होता है।
एक कल्पना करेंग्राहक एक एकांकी। एक मानक मॉडल में, आपके पास प्रत्येक ग्राहक ID के लिए एक पंक्ति होती है। एक समय संबंधी मॉडल में, आपके पास एक ही ग्राहक ID के लिए कई पंक्तियाँ होती हैं, जो समय द्वारा अलग की जाती हैं।
आवश्यक विशेषताएँ:
ग्राहक_id: प्राकृतिक व्यापारिक कुंजी।संस्करण_id: प्रत्येक विशिष्ट रिकॉर्ड उदाहरण के लिए एक अद्वितीय पहचानकर्ता।वैध_से: वह समय चिह्न जब यह रिकॉर्ड प्रभावी हुआ।वैध_तक: वह समय चिह्न जब यह रिकॉर्ड प्रभावी नहीं रहा। आमतौर पर वर्तमान रिकॉर्ड के लिए NULL के रूप में सेट किया जाता है।वर्तमान_है: एक बूलियन फ्लैग जो त्वरित रूप से नवीनतम स्थिति की पहचान करने के लिए होता है।
जब कोई ग्राहक अपना पता बदलता है, तो आप मौजूदा पंक्ति को अपडेट नहीं करते। इसके बजाय, आप:
- अपडेट करें
वैध_समाप्तिपुरानी पता पंक्ति को वर्तमान समय के टैग पर अपडेट करें। - सेट करें
वर्तमान_हैपुरानी पंक्ति के लिए गलत करें। - नए पते के साथ एक नई पंक्ति डालें।
- सेट करें
वैध_प्रारंभवर्तमान समय के टैग पर। - सेट करें
वैध_समाप्तिनॉल पर। - सेट करें
वर्तमान_हैसच करें।
अवधि तालिकाएँ और वैध समय 🗓️
जबकि SCD प्रकार 2 लचीला है, अवधि तालिकाएँ समय की एक कठोर परिभाषा प्रदान करती हैं। इस मॉडल में, समय अंतराल एक एकल लक्षण है। इससे तार्किक त्रुटियों से बचाव होता है जहां वैध_प्रारंभ अधिक है जबकि वैध_समाप्ति.
निम्नलिखित अवधि तालिका के लिए स्कीमा संरचना को ध्यान में रखें:
| कॉलम नाम | प्रकार | विवरण |
|---|---|---|
एंटिटी_आईडी |
UUID | एंटिटी के लिए प्राथमिक कुंजी |
डेटा_मान |
VARCHAR | ट्रैक किए जा रहे गुणधर्म |
समय_अवधि |
अवधि (समयचिह्न) | वैधता की शुरुआत और समाप्ति |
प्रणाली_संस्करण |
INT | पंक्ति के लिए क्रम संख्या |
इस संरचना सुनिश्चित करती है कि डेटाबेस इंजन समय अंतराल की पुष्टि संचयन से पहले करता है। यदि आप एक रिकॉर्ड को सम्मिलित करने की कोशिश करते हैं जो उसी एकता के लिए मौजूदा अवधि के साथ ओवरलैप करता है, तो ऑपरेशन विफल हो जाएगा जब तक कि विशेष रूप से अनुमति न दी गई हो।
लेनदेन समय का प्रबंधन 📝
वैध समय आपको बताता है कि क्या सच था। लेनदेन समय आपको बताता है कि आपको इसके बारे में कब पता चला। कभी-कभी आपको यह जानने की आवश्यकता होती है कि डेटाबेस एक तथ्य को सच मानता था, भले ही वास्तविक दुनिया में बाद में यह गलत साबित हो गया हो।
उदाहरण के लिए, एक उपयोगकर्ता गलत पता दर्ज कर सकता है। प्रणाली इसे लेनदेन समय के साथ रिकॉर्ड करती है। बाद में, उपयोगकर्ता इसे सुधारता है। यदि आप केवल वैध समय का अनुसरण करते हैं, तो आप मूल त्रुटि के रिकॉर्ड को खो देते हैं। यदि आप लेनदेन समय का अनुसरण करते हैं, तो आप प्रणाली के डेटा प्रविष्टि के इतिहास को सुरक्षित रखते हैं।
लेनदेन समय को लागू करने में आमतौर पर उपयोगकर्ता इंटरफेस से कॉलम को छिपाना शामिल होता है। इन कॉलम का प्रबंधन डेटाबेस इंजन द्वारा किया जाता है। “वर्तमान” स्थिति को जांचने पर, प्रणाली स्वचालित रूप से उन रिकॉर्ड्स को फ़िल्टर कर देती है जहां लेनदेन समय समाप्त हो गया है (अर्थात रिकॉर्ड को हटा दिया गया था)।
द्विसमयी मॉडलिंग की व्याख्या ⚖️
द्विसमयी मॉडलिंग वैध समय और लेनदेन समय को मिलाती है। यह नियामक सुसंगतता और अपराध विज्ञान डेटा विश्लेषण के लिए स्वर्ण मानक है।
स्कीमा प्रभाव:
- आपको चार समय-संबंधी कॉलम की आवश्यकता होगी:
वैध_शुरुआत,वैध_समाप्ति,लेनदेन_शुरुआत,लेनदेन_समाप्ति. - आपकी इंडेक्सिंग रणनीति दोनों आयामों को ध्यान में रखनी चाहिए।
- आपके प्रश्न अधिक जटिल हो जाते हैं, जो अक्सर सीमा जॉइन्स की आवश्यकता करते हैं।
प्रश्न उदाहरण तर्क:
किसी विशिष्ट समय पर एक रिकॉर्ड की स्थिति जानने के लिए, आप लेनदेन समय पर फ़िल्टर करते हैं। किसी विशिष्ट समय पर दुनिया की स्थिति जानने के लिए, आप वैध समय पर फ़िल्टर करते हैं। किसी विशिष्ट समय पर प्रणाली द्वारा समझी गई दुनिया की स्थिति जानने के लिए, आप दोनों पर फ़िल्टर करते हैं।
इस अंतर्विष्टता का स्तर वित्त, स्वास्थ्य और कानूनी सेवाओं जैसे क्षेत्रों के लिए आवश्यक है, जहां डेटा के स्रोत की महत्वपूर्णता डेटा के स्वयं के बराबर होती है।
कार्यान्वयन की चुनौतियाँ ⚠️
अपने एरडी में समय जोड़ने से जटिलता आती है जिसे सावधानी से प्रबंधित करने की आवश्यकता होती है।
1. स्टोरेज ब्लोट
हर बदलाव एक नई पंक्ति बनाता है। वर्षों में, एक तालिका अपने गैर-समय संबंधित संस्करण की तुलना में काफी बड़ी हो सकती है। आपको बढ़ी हुई स्टोरेज आवश्यकताओं की योजना बनानी होगी। समय सीमाओं (जैसे मासिक या वार्षिक) के आधार पर पार्टीशनिंग एक सामान्य रणनीति है जिससे क्वेरी तेज रहती है और रखरखाव आसान रहता है।
2. क्वेरी प्रदर्शन
समय सीमाओं के आधार पर फ़िल्टर करना आमतौर पर तेज होता है यदि सही तरीके से इंडेक्स किया गया हो। हालांकि, ऐतिहासिक स्थितियों को पुनर्निर्मित करने के लिए अक्सर कई तालिकाओं को जोड़ने की आवश्यकता होती है। एक क्वेरी जो पहले मिलीसेकंड में लेती थी, अब मिलियन पंक्तियों वाली इतिहास तालिका को स्कैन करने वाली हो तो सेकंड में ले सकती है।
3. एप्लिकेशन लॉजिक में बदलाव
मौजूदा एप्लिकेशन कोड जो प्रत्येक एंटिटी के लिए एक ही पंक्ति मानता है, टूट जाएगा। आपको सभी क्रूड ऑपरेशन को समय विशेषताओं को हैंडल करने के लिए फिर से लिखना होगा। इन्सर्ट ऑपरेशन शर्ती लॉजिक अपडेट में बदल जाते हैं।
4. डेटा सुसंगतता
सुनिश्चित करना कि वैध_शुरू हमेशा कम होवैध_समाप्त डेटाबेस की सीमाओं की आवश्यकता होती है। इन सीमाओं के बिना, आपको ऐतिहासिक रिपोर्टिंग को तोड़ने वाले अमान्य समय अंतराल बनाने का जोखिम है।
रखरखाव के लिए सर्वोत्तम प्रथाएं 🧹
एक समय संबंधित मॉडल को स्वस्थ रखने के लिए, इन दिशानिर्देशों का पालन करें।
- सरोगेट की का उपयोग करें: हमेशा इतिहास तालिका के लिए आंतरिक ID का उपयोग करें, व्यापार की कुंजी के बजाय। इससे व्यापार की कुंजी के बदले बिना संदर्भात्मक अखंडता बनी रहती है।
- रणनीतिक रूप से इंडेक्स बनाएं: (
एंटिटी_आईडी,वैध_शुरू) पर संयुक्त इंडेक्स बनाएं। इससे वर्तमान रिकॉर्ड और ऐतिहासिक स्नैपशॉट्स के लिए खोज तेज हो जाती है। - स्वचालित सफाई: आर्काइविंग नीतियों को लागू करें। यदि कोई रिकॉर्ड 10 वर्ष पुराना है, तो इसे एक कोल्ड स्टोरेज तालिका में स्थानांतरित करें ताकि सक्रिय तालिका हल्की रहे।
- समय रेखा का दस्तावेजीकरण करें: अपने डेटा शब्दकोश में वैध समय और लेनदेन समय के बीच के अंतर को स्पष्ट रूप से दस्तावेजीकृत करें। डेवलपर्स को यह जानने की आवश्यकता है कि उनके उपयोग के मामले के लिए कौन सा समयचिह्न लागू होता है।
- ओवरलैप की पुष्टि करें समान प्राधिकृत अवधि के ओवरलैपिंग को रोकने के लिए डेटाबेस की सीमाओं का उपयोग करें।
कालात्मक रणनीतियों की तुलना
सही मॉडल का चयन आपकी विशिष्ट आवश्यकताओं पर निर्भर करता है। नीचे दी गई तालिका व्यापार के लाभ-हानि का सारांश प्रस्तुत करती है।
| रणनीति | जटिलता | स्टोरेज लागत | प्रश्न गति | सर्वोत्तम उपयोग केस |
|---|---|---|---|---|
| SCD प्रकार 2 | मध्यम | मध्यम | उच्च | सामान्य व्यापार इतिहास ट्रैकिंग |
| अवधि तालिकाएं | उच्च | मध्यम | उच्च | कठोर नियामक सुसंगतता |
| द्विकालिक | अत्यधिक | उच्च | मध्यम | अपराध विज्ञान विश्लेषण, प्रणाली लेखा परीक्षण |
| घटना स्रोत | उच्च | अत्यधिक | निम्न (पढ़ना) | राज्य पुनर्निर्माण, वास्तविक समय के आहरण |
डेटा वार्डों के लिए अंतिम विचार
अपने एंटिटी रिलेशनशिप डायग्राम में समय को शामिल करना एक ऐसा निर्णय है जो आपके डेटा के जीवनचक्र को प्रभावित करता है। यह केवल तकनीकी समायोजन नहीं है; यह जानकारी को देखने के तरीके में बदलाव है।
जब आप समय को ध्यान में रखकर डिज़ाइन करते हैं, तो आप स्वीकार करते हैं कि डेटा स्थिर नहीं है। यह बहता है। यह बदलता है। यह बूढ़ा होता है। अपने स्कीमा के आधार में इन क्षमताओं को बनाकर, आप अतीत के विश्लेषण की आवश्यकता के खिलाफ अपने प्रणालियों को भविष्य के लिए सुरक्षित करते हैं।
अपनी प्रणाली में किन गुणों को वास्तव में इतिहास की आवश्यकता है, इसकी पहचान करके शुरुआत करें। हर कॉलम को समय टैग की आवश्यकता नहीं है। वित्तीय शेष, कर्मचारी नियुक्तियां और उत्पाद मूल्य जैसे उच्च मूल्य वाले डेटा बिंदुओं पर ध्यान केंद्रित करें। अनावश्यक ओवरहेड से बचने के लिए समय संबंधी पैटर्न को चुनौतीपूर्ण ढंग से लागू करें।
जैसे आपकी प्रणाली परिपक्व होती है, आप पाएंगे कि प्रारंभिक डिज़ाइन को सुधार की आवश्यकता हो सकती है। समय संबंधी डेटा मॉडल आवर्धन वाले होते हैं। अपने प्रश्न प्रदर्शन और भंडारण वृद्धि की निगरानी करें। ऐतिहासिक डेटा के आकार के साथ अपनी पार्टीशनिंग और इंडेक्सिंग रणनीति को समायोजित करें।
अंततः, समय-संवेदनशील एरडी एक ही स्रोत के सत्य को प्रदान करता है जो अतीत का सम्मान करता है जबकि वर्तमान की सेवा करता है। यह सुनिश्चित करता है कि जब किसी चीज के होने के ‘क्यों’ के बारे में प्रश्न उठते हैं, तो उत्तर पहले से ही आपके डेटाबेस में लिखा हुआ होता है, जिसे बाहर निकालने के लिए इंतजार कर रहा होता है।