











एक टिकाऊ ऑनलाइन स्टोर बनाने के लिए केवल फ्रंटएंड इंटरफेस से अधिक चाहिए। किसी भी सफल डिजिटल मार्केटप्लेस की रीढ़ उसकी डेटा आर्किटेक्चर में होती है। एक एंटिटी रिलेशनशिप डायग्राम (ईआरडी) जानकारी के भंडारण, संबंध और प्राप्ति के तरीके के लिए ब्लूप्रिंट के रूप में कार्य करता है। स्केल के लिए डिज़ाइन करते समय, जटिलता में काफी वृद्धि होती है। आपको डेटा अखंडता और प्रदर्शन के बीच संतुलन बनाए रखना होगा, ताकि हर लेनदेन भारी लोड के तहत भी चिकनी तरीके से प्रोसेस हो सके।
यह गाइड ई-कॉमर्स डेटाबेस डिज़ाइन के महत्वपूर्ण घटकों का अध्ययन करता है। हम मुख्य एंटिटीज़, उनके संबंधों और उच्च ट्रैफिक का समर्थन करने के लिए आवश्यक पैटर्न की जांच करेंगे। इन संरचनात्मक सिद्धांतों का पालन करके, आप एक ऐसा सिस्टम बना सकते हैं जो आपके ग्राहक आधार के बढ़ने के साथ भी स्थिर रहे। फोकस तार्किक डिज़ाइन, नॉर्मलाइज़ेशन और बॉटलनेक्स को उत्पन्न होने से पहले रोकने वाली रणनीतियों पर है।
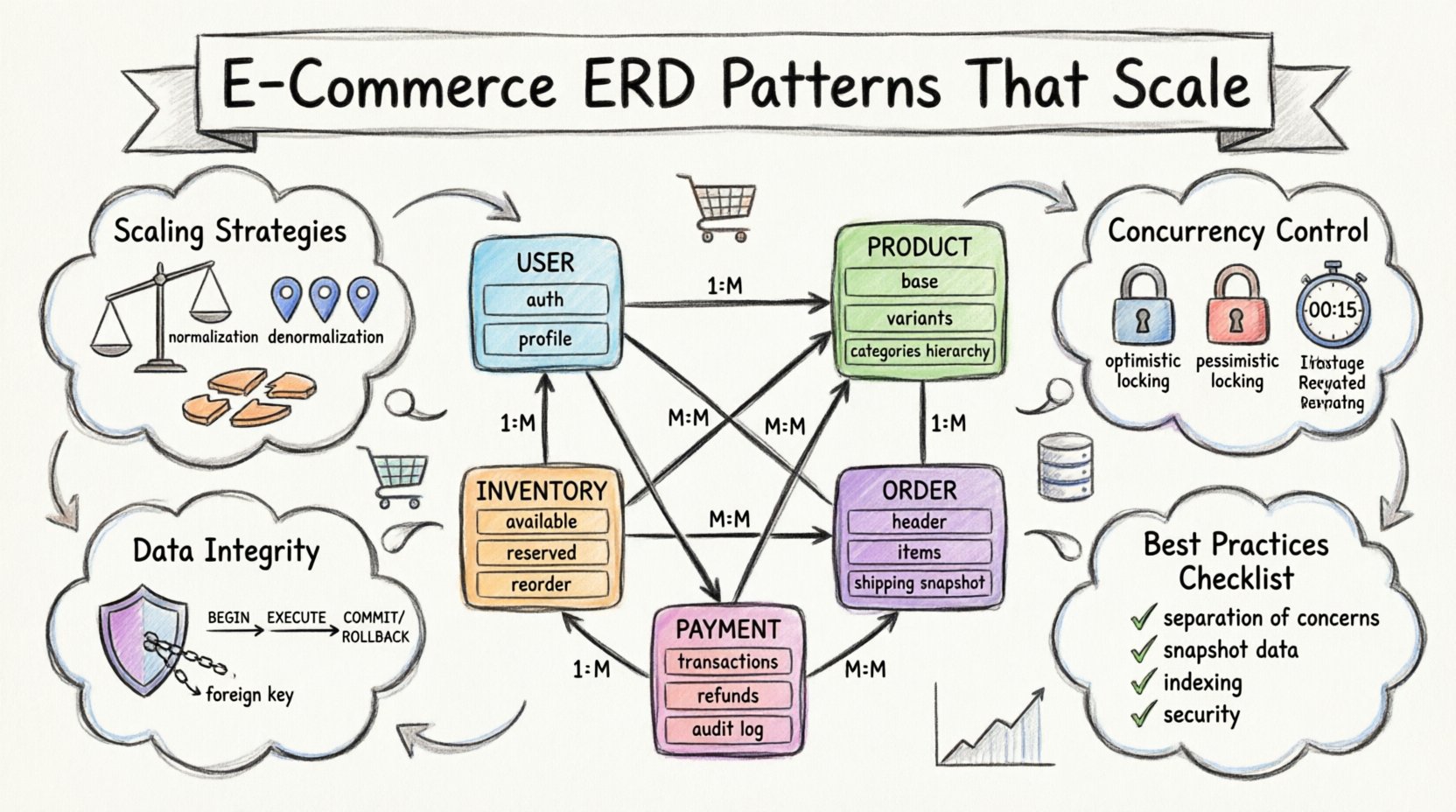
आधारभूत एंटिटीज़ और मुख्य संबंध 🏗️
प्रत्येक ई-कॉमर्स प्लेटफॉर्म व्यवसाय को परिभाषित करने वाले मूल डेटा बिंदुओं से शुरू होता है। इनमें ग्राहकों के बारे में जानकारी, वे क्या खरीदते हैं, और वस्तुओं को कैसे वर्गीकृत किया जाता है, इसकी जानकारी शामिल है। इन मुख्य तालिकाओं के डिज़ाइन ने पूरे सिस्टम की लचीलापन को निर्धारित करता है।
1. उपयोगकर्ता एंटिटी
उपयोगकर्ता तालिका प्रमाणीकरण और प्रोफाइल प्रबंधन के लिए प्रवेश बिंदु है। हालांकि, प्रमाणीकरण क्रेडेंशियल्स को उपयोगकर्ता प्रोफाइल विवरण से अलग करना एक सामान्य पैटर्न है। इस अलगाव के कारण सुरक्षा अपडेट करने में बड़े पैमाने पर उपयोगकर्ता डेटा संरचना को बाधित किए बिना संभव होता है।
- प्रमाणीकरण डेटा:प्रमाणीकरण, सेशन टोकन और खाता स्थिति को स्टोर करता है। इस डेटा को उच्च सुरक्षा और न्यूनतम उपलब्धता की आवश्यकता होती है।
- प्रोफाइल डेटा:नाम, संपर्क जानकारी और डिलीवरी पसंद को संग्रहीत करता है। इस डेटा को अधिक बार अपडेट किया जाता है।
- संबंध:उपयोगकर्ताओं और उनके ऑर्डर इतिहास के बीच एक से बहुत के संबंध होते हैं। प्रत्येक उपयोगकर्ता के कई ऑर्डर हो सकते हैं, लेकिन एक ऑर्डर केवल एक ही उपयोगकर्ता के लिए होता है।
इस चरण पर गोपनीयता नियमों को ध्यान में रखना महत्वपूर्ण है। व्यक्तिगत रूप से पहचान योग्य जानकारी (पीआईआई) को स्टोर करने के लिए विशिष्ट उपायों की आवश्यकता होती है। इस एंटिटी के लिए डेटा को रूपांतरित करने और सख्त पहुंच नियंत्रण को मानक अभ्यास माना जाता है।
2. उत्पाद कैटलॉग
उत्पाद प्रबंधन अक्सर ई-कॉमर्स स्कीमा का सबसे जटिल हिस्सा होता है। एक ही भौतिक वस्तु कई विकल्पों में मौजूद हो सकती है, जैसे आकार या रंग। इसके लिए एक लचीली संरचना की आवश्यकता होती है जिसमें निरंतर स्कीमा बदलाव की आवश्यकता नहीं होती।
- उत्पाद बेस तालिका:शीर्षक, विवरण और बेस मूल्य जैसी सामान्य जानकारी संग्रहीत करती है।
- वेरिएंट तालिका:एसकेयू, रंग, आकार और व्यक्तिगत मूल्य जैसी विशिष्ट विशेषताओं को स्टोर करती है।
- श्रेणी तालिका:हायरार्की को परिभाषित करती है। श्रेणियां नेस्टेड हो सकती हैं, जिसके लिए सेल्फ-रेफरेंसिंग संबंध या पाथ एन्यूमरेशन रणनीति की आवश्यकता होती है।
यहां डेनॉर्मलाइज़ेशन को आमतौर पर विचार में लिया जाता है। जबकि नॉर्मलाइज़ेशन अतिरेक को कम करता है, उत्पाद सूची पृष्ठ के लिए डेटा पढ़ने के लिए कई तालिकाओं को जोड़ने की आवश्यकता होती है। उच्च ट्रैफिक स्थितियों में, जोड़े गए डेटा को कैश करना या विशिष्ट फील्ड्स को डेनॉर्मलाइज़ करना प्रश्न गति में सुधार कर सकता है।
3. इन्वेंटरी और स्टॉक प्रबंधन
स्टॉक स्तर को ट्रैक करना ओवरसेलिंग से बचने के लिए महत्वपूर्ण है। इन्वेंटरी तालिका को उत्पाद वेरिएंट्स से सीधे लिंक करना चाहिए। इसमें वर्तमान उपलब्ध मात्रा, आरक्षित मात्रा और कुल क्षमता को स्टोर करना चाहिए।
- उपलब्ध स्टॉक:तुरंत खरीदने के लिए तैयार वस्तुओं की संख्या।
- आरक्षित स्टॉक:खरीदारी के दौरान ग्राहक के कार्ट में रखी गई वस्तुएं।
- पुनर्आदेश बिंदु: एक सीमा जो पुनर्भरण के लिए चेतावनी तब उत्पन्न करती है जब स्टॉक कम हो जाता है।
समानांतरता यहाँ एक प्रमुख चुनौती है। यदि दो उपयोगकर्ता एक ही समय में आखिरी वस्तु खरीदने की कोशिश करें, तो सिस्टम को दोनों के सफल होने से रोकना चाहिए। इसके लिए आमतौर पर डेटाबेस लेनदेन शामिल होते हैं जो अपडेट प्रक्रिया के दौरान विशिष्ट इन्वेंट्री पंक्ति को लॉक करते हैं।
लेनदेन आर्किटेक्चर और ऑर्डर प्रोसेसिंग 🛒
ऑर्डर जीवनचक्र प्लेटफॉर्म की धड़कन है। यह ग्राहक से व्यापारी तक मूल्य के हस्तांतरण का प्रतिनिधित्व करता है। डेटाबेस डिज़ाइन को कार्ट से फुलफिलमेंट तक होने वाले स्थिति परिवर्तनों का समर्थन करना चाहिए।
ऑर्डर एंटिटी संरचना
एक ऑर्डर रिकॉर्ड एक विशिष्ट समय पर लेनदेन की एक स्नैपशॉट है। इसे वर्तमान उत्पाद मूल्य को सिर्फ संदर्भित करना चाहिए। यदि ऑर्डर दर्ज करने के बाद मूल्य में परिवर्तन होता है, तो ऐतिहासिक रिकॉर्ड सटीक रहना चाहिए।
- ऑर्डर हेडर: ऑर्डर आईडी, उपयोगकर्ता आईडी, कुल राशि, कर, शिपिंग लागत और ऑर्डर स्थिति शामिल है।
- ऑर्डर आइटम्स: ऑर्डर्स को उत्पादों से जोड़ने वाली एक जंक्शन टेबल। इस टेबल में खरीदारी के समय विशिष्ट वेरिएंट, मात्रा और मूल्य का रिकॉर्ड रखा जाता है।
- शिपिंग पता: ऑर्डर के समय पता संग्रहीत करना उपयोगकर्ता के वर्तमान पता प्रोफाइल से जोड़ने की तुलना में सुरक्षित है।
स्थिति प्रबंधन
ऑर्डर विभिन्न स्थितियों से गुजरते हैं। अच्छी तरह से डिज़ाइन किया गया स्थिति फ़ील्ड सिस्टम को जटिल जॉइन्स के बिना प्रगति का अनुसरण करने में सक्षम बनाता है। सामान्य स्थितियाँ इस प्रकार हैं:
- प्रतीक्षा में: ऑर्डर बनाया गया है लेकिन अभी तक भुगतान नहीं किया गया है।
- भुगतान किया गया: भुगतान पुष्टि किया गया है।
- प्रोसेसिंग: इन्वेंट्री आवंटित की गई है और तैयारी की जा रही है।
- भेजा गया: ट्रैकिंग जानकारी के साथ वस्तु भेजी गई।
- डिलीवर किया गया: ग्राहक ने वस्तु प्राप्त कर ली है।
- रिफंड किया गया: धन ग्राहक को वापस लौटा दिया गया।
स्थिति के लिए एक प्रकार के सूचीबद्ध प्रकार का उपयोग करने से डेटा सुसंगतता सुनिश्चित होती है। यह टाइपो को रोकता है जो विशिष्ट स्थिति मानों पर निर्भर ऑटोमेशन स्क्रिप्ट को तोड़ सकते हैं।
भुगतान और वित्तीय रिकॉर्ड 💳
वित्तीय डेटा को सर्वोच्च सटीकता की आवश्यकता होती है। आप धन के लिए मानक एप्लीकेशन लॉजिक पर निर्भर नहीं कर सकते। डेटाबेस को वित्तीय लेनदेन को एक अलग घटना के रूप में रिकॉर्ड करना चाहिए।
- भुगतान लेनदेन: प्रत्येक भुगतान प्रयास को एक रिकॉर्ड बनाना चाहिए। इसमें गेटवे प्रतिक्रिया, उपयोग किए गए तरीके और अंतिम परिणाम शामिल हैं।
- लौटाए गए राशि: एक रिफंड मूल भुगतान से जुड़ी एक अलग लेनदेन है। इसे मूल रिकॉर्ड को सिर्फ शून्य करने के लिए नहीं होना चाहिए।
- कर की गणना: कर की दर स्थान के अनुसार बदलती है। प्रत्येक ऑर्डर आइटम के लिए लागू कर राशि स्टोर करने से ऑडिट करने में आसानी होती है।
यहां ऑडिट लॉगिंग अनिवार्य है। वित्तीय रिकॉर्ड में किए गए हर बदलाव को समयचिह्न और क्रिया करने वाले उपयोगकर्ता ID के साथ लॉग किया जाना चाहिए। इससे विवाद समाधान और आंतरिक ऑडिट के लिए एक निशान बनता है।
उच्च आयतन के लिए स्केलिंग रणनीतियां 📈
जैसे-जैसे ट्रैफिक बढ़ता है, डेटाबेस एक बॉटलनेक बन जाता है। मानक स्केलिंग में ऊर्ध्वाधर स्केलिंग (एकल सर्वर में अधिक शक्ति जोड़ना) शामिल है, लेकिन इसकी सीमाएं हैं। क्षैतिज स्केलिंग (अधिक सर्वर जोड़ना) के लिए सावधानीपूर्वक डेटा वितरण योजना की आवश्यकता होती है।
1. सामान्यीकरण बनाम असामान्यीकरण
सामान्यीकरण डेटा दोहराव को कम करता है। यह लेनदेन अखंडता के लिए मानक है। हालांकि, जैसे-जैसे डेटा का आयतन बढ़ता है, बहुत सारे टेबलों को जोड़ने वाले जटिल प्रश्न धीमे हो सकते हैं।
| रणनीति | लाभ | नुकसान |
|---|---|---|
| सामान्यीकरण | डेटा सुसंगतता, कम स्टोरेज | जटिल प्रश्न, धीमी पढ़ाई |
| असामान्यीकरण | तेज पढ़ाई, सरल प्रश्न | डेटा अतिरेक, अपडेट की जटिलता |
ई-कॉमर्स में, एक हाइब्रिड दृष्टिकोण अक्सर सबसे अच्छा होता है। मूल लेनदेन टेबलों को सामान्यीकृत रखें ताकि अखंडता सुनिश्चित हो। रिपोर्टिंग और खोज के उद्देश्यों के लिए असामान्यीकृत दृश्य या अलग टेबल बनाएं। इससे ऑर्डर प्रोसेसिंग की सटीकता को नुकसान नहीं पहुंचाए बिना तेजी से उत्पाद ब्राउज़ करने में सक्षम होते हैं।
2. इंडेक्सिंग रणनीतियां
इंडेक्स प्रदर्शन के लिए निर्णायक हैं। वे डेटाबेस को पूरी टेबल को स्कैन किए बिना पंक्तियों को खोजने की अनुमति देते हैं। हालांकि, बहुत सारे इंडेक्स लेखन ऑपरेशन को धीमा कर देते हैं।
- प्राथमिक कुंजियां: हमेशा इंडेक्स किए गए। ID द्वारा सीधे खोज के लिए उपयोग किया जाता है।
- विदेशी कुंजियां: अक्सर इंडेक्स किए जाते हैं ताकि संबंधित टेबलों के बीच जॉइन को तेज किया जा सके।
- संयुक्त इंडेक्स: बहुल वक्तव्यों द्वारा फ़िल्टर करने वाले प्रश्नों के लिए उपयोगी, जैसे स्थिति और तारीख।
- पूर्ण-पाठ इंडेक्स: उत्पाद खोज कार्यक्षमता के लिए आवश्यक हैं।
नियमित रूप से प्रश्न के निष्पादन योजनाओं की समीक्षा करें। यदि एक प्रश्न एक सूचकांक का उपयोग नहीं कर रहा है, तो डेटाबेस पूरी तालिका के स्कैन कर सकता है, जिससे डेटासेट बढ़ने के साथ प्रदर्शन घटता है।
3. विभाजन और शैडिंग
जब एक एकल तालिका बहुत बड़ी हो जाती है, तो विभाजन इसे छोटे, प्रबंधनीय टुकड़ों में बांटता है। इसे अक्सर तारीख या ID सीमा के आधार पर किया जाता है।
- रेंज विभाजन: आदेशों को वर्ष या महीने के आधार पर विभाजित करना। इससे हाल के डेटा तेजी से स्टोरेज पर रहता है जबकि पुराने डेटा को आर्काइव किया जाता है।
- हैश विभाजन: ID के हैश के आधार पर डेटा को कई सर्वरों पर वितरित करना। इससे लोड को समान रूप से फैलाया जाता है।
शैडिंग इसे आगे बढ़ाती है जब डेटा को कई भौतिक सर्वरों पर वितरित किया जाता है। इसके लिए एप्लिकेशन को यह जानने की आवश्यकता होती है कि कौन सा शैड डेटा को रखता है। यह एक जटिल आर्किटेक्चरल निर्णय है जिसे ऊर्ध्वाधर स्केलिंग के उपयोग के बाद सबसे अच्छा ढंग से लागू किया जाना चाहिए।
डेटा अखंडता और सीमाएं 🔒
संबंधित डेटाबेस डेटा गुणवत्ता बनाए रखने के लिए शक्तिशाली सीमाएं प्रदान करते हैं। नियमों को लागू करने के लिए एप्लिकेशन कोड पर भरोसा करना जोखिम भरा है, क्योंकि कोड में बग हो सकते हैं। डेटाबेस सीमाएं एक सुरक्षा नेट प्रदान करती हैं।
1. संदर्भात्मक अखंडता
विदेशी कुंजी सीमाएं सुनिश्चित करती हैं कि एक आदेश हमेशा एक वैध उपयोगकर्ता और उत्पाद से जुड़ा रहे। यदि कोई उत्पाद हटाया जाता है, तो डेटाबेस को या तो हटाने को रोकने या कार्य को निर्भर रिकॉर्ड्स तक कैस्केड करने के लिए कॉन्फ़िगर किया जा सकता है। ई-कॉमर्स में, मौजूदा आदेशों वाले उत्पादों को हटाने से बचना आमतौर पर सुरक्षित विकल्प होता है।
2. लेनदेन एटॉमिकिटी
एक लेनदेन एकल इकाई में कई संचालनों को समूहित करता है। या तो सभी संचालन सफल होते हैं, या कोई भी नहीं। यह इन्वेंट्री अपडेट के लिए महत्वपूर्ण है। जब कोई आदेश दिया जाता है, तो इन्वेंट्री कम होनी चाहिए। यदि इन्वेंट्री अपडेट विफल होता है, तो आदेश रिकॉर्ड को नहीं बनाना चाहिए।
- लेनदेन शुरू करें:संबंधित संसाधनों को लॉक करता है।
- अपडेट निष्पादित करें:आवश्यक लेखन करें।
- कॉमिट करें: बदलावों को स्थायी बनाता है।
- रोलबैक करें: यदि कोई त्रुटि होती है तो बदलावों को वापस ले लेता है।
3. अद्वितीय सीमाएं
अद्वितीय सीमाएं डुप्लीकेट लेनदेन को रोकती हैं। यह उपयोगकर्ता तालिका में ईमेल पते या उत्पाद तालिका में SKU कोड के लिए उपयोगी है। यह सिस्टम को गलती से डुप्लीकेट खाते या टकराव वाले इन्वेंट्री आइटम बनाने से रोकता है।
उच्च समानांतरता का प्रबंधन ⚡
फ्लैश सेल और उच्च ट्रैफिक घटनाएं रेस कंडीशन बनाती हैं। कई उपयोगकर्ता एक ही आइटम को ठीक एक ही मिलीसेकंड में खरीदने की कोशिश कर सकते हैं।
आशावादी लॉकिंग
आशावादी लॉकिंग मानती है कि संघर्ष दुर्लभ होते हैं। इसमें पंक्ति में एक संस्करण संख्या जोड़ना शामिल है। अपडेट करते समय, डेटाबेस जांचता है कि क्या संस्करण संख्या मेल खाती है। यदि यह बदल गई है, तो अपडेट को अस्वीकार कर दिया जाता है, और एप्लिकेशन को पुनरायोजन करना होगा।
आलसी लॉकिंग
आलसी लॉकिंग पाठ्यक्रम को पढ़ते ही तुरंत लॉक कर देती है। अन्य लेनदेन को लॉक रिलीज होने तक प्रतीक्षा करनी होती है। इससे डेटा संगतता सुनिश्चित होती है, लेकिन उच्च प्रतिस्पर्धा के दौरान थ्रूपुट को कम कर सकती है।
इन्वेंटरी आरक्षण
अधिक बिक्री से बचने के लिए, जब उपयोगकर्ता एक वस्तु को अपने खरीदारी बाग में जोड़ता है, तो इन्वेंटरी का आरक्षण करें। इस आरक्षण के लिए एक समय सीमा सेट करें। यदि उपयोगकर्ता समय सीमा के भीतर खरीदारी पूरी नहीं करता है, तो इन्वेंटरी उपलब्ध स्टॉक में वापस छोड़ दी जाती है।
खोज और विश्लेषण विचार 📊
लेनदेन डेटाबेस को जटिल विश्लेषणात्मक प्रश्नों या पूर्ण-पाठ खोज के लिए नहीं डिज़ाइन किया गया है। मुख्य आदेश या उत्पाद तालिकाओं पर भारी खोज प्रश्न चलाने से सामान्य उपयोगकर्ताओं के लिए प्रदर्शन में कमी आ सकती है।
- खोज इंजन: उत्पाद खोज के लिए एक निर्दिष्ट खोज इंजन का उपयोग करें। मुख्य डेटाबेस से खोज इंजन में उत्पाद डेटा को असिंक्रोनस रूप से सिंक करें।
- विश्लेषण गोदाम: ऐतिहासिक डेटा को रिपोर्टिंग के लिए अलग विश्लेषणात्मक स्टोर में स्थानांतरित करें। इससे लेनदेन डेटाबेस हल्का रहता है।
- पठन प्रतिकृतियाँ: पठन केवल ट्रैफिक को प्रतिकृति सर्वरों की ओर मार्गदर्शित करें। इससे लोड को मुख्य लेखन सर्वर से अलग किया जाता है।
लेखन-भारी संचालनों को पठन-भारी संचालनों से अलग करके, आप सुनिश्चित करते हैं कि खरीदारी प्रक्रिया तेज रहती है, भले ही उपयोगकर्ता ब्राउज़ कर रहे हों या रिपोर्ट बना रहे हों।
रखरखाव और लंबे समय तक वृद्धि 🔄
एक डेटाबेस डिज़ाइन स्थिर नहीं होता है। इसे व्यवसाय के साथ विकसित होना चाहिए। जैसे ही नए फीचर जोड़े जाते हैं, स्कीमा में समायोजन की आवश्यकता हो सकती है।
- संस्करण निर्धारण: स्कीमा संस्करणों का अनुसरण करें। यह सुनिश्चित करता है कि यदि कोई माइग्रेशन विफल होती है, तो सुरक्षित रूप से वापस जाया जा सकता है।
- आर्काइविंग: पुराने आदेशों को कोल्ड स्टोरेज में स्थानांतरित करें। इससे सक्रिय तालिका का आकार प्रबंधनीय रहता है।
- निगरानी: धीमे प्रश्नों, लॉक इंतजार और डिस्क स्पेस उपयोग के लिए चेतावनियाँ सेट करें। सक्रिय निगरानी बाधाओं को रोकती है।
वास्तविक उपयोग पैटर्न के अनुसार नियमित रूप से एरडी की समीक्षा करें। कुछ संबंध जो कागज पर अच्छे लगते हैं, उत्पादन में अक्षम साबित हो सकते हैं। जब डेटा पैटर्न में महत्वपूर्ण परिवर्तन होते हैं, तो फिर से डिज़ाइन करने के लिए तैयार रहें।
सर्वोत्तम प्रथाओं का सारांश ✅
एक स्केलेबल ई-कॉमर्स डेटाबेस को बनाने के लिए संरचना और लचीलापन के बीच संतुलन आवश्यक है। निम्नलिखित बिंदु एक लचीले प्रणाली के निर्माण के लिए मुख्य निष्कर्षों का सारांश प्रस्तुत करते हैं।
- चिंताओं का अलगाव: प्रमाणीकरण, कैटलॉग और लेनदेन डेटा को अलग-अलग रखें।
- स्नैपशॉट डेटा: खरीदारी के समय आदेश विवरण को स्टोर करें, केवल संदर्भ नहीं।
- समानांतरता नियंत्रण: अधिक बिक्री से बचने के लिए लेनदेन और लॉकिंग का उपयोग करें।
- इंडेक्सिंग: सबसे आम पठन और लेखन पैटर्न के लिए अनुकूलित करें।
- स्केलेबिलिटी: आर्किटेक्चर के शुरुआती चरण में पार्टीशनिंग और शार्डिंग की योजना बनाएं।
- सुरक्षा: संवेदनशील डेटा को एन्क्रिप्ट करें और सख्त पहुंच नियंत्रण लागू करें।
इन पैटर्न्स का पालन करने से आप विकास को समर्थन देने वाली एक आधारशिला बनाते हैं। डेटाबेस एक स्थिर इंजन बन जाता है जो निरंतर आपातकालीन ठीक किए बिना व्यवसाय को संचालित करता है। सबसे पहले डेटा अखंडता पर ध्यान केंद्रित करें, फिर गति के लिए अनुकूलित करें। एक धीमा सिस्टम गलत एक से बेहतर है।