











Datenbankmodelle bilden die Grundlage jeder robusten Anwendung. Wenn Entitäten, Beziehungen und Attribute sich weiterentwickeln, muss das zugrundeliegende Schema sich anpassen, ohne die Datenintegrität zu gefährden. Dieser Leitfaden untersucht die Disziplin des Managements von Änderungen am Entity-Relationship-Diagramm (ERD) durch Versionskontrolle. Wir werden untersuchen, wie Konsistenz gewahrt, die Historie verfolgt und effektiv über Teams hinweg zusammengearbeitet werden kann.
Moderne Entwicklungszyklen erfordern Geschwindigkeit, aber die Datenstabilität darf nicht auf Kosten der Geschwindigkeit opfern werden. Ein Datenbankschema ist nicht einfach nur eine Sammlung von Tabellen; es ist ein Vertrag zwischen der Anwendung und dem dauerhaften Speicher. Die Änderung dieses Vertrags ohne angemessene Governance birgt Risiken. Indem man das Datenbankmodell als Code behandelt, können Teams bewährte ingenieurwissenschaftliche Praktiken auf die Dateninfrastruktur anwenden.
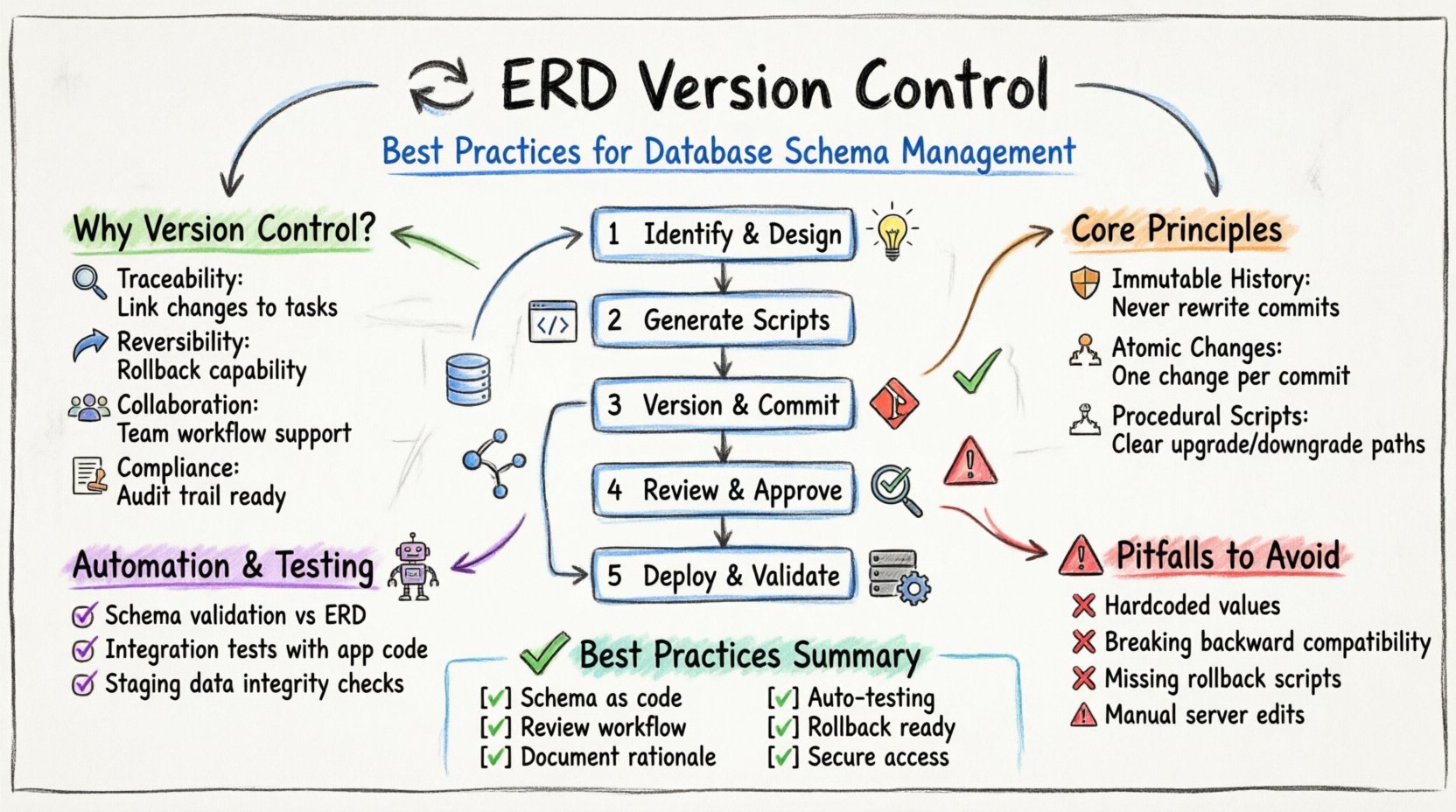
Warum die Versionsverwaltung von Datenbankschemata wichtig ist 🤔
Die Versionskontrolle für Datenbankmodelle wird im Vergleich zu Anwendungscode oft übersehen. Entwickler verwalten die Anwendungslogik häufig in Repositories, während sie Datenbankänderungen als spontane Skripte behandeln. Diese Diskrepanz führt zu technischem Schulden und operativer Fragilität. Ein strukturierter Ansatz für die Schema-Evolution stellt sicher, dass jede Änderung dokumentiert, überprüft und rückgängig gemacht werden kann.
Berücksichtigen Sie die Auswirkungen eines fehlenden Migrations-Skripts. In einer Produktionsumgebung kann eine unerwartete Schemaänderung die gesamte Bereitstellungspipeline stoppen. Ohne eine Historie der Änderungen wird das Debugging zu einem Ratespiel. Existiert diese Spalte letzte Woche noch? Ist der Index absichtlich gelöscht worden? Die Versionskontrolle beantwortet diese Fragen eindeutig.
- Nachvollziehbarkeit: Jede Änderung ist einer bestimmten Anforderung oder Aufgabe zugeordnet.
- Rückgängigmachbarkeit: Wenn eine Änderung Probleme verursacht, kann das System auf einen früheren Zustand zurückgesetzt werden.
- Zusammenarbeit: Mehrere Entwickler können an verschiedenen Teilen des Modells arbeiten, ohne sich gegenseitig zu überschreiben.
- Einhaltung von Vorschriften: Audit-Protokolle erfüllen regulatorische Anforderungen an die Datenverarbeitung und den Zugriff.
Grundprinzipien der Modellstabilität 🛡️
Eine effektive Versionskontrolle beruht auf einer Reihe von Leitprinzipien. Diese Regeln bestimmen, wie Änderungen vorgeschlagen, umgesetzt und zusammengeführt werden. Die Einhaltung dieser Standards minimiert Konflikte und maximiert die Zuverlässigkeit.
1. Unveränderliche Historie
Sobald eine Schema-Version in das Repository committet wurde, sollte sie niemals verändert werden. Selbst wenn ein Fehler entdeckt wird, ist der richtige Ansatz, eine neue Version zu erstellen, die den vorherigen Zustand korrigiert. Die Umgestaltung der Historie verschleiert den Zeitverlauf der Entscheidungen und erschwert die Überprüfung von Änderungen.
2. Atomare Änderungen
Änderungen sollten in kleinen, logischen Einheiten vorgenommen werden. Ein einzelner Commit sollte eine spezifische Anforderung abdecken. Das Zusammenfassen unzusammenhängender Änderungen in einem einzigen Paket erschwert die Isolierung von Problemen. Wenn eine Bereitstellung fehlschlägt, hilft es, die genaue Änderung zu kennen, die das Problem verursacht hat, die Lösung zu beschleunigen.
3. Deklarativ vs. Prozedural
Es gibt zwei Hauptphilosophien zur Darstellung des Schema-Zustands. Ein Ansatz konzentriert sich auf den gewünschten Endzustand (deklarativ), während der andere sich auf die Schritte zur Erreichung dieses Zustands konzentriert (prozedural). Beide haben ihre Vorzüge, aber prozedurale Migrations-Skripte werden oft für Produktionsumgebungen bevorzugt, da sie einen klaren Weg für Upgrade- und Downgrade-Prozesse bieten.
Der Lebenszyklus einer Schema-Änderung 🔄
Die Verwaltung einer ERD-Änderung erfordert einen strukturierten Ablauf. Dieser Prozess führt ein Konzept von einem Diagramm in einer Modellierungstool zu einem validierten Zustand in einer laufenden Datenbank. Die Einhaltung dieses Lebenszyklus stellt sicher, dass kein Schritt ausgelassen wird.
Schritt 1: Identifikation und Gestaltung
Der Prozess beginnt mit der Identifikation des Bedarfs an einer Änderung. Dies könnte eine neue Tabelle für eine Funktion, eine Aufteilung einer bestehenden Tabelle oder eine Änderung einer Beziehung sein. Die Gestaltung sollte in dem ERD-Modellierungstool erfasst werden. In diesem Stadium liegt der Fokus auf logischer Konsistenz, nicht auf physischen Implementierungsdetails.
- Definieren Sie die Entität und ihre Attribute eindeutig.
- Legen Sie Primär- und Fremdschlüssel fest.
- Überprüfen Sie Einschränkungen auf Datenintegrität.
- Dokumentieren Sie die Begründung für die Änderung.
Schritt 2: Skriptgenerierung
Sobald das logische Modell genehmigt ist, muss es in ausführbare Skripte übersetzt werden. Hierbei werden SQL-Anweisungen generiert, die Datenbankobjekte erstellen, ändern oder löschen. Es ist entscheidend, sicherzustellen, dass diese Skripte so weit wie möglich idempotent sind, was bedeutet, dass sie mehrfach ausgeführt werden können, ohne Fehler zu verursachen.
Schritt 3: Versionsverwaltung und Committen
Die Skripte werden dem Versionskontrollsystem hinzugefügt. Jedes Skript sollte eine eindeutige Kennung besitzen, oft eine Zeitmarke oder eine Sequenznummer. Die Commit-Nachricht muss die Änderung ausführlich beschreiben und auf die zugehörige Aufgabe oder das zugehörige Problem verweisen. Dadurch entsteht eine klare Verbindung zwischen dem Code und den Daten.
Schritt 4: Überprüfung und Genehmigung
Bevor die Änderungen zusammengeführt werden, müssen sie von Kollegen überprüft werden. Dieser Schritt ist entscheidend, um logische Fehler zu erkennen, die automatisierte Werkzeuge möglicherweise übersehen. Die Überprüfer sollten auf Namenskonventionen, Constraint-Definitionen und mögliche Leistungseinbußen achten. Ein formeller Genehmigungsprozess verhindert, dass unautorisierte Änderungen in den Hauptzweig gelangen.
Schritt 5: Bereitstellung und Validierung
Der letzte Schritt besteht darin, die Änderungen in die Zielumgebung anzuwenden. Dies erfolgt typischerweise über eine automatisierte Pipeline. Die Validierung nach der Bereitstellung stellt sicher, dass das Schema dem erwarteten Zustand entspricht. Dazu können Abfragen zur Überprüfung der Spaltenanzahl oder die Prüfung von Datenintegritätsbedingungen gehören.
Umgang mit gleichzeitiger Entwicklung und Konflikten ⚔️
Bei Teams mit mehreren Entwicklern finden Schemaänderungen oft gleichzeitig statt. Wenn zwei Personen dieselbe Tabelle oder Beziehung ändern, entsteht ein Konflikt. Die Lösung dieser Konflikte erfordert einen systematischen Ansatz.
Die Konfliktlösung geht nicht nur darum, Texte zusammenzuführen, sondern darum, Datenstrukturen zu vereinen. Das Zusammenführen zweier ERDs ist komplexer als das Zusammenführen zweier Quellcode-Dateien. Sie müssen sicherstellen, dass das kombinierte Modell weiterhin logisch sinnvoll ist.
- Kommunikation:Entwickler sollten sich vor Änderungen an gemeinsam genutzten Entitäten abstimmen.
- Branching-Strategie:Verwenden Sie Feature-Branches, um Änderungen zu isolieren. Führen Sie diese Branches vor der Produktion in einen gemeinsam genutzten Integrations-Branch zusammen.
- Manueller Merge:Automatisierte Werkzeuge kämpfen oft mit Schema-Konflikten. Häufig ist menschliches Eingreifen erforderlich, um Unterschiede auszugleichen.
- Konfliktlösung:Wenn ein Konflikt auftritt, muss das Team entscheiden, welche Version der Änderung Vorrang hat. Diese Entscheidung sollte dokumentiert werden.
Häufige Konfliktszenarien
| Szenario | Beschreibung | Lösungsstrategie |
|---|---|---|
| Spaltenumbenennung | Zwei Entwickler benennen die gleiche Spalte unterschiedlich um. | Einheitliche Namenskonvention festlegen und auf den vereinbarten Namen zurückkehren. |
| Tabellenlöschung | Ein Entwickler löscht eine Tabelle, die ein anderer bearbeitet. | Stellen Sie sicher, dass alle Abhängigkeiten vor der Löschung entfernt werden. Rollen Sie die Löschung zurück, falls die Tabelle weiterhin benötigt wird. |
| Datenmigration | Skripte bewegen Daten in widersprüchliche Richtungen. | Kombinieren Sie die Logik in einem einzigen Skript, das alle Transformationen korrekt verarbeitet. |
| Hinzufügen von Einschränkungen | Zwei Entwickler fügen Einschränkungen in dieselbe Spalte ein. | Führen Sie die Einschränkungen zusammen, wenn sie kompatibel sind, oder konsolidieren Sie sie in einer einzigen Einschränzungsdefinition. |
Automatisierung der Validierung und Prüfung 🤖
Manuelle Tests sind fehleranfällig. Die Automatisierung stellt sicher, dass Schemaänderungen Qualitätsstandards erfüllen, bevor sie bereitgestellt werden. Die Integration in eine Continuous-Integration-Pipeline ermöglicht sofortige Rückmeldung bei jedem Commit.
Schema-Validierung
Automatisierte Tools können den generierten SQL-Code mit dem ERD-Modell überprüfen. Dadurch wird sichergestellt, dass die physische Implementierung der logischen Gestaltung entspricht. Jede Abweichung löst einen Fehler in der Build-Pipeline aus und warnt den Entwickler sofort.
Integrationstest
Schemaänderungen sollten gegen den Anwendungscode getestet werden. Wenn eine Spalte entfernt wird, sollte die Anwendung fehlschlagen, wenn sie weiterhin auf diese Spalte verweist. Diese Verknüpfung verhindert, dass gravierende Änderungen unentdeckt bleiben.
Prüfung der Datenintegrität
Die Durchführung der Migration auf einer Staging-Datenbank mit produktionsähnlichen Datenmengen hilft, Leistungsprobleme zu identifizieren. Langlaufende Abfragen oder Lock-Konflikte können erkannt werden, bevor sie Live-User beeinträchtigen. Dieser Schritt ist für großskalige Datenbankumgebungen unerlässlich.
Dokumentation und Audit-Trails 📜
Dokumentation ist oft das Erste, was bei sich nähernden Fristen vernachlässigt wird. Für Datenbankmodelle ist Dokumentation jedoch eine Art Versicherung. Sie erklärt das „Warum“ hinter dem „Was“.
Jede Änderung sollte mit einer Beschreibung versehen werden. Diese Beschreibung sollte zusammen mit den Skripten im Versionskontrollsystem gespeichert werden. Sie sollte folgende Fragen beantworten:
- Warum ist diese Änderung notwendig?
- Welche Daten werden betroffen?
- Gibt es Abhängigkeiten von anderen Systemen?
- Wie lange ist die erwartete Ausfallzeit?
Audit-Trails liefern eine Aufzeichnung darüber, wer Änderungen vorgenommen und wann dies geschah. Dies ist für Sicherheit und Compliance von entscheidender Bedeutung. Wenn ein Datenleck auftritt oder eine Abfrage schlecht läuft, hilft die Kenntnis der Quelle der Schemaänderung bei der Fehlerbehebung.
Häufige Fehlerquellen, die vermieden werden sollten 🚫
Selbst mit einem robusten Prozess passieren Fehler. Die Kenntnis häufiger Fehlerquellen hilft Teams, diese zu vermeiden.
Harte Codierung von Werten
Vermeiden Sie die Einbettung umgebungsspezifischer Werte in Migrationsskripte. Ein Skript, das in der Entwicklung funktioniert, könnte in der Produktion fehlschlagen, wenn Pfade oder Anmeldeinformationen hartcodiert sind. Verwenden Sie Konfigurationsmanagement, um diese Unterschiede zu behandeln.
Ignorieren der Abwärtskompatibilität
Gravierende Änderungen sollten so weit wie möglich vermieden werden. Wenn eine Spalte entfernt wird, stellen Sie sicher, dass die Anwendung weiterhin funktioniert. Eine gängige Strategie besteht darin, eine neue Spalte hinzuzufügen, die Daten zu migrieren und die alte Spalte in einer nachfolgenden Version zu deaktivieren.
Fehlende Rollback-Pläne
Jedes Migrationsskript sollte ein entsprechendes Rollback-Skript haben. Wenn eine Bereitstellung fehlschlägt, müssen Sie die Änderung schnell rückgängig machen können. Ohne einen Rollback-Plan kann eine fehlgeschlagene Bereitstellung die Datenbank in einem inkonsistenten Zustand lassen.
Manuelle Skriptbearbeitung
Bearbeiten Sie Datenbankskripte niemals direkt auf dem Server. Nehmen Sie immer Änderungen im Versionskontrollsystem vor und stellen Sie diese bereit. Direkte Änderungen gehen beim Neustart verloren und hinterlassen keine Aufzeichnung der Änderung.
Zusammenfassung der Best Practices 🏁
Die Aufrechterhaltung eines gesunden Datenbankmodells erfordert Disziplin. Es reicht nicht aus, nur Code zu schreiben; die Datenebene muss mit derselben Sorgfalt behandelt werden. Die folgende Tabelle fasst die wichtigsten Erkenntnisse zur Verwaltung von ERD-Änderungen zusammen.
| Bereich | Best Practice |
|---|---|
| Versionsverwaltung | Behandeln Sie das Schema wie Code in einem Repository. |
| Workflow | Verwenden Sie einen definierten Überprüfungs- und Genehmigungsprozess. |
| Testen | Automatisieren Sie Validierungs- und Integrationsprüfungen. |
| Kommunikation | Dokumentieren Sie die Begründung für jede Änderung. |
| Wiederherstellung | Stellen Sie immer Wiederherstellungsskripte bereit. |
| Sicherheit | Beschränken Sie den direkten Zugriff auf Produktionsdatenbanken. |
Durch die Umsetzung dieser Praktiken können Teams das Risiko senken und mehr Vertrauen in ihre Dateninfrastruktur setzen. Ziel ist es, die Datenbank so zuverlässig und vorhersehbar zu gestalten wie den Anwendungscode, der darauf läuft.