










Der Aufbau einer robusten Datenbank beginnt lange bevor der erste Codezeile geschrieben wird. Die Grundlage liegt in der Verständnis der Logik, die die Geschäftsvorgänge antreibt. Wenn Geschäftsanforderungen unklar oder missverstanden sind, wird die resultierende Datenstruktur instabil. Dieser Leitfaden bietet einen strukturierten Ansatz zur Umwandlung von Geschäftsregeln in ein Entitäts-Beziehungs-Diagramm (ERD). Dieser Prozess stellt sicher, dass das Datenbankschema die organisatorischen Anforderungen genau widerspiegelt, ohne sich auf spezifische Werkzeuge oder Plattformen zu verlassen.
Die Übersetzung abstrakter Konzepte in konkrete Datenmodelle erfordert Präzision. Eine Geschäftsregel könnte lauten:„Ein Kunde kann mehrere Bestellungen aufgeben, aber jede Bestellung gehört genau einem Kunden“. Ohne eine korrekte Übersetzung könnte diese Logik bei der Umsetzung verloren gehen oder missverstanden werden. Durch die Anwendung eines systematischen Frameworks können technische Teams Schemata erstellen, die skalierbar, wartbar und mit den operativen Realitäten übereinstimmen.
Verständnis der Kernkomponenten von Geschäftsregeln 🧩
Bevor irgendein Diagramm gezeichnet wird, muss die von den Stakeholdern bereitgestellte Information analysiert werden. Geschäftsregeln sind nicht nur Vorlieben; sie sind Beschränkungen und Definitionen, die steuern, wie Daten verwendet und verarbeitet werden. Sie lassen sich in mehrere Kategorien einteilen, die jeweils unterschiedlich auf die Datenbankgestaltung einwirken.
- Strukturelle Regeln: Definieren, welche Daten existieren. Zum Beispiel: „Jeder Mitarbeiter muss eine eindeutige ID-Nummer haben.“
- Prozedurale Regeln: Definieren, wie Daten behandelt werden. Zum Beispiel: „Bestellungen über 1000 US-Dollar erfordern die Genehmigung eines Managers, bevor sie versandt werden.“
- Zustandsregeln: Definieren Bedingungen, die für bestimmte Aktionen erfüllt sein müssen. Zum Beispiel: „Ein Konto kann nicht geschlossen werden, wenn das Guthaben nicht null ist.“
- Transformationenregeln: Definieren, wie Daten sich verändern. Zum Beispiel: „Steuersätze müssen neu berechnet werden, wenn sich die Lieferadresse ändert.“
Das Erkennen dieser Unterschiede hilft dabei, festzustellen, wo sie im Datenmodell ihren Platz finden. Strukturelle Regeln werden oft zu Entitäten und Attributen. Prozedurale Regeln könnten zu Triggern oder gespeicherten Prozeduren werden, beeinflussen aber gleichzeitig die Beziehungen zwischen Tabellen. Zustandsregeln legen oft Beschränkungen und Validierungslogik fest.
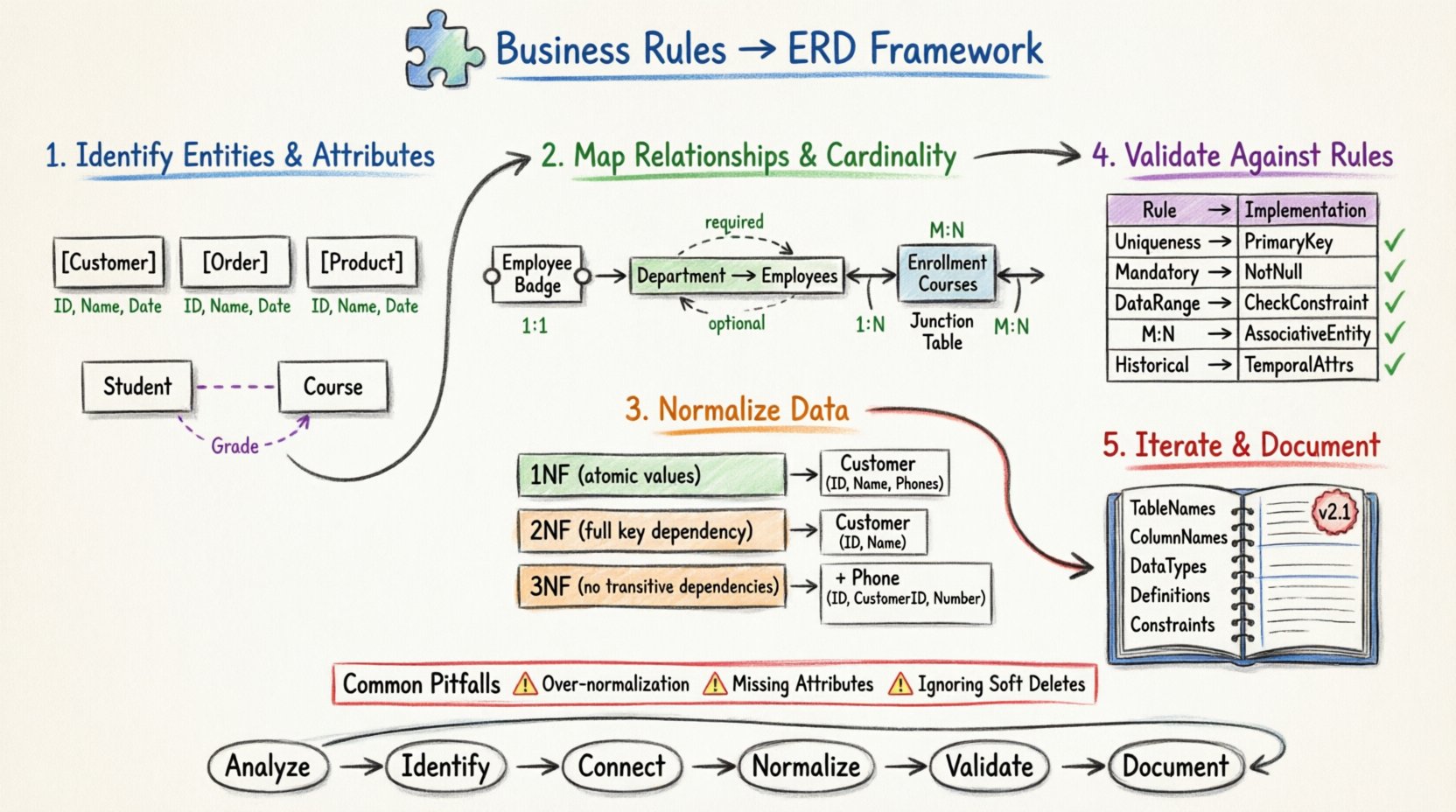
Schritt 1: Identifizierung von Entitäten und Attributen 🏢
Der erste wichtige Schritt im Datenmodellieren besteht darin, die Substantive innerhalb der Geschäftsregeln zu identifizieren. Diese Substantive stellen typischerweise die Entitäten dar. Entitäten sind Gegenstände oder Konzepte der realen Welt, über die Daten gespeichert werden. Sobald Entitäten identifiziert sind, werden die Adjektive und Beschreibungen, die mit ihnen verbunden sind, zu Attributen.
1.1 Extrahieren potenzieller Entitäten
Überprüfen Sie die Dokumentation oder Interviewprotokolle auf Schlüsselwörter. Suchen Sie nach Substantiven, die häufig erwähnt werden. Zum Beispiel sind in einem Einzelhandelskontext Wörter wieProdukt, Geschäft, Lieferant, undKunde starke Kandidaten.
- Überprüfen Sie den Text: Markieren Sie jedes Substantiv, das ein eindeutiges Objekt darstellt.
- Doppelte filtern: Stellen Sie sicher, dass „Artikel“ und „Produkt“ nicht als separate Entitäten behandelt werden, wenn sie auf dasselbe Konzept verweisen.
- Auf Assoziationen prüfen: Einige Substantive können Attribute anderer sein. „Adresse“ ist oft ein Attribut von „Kunde“, keine separate Entität, es sei denn, das System verfolgt mehrere Adressen pro Kunde.
1.2 Definieren von Attributen
Sobald Entitäten festgelegt sind, definieren Sie die Datenpunkte, die sie beschreiben. Attribute liefern die Details, die zur Identifizierung und Beschreibung der Entität erforderlich sind.
- Primärschlüssel: Identifizieren Sie den eindeutigen Bezeichner für jede Entität. Dies ist entscheidend für die Datenintegrität.
- Beschreibende Attribute: Listen Sie die Eigenschaften wie Namen, Daten oder Beschreibungen auf.
- Berechnete Attribute: Notieren Sie Werte, die abgeleitet werden müssen, obwohl diese oft in der Anwendungsschicht behandelt werden.
Berücksichtigen Sie die Regel: „Ein Student meldet sich für eine Veranstaltung an und erhält eine Note.“
- Entitäten:Student, Veranstaltung, Einschreibung.
- Attribute:Studenten-ID, Name, Veranstaltungs-ID, Titel, Note, Anmeldedatum.
Beachten Sie, dass Note ist kein Attribut von Student oder Veranstaltung allein. Es ist spezifisch für die Beziehung zwischen ihnen. Diese Erkenntnis führt oft zur Erstellung einer assoziativen Entität.
Schritt 2: Abbildung von Beziehungen und Kardinalität 🔗
Beziehungen definieren, wie Entitäten miteinander interagieren. Die häufigste Quelle von Fehlern bei der Datenmodellierung entsteht, wenn Beziehungen nicht eindeutig definiert sind oder die Kardinalität missverstanden wird. Die Kardinalität legt fest, wie viele Instanzen einer Entität mit Instanzen einer anderen Entität in Beziehung stehen können oder müssen.
2.1 Identifizieren von Beziehungen
Suchen Sie nach Verben in den Geschäftsregeln. Verben deuten oft auf die Beziehung zwischen Entitäten hin. Häufige Verben sind weist zu, enthält, beschäftigt, oder kauft.
- Ein-zu-eins (1:1): Eine Instanz der Entität A steht in Beziehung zu genau einer Instanz der Entität B. Beispiel: Ein Mitarbeiter hat genau ein Ausweiskarte.
- Ein-zu-viele (1:N): Eine Instanz der Entität A steht in Beziehung zu vielen Instanzen der Entität B. Beispiel: Eine Abteilung beschäftigt viele Mitarbeiter.
- Viele-zu-viele (M:N): Viele Instanzen der Entität A stehen in Beziehung zu vielen Instanzen der Entität B. Beispiel: Studierende melden sich in vielen Kursen an, und Kurse haben viele Studierende.
2.2 Behandlung von Many-to-Many-Beziehungen
Bei der relationalen Datenbankgestaltung ist eine direkte Viele-zu-viele-Beziehung physisch nicht möglich. Sie muss durch Einführung einer assoziativen Entität (auch als Verknüpfungstabelle oder Brückentabelle bezeichnet) aufgelöst werden.
Wenn eine Geschäftsregel besagt, dass „Ein Bauteil wird in vielen Zusammenstellungen verwendet, und eine Zusammenstellung enthält viele Bauteile“, erfordert die Übersetzung eine neue Entität, wie zum Beispiel Zusammenstellung_Bauteil_Nutzung. Diese neue Entität enthält die Fremdschlüssel aus beiden Entitäten Bauteil und Zusammenstellung, sowie alle Attribute, die spezifisch für diese Beziehung sind, wie beispielsweise die Menge.
2.3 Bestimmung der Optionalfunktion
Die Kardinalität geht nicht nur um die Anzahl, sondern auch um die Notwendigkeit. Muss die Beziehung bestehen?
- Erforderlich: Eine Beziehung muss bestehen. Beispiel: Eine Bestellung muss einen Kunden haben.
- Optional: Eine Beziehung kann bestehen oder auch nicht. Beispiel: Ein Kunde kann einen Mittelnamen haben oder auch nicht.
Die Dokumentation dieser Unterscheidung verhindert Nullwert-Fehler und stellt sicher, dass die Einschränkungen zur Referenzintegrität korrekt angewendet werden.
Schritt 3: Normalisierung und Anwendung von Einschränkungen ⚖️
Sobald das ursprüngliche Diagramm entworfen ist, muss die Datenstruktur verfeinert werden. Die Normalisierung ist der Prozess der Organisation von Daten, um Redundanz zu reduzieren und die Integrität zu verbessern. Es handelt sich nicht lediglich um eine technische Übung; vielmehr spiegelt sie die Effizienz der Geschäftslogik wider.
3.1 Erste Normalform (1NF)
Alle Attribute müssen atomare Werte enthalten. Es sollten keine sich wiederholenden Gruppen vorhanden sein. Wenn eine Geschäftsregel besagt„Ein Kunde hat mehrere Telefonnummern“, speichern Sie sie nicht in einer einzigen Spalte wiephone_numbers: '555-1234, 555-5678'. Stattdessen erstellen Sie eine separate Zeile oder eine zugehörige Tabelle für Telefonnummern.
3.2 Zweite Normalform (2NF)
Attribute müssen vollständig vom Primärschlüssel abhängen. Wenn eine Entität einen zusammengesetzten Schlüssel hat, darf kein Attribut nur von einem Teil dieses Schlüssels abhängen. Zum Beispiel, wenn ein zusammengesetzter Schlüssel ausStudent_ID undCourse_ID, sollte ein Attribut wieStudent_Name nicht in der Anmeldetabelle gespeichert werden. Es gehört in die Studententabelle.
3.3 Dritte Normalform (3NF)
Attribute müssen unabhängig von anderen Nicht-Schlüssel-Attributen sein. Dies beseitigt transitive Abhängigkeiten. WennStadthängt ab vonPLZ, undPLZist ein Attribut vonAdresse, dann sollteStadtidealerweise in der Adresse-Entität oder einer verknüpften PLZ-Entität gespeichert werden, nicht in mehreren Tabellen dupliziert.
Schritt 4: Überprüfung des Modells anhand der Regeln ✅
Nachdem das Diagramm erstellt ist, muss es validiert werden. Diese Phase stellt sicher, dass das technische Modell von den ursprünglichen geschäftlichen Anforderungen nicht abgewichen ist. Eine Prüfliste ist ein effektives Werkzeug für diese Validierung.
| Geschäftsregeltyp | ERD-Komponente | Validierungsprüfung |
|---|---|---|
| Eindeutigkeitsbeschränkung | Primärschlüssel / Eindeutiger Index | Ist jedes Entität eindeutig identifizierbar? |
| Pflichtbeziehung | Nicht-Null-Beschränkung | Sind Fremdschlüssel dort erforderlich, wo sie notwendig sind? |
| Datenumfang | Prüfbeschränkungen / Datentypen | Stimmen die numerischen Felder mit den erwarteten geschäftlichen Grenzwerten überein? |
| Mehrfache Beziehungen | Assoziative Entität | Sind M:N-Beziehungen in 1:N-Beziehungen aufgelöst? |
| Historische Daten | Zeitliche Attribute | Sind Geltungsdaten enthalten, um Änderungen zu verfolgen? |
Die Überprüfung dieser Tabelle hilft, Lücken zu erkennen. Wenn beispielsweise eine Regel besagt„Preise dürfen nicht negativ sein“, bestätigt die Validierungsprüfung, dass Datentyp und Beschränkungen dies verhindern. Wenn die Regel besagt„Ein Produkt muss einer Kategorie zugeordnet sein“, stellt die Validierungsprüfung sicher, dass der Fremdschlüssel nicht NULL sein darf.
Häufige Fehler bei der Übersetzung 🚧
Selbst erfahrene Modelleure stoßen auf wiederkehrende Probleme. Die Kenntnis dieser häufigen Fehler kann erhebliche Zeit während der Entwicklungsphase sparen.
- Übernormalisierung:Das Aufteilen von Tabellen zu sehr kann zu übermäßigen Joins führen und die Abfrageleistung verlangsamen. Gleichgewicht zwischen Integrität und Leistungsanforderungen herstellen.
- Fehlende Attribute:Auf Beziehungen zu achten, aber die für die Entität benötigten beschreibenden Daten zu vergessen.
- Annahme von 1:1-Beziehungen:Behandlung einer 1:1-Beziehung als einer einzigen Tabelle, obwohl sie getrennt sein sollten, um logische Trennung oder Sicherheit zu gewährleisten.
- Ignorieren von Weichlöschungen:Geschäftsregeln erfordern oft, dass Daten zur Historie beibehalten werden, auch wenn sie als inaktiv markiert sind. Das Modell muss berücksichtigen, dass ein
is_activeFlag oder eine separate Archivtabelle vorhanden ist. - Verwechseln von Attributen mit Entitäten:Behandeln einer Liste von Optionen (z. B. „Status“) als Entität, obwohl sie eine Domänenbeschränkung oder Enum-Wert sein sollte.
Schritt 5: Iteration und Dokumentation 📝
Die Datenbankgestaltung ist selten ein linearer Prozess. Die Anforderungen entwickeln sich weiter, und das ursprüngliche Modell erfordert möglicherweise Anpassungen. Die Dokumentation ist hier entscheidend. Sie dient als Brücke zwischen dem technischen Team und den geschäftlichen Stakeholdern.
5.1 Pflege des Datenwörterbuchs
Ein Datenwörterbuch definiert die Metadaten der Datenbank. Es sollte enthalten:
- Tabellennamen:Einzel- oder Pluralform.
- Spaltennamen:Klare Namenskonventionen (z. B.
customer_idvscust_id). - Daten-Typen: Ganzzahlen, Varchars, Datumsangaben usw.
- Geschäftsdefinitionen:Einfache englische Erklärungen dessen, was die Daten darstellen.
- Beschränkungen:Regeln, die auf die Daten angewendet werden.
5.2 Versionskontrolle für Modelle
Genau wie Anwendungscode sollten Datenmodelle versioniert werden. Änderungen am Schema sollten verfolgt werden. Dadurch wird sichergestellt, dass im Falle einer Regression das Team auf einen früheren Zustand zurückkehren kann, der zu diesem Zeitpunkt mit den Geschäftsregeln übereinstimmte.
Abschließende Gedanken zur Ausrichtung 🎯
Die Übersetzung von Geschäftsregeln in ein Entitäts-Beziehungs-Diagramm ist eine entscheidende Disziplin. Sie erfordert das Zuhören von Stakeholdern, die technische Interpretation ihrer Bedürfnisse und die Erstellung eines Modells, das der Zeit standhält. Eine gut strukturierte Datenbank reduziert technischen Schulden und unterstützt das Wachstum des Unternehmens.
Wenn das Modell den Regeln entspricht, werden Abfragen vorhersehbar, die Berichterstattung genau, und das System wird einfacher zu warten. Die in die Übersetzungsphase gesteckte Anstrengung zahlt sich bei Entwicklung und Wartung aus. Konzentrieren Sie sich bei jedem Schritt auf Klarheit, Konsistenz und Validierung.
Durch die Einhaltung dieses Rahmens können Teams der häufigen Falle entgehen, eine Datenbank zu erstellen, die technisch funktioniert, aber die tatsächlichen Geschäftsabläufe nicht unterstützt. Das Ziel ist nicht nur, Daten zu speichern, sondern Informationen so zu strukturieren, dass Entscheidungsfindung möglich wird.
Zusammenfassung des Rahmens 📋
- Analysieren: Kategorisieren Sie Geschäftsregeln in strukturelle, prozedurale und Zustandsarten.
- Identifizieren: Extrahieren Sie Substantive für Entitäten und Adjektive für Attribute.
- Verbinden: Karten Sie Beziehungen ab und lösen Sie viele-zu-viele-Szenarien.
- Normalisieren: Wenden Sie 1NF, 2NF und 3NF an, um Redundanz zu reduzieren.
- Validieren: Kreuzreferenzieren Sie das Modell mit den ursprünglichen Regeln.
- Dokumentieren: Pflegen Sie ein lebendiges Datenwörterbuch und Versionskontrolle.
Dieser strukturierte Ansatz stellt sicher, dass das resultierende Datenbank-Schema nicht nur eine Sammlung von Tabellen ist, sondern eine Abbildung der Logik und Ziele der Organisation. Er verwandelt abstrakte Anforderungen in ein konkretes Gut, das Effizienz fördert.