










Der Aufbau einer Technologiearchitektur, die Wachstum unterstützt, erfordert mehr als nur die Zusammenstellung von Komponenten. Es erfordert einen strategischen Ansatz, der Nachfrage vorhersieht, Resilienz gewährleistet und die Leistung unter Druck aufrechterhält. Wenn Organisationen Skalierbarkeit anstreben, suchen sie nicht einfach nur Geschwindigkeit, sondern Ausdauer und Anpassungsfähigkeit. Dieser Leitfaden untersucht die Prinzipien, Rahmenwerke und strukturellen Elemente, die zur Planung einer Technologiearchitektur für skalierbare Infrastruktur notwendig sind. Wir werden untersuchen, wie etablierte Methodologien wie das TOGAF-Rahmenwerk diese Entscheidungen leiten können, ohne sich auf spezifische Anbieterlösungen zu stützen.
Skalierbarkeit ist die Fähigkeit eines Systems, erhöhte Last durch Hinzufügen von Ressourcen zu bewältigen. Doch echte architektonische Skalierbarkeit bedeutet, Systeme so zu gestalten, dass Wachstum die Stabilität nicht beeinträchtigt. Dazu ist ein tiefes Verständnis der nicht-funktionalen Anforderungen, des Datenflusses und der Wechselwirkung zwischen Hardware- und Software-Ebenen erforderlich. Indem Teams sich auf grundlegende Prinzipien konzentrieren, können sie Umgebungen schaffen, die sich organisch an die geschäftlichen Bedürfnisse anpassen.
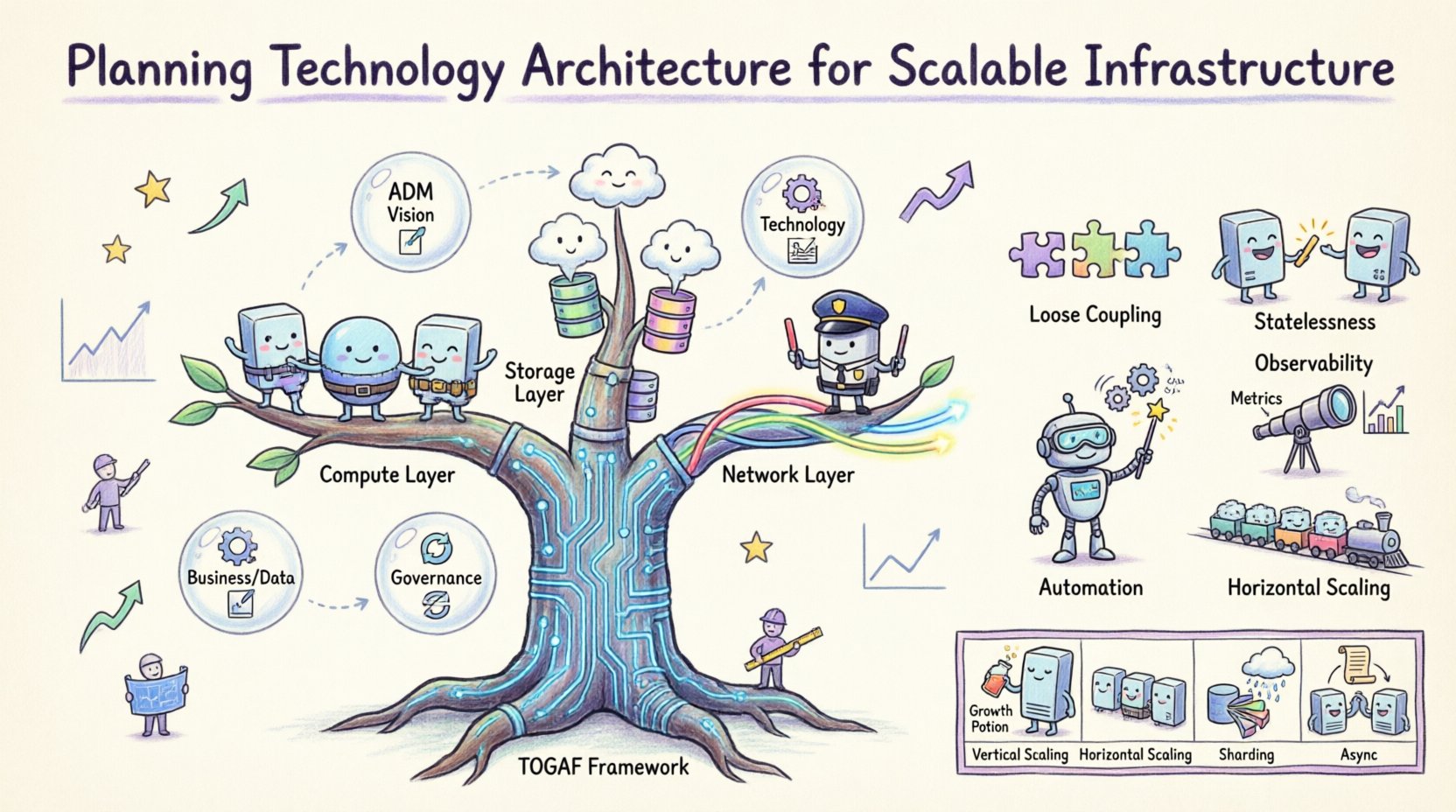
Verständnis von TOGAF im Kontext der Infrastruktur 🧭
Das Open Group Architecture Framework (TOGAF) bietet einen strukturierten Ansatz zur Gestaltung, Planung, Umsetzung und Steuerung der Unternehmensinformationarchitektur. Obwohl es oft mit strategischen Geschäftsentscheidungen auf hoher Ebene assoziiert wird, ist die Anwendung des Architecture Development Method (ADM) besonders wirksam für die Planung von Infrastruktur. TOGAF stellt sicher, dass technische Entscheidungen mit den Geschäftszielen übereinstimmen und verhindert die Entstehung von isolierten Systemen, die nicht kommunizieren oder effizient skalieren können.
Wenn TOGAF auf die Technologiearchitektur angewendet wird, verschiebt sich der Fokus auf die Phase der Technologiearchitektur. In dieser Phase werden die Hardware-, Software- und Netzwerkfähigkeiten definiert, die erforderlich sind, um die priorisierten Geschäftsprozesse zu unterstützen. Sie schließt die Lücke zwischen den logischen Geschäftsanforderungen und der physischen Umsetzung.
- Ausrichtung: Stellt sicher, dass die Infrastruktur gegenwärtige und zukünftige Geschäftsziele unterstützt.
- Standardisierung: Verringert die Komplexität durch die Durchsetzung gemeinsamer Technologiestandards.
- Integration: Ermöglicht einen reibungslosen Datenaustausch über verschiedene Systemebenen hinweg.
- Verwaltbarkeit: Vereinfacht Betrieb und Wartung über den gesamten Lebenszyklus des Systems.
Die Verwendung eines solchen Rahmens verhindert die ad-hoc-Skalierung, bei der neue Ressourcen ohne einen kohärenten Plan hinzugefügt werden. Stattdessen fördert er einen ganzheitlichen Ansatz, bei dem Skalierung eine geplante Entwicklung ist, anstatt eine reaktive Lösung.
Der Zyklus des Architecture Development Method (ADM) ⏳
Der ADM-Zyklus ist das Herzstück der TOGAF-Methodeologie. Er ist iterativ und ermöglicht es Architekten, ihre Entwürfe zu verfeinern, während sich die Anforderungen entwickeln. Für die Planung von Infrastruktur bieten bestimmte Phasen entscheidende Erkenntnisse.
Phase A: Architekturvision 🎯
In dieser Phase wird das Fundament gelegt, indem Umfang und Beschränkungen definiert werden. Bei der Planung von Infrastruktur geht es darum, die prognostizierten Wachstumsraten, regulatorischen Anforderungen und Leistungsziele zu verstehen. Die Stakeholder einigen sich auf die Definition von Skalierbarkeit innerhalb der Organisation. Ist das Ziel, zehnmal die aktuelle Last zu bewältigen, oder neue geografische Regionen zu unterstützen? Diese Fragen prägen den technischen Fahrplan.
Phase B & C: Geschäfts- und Informationssystemarchitektur 📊
Bevor Server oder Netzwerke entworfen werden, muss man die Daten und Anwendungen verstehen, die darauf laufen werden. In Phase B werden die Geschäftsprozesse identifiziert. In Phase C wird die Datenarchitektur und die Anwendungsarchitektur definiert. Die Skalierbarkeit hängt stark davon ab, wie Daten strukturiert und abgerufen werden. Wenn das Datenmodell starr ist, kann die Infrastruktur nicht effektiv skaliert werden. In dieser Phase wird sichergestellt, dass die logischen Anforderungen an Datenmenge und Transaktionsgeschwindigkeit früh dokumentiert werden.
Phase D: Technologiearchitektur 🖥️
Dies ist die entscheidende Phase für die Planung von Infrastruktur. Sie übersetzt die logischen Anforderungen aus Phase C in physische Spezifikationen. Sie umfasst die Plattformauswahl, die Netztopologie und die Sicherheitsarchitektur. Ziel ist es, eine Bauplanung zu erstellen, die die erforderliche Durchsatzleistung und Verfügbarkeit unterstützt. Wichtige Überlegungen sind:
- Rechenressourcen: Die Abwägung zwischen Rechenleistung und Speicher.
- Speicherstrategien: Die Entscheidung zwischen lokalen und verteilten Speicherlösungen.
- Netzwerkbandbreite: Sicherstellen ausreichender Kapazität für den Datenverkehr zwischen Knoten.
- Resilienz: Gestaltung mit Redundanz, um Einzelpunkte des Versagens zu vermeiden.
Phase E bis H: Chancen, Planung, Governance und Veränderung 🔄
Diese Phasen steuern die Umsetzung und die kontinuierliche Entwicklung. Skalierbarkeit ist kein einmaliger Vorgang; es ist ein kontinuierlicher Prozess. Die Governance stellt sicher, dass Änderungen an der Infrastruktur die Leistung nicht beeinträchtigen. Das Änderungsmanagement ermöglicht es der Architektur, sich neuen Technologien oder sich verändernden Marktanforderungen anzupassen, ohne eine vollständige Neugestaltung zu erfordern.
Wichtige architektonische Prinzipien für Wachstum 📈
Um Skalierbarkeit zu erreichen, müssen bestimmte Prinzipien jede Entscheidung leiten. Diese Prinzipien wirken als Leitschnüre und stellen sicher, dass die Architektur auch bei Ausweitung robust bleibt.
- Schwache Kopplung:Komponenten sollten unabhängig voneinander arbeiten. Wenn ein Dienst ausfällt oder skaliert werden muss, sollte dies andere nicht beeinträchtigen. Dadurch ist eine gezielte Ressourcenallokation möglich.
- Zustandslosigkeit:Anwendungsserver sollten keine Benutzersitzungsdaten lokal speichern. Dadurch kann jeder Server jede Anfrage verarbeiten, was die Lastverteilung vereinfacht.
- Automatisierung:Manuelle Skalierung ist langsam und fehleranfällig. Die Prozesse zur Bereitstellung und Konfiguration von Ressourcen sollten automatisiert werden.
- Beobachtbarkeit:Das System muss klare Einblicke in seinen eigenen Zustand ermöglichen. Metriken, Protokolle und Spuren sind entscheidend, um Engpässe zu erkennen, bevor sie zu Ausfällen führen.
- Horizontales Skalieren:Das Hinzufügen weiterer Knoten zu einem Cluster ist oft effektiver und kostengünstiger als die Steigerung der Leistung eines einzelnen Knotens.
Die Einhaltung dieser Prinzipien reduziert technische Schulden und schafft eine Grundlage, die ein schnelles Wachstum ermöglicht.
Aufbau der Infrastrukturkomponenten 💻
Eine skalierbare Infrastruktur besteht aus mehreren voneinander abhängigen Schichten. Jede Schicht muss so gestaltet sein, dass sie eine erhöhte Last bewältigen kann, ohne zum Engpass zu werden.
Rechenschicht
Die Rechenschicht ist der Ort, an dem die Geschäftslogik ausgeführt wird. Für Skalierbarkeit liegt der Fokus auf Elastizität. Ressourcen sollten dynamisch nach Bedarf bereitgestellt werden. Dazu gehört die Gruppierung von Rechenressourcen in Pools, die automatisch erweitert oder verkleinert werden können. Wichtige Überlegungen sind:
- Prozessorenarchitektur:Auswahl von Befehlssätzen, die für die spezifische Arbeitslast optimiert sind.
- Speicherverwaltung:Sicherstellen ausreichend RAM, um gleichzeitige Prozesse ohne Auslagerung zu bewältigen.
- Containerisierung:Verwendung von leichtgewichtigen Verpackungen, um Anwendungen zu isolieren und Ressourcengrenzen effizient zu verwalten.
Speicherschicht
Datenaufbau ist unausweichlich. Die Speicherarchitektur muss wachsenden Volumina gerecht werden, während sie eine geringe Latenz beibehält. Verteilte Speichersysteme werden für großskalige Umgebungen oft bevorzugt gegenüber zentralisierten Arrays. Sie bieten eine bessere Fehlertoleranz und die Möglichkeit, Kapazität schrittweise zu erweitern.
- Datenaufteilung:Aufteilung der Daten auf mehrere Knoten, um Lese- und Schreiblast zu verteilen.
- Replikation: Erstellen von Kopien von Daten an verschiedenen Standorten, um die Verfügbarkeit zu gewährleisten und den Zugriff zu beschleunigen.
- Caching: Speichern von häufig abgerufenen Daten in schnellen Speicherlagen, um die Datenbanklast zu reduzieren.
Netzwerkschicht
Das Netzwerk wirkt als verbindendes Gewebe. Wenn das Netzwerk nicht mithalten kann, verlangsamt sich das gesamte System. Ein skalierbares Netzwerkkonzept konzentriert sich auf Bandbreite, Latenz und Effizienz der Routing-Verfahren.
- Lastverteilung: Verteilen des eingehenden Datenverkehrs auf mehrere Server, um Überlastung zu vermeiden.
- Inhaltsbereitstellung: Platzieren von Inhalten näher am Benutzer, um die Latenz zu reduzieren.
- Bandbreitenmanagement: Priorisierung kritischer Datenströme, um sicherzustellen, dass wesentliche Dienste weiterhin reagieren.
Tabelle: Skalierbarkeitsmuster und Einsatzfälle
| Muster | Funktion | Am besten geeignet für |
|---|---|---|
| Vertikale Skalierung | Hinzufügen von Ressourcen zu bestehenden Knoten | Datenbanken, die hohe Leistung pro Knoten erfordern |
| Horizontale Skalierung | Hinzufügen weiterer Knoten zum Pool | Webanwendungen und Mikrodienste |
| Sharding | Aufteilen von Daten über mehrere Datenbanken | Hochvolumige transaktionale Daten |
| Caching | Speichern von Kopien von Daten für schnellen Zugriff | Leseintensive Arbeitslasten |
| Asynchrone Verarbeitung | Aufgaben in einer Warteschlange für spätere Ausführung anordnen | Hintergrundaufgaben und Benachrichtigungen |
Datenverwaltung in Umgebungen mit hohem Wachstum 💾
Daten sind oft die größte Beschränkung beim Skalieren. Wenn die Transaktionsvolumina steigen, kann die Datenbankleistung schnell abnehmen. Die Planung für Daten-Skalierbarkeit erfordert einen Wechsel von traditionellen relationalen Modellen hin zu flexibleren Architekturen.
Lesekopien: Erstellen von Kopien der primären Datenbank, die schreibgeschützte Abfragen bedienen. Dadurch wird das primäre System entlastet und die Antwortzeiten für Benutzer verbessert.
Datenbank-Sharding: Dabei wird eine große Datenbank in kleinere, schnellere und leichter zu verwaltende Teile, sogenannte Shards, aufgeteilt. Jeder Shard ist eine separate Datenbankinstanz. Dadurch kann das System durch Hinzufügen weiterer Shards horizontal skaliert werden, anstatt einen einzigen riesigen Server zu aktualisieren.
Ereignisgesteuerte Architektur: Anstatt dass Systeme sich gegenseitig nach Daten abfragen, reagieren sie auf Ereignisse. Dadurch werden Komponenten entkoppelt und es wird ermöglicht, dass jeder Teil des Systems unabhängig basierend auf seiner spezifischen Ereignislast skaliert.
Bei der Gestaltung der Datenarchivierung müssen Architekten auch Datenhaltungspolitiken berücksichtigen. Das Archivieren alter Daten in kalten Speichern hält das aktive System schlank und schnell. Dadurch wird sichergestellt, dass Hochleistungsressourcen den aktuellen betrieblichen Anforderungen gewidmet sind.
Netzwerk- und Verbindungsaspekte 🌐
Eine skalierbare Infrastruktur beruht auf einem robusten Netzwerk. Mit wachsender Anzahl an verbundenen Geräten und Diensten steigt die Netzwerkkomplexität. Das Design muss Latenz, Durchsatz und Sicherheit berücksichtigen.
Mikrosegmentierung: Aufteilung des Netzwerks in kleinere Zonen, um die Ausbreitung von Sicherheitsbedrohungen einzuschränken. Dies ermöglicht auch eine fein abgestimmte Verkehrssteuerung und stellt sicher, dass kritische Dienste Priorität erhalten.
Mehrregionale Bereitstellung:Die Bereitstellung von Infrastruktur an mehreren geografischen Standorten reduziert die Latenz für Benutzer in verschiedenen Regionen. Sie bietet auch Fähigkeiten zur Katastrophenwiederherstellung. Wenn eine Region offline geht, kann der Datenverkehr auf eine andere umgeleitet werden.
API-Gateways: Diese fungieren als einziger Einstiegspunkt für alle Clientanfragen. Sie verwalten Authentifizierung, Rate Limiting und Routing. Dadurch werden Backend-Dienste vor Überlastung durch direkten Datenverkehr geschützt.
Bandbreitenoptimierung: Die Komprimierung von Datenübertragungen und die Minimierung der Nutzlastgröße verringern die Belastung des Netzwerks. Effiziente Protokolle sollten verwendet werden, um einen maximalen Durchsatz bei minimalem Overhead zu gewährleisten.
Governance und Lebenszyklus-Management 🛡️
Ohne Governance können Skalierungsmaßnahmen zu Chaos führen. Governance stellt sicher, dass Änderungen an der Infrastruktur dokumentiert, überprüft und genehmigt werden. Sie gewährleistet Konsistenz innerhalb der Organisation.
- Änderungssteuerung: Jede Änderung an der Infrastruktur muss verfolgt werden. Dadurch wird Konfigurationsdrift verhindert und sichergestellt, dass Produktionsumgebungen den Gestaltungsanforderungen entsprechen.
- Kostenmanagement: Skalierbarkeit erhöht oft die Kosten. Governance stellt sicher, dass Ressourcen effizient genutzt werden und die Ausgaben den budgetären Beschränkungen entsprechen.
- Sicherheitskonformität: Sicherheitskontrollen müssen mit der Infrastruktur skaliert werden. Wenn neue Knoten hinzugefügt werden, müssen sie automatisch Sicherheitsrichtlinien erben, um Schwachstellen zu vermeiden.
Das Lebenszyklus-Management umfasst die gesamte Reise einer Ressource von der Erstellung bis zur Stilllegung. Automatisierte Werkzeuge sollten die Bereitstellung und das Ausschalten von Ressourcen übernehmen. Dadurch wird menschliches Versagen reduziert und sichergestellt, dass nicht genutzte Ressourcen keine unnötigen Kosten verursachen.
Bewertung von Risiken und Maßnahmen zur Risikominderung ⚠️
Das Skalieren bringt neue Risiken mit sich. Je komplexer das System ist, desto höher ist das Potenzial für Ausfallstellen. Ein proaktiver Ansatz zur Risikomanagement ist unerlässlich.
- Einzelne Ausfallstellen:Identifizieren Sie jede Komponente, die bei Ausfall das System lahmlegt. Gestalten Sie Redundanz für alle kritischen Komponenten.
- Capacitätsplanung:Bewerten Sie regelmäßig den aktuellen Nutzungswert im Vergleich zum prognostizierten Wachstum. Stellen Sie sicher, dass Ressourcen hinzugefügt werden können, bevor die Nachfrage die Kapazität übersteigt.
- Notfallwiederherstellung:Testen Sie Sicherungs- und Wiederherstellungsverfahren regelmäßig. In einer Krise ist die Fähigkeit, den Service schnell wiederherzustellen, entscheidend.
- Anbieterbindung:Die Abhängigkeit von einem einzigen Anbieter kann die Flexibilität einschränken. Verwenden Sie bei Gelegenheit offene Standards, um Portabilität und Verhandlungsmacht zu gewährleisten.
Regelmäßige Stress- und Lasttests helfen, Schwachstellen zu identifizieren, bevor sie zu kritischen Problemen werden. Durch die Simulation von Spitzenlasten können Teams überprüfen, ob die Infrastruktur unter Druck wie erwartet funktioniert.
Vorbereitung auf zukünftige Erweiterungen 🔮
Die technologische Landschaft verändert sich schnell. Eine Architektur, die heute entworfen wird, muss an die Anforderungen von morgen angepasst werden können. Dazu gehört, über aufkommende Technologien und Branchentrends informiert zu bleiben.
- Modularität:Gestalten Sie Systeme als modulare Komponenten. Dadurch können Teile des Systems aktualisiert oder ersetzt werden, ohne das gesamte System zu beeinträchtigen.
- Interoperabilität:Stellen Sie sicher, dass verschiedene Systeme mithilfe standardisierter Protokolle kommunizieren können. Dadurch wird die Integration mit neuen Tools und Diensten erleichtert.
- Skalierbare Sicherheit:Sicherheitsmaßnahmen müssen sich gemeinsam mit der Infrastruktur weiterentwickeln. Neue Bedrohungen erfordern neue Verteidigungsstrategien, und die Architektur muss diese Updates nahtlos unterstützen.
- Fortlaufende Verbesserung:Behandeln Sie die Architektur als lebendiges Dokument. Regelmäßige Überprüfungen stellen sicher, dass das Design mit den Geschäftszielen und technischen Gegebenheiten im Einklang bleibt.
Die Investition in Dokumentation und Wissensaustausch stellt sicher, dass das Team die Architektur versteht. Bei Personalwechsel bleibt das institutionelle Wissen erhalten und bewahrt die Integrität des Systems.
Abschließende Überlegungen für Architekten 🏁
Die Planung der Technologiearchitektur für skalierbare Infrastruktur ist eine komplexe Aufgabe, die das Abwägen konkurrierender Anforderungen erfordert. Leistungsfähigkeit, Kosten, Sicherheit und Flexibilität müssen alle berücksichtigt werden. Durch die Nutzung strukturierter Methoden und die Einhaltung bewährter Prinzipien können Organisationen Systeme aufbauen, die der Zeit standhalten.
Die Reise endet nicht mit der Bereitstellung. Kontinuierliche Überwachung und Optimierung sind erforderlich, um die Skalierbarkeit aufrechtzuerhalten. Sobald sich die Geschäftsanforderungen verändern, muss auch die Architektur sich anpassen. Dadurch bleibt die Technologie ein Treiber des Wachstums und kein Hemmnis.
Konzentrieren Sie sich auf die Grundlagen: saubere Gestaltung, Automatisierung und Beobachtbarkeit. Diese Säulen stützen eine widerstandsfähige Infrastruktur, die den Herausforderungen der Zukunft gewachsen ist. Mit sorgfältiger Planung und disziplinierter Umsetzung werden skalierbare Systeme zur Realität, die den Geschäftserfolg voranbringen.