










एक विश्वसनीय डेटाबेस स्कीमा डिज़ाइन करना सॉफ्टवेयर इंजीनियरिंग में एक मूल चरण है। इस आर्किटेक्चर के लिए ब्लूप्रिंट एंटिटी-रिलेशनशिप डायग्राम (ERD) है। एक ERD डेटा की संरचना को दर्शाता है, जो विभिन्न जानकारी के टुकड़ों के बीच संबंध को परिभाषित करता है। एक कार्यात्मक डायग्राम डेटा अखंडता सुनिश्चित करता है, लेकिन एक साफ, रखरखाव योग्य डायग्राम यह सुनिश्चित करता है कि प्रणाली समय के साथ समझने योग्य और अनुकूलन योग्य बनी रहे। तकनीकी ऋण अक्सर कोड में नहीं, बल्कि उन दस्तावेज़ों और डिज़ाइन अभिलेखों में जमा होता है जो प्राचीन हो जाते हैं या भ्रामक हो जाते हैं। यह गाइड ऐसे ERD बनाने के लिए आवश्यक सिद्धांतों को रेखांकित करता है जो समय के परीक्षण को सहन कर सकें।
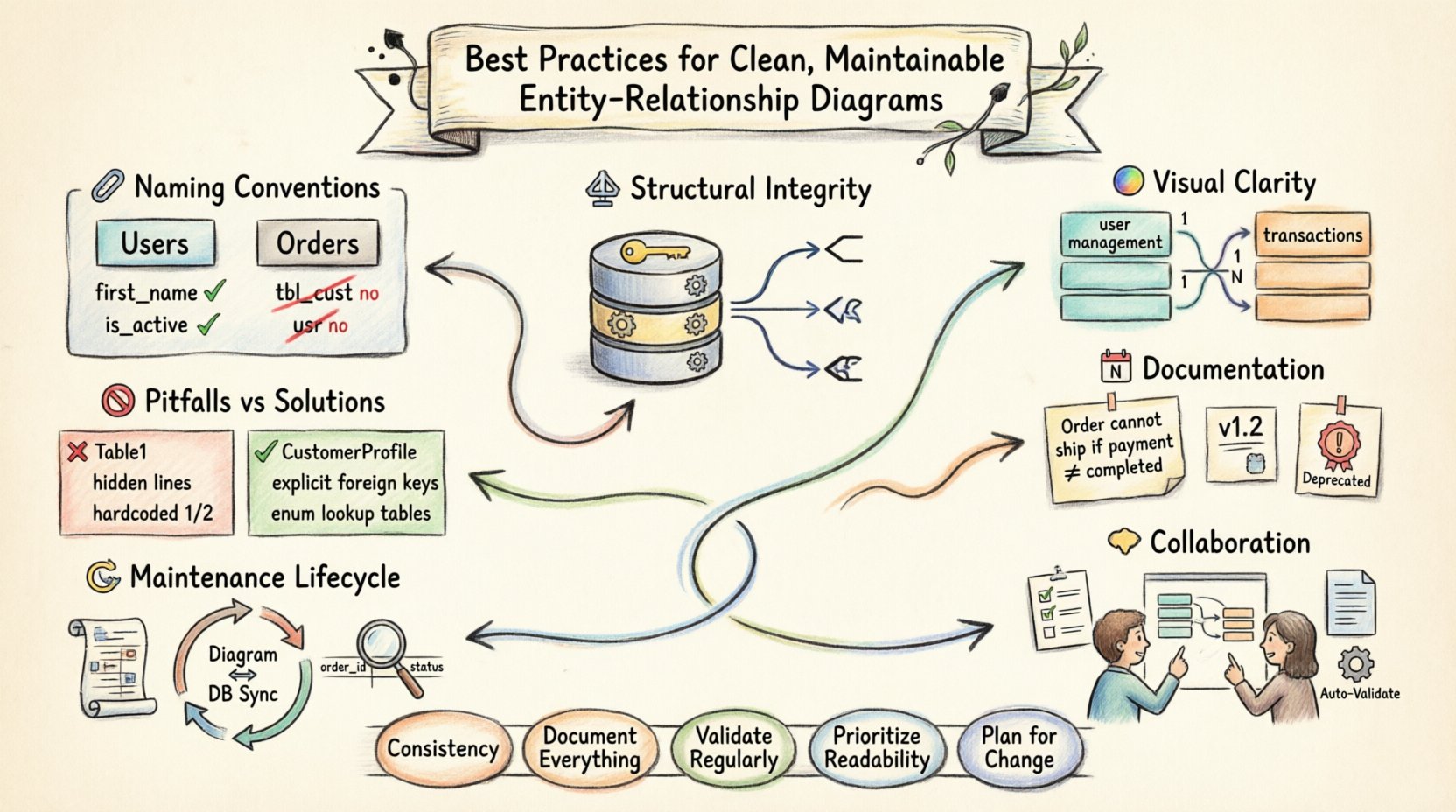
1. नामकरण प्रथाएं और मानक 🏷️
किसी एंटिटी या एट्रिब्यूट का नाम किसी भी डेवलपर के लिए स्कीमा की समीक्षा करने का पहला बिंदु है। असंगत नामकरण बाधाओं को उत्पन्न करता है, ऑनबोर्डिंग को धीमा करता है, और विकास के दौरान त्रुटियों की संभावना बढ़ाता है। एक मानकीकृत नामकरण रणनीति केवल सौंदर्यशास्त्रीय नहीं है; यह एक संचार प्रोटोकॉल है।
एंटिटी नामकरण नियम
- बहुवचन रूप:एंटिटीज़ को सामान्यतः बहुवचन रूप में नामित किया जाना चाहिए (उदाहरण के लिए,
उपयोगकर्ता,आदेश) रिकॉर्ड्स के संग्रह का प्रतिनिधित्व करने के लिए होते हैं। एकवचन नाम (उदाहरण के लिए,उपयोगकर्ता) एक सिंगलटन उदाहरण को इंगित कर सकते हैं, जो संबंधात्मक तालिकाओं में दुर्लभ होता है। - कैमलकेस या स्नेककेस: एक शैली चुनें और उसे सार्वभौमिक रूप से लागू करें। कैमलकेस (उदाहरण के लिए,
ग्राहकआदेश) ऑब्जेक्ट-ओरिएंटेड संदर्भों में आम है, जबकि स्नेककेस (उदाहरण के लिए,ग्राहक_आदेश) अक्सर SQL पर्यावरणों में पसंद की जाती है। शैलियों को मिलाने से बचें। - वर्णनात्मकता: नामों को उस डेटा का वर्णन करना चाहिए जो उनके भीतर संग्रहीत है। जैसे कि
तालिका_ग्राहकयाआदेशके लिए अपरिहार्य छोटे रूपों से बचें। यदि छोटा रूप आवश्यक है, तो एक शब्दकोश तैयार करें।ग्राहकके बजायग्राहक. - आरक्षित शब्दों से बचें: सुनिश्चित करें कि एंटिटी के नाम डेटाबेस कीवर्ड्स के साथ टकराएं नहीं (उदाहरण के लिए,
समूह,आदेश,कुंजी). यदि एक टकराव अनिवार्य है, तो नाम को उद्धरण चिह्नों में लपेटें या प्रीफिक्स का उपयोग करें, हालांकि नाम बदलना बेहतर है।
एट्रिब्यूट नामकरण नियम
- लोअरकेस मानक: विभिन्न डेटाबेस इंजनों में केस-संवेदनशीलता को सुनिश्चित करने के लिए एट्रिब्यूट्स के लिए लोअरकेस का उपयोग करें।
प्रथमनामहोना चाहिएप्रथम_नाम. - परिवर्तनीय कुंजियों के लिए प्रीफिक्स: जब किसी अन्य एंटिटी के संदर्भ में किया जाता है, तो परिवर्तनीय कुंजी का आदर्श रूप से संदर्भित एंटिटी की प्राथमिक कुंजी के नाम के साथ मेल खाना चाहिए, जो अक्सर स्रोत को इंगित करने वाले एक अंत्याक्षर या लक्ष्य को इंगित करने वाले एक प्रीफिक्स के साथ होता है। उदाहरण के लिए, यदि
उपयोगकर्तातालिका में एक हैउपयोगकर्ता_आईडी, तोआदेशतालिका को इसेउपयोगकर्ता_आईडी. - बूलियन स्पष्टता: बूलियन एट्रिब्यूट्स को प्रश्नों या स्पष्ट फ्लैग्स के रूप में नामित किया जाना चाहिए (उदाहरण के लिए,
सक्रिय_है,सदस्यता_है) जैसे सामान्य फ्लैग्स के बजायस्थितियाझंडा.
2. संरचनात्मक अखंडता और सामान्यीकरण ⚖️
एक आरेख जो अच्छा लगता है लेकिन सामान्यीकरण के सिद्धांतों का उल्लंघन करता है, डेटा विचलन की ओर जाएगा। रखरखाव के लिए आवश्यक है कि संरचना प्रभावी प्रश्न प्रश्नों के समर्थन करे और अतिरिक्तता को न्यूनतम करे।
प्राथमिक कुंजियाँ
- स्पष्ट घोषणा: प्रत्येक तालिका में स्पष्ट रूप से परिभाषित प्राथमिक कुंजी होनी चाहिए। कभी भी डेटाबेस इंजन पर निर्भर न करें जो बिना दस्तावेजीकरण के एक उत्पन्न करे।
- प्रतिस्थापन कुंजियाँ: प्राकृतिक कुंजियों (जैसे ईमेल पते या सामाजिक सुरक्षा संख्या) के बजाय प्रतिस्थापन कुंजियों (स्वतः बढ़ते पूर्णांक या UUIDs) का उपयोग करने पर विचार करें। प्राकृतिक कुंजियाँ बदल सकती हैं, जिसके कारण पूरे डेटाबेस में श्रृंखलाबद्ध अद्यतन की आवश्यकता होती है, जो जोखिम भरा और महंगा है।
- संयुक्त कुंजियाँ: संयुक्त कुंजियों का उपयोग केवल तभी करें जब तार्किक रूप से आवश्यक हो (उदाहरण के लिए, बहु-से-बहु संयोजन तालिकाएँ)। मुख्य एककों के लिए इन्हें बचें क्योंकि ये इंडेक्सिंग और संबंधों को जटिल बना देते हैं।
परदार कुंजियाँ और संदर्भात्मक अखंडता
- संबंधों को परिभाषित करें: प्रत्येक परदार कुंजी को आरेख में स्पष्ट रूप से परिभाषित किया जाना चाहिए। नामकरण परंपराओं द्वारा निहित संबंधों को अकेले छोड़ देने के लिए न जाए।
- श्रृंखला नियम: हटाने और अद्यतन के व्यवहार को दस्तावेजीकृत करें। क्या एक रिकॉर्ड को मिटाया जाना चाहिए जब माता-पिता को हटा दिया जाता है? क्या इसे खाली कर दिया जाना चाहिए? इन नियमों (CASCADE, SET NULL, RESTRICT) को डिज़ाइन दस्तावेज़ में दिखाई देना चाहिए।
- चक्रीय निर्भरता से बचें: सुनिश्चित करें कि संबंध चक्रीय निर्भरता न बनाएं जो जॉइन को असंभव या प्रदर्शन अनिश्चित बना दें।
3. दृश्य स्पष्टता और व्यवस्था 🎨
एक ईआरडी एक दृश्य उपकरण है। यदि व्यवस्था अव्यवस्थित है, तो डेटा मॉडल को समझना कठिन हो जाता है। दृश्य प्राथमिकता पाठक को तुरंत प्रणाली की संरचना समझने में मदद करती है।
समूहीकरण और संगठन
- कार्यात्मक समूहीकरण: संबंधित एककों को एक साथ समूहित करें। उदाहरण के लिए, सभी उपयोगकर्ता प्रबंधन तालिकाओं को एक दूसरे के पास रखें, और सभी लेनदेन तालिकाओं को अलग क्लस्टर में रखें।
- तार्किक अलगाव: पठन केवल डेटा को लेखन-भारी डेटा से अलग करें। यदि आपकी प्रणाली में रिपोर्टिंग तालिकाएँ हैं, तो उन्हें संचालन तालिकाओं से दृश्य रूप से अलग करें।
- दिशात्मक प्रवाह: आरेखों को डेटा प्रवाह के संकेत देने के लिए व्यवस्थित करें। आमतौर पर, इसका अर्थ है कि मुख्य संदर्भ डेटा को ऊपर या बाएं रखना, और लेनदेन या लॉग डेटा को नीचे या दाएं रखना।
संपर्क रेखाएँ
- लंबवत रूटिंग: जहां संभव हो, डायगोनल लाइनों के बजाय समकोण लाइनों का उपयोग करें। डायगोनल लाइनें अक्सर एक दूसरे को प्रतिच्छेद करती हैं, जिससे दृश्य शोर बनता है।
- प्रतिच्छेदनों को कम करें: संबंध लाइनों के प्रतिच्छेदन की संख्या को कम करने के लिए एंटिटी की स्थिति को समायोजित करें। प्रतिच्छेदन वाली लाइनें संबंध के मार्ग को छिपा देती हैं।
- कार्डिनैलिटी नोटेशन: मानक नोटेशन (क्राउ के फुट, चेन या यूएमएल) का निरंतर रूप से उपयोग करें। सुनिश्चित करें कि “एक” और “बहुत” छोर स्पष्ट रूप से चिह्नित हैं। कार्डिनैलिटी को निरूपित करने के लिए केवल लाइन की मोटाई या रंग पर भरोसा न करें।
4. दस्तावेज़ीकरण और मेटाडेटा 📝
आरेख खुद पर्याप्त नहीं है। मेटाडेटा डिज़ाइन निर्णयों के पीछे के “क्यों” को समझने के लिए आवश्यक संदर्भ प्रदान करता है।
टिप्पणियाँ और टिप्पणियाँ
- व्यापार तर्क: विशिष्ट व्यापार नियमों को समझाने वाली टिप्पणियाँ जोड़ें। उदाहरण के लिए, एक टिप्पणी एक
आदेशोंतालिका में यह स्पष्ट कर सकती है कि यदि भुगतान स्थितिपूर्ण. - सीमाएँ: यूनिक सीमाएँ, चेक सीमाएँ और डिफ़ॉल्ट मानों को दस्तावेज़ करें। ये अक्सर तब खो जाती हैं जब केवल स्कीमा दृश्य पर ध्यान दिया जाता है।
- प्रतिस्थापन चिह्न: यदि कोई एंटिटी या विशेषता प्रतिस्थापित की गई है लेकिन पीछे की संगतता के लिए रखी गई है, तो इसे स्पष्ट रूप से चिह्नित करें। इसे छिपाएं नहीं, क्योंकि यह अभी भी पुराने कोड में संदर्भित हो सकती है।
संस्करण नियंत्रण
- परिवर्तन लॉग: परिवर्तनों का इतिहास बनाए रखें। किसने स्कीमा को संशोधित किया? कब? क्यों? यह उत्पादन समस्याओं के निराकरण के लिए महत्वपूर्ण है।
- संस्करण संख्या: आरेखों को संस्करण संख्या (उदाहरण के लिए, v1.0, v1.1) के साथ टैग करें। जब एक से अधिक डेटाबेस माइग्रेशन एक साथ चल रही हों, तो इससे भ्रम से बचा जा सकता है।
5. सहयोग और समीक्षा प्रक्रियाएँ 🤝
डेटाबेस डिज़ाइन अक्सर एकांत गतिविधि नहीं होती है। इसमें बैकएंड इंजीनियरों, डेटा विश्लेषकों और व्यापार स्टेकहोल्डरों के योगदान की आवश्यकता होती है।
सहकर्मी समीक्षा
- स्वतंत्र ऑडिट: एक डेवलपर को डिज़ाइन की समीक्षा करने के लिए रखें जिसने डिज़ाइन नहीं लिखा है। ताज़ा नज़रें तार्किक अंतराल और नामकरण असंगतियों को पकड़ती हैं।
- क्षेत्र विशेषज्ञ सत्यापन: मॉडल को व्यवसाय क्षेत्र का सही प्रतिनिधित्व करने के लिए सुनिश्चित करें। एक डेटा मॉडलर एक तालिका देख सकता है, लेकिन एक व्यवसाय विश्लेषक जानता है कि क्या यह तालिका वास्तविक कार्यप्रवाह का प्रतिनिधित्व करती है।
उपकरण और मानक
- मानक टेम्पलेट: सभी आरेखों के लिए एक टेम्पलेट का उपयोग करें ताकि संगठन के भीतर विभिन्न परियोजनाओं में संगतता सुनिश्चित हो।
- स्वचालित सत्यापन: आरेख को वास्तविक डेटाबेस स्कीमा के खिलाफ सत्यापित करने के लिए उपकरणों का उपयोग करें। आरेख और कोड के बीच विचलन त्रुटि का एक सामान्य स्रोत है।
6. रखरखाव चक्र 🔄
एक बार डेप्लॉय करने के बाद, एक एरडी स्थिर नहीं होता है। यह विकसित होता है। इस विकास को बनाए रखने के लिए अनुशासन की आवश्यकता होती है।
स्कीमा ड्रिफ्ट प्रबंधन
- नियमित रूप से सिंक करें: उत्पादन डेटाबेस से आरेख को नियमित रूप से पुनर्जनन करें ताकि यह वास्तविकता के अनुरूप हो।
- माइग्रेशन स्क्रिप्ट्स: एरडी में किसी भी परिवर्तन के लिए एक माइग्रेशन स्क्रिप्ट का होना आवश्यक है। आरेख को अपडेट किए बिना कभी भी डेटाबेस को हाथ से बदलें नहीं।
- प्रभाव विश्लेषण: प्राथमिक कुंजी बदलने या कॉलम को हटाने से पहले, विश्लेषण करें कि इस पर कौन सी निचली रिपोर्ट या एप्लिकेशन निर्भर है।
प्रदर्शन पर विचार
- इंडेक्सिंग रणनीति: दर्ज करें कि कौन से कॉलम इंडेक्स किए गए हैं और क्यों। यह भविष्य के डेवलपर्स को प्रश्न अनुकूलन निर्णयों को समझने में मदद करता है।
- पार्टीशनिंग: यदि एक तालिका विशाल है, तो आरेख में पार्टीशनिंग रणनीति को नोट करें। इसका डेटा के प्रश्न और रखरखाव के तरीके पर प्रभाव पड़ता है।
7. सामान्य त्रुटियाँ और विपरीत पैटर्न 🚫
गलतियों से बचना बेस्ट प्रैक्टिस का पालन करने जितना ही महत्वपूर्ण है। नीचे सामान्य त्रुटियों और सिफारिश किए गए तरीकों की तुलना दी गई है।
| त्रुटि | सिफारिश किया गया तरीका | तर्क |
|---|---|---|
| सामान्य नाम जैसे कि, तालिका1, डेटा |
विशिष्ट नाम जैसे कि, ग्राहक प्रोफ़ाइल, उत्पाद भंडारण |
विशिष्ट नाम डेवलपर्स को बाहरी दस्तावेज़ीकरण के बिना डेटा को समझने में सक्षम बनाते हैं। |
| छिपे हुए संबंध तालिकाओं के बीच कोई रेखा नहीं खींची गई है |
स्पष्ट विदेशी कुंजियाँ रेखाएँ स्पष्ट रूप से खींची गई हैं और लेबल किए गए हैं |
अप्रत्यक्ष संबंध डेटा अखंडता के उल्लंघन और भ्रम की ओर जाते हैं। |
| अत्यधिक सामान्यीकरण बहुत सारी छोटी तालिकाएँ |
उचित सामान्यीकरण 3NF और प्रदर्शन की आवश्यकताओं के बीच संतुलन |
अत्यधिक जॉइन्स के कारण प्रश्न प्रदर्शन में महत्वपूर्ण कमी आ सकती है। |
| अनुपस्थित मेटाडेटा कोई विवरण या प्रकार नहीं |
समृद्ध मेटाडेटा डेटा प्रकार, सीमाएँ और टिप्पणियाँ शामिल करें |
मेटाडेटा का एकीकरण और दीर्घकालिक रखरखाव के लिए आवश्यक है। |
| कड़े मूल्य स्थिति कोड जैसे 1, 2 आरेख में |
प्रतिपादित प्रकार लुकअप तालिकाओं या स्पष्ट एन्यूम्स का उपयोग करें |
कड़े पूर्णांक का बिना विवरण के कोई अर्थ नहीं होता है और बदलने के लिए झुकाव रखते हैं। |
लंबे समय तक टिकाऊपन पर निष्कर्ष
एक साफ एरडी बनाना प्रोजेक्ट के भविष्य में निवेश है। यह डेवलपर्स पर मानसिक भार को कम करता है, डेटा के दूषित होने के जोखिम को कम करता है, और यह सुनिश्चित करता है कि सिस्टम को पूरी तरह से फिर से लिखे बिना विकसित किया जा सके। सख्त नामकरण प्रणाली का पालन करना, दृश्य स्पष्टता बनाए रखना और मेटाडेटा का दस्तावेजीकरण करना, आपको एक ऐसा आधार बनाने में मदद करता है जो स्केलेबल विकास का समर्थन करता है। आज डिजाइन पर लगाए गए प्रयास से भविष्य में रखरखाव के अव्यवस्था को रोका जा सकता है।
याद रखें कि एक एरडी एक जीवित दस्तावेज है। इसे उसी स्तर की देखभाल और संस्करण नियंत्रण की आवश्यकता होती है जैसे कि वह स्रोत कोड जिसे यह दर्शाता है। नियमित समीक्षा, मानकों का पालन करना और सटीकता के प्रति प्रतिबद्धता आपकी डेटा आर्किटेक्चर को मजबूत और टीम को उत्पादक रखेगी।
मुख्य बातें ✅
- सुसंगतता महत्वपूर्ण है: पूरे प्रोजेक्ट के दौरान एक ही नामकरण प्रणाली और एक ही दृश्य शैली का पालन करें।
- सब कुछ दस्तावेजीकरण करें: यह न मानें कि कोड खुद ही अपना विवरण देता है। व्यावसायिक तर्क और सीमाओं के लिए टिप्पणियाँ जोड़ें।
- नियमित रूप से सत्यापित करें: सुनिश्चित करें कि आरेख वास्तविक डेटाबेस स्थिति के अनुरूप हो ताकि विचलन से बचा जा सके।
- पठनीयता को प्राथमिकता दें: यदि एक आरेख पढ़ने में कठिन है, तो उसका रखरखाव करना कठिन होता है। संबंधों को सरल बनाएं और तार्किक रूप से समूहित करें।
- परिवर्तन के लिए योजना बनाएं: भविष्य के बारे में सोचकर डिजाइन करें। जहां संभव हो, सरोगेट की का उपयोग करें और कठोर निर्भरताओं से बचें।