



Die Gestaltung eines robusten Datenmodells erfordert mehr als nur die Abbildung von Entitäten und Beziehungen. Es erfordert ein Verständnis dafür, wie sich Daten im Laufe der Zeit entwickeln. In traditionellen Entity-Relationship-Diagrammen (ERDs) erfassen wir oft den Zustand eines Datensatzes zu einem einzigen Zeitpunkt. Wir speichern den aktuellen Wert eines Gehalts, den aktiven Status eines Benutzers oder den neuesten Preis eines Produkts. Doch Geschäftsintelligenz und regulatorische Compliance erfordern oft nicht nur, was aktuell gilt, sondern auch, was in der Vergangenheit galt.
Genau hier setzt die zeitliche Datenmodellierung ein. Sie verwandelt ein statisches Schema in einen dynamischen Verlaufstracker. Indem Sie Zeitdimensionen direkt in Ihr ERD integrieren, stellen Sie sicher, dass jede Änderung dokumentiert, nachvollziehbar und abfragbar ist, ohne den Kontext zu verlieren, zu dem diese Änderungen erfolgt sind. Dieser Leitfaden untersucht die strukturellen Techniken, die erforderlich sind, um zeitbewusste Datenbanksysteme zu entwickeln.
Warum herkömmliche ERDs für die Historie versagen 📉
Ein herkömmliches ERD konzentriert sich auf den aktuellen Zustand. Wenn ein Datensatz aktualisiert wird, wird der alte Wert typischerweise überschrieben. Obwohl dies für einfache operative Systeme funktioniert, erzeugt es erhebliche Blindstellen für analytische Anforderungen. Betrachten Sie eine Situation, in der Sie die Rechnungshistorie eines Kunden über die letzten fünf Jahre rekonstruieren müssen. Eine Standardtabelle könnte nur die aktuelle Adresse oder den aktuellen Abonnement-Tarif anzeigen.
Ohne zeitliche Modellierung stehen Sie vor mehreren Herausforderungen:
- Verlust des Kontexts:Sie können nicht feststellen, wann eine Preiserhöhung in der realen Welt tatsächlich in Kraft trat, im Vergleich zu dem Zeitpunkt, zu dem sie in das System eingegeben wurde.
- Komplexität der Prüfung:Die Erstellung einer separaten Audit-Log-Tabelle erfordert manuelle Trigger-Implementierung und fügt jeder Schreiboperation zusätzlichen Overhead hinzu.
- Abfragekomplexität:Die Rekonstruktion einer Zeitleiste erfordert oft komplexe Joins oder Selbstjoins, die schwer zu pflegen und zu optimieren sind.
- Datenintegrität:Ohne explizite Zeitbeschränkungen ist es leicht, historische Daten versehentlich während Massenaktualisierungen zu überschreiben.
Durch die direkte Einbettung von Zeit in das Schema verschieben Sie die Verantwortung für die Verfolgung der Historie von der Anwendungslogik auf die Datenstruktur selbst.
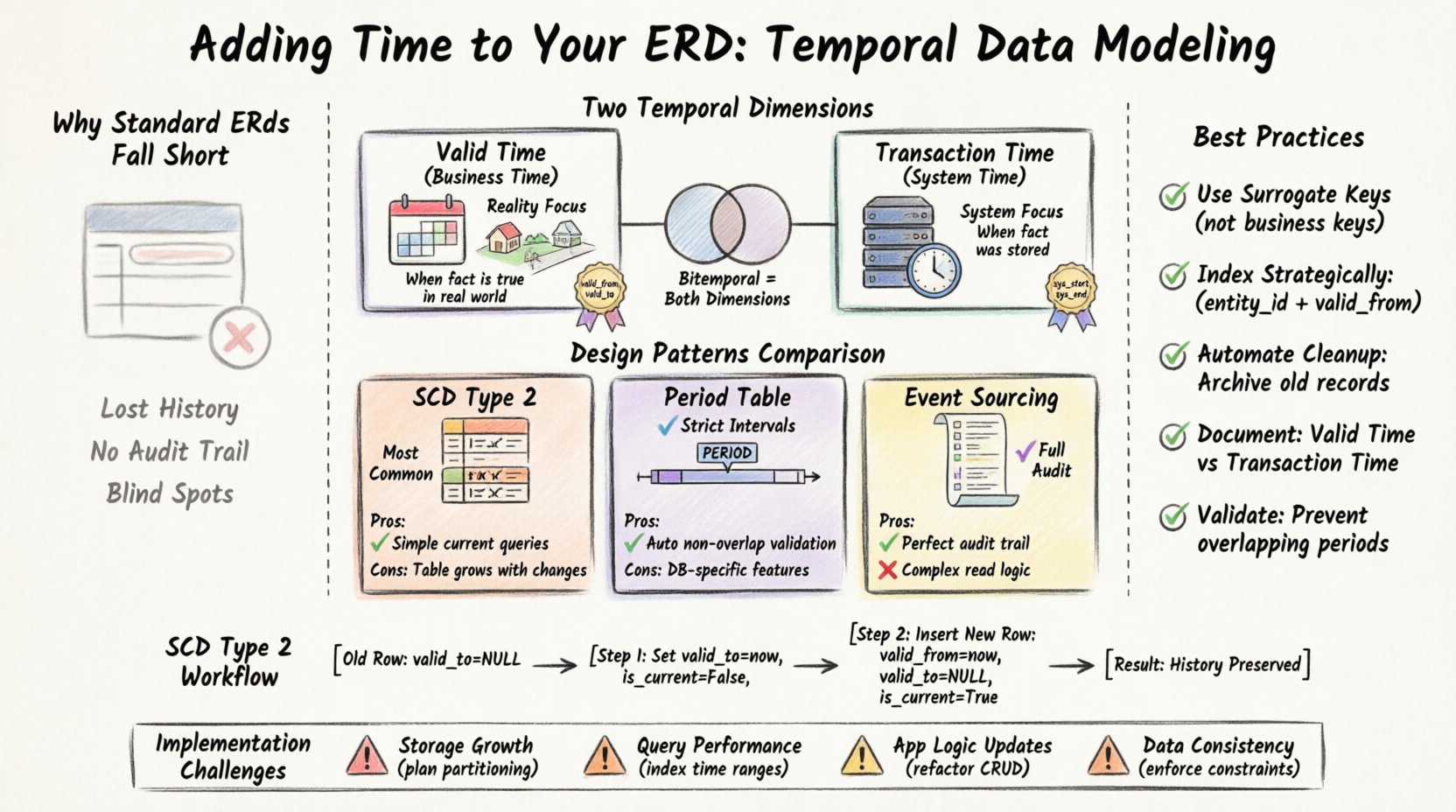
Verständnis zeitlicher Dimensionen ⏳
Um Zeit effektiv zu modellieren, müssen Sie die verschiedenen Weisen unterscheiden, wie Zeit in einer Datenbank existiert. Es gibt zwei primäre Dimensionen, die berücksichtigt werden müssen: Gültige Zeit und Transaktionszeit. Das Verständnis des Unterschieds ist entscheidend für die Auswahl der richtigen Modellierungstechnik.
1. Gültige Zeit (Geschäftszeit)
Die Gültige Zeit stellt den Zeitraum dar, in dem eine Tatsache in der realen Welt wahr ist. Dies ist unabhängig vom Datenbanksystem. Wenn beispielsweise ein Mitarbeiter am 1. Januar von Sales in die Abteilung Engineering wechselt, beginnt die Gültige Zeit für die Ingenieurzuteilung an diesem Tag, unabhängig davon, wann der HR-Manager sie in das System eingegeben hat.
- Schwerpunkt: Wirklichkeit.
- Anwendungsfall: Historische Berichterstattung, Compliance-Prüfungen, Rekonstruktion vergangener Zustände.
- Attribute: Typischerweise implementiert mit
gültig_abundgültig_bisZeitstempeln.
2. Transaktionszeit (Systemzeit)
Die Transaktionszeit verfolgt, wann ein Fakt in der Datenbank gespeichert wurde. Sie wird vollständig vom System verwaltet. Wenn ein Benutzer heute eine Aufzeichnung bearbeitet, erfasst die Transaktionszeit diesen spezifischen Moment. Wenn die Aufzeichnung gelöscht wird, stellt die Transaktionszeit sicher, dass das System weiß, wann sie nicht mehr in der aktiven Menge sichtbar war.
- Schwerpunkt: Systemoperationen.
- Anwendungsfall: Debuggen von Datenproblemen, Verständnis des Systemzustands zu einem bestimmten Zeitpunkt, Rückgängigmachungsfunktionen.
- Attribute: Meist automatisch vom Datenbank-Engine verwaltet als
sys_startundsys_end.
3. Bitemporale Daten
Wenn Sie sowohl die Gültigkeitszeit als auch die Transaktionszeit benötigen, erstellen Sie eine bitemporale Tabelle. Dies ist die umfassendste Form der zeitlichen Modellierung. Sie ermöglicht es Ihnen, Fragen wie folgt zu stellen: „Was glaubte das System am 1. März 2023 bezüglich des tatsächlichen Zustands der Welt am 1. Januar 2023 für wahr?“
Entwurfsmuster für zeitbewusste Schemata 🛠️
Es gibt mehrere architektonische Muster zur Implementierung zeitlicher Daten innerhalb eines ERD. Die Wahl hängt von Ihren Abfragemustern und Speicherbeschränkungen ab.
Das Muster des langsam veränderlichen Dimensions (SCD) Typ 2
Dies ist die häufigste Technik zur historischen Verfolgung in Data-Warehousing. Anstatt eine Zeile zu aktualisieren, fügen Sie eine neue Zeile mit einem neuen Versionskennzeichen ein. Die alte Zeile wird als inaktiv markiert.
- Wichtige Ergänzung:
Surrogatschlüssel(um mit der neuen Version zu verknüpfen) undist_aktivKennzeichen. - Vorteil: Einfache Abfragen, um die aktuelle Aufzeichnung mithilfe eines Filters zu finden.
- Nachteil: Die Tabelle wächst linear mit Änderungen. Das Löschen einer Zeile erfordert die Aktualisierung aller vorherigen Versionen oder deren Kennzeichnung.
Das Muster der Zeitintervall-Tabelle
Bei diesem Ansatz wird die Zeit als Zeitintervalltyp gespeichert, anstatt in zwei getrennten Spalten. Dies wird oft nativ von modernen Datenbank-Engines unterstützt. Es stellt sicher, dass sich Intervalle nicht überlappen.
- Wichtige Ergänzung: Eine
ZEITRAUMDatentypbeschränkung. - Vorteil: Automatische Durchsetzung von nicht überlappenden Zeitintervallen.
- Nachteil: Erfordert spezifische Datenbankfunktionen, die in allen Systemen nicht verfügbar sein können.
Das Event Sourcing-Muster
Anstatt den aktuellen Zustand zu speichern, speichern Sie eine Folge von Ereignissen. Der Zustand wird durch erneutes Abspielen dieser Ereignisse rekonstruiert. Dies ist sehr detailliert, kann aber rechenintensiv sein, um zu lesen.
- Wichtige Ergänzung: Eine append-only-Protokolltabelle.
- Vorteil: Perfekter Audit-Verlauf; keine Daten werden jemals gelöscht.
- Nachteil: Komplexe Lese-Logik; die Zustandsrekonstruktion ist nicht sofort möglich.
Die SCD-Type-2-Methode im Detail 🔄
Für die meisten Unternehmensanwendungen bietet SCD Typ 2 das beste Gleichgewicht zwischen Komplexität und Nutzen. Schauen wir uns an, wie sich dies in eine ERD-Struktur umsetzt.
Stellen Sie sich eine KundeEntität vor. In einem Standardmodell haben Sie eine Zeile pro Kunden-ID. In einem zeitlichen Modell haben Sie mehrere Zeilen für dieselbe Kunden-ID, die sich durch die Zeit unterscheiden.
Erforderliche Attribute:
kunden_id: Der natürliche Geschäfts-Schlüssel.versions_id: Eine eindeutige Kennung für jede spezifische Datensatzinstanz.gültig_ab: Der Zeitstempel, ab dem dieser Datensatz wirksam wurde.gültig_bis: Der Zeitstempel, ab dem dieser Datensatz nicht mehr wirksam war. Oft auf NULL gesetzt für den aktuellen Datensatz.ist_aktuell: Ein boolescher Kennzeichen, um den neuesten Zustand schnell zu identifizieren.
Wenn ein Kunde seine Adresse ändert, aktualisieren Sie die bestehende Zeile nicht. Stattdessen führen Sie folgende Schritte aus:
- Aktualisieren Sie die
valid_toder alten Adresszeile auf das aktuelle Zeitstempel. - Legen Sie
is_currentauf False für die alte Zeile fest. - Fügen Sie eine neue Zeile mit der neuen Adresse ein.
- Legen Sie
valid_fromauf das aktuelle Zeitstempel fest. - Legen Sie
valid_toauf NULL fest. - Legen Sie
is_currentauf True fest.
Periodentabellen und gültige Zeit 🗓️
Während SCD Typ 2 flexibel ist, bieten Periodentabellen eine strengere Definition der Zeit. In diesem Modell ist das Zeitintervall ein einzelnes Attribut. Dies hilft, logische Fehler zu vermeiden, bei denen valid_from größer als valid_to.
Berücksichtigen Sie die folgende Schemastruktur für eine Periodentabelle:
| Spaltenname | Typ | Beschreibung |
|---|---|---|
entity_id |
UUID | Primärschlüssel für die Entität |
datenwert |
VARCHAR | Das zu verfolgende Attribut |
zeitraum |
PERIOD(TIMESTAMP) | Start und Ende der Gültigkeit |
systemversion |
INT | Reihenfolgennummer für die Zeile |
Diese Struktur stellt sicher, dass die Datenbankengine die Zeitintervalle vor der Einfügung überprüft. Wenn Sie versuchen, einen Datensatz einzufügen, der mit einem bestehenden Zeitraum für dasselbe Entität überschneidet, schlägt die Operation fehl, es sei denn, sie ist ausdrücklich erlaubt.
Umgang mit Transaktionszeit 📝
Gültige Zeit sagt Ihnen, was wahr war. Transaktionszeit sagt Ihnen, wann Sie es wussten. Manchmal müssen Sie wissen, dass die Datenbank eine Tatsache für wahr hielt, auch wenn diese Tatsache später in der realen Welt als falsch erwiesen wurde.
Zum Beispiel könnte ein Benutzer eine falsche Adresse eingeben. Das System erfasst sie mit einer Transaktionszeit. Später korrigiert der Benutzer sie. Wenn Sie nur die Gültige Zeit verfolgen, verlieren Sie die Aufzeichnung des ursprünglichen Fehlers. Wenn Sie die Transaktionszeit verfolgen, bewahren Sie die Historie der Dateneingabe im System.
Die Implementierung der Transaktionszeit beinhaltet in der Regel, die Spalten aus der Benutzeroberfläche zu verbergen. Diese Spalten werden von der Datenbankengine verwaltet. Beim Abfragen des „aktuellen“ Zustands filtert das System automatisch Datensätze heraus, bei denen die Transaktionszeit abgelaufen ist (d. h. der Datensatz wurde gelöscht).
Bitemporale Modellierung erklärt ⚖️
Die bitemporale Modellierung kombiniert Gültige Zeit und Transaktionszeit. Dies ist der Goldstandard für regulatorische Compliance und forensische Datenanalyse.
Auswirkungen auf das Schema:
- Sie benötigen vier zeitbezogene Spalten:
gültig_ab,gültig_bis,transaktions_ab,transaktions_bis. - Ihre Indexstrategie muss beide Dimensionen berücksichtigen.
- Ihre Abfragen werden komplexer und erfordern oft Bereichsverknüpfungen.
Abfrage-Beispiel-Logik:
Um den Zustand eines Datensatzes so zu finden, wie er zu einem bestimmten Zeitpunkt bekannt war, filtern Sie nach der Transaktionszeit. Um den Zustand der Welt zu einem bestimmten Zeitpunkt zu finden, filtern Sie nach der Gültigen Zeit. Um den Zustand der Welt zu finden, wie das System ihn zu einem bestimmten Zeitpunkt verstand, filtern Sie nach beiden.
Diese Granularität ist für Branchen wie Finanzen, Gesundheitswesen und Rechtsdienstleistungen unerlässlich, bei denen die Herkunft von Daten genauso wichtig ist wie die Daten selbst.
Implementierungs-Herausforderungen ⚠️
Das Hinzufügen von Zeit zu Ihrem ERD führt zu Komplexität, die sorgfältig verwaltet werden muss.
1. Speicherplatzschwellen
Jede Änderung erzeugt eine neue Zeile. Über Jahre hinweg kann eine Tabelle erheblich größer werden als ihre nicht-temporale Entsprechung. Sie müssen für erhöhte Speicheranforderungen planen. Die Partitionierung nach Zeitbereichen (z. B. monatlich oder jährlich) ist eine gängige Strategie, um Abfragen schnell und die Wartung einfach zu halten.
2. Abfrageleistung
Die Filterung nach Zeitbereichen ist im Allgemeinen schnell, wenn sie korrekt indiziert ist. Die Rekonstruktion historischer Zustände erfordert jedoch oft das Verknüpfen mehrerer Tabellen. Eine Abfrage, die ursprünglich Millisekunden dauerte, kann Sekunden dauern, wenn sie eine Historientabelle mit Millionen von Zeilen durchsucht.
3. Änderungen im Anwendungslogik
Bestehender Anwendungscode, der von einer einzelnen Zeile pro Entität ausgeht, wird brechen. Sie müssen alle CRUD-Operationen umschreiben, um die Zeitattribute zu berücksichtigen. Einfügeoperationen werden zu bedingten Logik-Updates.
4. Datenkonsistenz
Sicherstellen, dass gültig_ab immer kleiner als gültig_biserfordert Datenbankbeschränkungen. Ohne diese Beschränkungen besteht die Gefahr, ungültige Zeitabschnitte zu erstellen, die die historische Berichterstattung stören.
Best Practices für die Wartung 🧹
Um ein temporales Modell gesund zu halten, folgen Sie diesen Richtlinien.
- Verwenden Sie Ersatzschlüssel:Verwenden Sie immer eine interne ID für die Historientabelle, nicht den Geschäfts-Schlüssel. Dadurch kann sich der Geschäfts-Schlüssel ändern, ohne die Referenzintegrität zu verletzen.
- Indizieren Sie strategisch: Erstellen Sie zusammengesetzte Indizes auf (
entität_id,gültig_ab). Dadurch werden Abfragen nach dem aktuellen Datensatz und historischen Snapshots beschleunigt. - Automatisieren Sie die Bereinigung: Implementieren Sie Archivierungsrichtlinien. Wenn eine Aufzeichnung 10 Jahre alt ist, verschieben Sie sie in eine Kalt-Speicher-Tabelle, um die aktive Tabelle schlank zu halten.
- Dokumentieren Sie den Zeitverlauf: Dokumentieren Sie die Unterschiede zwischen Gültigkeitszeit und Transaktionszeit in Ihrem Datenwörterbuch. Entwickler müssen wissen, welcher Zeitstempel für ihren Anwendungsfall gilt.
- Überprüfen Sie Überlappungen: Verwenden Sie Datenbankbeschränkungen, um überlappende gültige Zeiträume für dasselbe Entität zu verhindern.
Vergleich von zeitbasierten Strategien
Die Auswahl des richtigen Modells hängt von Ihren spezifischen Anforderungen ab. Die folgende Tabelle fasst die Kompromisse zusammen.
| Strategie | Komplexität | Speicherkosten | Abfragegeschwindigkeit | Beste Anwendungsfälle |
|---|---|---|---|---|
| SCD Typ 2 | Mittel | Mittel | Hoch | Allgemeine Verfolgung der Geschäftsverlauf |
| Zeitintervalltabellen | Hoch | Mittel | Hoch | Strenge regulatorische Compliance |
| Bitemporal | Sehr hoch | Hoch | Mittel | Forensische Analyse, System-Audits |
| Ereignisquellen | Hoch | Sehr hoch | Niedrig (Lesen) | Zustandsrekonstruktion, Echtzeit-Feeds |
Abschließende Überlegungen für Datenarchitekten
Die Integration von Zeit in Ihr Entitäts-Beziehungs-Diagramm ist eine Entscheidung, die den Lebenszyklus Ihrer Daten beeinflusst. Es handelt sich nicht nur um eine technische Anpassung; es ist eine Veränderung der Art und Weise, wie Sie Informationen betrachten.
Wenn Sie bei der Gestaltung die Zeit berücksichtigen, erkennen Sie an, dass Daten nicht statisch sind. Sie fließen. Sie verändern sich. Sie altern. Indem Sie diese Fähigkeiten in die Grundlage Ihres Schemas integrieren, zukunftssichernd Ihre Systeme gegenüber der Notwendigkeit einer retrospektiven Analyse.
Beginnen Sie damit, welche Attribute in Ihrem System wirklich eine Historie erfordern. Nicht jeder Spalte benötigt einen Zeitstempel. Konzentrieren Sie sich auf wertvolle Datenpunkte wie Finanzbestände, Personalzuweisungen und Produktpreise. Wenden Sie die zeitlichen Muster gezielt an, um unnötigen Overhead zu vermeiden.
Wenn sich Ihr System weiterentwickelt, können Sie feststellen, dass das ursprüngliche Design überarbeitet werden muss. Zeitliche Datenmodelle sind iterativ. Überwachen Sie die Abfrageleistung und die Speicherausweitung. Passen Sie Ihre Partitionierungs- und Indexstrategien an, je mehr historische Daten anfallen.
Letztendlich bietet ein zeitbewusstes ERD eine einzigartige Quelle der Wahrheit, die die Vergangenheit respektiert, während sie die Gegenwart bedient. Es stellt sicher, dass, wenn Fragen zur „Warum“-Begründung eines Ereignisses auftauchen, die Antwort bereits in Ihrer Datenbank steht und darauf wartet, abgerufen zu werden.