











Der Aufbau einer robusten Datenbankinfrastruktur erfordert Präzision bei jedem Entwicklungsstadium. Das Entity-Relationship-Diagramm (ERD) dient als Bauplan für diese Struktur. Es definiert, wie Datenentitäten interagieren, wie Informationen fließen und wie Integrität während des gesamten Systemlebenszyklus gewährleistet wird. Das Überspringen einer gründlichen Überprüfung des ERD kann zu kostspieligen Umgestaltungen, Datenkorruption und Leistungsengpässen führen. Diese Anleitung bietet eine detaillierte, umsetzbare Checkliste, um Ihr Schema zu validieren, bevor Sie sich der Implementierung widmen.
Datenbankarchitekten und Entwickler müssen beim Schema-Design mit kritischem Blick vorgehen. Die Kosten, um einen strukturellen Fehler in der Produktion zu korrigieren, sind erheblich höher als die Anstrengung, ihn in der Entwurfsphase zu beheben. Durch die Einhaltung eines strukturierten Überprüfungsprozesses stellen Teams sicher, dass die resultierende Datenbank die Geschäftslogik unterstützt, den Normalisierungsprinzipien folgt und skalierbar bleibt.
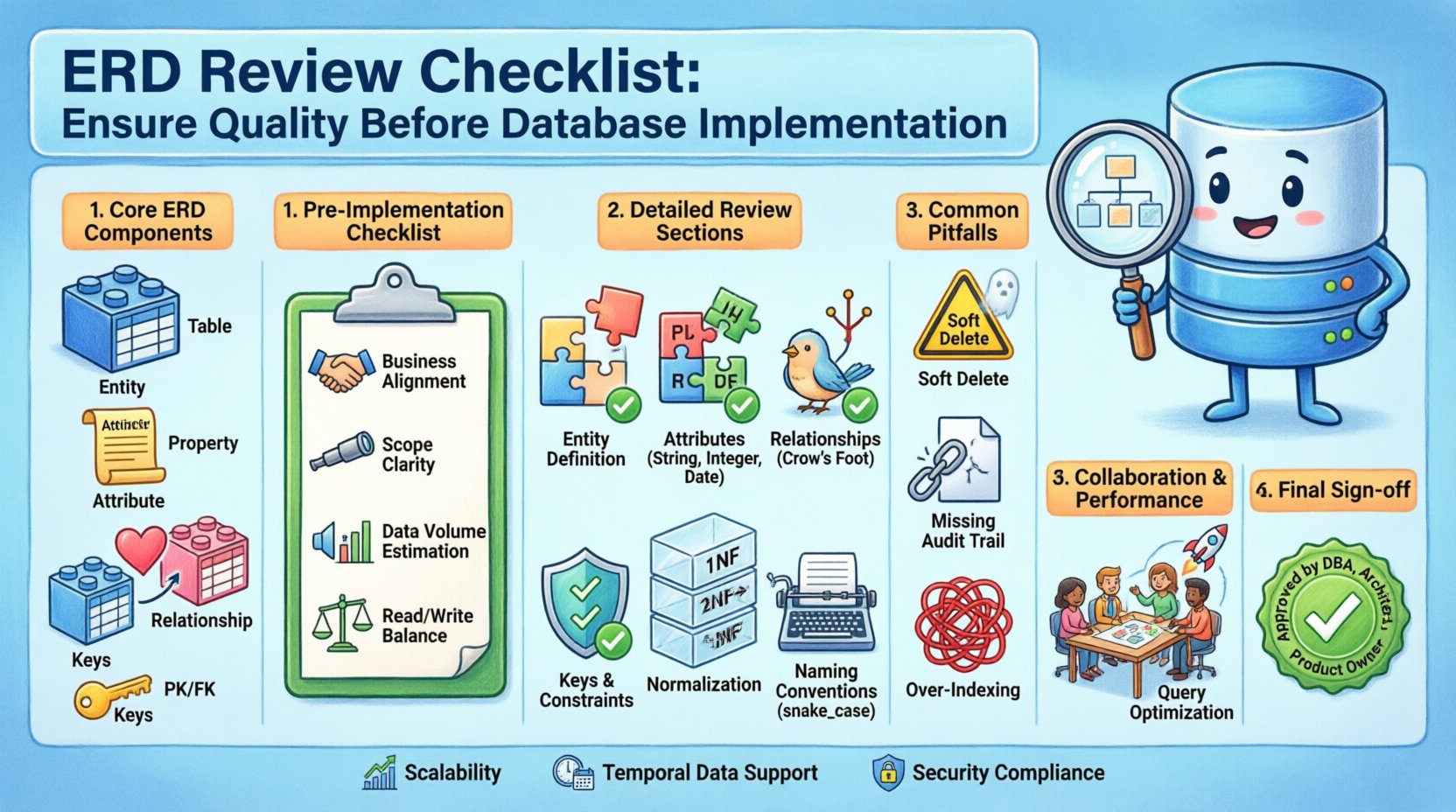
Verständnis der Kernkomponenten eines ERD 🔍
Bevor Sie in die Checkliste einsteigen, ist es unerlässlich, die grundlegenden Bausteine zu verstehen, aus denen ein Standard-Entity-Relationship-Diagramm besteht. Diese Komponenten bilden die Vokabeln Ihres Datenmodells.
- Entitäten: Diese stellen Gegenstände oder Konzepte der realen Welt dar, über die Daten gespeichert werden. Im relationalen Kontext entsprechen Entitäten typischerweise Tabellen.
- Attribute: Diese beschreiben die Eigenschaften oder Merkmale einer Entität. Sie entsprechen Spalten innerhalb einer Tabelle.
- Beziehungen: Diese definieren die Verbindungen zwischen Entitäten. Sie zeigen an, wie Daten in einer Tabelle mit Daten in einer anderen Tabelle verknüpft sind.
- Kardinalitäten und Schlüssel: Die Kardinalität definiert die numerische Beziehung zwischen Entitäten (z. B. ein-zu-eins, viele-zu-viele). Schlüssel sorgen für eindeutige Identifizierung und Verbindung.
Ein hochwertiges ERD muss diese Elemente eindeutig darstellen. Mehrdeutigkeit im Diagramm übersetzt sich direkt in Mehrdeutigkeit im Code und führt zu Implementierungsfehlern.
Validierungsschritte vor der Implementierung ✅
Bevor Sie einzelne Checkliste-Elemente anwenden, muss der Gesamtzusammenhang der Datenbank mit den Geschäftsanforderungen abgestimmt sein. Diese Phase stellt sicher, dass das Modell zweckdienlich ist.
- Ausrichtung an Geschäftsanforderungen: Stellen Sie sicher, dass jede Entität und jede Beziehung einer bestimmten Geschäftsregel oder einem Benutzerstory entspricht.
- Abgrenzung des Umfangs: Bestätigen Sie die Grenzen der Daten. Entwickeln wir für eine einzelne Anwendung, einen Microservice oder ein unternehmensweites Data Warehouse?
- Schätzung des Datenvolumens: Berücksichtigen Sie das erwartete Datenvolumen. Dies beeinflusst Entscheidungen bezüglich Indexierung und Partitionierungsstrategien.
- Lese-/Schreibverhältnis: Verstehen Sie das Arbeitslastprofil. Eine leseschwere Anwendung könnte eine De-Normalisierung erfordern, während ein schreibschweres System eine strikte Integrität priorisiert.
Detaillierte ERD-Überprüfungsliste 📝
Dieser Abschnitt analysiert die spezifischen technischen Attribute, die einer sorgfältigen Prüfung unterzogen werden müssen. Verwenden Sie diese Liste als Überprüfungs-Tool während Ihrer Design-Review-Sitzungen.
1. Definition von Entität und Tabelle
Jede Entität im Diagramm muss eindeutig und gut definiert sein. Ein häufiger Fehler ist die Erstellung überlappender Entitäten, die zusammengeführt werden sollten, oder die unnötige Aufteilung eines einzelnen Konzepts auf mehrere Tabellen.
- Einzigartigkeit: Stellen Sie sicher, dass jede Tabelle ein einzigartiges Konzept darstellt. Vermeiden Sie Tabellen, die ähnliche Daten für unterschiedliche Zwecke speichern, ohne eine klare Unterscheidung.
- Granularität: Überprüfen Sie, ob die Tabellen zu granular sind. Eine übermäßige Aufteilung kann zu komplexen Joins und Leistungsabfall führen.
- Namenskonventionen: Überprüfen Sie die Konsistenz. Tabellen sollten im Singular benannt werden (z. B.
KundeanstattKunden) um mit objektorientierten Abbildungsmustern übereinzustimmen. - Metadaten: Stellen Sie sicher, dass in jeder Tabelle Erstellungs- und Änderungszeitstempel enthalten sind, um Auditing und die Verfolgung der Datenherkunft zu unterstützen.
2. Attribute und Datentypen
Attribute definieren die Art der gespeicherten Daten. Die Auswahl des richtigen Datentyps ist entscheidend für Speichereffizienz und Abfrageleistung.
- Primäre Datentypen: Stellen Sie sicher, dass Ganzzahlen, Zeichenketten und boolesche Werte korrekt verwendet werden. Vermeiden Sie die Verwendung von Zeichenketten für Daten oder Zahlen.
- Längenbeschränkungen: Definieren Sie maximale Längen für Zeichenkettenfelder. Dies verhindert Speicherplatzverschwendung und stellt Konsistenz bei der Eingabeverifizierung sicher.
- Nullableität: Definieren Sie explizit, ob ein Feld null sein darf. Die meisten Felder sollten nicht nullbar sein, es sei denn, die Geschäftslogik erlaubt dies.
- Standardwerte: Überprüfen Sie, ob Standardwerte erforderlich sind. Zum Beispiel könnte ein Statusfeld standardmäßig auf „aktiv“ gesetzt werden, anstatt einen initialen Eintrag zu erfordern.
- Aufzählungswerte: Verwenden Sie bei Gelegenheit aufgezählte Listen, um Werte einzuschränken. Dies verhindert ungültige Dateneingaben am Quellort.
3. Beziehungen und Kardinalität
Beziehungen sind das Bindeglied, das das Datenmodell zusammenhält. Fehler hier führen zu verwaisten Datensätzen oder Daten-Duplikaten.
| Beziehungstyp | Beschreibung | Implementierungshinweis |
|---|---|---|
| Ein-zu-Eins (1:1) | Ein Datensatz in Tabelle A verweist genau auf einen Datensatz in Tabelle B. | Meistens wird dies erreicht, indem der Primärschlüssel von A als Fremdschlüssel in B platziert wird. |
| Ein-zu-Viele (1:N) | Ein Datensatz in Tabelle A verweist auf viele Datensätze in Tabelle B. | Platzieren Sie den Primärschlüssel von A als Fremdschlüssel in B. |
| Viele-zu-Viele (M:N) | Datensätze in A können mit vielen in B verknüpft werden und umgekehrt. | Erfordert eine Verbindungstabelle, die die beiden Primärschlüssel verknüpft. |
- Kardinalitätsprüfung:Überprüfen Sie die Krähenfuß-Notation oder eine äquivalente Darstellung, um sicherzustellen, dass die Richtung der Beziehung korrekt ist.
- Optionalität:Unterscheiden Sie zwischen obligatorischen und optionalen Beziehungen. Eine Fremdschlüsselbeschränkung sollte widerspiegeln, ob ein zugehöriger Datensatz existieren muss.
- Rekursive Beziehungen: Überprüfen Sie auf Selbstverweise in Tabellen (z. B. eine
MitarbeiterTabelle, die auf eineLeiterID innerhalb derselben Tabelle verweist). - Zirkuläre Abhängigkeiten: Stellen Sie sicher, dass Beziehungen keine zirkulären Schleifen erzeugen, die das Laden oder Abfragen von Daten erschweren.
4. Schlüssel und Einschränkungen
Schlüssel sind das Mittel zur Gewährleistung von Eindeutigkeit und Verknüpfung. Ohne geeignete Schlüssel bricht die Datenintegrität zusammen.
- Primärschlüssel: Jede Tabelle muss einen Primärschlüssel besitzen. Er muss eindeutig sein und niemals null sein.
- Surrogatschlüssel: Berücksichtigen Sie die Verwendung von systemgenerierten IDs (Surrogatschlüssel) anstelle natürlicher Geschäftsschlüssel. Dadurch werden Änderungen im Geschäftslogik nicht auf die Datenbankstruktur übertragen.
- Fremdschlüssel: Stellen Sie sicher, dass alle Fremdschlüssel gültige Primärschlüssel in übergeordneten Tabellen referenzieren.
- Eindeutigkeitsbeschränkungen: Identifizieren Sie Felder, die eindeutig sein müssen (z. B. E-Mail-Adressen, Kontonummern), aber kein Primärschlüssel sind.
- Prüfbeschränkungen: Suchen Sie nach logischen Regeln, die nicht allein durch Datentypen erzwungen werden können (z. B.
start_datummuss vorend_datum).
5. Normalisierung
Die Normalisierung reduziert Redundanz und verbessert die Datenintegrität. Während eine Übernormalisierung die Leistung beeinträchtigen kann, führt eine Unterormalisierung zu Anomalien.
- Erste Normalform (1NF):Stellen Sie atomare Werte sicher. Keine wiederholten Gruppen oder Arrays innerhalb einer einzelnen Zelle.
- Zweite Normalform (2NF):Stellen Sie sicher, dass alle nicht-schlüsselbasierten Attribute vollständig vom Primärschlüssel abhängen, nicht nur von einem Teil davon.
- Dritte Normalform (3NF):Stellen Sie sicher, dass keine transitiven Abhängigkeiten bestehen. Nicht-schlüsselbasierte Attribute sollten sich nur vom Primärschlüssel, nicht von anderen nicht-schlüsselbasierten Attributen, ableiten.
- Strategie der De-Normalisierung: Wenn die Leistung ein Problem darstellt, dokumentieren Sie, wo und warum die De-Normalisierung angewendet wird. Dies sollte eine bewusste Entscheidung sein, keine Vernachlässigung.
6. Namenskonventionen
Konsistente Namensgebung reduziert die kognitive Belastung für Entwickler und verringert die Wahrscheinlichkeit von Fehlern.
- Tabellennamen: Verwenden Sie Singular-Nomen (z. B.
Bestellung, nichtBestellungen). - Spaltennamen: Verwenden Sie snake_case zur Konsistenz (z. B.
erstellt_am). - Vermeiden Sie reservierte Wörter: Stellen Sie sicher, dass keine Spaltennamen mit SQL-Schlüsselwörtern kollidieren (z. B.
benutzer,Reihenfolge,Gruppe). - Klarheit: Namen sollten beschreibend sein. Vermeiden Sie Abkürzungen, es sei denn, sie sind branchenüblich.
Häufige Fehler, die vermieden werden sollten ⚠️
Selbst erfahrene Designer können wichtige Details übersehen. Die Kenntnis häufiger Fallen hilft dabei, ein sauberes Schema aufrechtzuerhalten.
- Ignorieren von Weichlöschungen: Entscheiden Sie, ob Daten dauerhaft gelöscht werden müssen oder logisch als inaktiv markiert werden sollen. Ein
is_deletedFlag ist oft sicherer als physische Entfernung. - Fehlende Auditspur: Stellen Sie sicher, dass es eine Möglichkeit gibt, wer Daten geändert hat und wann. Dies ist entscheidend für die Einhaltung von Vorschriften.
- Überindizierung: Zu viele Indizes verlangsamen Schreibvorgänge. Überprüfen Sie die Abfragemuster, um die Platzierung von Indizes zu rechtfertigen.
- Hartkodierte Werte: Vermeiden Sie das Speichern spezifischer Werte wie Ländercodes als Zeichenketten, wenn sie einer Referenztabelle zugeordnet werden können.
- Implizite Annahmen: Nehmen Sie nicht an, dass ein Feld optional ist, wenn die Geschäftslogik es erfordert. Dokumentieren Sie Annahmen klar.
Zusammenarbeit und Dokumentation 🤝
Ein ERD ist nicht nur ein technisches Artefakt; er ist ein Kommunikationsmittel. Er muss von Stakeholdern verstanden werden, nicht nur von Datenbankadministratoren.
- Überprüfung durch Stakeholder: Lassen Sie Geschäftsanalysten das Diagramm überprüfen, um sicherzustellen, dass es ihrem mentalen Modell des Prozesses entspricht.
- Versionskontrolle: Behandeln Sie den ERD wie Code. Speichern Sie ihn in der Versionskontrolle, um Änderungen im Laufe der Zeit nachverfolgen zu können.
- Dokumentation: Fügen Sie eine Datenwörterbuch neben das Diagramm hinzu. Definieren Sie, was jeder Feldwert bedeutet und welcher Wertebereich zulässig ist.
- Änderungsmanagement: Legen Sie einen Prozess für die Änderung des Schemas fest. Änderungen sollten überprüft und genehmigt werden, nicht spontan angewendet werden.
Leistungsüberlegungen 🚀
Obwohl das ERD logisch ist, muss es physischen Leistungszielen entsprechen. Bestimmte Gestaltungsentscheidungen haben direkte Auswirkungen auf die Leistung.
- Komplexität der Verknüpfungen:Minimieren Sie die Anzahl der für häufige Abfragen erforderlichen Verknüpfungen. Komplexe Verknüpfungen können den Abfrage-Optimierer belasten.
- Bereitschaft für Partitionierung: Gestalten Sie Tabellen unter Berücksichtigung der Partitionierung, falls mit einem massiven Wachstum der Datenmenge gerechnet wird.
- Durchsuchbarkeit: Stellen Sie sicher, dass Felder, die häufig durchsucht werden, indiziert sind. Berücksichtigen Sie Anforderungen für Volltextsuche bei textlastigen Feldern.
- Konkurrenzfähigkeit: Bewerten Sie Sperrstrategien. Umgebungen mit hoher Konkurrenz erfordern möglicherweise spezifische Isolationsstufen oder Tabellengestaltungen.
Endgültige Freigabekriterien 🏁
Bevor mit der Umsetzung fortgefahren wird, muss das ERD bestimmten Akzeptanzkriterien entsprechen. Dadurch wird ein reibungsloser Übergang von der Gestaltung zur Entwicklung gewährleistet.
- Vollständigkeit: Alle Entitäten und Beziehungen, die durch den Umfang erforderlich sind, sind vorhanden.
- Konsistenz: Namenskonventionen und Datentypen werden einheitlich angewendet.
- Integrität: Primär- und Fremdschlüsselbeschränkungen sind korrekt definiert.
- Klarheit: Das Diagramm ist für das Ingenieurteam lesbar und verständlich.
- Genehmigung: Schlüsselbeteiligte haben die Gestaltung freigegeben.
Die Einhaltung dieser Checkliste stellt sicher, dass die Datenbankgrundlage solide ist. Sie verringert technische Schulden und erleichtert reibungslosere Entwicklungszyklen. Ein gründlich geprüftes ERD ist der erste Schritt hin zu einer widerstandsfähigen Datenarchitektur.
Überprüfung des ERD auf zukünftige Skalierbarkeit
Die Gestaltung für die Gegenwart reicht nicht aus. Das Datenmodell muss Wachstum ohne vollständige Neugestaltung ermöglichen.
- Horizontales Skalieren: Berücksichtigen Sie, wie Sharding die Beziehungen beeinflussen könnte. Fremdschlüssel über Shards hinweg sind komplex und werden oft vermieden.
- Vertikales Skalieren: Stellen Sie sicher, dass Datentypen größere Werte verarbeiten können. Zum Beispiel die Verwendung von
BIGINTanstattINTfür Zähler. - Feature-Flags: Gestalten Sie Tabellen, um weiche Feature-Flags zu unterstützen. Dadurch kann neue Funktionalität ohne Änderungen am Schema aktiviert oder deaktiviert werden.
- Rückwärtskompatibilität: Planen Sie Schema-Migrationen. Das Hinzufügen von Spalten sollte bestehende Abfragen nicht stören.
Behandlung von Sonderfällen wie zeitbezogene Daten
Zeit ist eine entscheidende Dimension im Datenmodellieren. Die korrekte Behandlung von Historie wird oft übersehen.
- Gültigkeitsdaten: Für Entitäten, die sich im Laufe der Zeit ändern, sollten Start- und Enddaten enthalten sein, um die Historie zu verfolgen.
- Zeitzone: Speichern Sie Zeitstempel in UTC, um Mehrdeutigkeiten über Regionen hinweg zu vermeiden.
- Schnappschüsse: Entscheiden Sie, ob historische Schnappschüsse erforderlich sind. Dies könnte eine separate Historietabelle erfordern.
- Zeitliche Tabellen: Einige Systeme unterstützen native zeitliche Tabellen. Prüfen Sie, ob dies in die architektonischen Anforderungen passt.
Sicherheit und Compliance im Schema
Daten-Sicherheit beginnt auf Tabellenebene. Die Struktur muss Datenschutz- und Schutzanforderungen unterstützen.
- Umgang mit personenbezogenen Daten (PII): Identifizieren Sie Felder mit personenbezogenen Daten. Diese erfordern Verschlüsselung oder Maskierung.
- Zugriffssteuerung: Gestalten Sie Rollen und Berechtigungen basierend auf der in das Schema definierten Datensensibilität.
- Verschlüsselung im Ruhezustand: Stellen Sie sicher, dass die Datenbank-Engine die Verschlüsselung für sensible Felder unterstützt.
- Aufbewahrungsrichtlinien: Definieren Sie Felder, die angeben, wann Daten gemäß gesetzlichen Anforderungen gelöscht werden dürfen.
Durch die strikte Anwendung dieser Überprüfungen wird die Datenbank zu einem zuverlässigen Vermögenswert statt zu einer Belastung. Die Investition in die ERD-Überprüfungsphase zahlt sich in Bezug auf Wartbarkeit und Leistung aus.