











在数据库设计的复杂架构中,很少有概念能像自引用实体一样对工程师构成挑战。也被称为递归关系,这种模式允许一个表链接到自身,从而在扁平化模式中实现对层次结构和复杂结构的建模。正确理解如何实现这一关系对于维护数据完整性和查询性能至关重要。
在设计实体关系图(ERD)时,大多数关系连接的是两个不同的实体。然而,现实世界中的数据常常要求一个实体与自身类型相关联。例如,经理管理员工,类别包含子类别,产品可以是套件的一部分。这些场景都需要使用递归关系。
本指南探讨了处理自引用实体的机制、设计模式和最佳实践。我们将研究如何在不依赖特定软件工具的情况下构建这些关系,重点聚焦于通用的数据库原则。
🧐 什么是自引用实体?
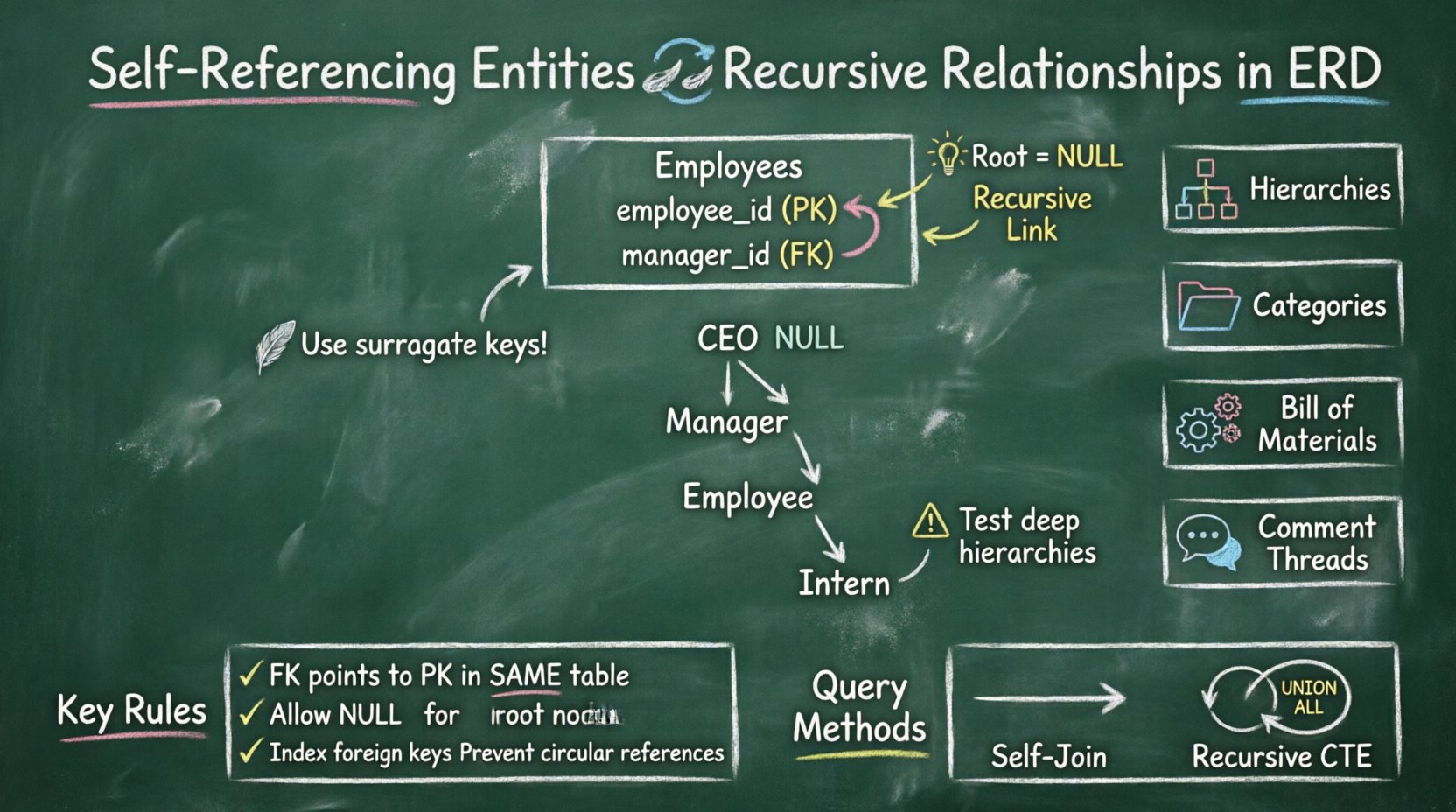
当表中的外键指向同一张表的主键时,就会发生自引用实体。这形成一个循环,使得单个表中的数据行可以引用该表中的其他行。这是建模层次数据结构的基本技术。
关键特征:
- 单表: 关系完全存在于一个表结构内部。
- 父子关联: 一行作为父级,另一行作为子级。
- 空值处理: 层次结构的根节点在外部键列中通常具有空值。
- 循环逻辑: 在数据检索过程中必须小心,以防止出现无限循环。
🏗️ 递归关系的核心组件
为了有效实现这种关系,必须协调特定的数据库组件。模式设计在很大程度上依赖于主键和外键之间的交互。
🔑 主键
表中的每一行都必须有一个唯一标识符。这是锚点。当一行引用另一行时,它通过存储父行的唯一标识符来实现。
- 它必须是稳定的。更改主键是一项复杂操作。
- 应建立索引以实现快速查找性能。
- 通常,这是一个自增整数或UUID。
🔗 外键
外键列与主键位于同一张表中。它存储父行主键的值。该列定义了关系的方向。
- 可为空: 在层次结构中,顶级项目(根节点)没有父节点。因此,该列必须允许为空值。
- 约束: 外键约束确保存储的值与同一表中已存在的主键匹配。
- 索引: 虽然并非总是强制要求,但对外键列建立索引可以显著加快遍历层次结构的查询速度。
📐 在实体关系图中进行可视化
在绘制ERD以表示自引用实体时,符号一开始可能会让人感到困惑。标准的ERD工具使用特定的线条来表示连接。
视觉符号规则:
- 实体框只绘制一次。
- 关系线将主键与同一框内的外键连接起来。
- 这条线通常会回绕到实体,形成一个视觉上的圆圈。
- 基数标记(1:1,1:M)被放置在该线上,以表示父级可以有多少个子级。
示例:组织结构
| 概念 | 描述 | ERD符号 |
|---|---|---|
| 员工 | 被建模的实体 | 标有“员工”的框 |
| 经理 | 引用同一张表的角色 | 从经理ID到员工ID的连线 |
| 汇报关系 | 递归关系 | 环形箭头 |
| 根节点 | 首席执行官或最高层主管 | 经理ID为NULL值 |
🌳 递归数据的常见应用场景
递归关系并非理论上的概念;它们在数据建模中解决了实际问题。以下是该模式最常被应用的几种场景。
1️⃣ 组织层级
每家公司都有其结构。员工向经理汇报,经理向总监汇报,总监向副总裁汇报。这一链条是一种经典的树状结构。
- 数据模型: 一张名为“员工”的表。
- 列:
员工编号,名称,主管编号. - 逻辑: 该
主管编号列引用员工编号. - 优势: 新员工入职只需插入一行数据。无需为每个部门创建新的表。
2️⃣ 分类树
电商平台通常将产品组织成嵌套的分类。电子产品 > 计算机 > 笔记本电脑。
- 数据模型: 一张名为“分类”的表。
- 列:
分类编号,名称,父级编号. - 逻辑: 一个分类可以有父级,也可以是根分类(父级编号为空)。
- 优势: 可以灵活添加任意数量的子分类,而无需更改数据结构。
3️⃣ 物料清单(BOM)
制造通常需要复杂的零部件清单。一辆汽车由发动机组成,而发动机又由活塞组成。有时一个活塞可能是另一种发动机型号的一部分。
- 数据模型: 一张名为“Parts”的表。
- 列:
零件ID,描述,组件ID. - 逻辑: 一个零件本身也可以是一个组件,包含其他零件。
- 优势: 支持多层级的制造结构。
4️⃣ 评论线程
论坛和博客允许用户回复评论。一条评论可以有一个它所回复的父评论,也可以是独立的评论。
- 数据模型: 一张名为“Comments”的表。
- 列:
评论ID,用户ID,内容,父评论ID. - 逻辑: 回复会链接回原始评论的ID。
- 优势: 支持讨论的无限嵌套。
⚙️ 实现注意事项
设计模式只是第一步。确保数据在各种条件下都能正确运行,需要仔细规划。
🛑 防止循环引用
递归关系中的一个关键风险是形成循环。例如,员工A管理员工B,而员工B又管理员工A。这会导致无限循环。
- 应用逻辑: 在插入或更新数据时,应用程序应验证层级深度,以确保不会形成循环。
- 数据库约束: 虽然标准SQL约束难以轻易防止循环(因为它们检查的是当前状态,而非结果状态),但在某些系统中可以使用触发器在写入前验证路径。
- 根节点识别: 确保每个有效的树结构恰好有一个根节点(即外键为null的节点)。
📉 处理空值
层次结构的根是起点。在标准的递归关系中,根行在外键列中具有空值。
- 查询: 要查找所有根节点,请查询外键为NULL的行。
- 默认值: 如果默认值暗示了父节点,则不应为外键设置默认值。0或-1的默认值可能具有误导性,并导致数据完整性问题。
- 完整性: 确保数据库引擎允许外键列为空。NOT NULL约束将破坏层次结构模型。
📈 性能与索引
随着数据的增长,查询递归结构可能会变得缓慢。查找特定节点所有后代的简单查询可能需要多次连接或递归查询。
优化策略:
- 索引外键: 在存储父级引用的列上创建索引。这可以加快查找子节点的速度。
- 物化路径: 某些系统将层次结构的完整路径存储在单独的列中(例如“/1/5/12/20”)。这允许更快的基于字符串的过滤,但每次插入都需要更新。
- 嵌套集合: 一种替代算法,使用左值和右值来表示深度。检索速度更快,但插入速度较慢。
- 查询深度: 限制查询中的递归深度。如果未设置上限,无限循环可能导致数据库引擎崩溃。
🔍 查询递归数据
获取层次化数据比获取扁平数据更复杂。标准的JOIN操作仅适用于单层,但多层结构需要专门的逻辑。
🔄 自连接
最常用的方法是将表与自身进行连接。你需要将表别名一次设为父节点,一次设为子节点。
- 单层: 将表与自身连接一次,以获取直接父节点。
- 多层: 需要多次连接,很快就会变得难以处理。
- 缺点: 所需的连接次数等于层次结构的深度。
🔁 递归公用表表达式(CTEs)
现代数据库引擎支持递归CTE。这使得查询可以反复与自身进行UNION ALL操作,直到不再找到匹配的行为止。
- 锚点成员: 递归的起始点(通常是根节点)。
- 递归成员: 查询中将结果重新连接回表以查找下一层的部分。
- 终止条件: 当不再找到匹配的行时,查询停止。
- 优势: 无需预先知道层次深度即可处理任意深度的层次结构。
🛡️ 数据完整性和约束
维护自引用表的完整性至关重要。如果删除了父节点,子节点会怎样?
🗑️ 删除级联
当删除父行时,数据库必须决定如何处理子行。
- RESTRICT(限制): 如果存在子节点,则阻止父节点的删除。这可以保护数据,但可能会阻碍必要的清理操作。
- CASCADE(级联): 删除父节点时,也会删除所有子节点。在深层层次结构中这很危险,可能导致意外删除大量数据。
- SET NULL(设为空): 将子节点的外键设为NULL,使其成为新的根节点。这通常是保持数据结构安全的首选方案。
- 设置默认值: 将外键设置为默认值(例如,某个特定的孤立类别)。
🔒 更新约束
更改父行的主键存在风险。如果你更改了经理的ID,就必须在所有引用该经理的员工记录中更新该ID。
- 应用层: 以事务方式处理更新,确保所有引用同时更新。
- 数据库触发器: 可以自动传播ID变更,但会增加复杂性。
- 最佳实践: 尽可能避免在递归结构中更新主键。应使用代理键(自增整数)而非自然键(如员工代码)。
🚧 排查常见问题
即使设计得当,开发和维护过程中仍可能出现问题。
❓ 如何查找树的深度?
要确定特定行的层级,必须从该行向上遍历到根节点。计算经过的跳数。
- 查询方法: 使用递归查询,在向上移动时统计行数。
- 应用方法: 在插入时将深度存储在列中。这可以节省查询时间,但需要维护。
❓ 如何处理孤立节点?
孤立节点是指外键指向不存在的父节点的行。这通常是由于错误或手动数据输入错误导致的。
- 验证: 定期运行完整性检查,以查找外键不匹配任何主键的行。
- 恢复: 制定处理策略:将其移至根类别、删除或标记为待审核。
❓ 随时间推移性能下降
随着树的增大,扫描整个树的查询会变得越来越慢。
- 缓存: 将频繁访问的层次结构缓存在应用内存中。
- 归档: 将层次结构中的历史或不活跃部分移至归档表中。
- 分区: 如果数据量巨大,按根类别对表进行分区。
📝 最佳实践摘要
为确保自引用实体的稳健实现,请遵循以下指南。
- 使用代理键: 优先为主键使用自增整数,而非业务键。
- 允许空值: 确保外键列允许根节点为空值。
- 为外键建立索引: 始终为存储父级引用的列建立索引。
- 验证循环: 实现检查以防止循环引用(A -> B -> A)。
- 限制递归: 限制查询中的递归深度,以防止栈溢出。
- 记录模式: 在你的ERD文档中明确标注哪些列是自引用的。
- 规划删除操作: 明确定义在父级删除时的级联删除规则或设置为空值的规则。
- 测试深层层级: 使用至少10层深度的查询进行测试,以确保性能稳定。
🔮 未来考量
数据库技术持续演进。尽管自引用实体的概念保持不变,但管理它的工具正在不断改进。
- 图数据库: 某些现代系统将关系视为一等公民。它们原生地处理递归路径,无需复杂的SQL。
- JSON支持: 更新的数据库引擎允许在JSON列中存储层次化数据,这可以简化深层嵌套结构的模式设计。
- ORM改进: 对象关系映射器在自动处理递归关系方面越来越出色,减少了样板代码。
尽管有这些进步,递归关系的核心逻辑仍然不变。理解主键、外键和表关系的底层机制,对于任何从事数据结构工作的技术人员都至关重要。
通过遵循这些原则,你可以构建出足够灵活以处理复杂层级结构,同时保持高性能和可维护性的系统。只要使用得当,自引用实体就是你数据建模工具箱中的强大工具。