











Die Datenbankarchitektur beginnt mit einer Vision. Bevor ein einziger Codezeile geschrieben wird, müssen Datenstrukturen konzipiert, organisiert und validiert werden. Das Entity-Relationship-Diagramm (ERD) dient als Bauplan für diese Struktur und übersetzt realweltliche Anforderungen in ein visuelles Modell. Ein Diagramm allein speichert jedoch keine Daten. Das logische Schema ist die greifbare Implementierung, die steuert, wie Informationen physisch gespeichert, abgerufen und gesichert werden.
Der Übergang von dem abstrakten ERD zum konkreten Schema erfordert Präzision. Dabei werden Entitäten auf Tabellen, Beziehungen auf Schlüssel und Attribute auf Spalten abgebildet. Dieser Prozess bestimmt die Integrität und Leistungsfähigkeit des gesamten Systems. Das Verständnis der Feinheiten dieser Übersetzung stellt sicher, dass die Datenbank auch unter Last stabil bleibt und sich zukünftigen Anforderungen anpassen lässt.
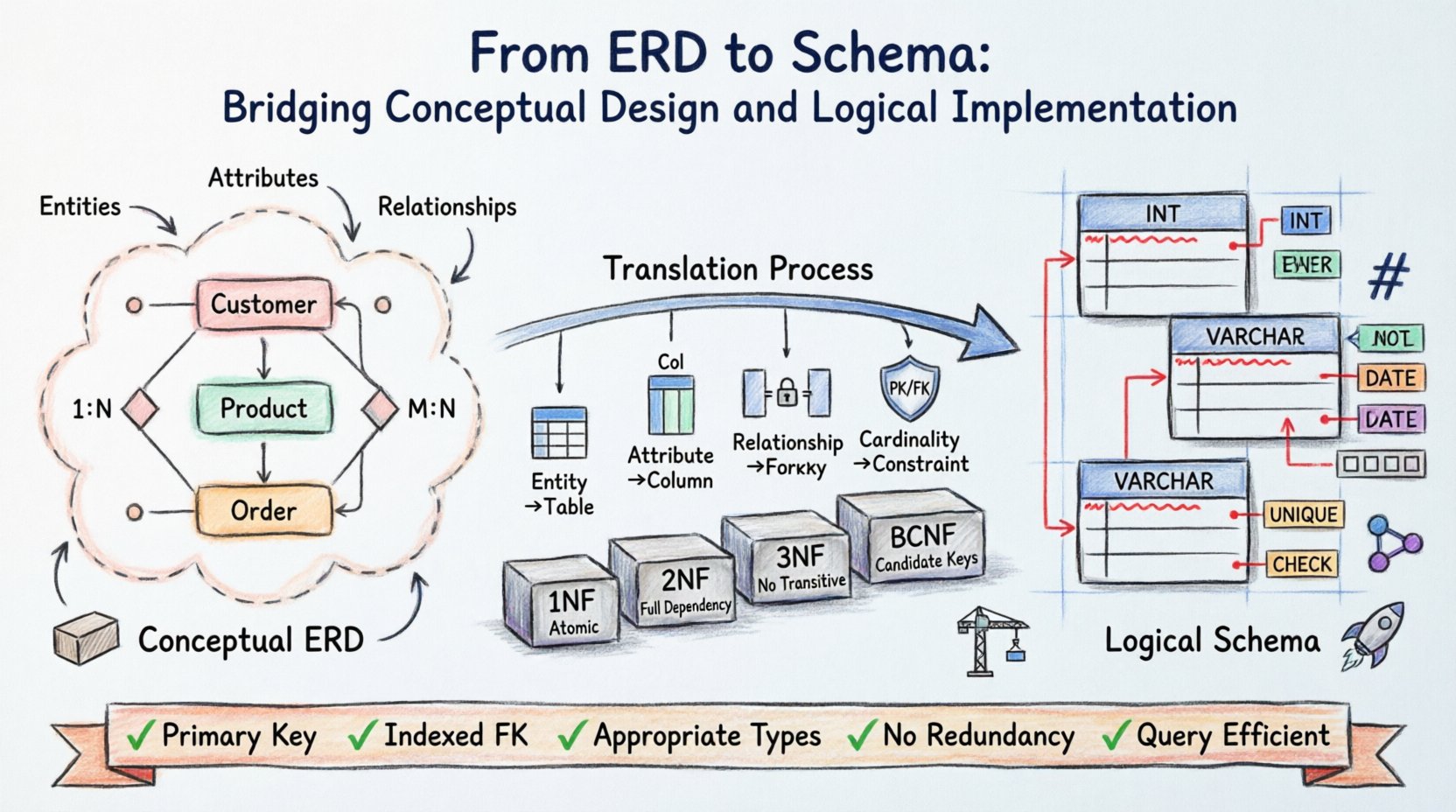
Das Verständnis der konzeptuellen Grundlage 🧱
Das Entity-Relationship-Diagramm arbeitet auf konzeptueller Ebene. Es konzentriert sich auf das „Was“ statt auf das „Wie“. In dieser Phase identifizieren Stakeholder und Architekten die zentralen Objekte innerhalb des Bereichs.
- Entitäten: Diese stellen unterschiedliche Objekte oder Konzepte dar, wie beispielsweise ein Kunde, Produkt oder Auftrag.
- Attribute: Diese definieren die Eigenschaften einer Entität, wie beispielsweise Name, Preis oder Datum.
- Beziehungen: Diese beschreiben, wie Entitäten miteinander interagieren, beispielsweise ein Kunde, der einen Auftrag aufgibt.
In diesem Stadium sind technische Einschränkungen sekundär. Ziel ist Klarheit. Wenn das konzeptionelle Modell mehrdeutig ist, wird das resultierende Schema fehlerhaft sein. Häufige Fehler bestehen darin, Attribute mit Entitäten zu verwechseln oder die Kardinalität nicht korrekt zu definieren.
Kardinalität und Beteiligung
Eine der entscheidenden Aspekte der ERD-Design ist die Definition der Kardinalität. Diese bestimmt die quantitative Beziehung zwischen Entitäten.
- Ein-zu-eins (1:1): Ein Datensatz in Tabelle A steht genau mit einem Datensatz in Tabelle B in Beziehung.
- Ein-zu-viele (1:N): Ein Datensatz in Tabelle A steht mit mehreren Datensätzen in Tabelle B in Beziehung.
- Viele-zu-viele (M:N): Mehrere Datensätze in Tabelle A stehen mit mehreren Datensätzen in Tabelle B in Beziehung.
Teilnahme-Beschränkungen verfeinern dieses Modell weiter. Ist die Beziehung obligatorisch oder optional? Wenn ein Kunde einen Auftrag stellen muss, ist die Beteiligung obligatorisch. Wenn er auch ohne Auftrag existieren kann, ist sie optional. Diese Unterscheidungen beeinflussen direkt die Zulässigkeit von NULL-Werten in Spalten des logischen Schemas.
Das logische Schema: Strukturelle Implementierung 🏗️
Das logische Schema schließt die Lücke zwischen Theorie und physischer Speicherung. Während das ERD plattformunabhängig ist, bereitet das logische Schema die Daten für spezifische Speichermechanismen vor. Diese Ebene führt spezifische Regeln hinsichtlich Datentypen, Einschränkungen und Normalisierung ein.
Im Gegensatz zum konzeptionellen Modell muss das logische Schema die Datenintegrität explizit berücksichtigen. Dies wird durch Primärschlüssel, Fremdschlüssel und eindeutige Einschränkungen erreicht. Diese Regeln verhindern verwaiste Datensätze und stellen sicher, dass Beziehungen konsistent bleiben.
Schlüsselübersetzungsregeln
Die Übersetzung von Schlüsseln vom ERD zum Schema erfordert strikte Einhaltung der relationalen Theorie.
- Primärschlüssel: Jede Entität muss einen eindeutigen Bezeichner haben. Im ERD wird dies oft unterstrichen. Im Schema wird daraus die PRIMARY KEY-Beschränkung.
- Fremdschlüssel: Beziehungen werden über Fremdschlüssel implementiert. Eine Viele-zu-viele-Beziehung erfordert typischerweise eine assoziative Tabelle mit zwei Fremdschlüsseln, um die Kardinalität aufzulösen.
- Komposite Schlüssel: Wenn eine Entität auf mehrere Attribute für Eindeutigkeit angewiesen ist, müssen diese in der logischen Definition kombiniert werden.
Zuordnung von Entitäten zu Tabellen 🔄
Der Prozess der Umwandlung einer Entität in eine Tabelle ist einfach, erfordert aber Aufmerksamkeit für die Details. Jede Entität wird im Allgemeinen einer Tabelle zugeordnet. Komplexe Szenarien erfordern jedoch möglicherweise eine Aufteilung oder Zusammenführung.
Behandlung von Spezialisierung und Generalisierung
Wenn Entitäten gemeinsame Attribute teilen, können sie als Unterklassen modelliert werden. Zum Beispiel hat eine FahrzeugEntität Unterklassen wie Auto und LKW.
Es gibt zwei Hauptstrategien, dies in einem Schema umzusetzen:
- Einzelne Tabellenvererbung: Alle Unterklassen werden in einer einzigen Tabelle mit einer Unterscheidungsspalte gespeichert. Dies reduziert Joins, erhöht aber NULL-Werte.
- Klassentabellenvererbung: Jede Unterklasse erhält ihre eigene Tabelle, die über eine Fremdschlüsselverbindung mit der Elternklasse verknüpft ist. Dies ist normalisierter, erfordert aber komplexere Abfragen.
Attributzuordnung
Attribute aus dem ERD müssen Spaltendefinitionen zugeordnet werden. Nicht alle Attribute lassen sich direkt übersetzen.
- Einfache Attribute: Werden direkt auf Spalten abgebildet.
- Komposite Attribute: Müssen in einzelne Spalten aufgeteilt werden (z. B. Adressen werden in Straße, Stadt, PLZ aufgeteilt).
- Mehrwertige Attribute: Können nicht in einer einzigen Spalte gespeichert werden. Dafür ist eine separate Tabelle erforderlich, die über einen Fremdschlüssel verknüpft ist (z. B. Telefonnummern für einen Benutzer).
- Abgeleitete Attribute: Diese werden aus anderen Daten berechnet (z. B. Alter aus Geburtsdatum). Sie werden oft aus dem Schema weggelassen, um Redundanz zu vermeiden, es sei denn, eine Leistungs-Optimierung ist entscheidend.
Normalisierung im Detail 📊
Die Normalisierung ist der Prozess der Datenorganisation zur Reduzierung von Redundanz und Verbesserung der Integrität. Beim Übergang vom ERD zum Schema müssen Designer sicherstellen, dass das Modell bestimmten Normalformen entspricht.
Erste Normalform (1NF)
Eine Tabelle befindet sich in 1NF, wenn sie atomare Werte enthält. Keine Spalte sollte eine Liste oder eine Menge von Werten enthalten. Wenn eine Entität mehrere Werte für ein einzelnes Attribut hat, muss eine neue Tabelle erstellt werden.
Zweite Normalform (2NF)
2NF erfordert, dass die Tabelle in 1NF ist und keine partiellen Abhängigkeiten aufweist. Alle Nicht-Schlüsselattribute müssen auf den gesamten Primärschlüssel, nicht nur auf einen Teil davon, abhängen. Dies ist entscheidend für Tabellen mit zusammengesetzten Schlüsseln.
Dritte Normalform (3NF)
3NF erfordert, dass keine transitiven Abhängigkeiten bestehen. Ein Nicht-Schlüsselattribut sollte nicht von einem anderen Nicht-Schlüsselattribut abhängen. Zum Beispiel, wenn Stadt hängt ab von Postleitzahl, und Postleitzahl hängt ab von Kunden-ID, Stadt sollte in eine separate Tabelle verschoben werden.
Boyce-Codd-Normalform (BCNF)
BCNF ist eine strengere Version von 3NF. Sie behandelt Fälle, in denen eine Tabelle mehrere Kandidatenschlüssel hat und ein Nicht-Schlüsselattribut von einer Teilmenge dieser Schlüssel abhängt.
| Normalform | Anforderung | Schwerpunkt |
|---|---|---|
| 1NF | Atomare Werte | Wiederholungsgruppen beseitigen |
| 2NF | Vollständige Abhängigkeit | Partielle Abhängigkeiten beseitigen |
| 3NF | Keine transitive Abhängigkeit | Indirekte Abhängigkeiten beseitigen |
| BCNF | Kandidatenschlüssel-Abhängigkeit | Überlappende Schlüssel beseitigen |
Datenarten und Einschränkungen 🔒
Die Auswahl der richtigen Datenart ist entscheidend für Speichereffizienz und Abfrageleistung. Der ERD gibt selten genaue Datenarten an, was diese Entscheidung in die Phase der logischen Gestaltung verlegt.
Ganzzahl vs. Numerisch
Ganzzahlen speichern ganze Zahlen und sind für Berechnungen schneller. Numerische oder Dezimaltypen werden für Finanzdaten verwendet, um Genauigkeit zu bewahren. Die Verwendung von Ganzzahlen für Währungen kann zu Rundungsfehlern führen.
Datum und Uhrzeit
Zeitstempel sollten zwischen UTC und lokaler Zeit unterscheiden. Das Speichern von Daten als Zeichenketten ist ein häufiger Fehler, der eine effiziente Sortierung und Filterung verhindert. Verwenden Sie die standardmäßigen Datentypen, die von der Datenbankengine bereitgestellt werden.
Einschränkungen
Einschränkungen setzen Geschäftsregeln auf Datenbankebene durch.
- NICHT NULL:Stellt sicher, dass eine Spalte immer einen Wert enthält.
- EINDEUTIG:Verhindert doppelte Werte in einer Spalte.
- ÜBERPRÜFEN:Überprüft Daten anhand einer bestimmten Bedingung (z. B. Alter > 0).
- Standardwert:Stellt einen Rückfallwert bereit, falls kein anderer Wert angegeben wird.
Häufige Fehlerquellen und Überprüfung ⚠️
Selbst mit einem soliden Plan können Fehler während der Umsetzung auftreten. Die frühzeitige Erkennung dieser Fehlerquellen spart später erheblich Zeit.
- Über-Normalisierung:Die Erstellung zu vieler Tabellen kann Abfragen langsam und komplex machen. Eine De-Normalisierung kann bei Lese-lastigen Workloads notwendig sein.
- Schwache Schlüssel:Die Verwendung natürlicher Schlüssel (wie E-Mail-Adressen) als Primärschlüssel ist riskant. Sie können sich ändern und zu kaskadierenden Problemen führen. Fremdschlüssel (Auto-Increment-IDs) sind oft sicherer.
- Fehlende Indizes:Fremdschlüssel sollten indiziert werden. Ohne sie wird das Verknüpfen von Tabellen zu einer Leistungsbremse.
- Zirkuläre Abhängigkeiten:Es ist entscheidend, sicherzustellen, dass Tabellen keine Schleifen in Beziehungen erzeugen, um die Referenzintegrität aufrechtzuerhalten.
Überprüfungsliste
Bevor Sie das Schema endgültig festlegen, durchlaufen Sie diese Überprüfungsliste:
- Hat jede Tabelle einen Primärschlüssel?
- Sind alle Fremdschlüssel ordnungsgemäß indiziert?
- Sind die Datentypen für das erwartete Datenvolumen geeignet?
- Gibt es überflüssige Spalten, die entfernt werden können?
- Unterstützt das Schema die erforderlichen Abfragen effizient?
Leistungsüberlegungen 🚀
Das logische Schema geht nicht nur um Richtigkeit, sondern auch um Geschwindigkeit. Mit wachsenden Daten muss die Struktur eine zunehmende Last bewältigen können.
Partitionierung
Große Tabellen können in kleinere, übersichtlichere Teile aufgeteilt werden. Dies kann horizontal (nach Zeilen) oder vertikal (nach Spalten) erfolgen. Die Partitionierung ermöglicht es Abfragen, nur die relevanten Datenabschnitte zu erreichen.
Architekturelle Muster
Entwurfsmuster wie Sharding verteilen Daten über mehrere Server. Dazu ist eine sorgfältige Planung während der logischen Entwurfsphase erforderlich, um sicherzustellen, dass verwandte Daten möglichst zusammenbleiben.
Zusammenfassung der Best Practices ✅
Das Erstellen eines Datenbank-Schemas ist ein iterativer Prozess. Es erfordert ein Gleichgewicht zwischen theoretischer Reinheit und praktischen Einschränkungen.
- Dokumentieren Sie alles:Pflegen Sie klare Dokumentation, die ERD-Elemente mit Schema-Definitionen verknüpft.
- Versionskontrolle:Behandeln Sie Schema-Änderungen wie Code. Verwenden Sie Migrations-Skripte, um Änderungen im Laufe der Zeit zu verfolgen.
- Überprüfen Sie regelmäßig:Wie sich die geschäftlichen Anforderungen entwickeln, sollte auch das Schema sich anpassen. Planen Sie regelmäßige Audits, um die Übereinstimmung mit den aktuellen Anforderungen sicherzustellen.
- Kooperieren Sie:Beteiligen Sie Entwickler, Analysten und Stakeholder frühzeitig. Verschiedene Perspektiven bringen Randfälle ans Licht, die ein einzelner Designer übersehen könnte.
Der Übergang von der Entitäts-Beziehungs-Diagramm zum logischen Schema ist die Grundlage der Dateningenieurwissenschaft. Er verwandelt abstrakte Ideen in ein funktionierendes System. Durch Einhaltung der Normalisierungsregeln, Auswahl geeigneter Datentypen und Berücksichtigung von Leistungsanforderungen wird die resultierende Datenbank zu einer zuverlässigen Grundlage für Anwendungen.
Letztendlich bestimmt die Qualität des Schemas die Haltbarkeit des Systems. Eine gut strukturierte Gestaltung minimiert technischen Schulden und erleichtert zukünftiges Wachstum. Konzentrieren Sie sich auf Klarheit, Integrität und Skalierbarkeit, um Systeme zu bauen, die der Zeit standhalten.