











In der Landschaft der Datenarchitektur erzeugen kaum Konzepte mehr Verwirrung als die Many-to-Many-Beziehung. Beim Entwerfen eines Entitäts-Beziehungs-Diagramms (ERD) erfordert die Situation, bei der eine Entität mit mehreren Instanzen einer anderen Entität und umgekehrt verbunden ist, einen spezifischen strukturellen Ansatz. Relationale Datenbankmanagementsysteme unterstützen keine direkten Many-to-Many-Verbindungen nativ. Sie erfordern eine Zwischeneinrichtung, um die Datenintegrität zu gewährleisten und eine effiziente Abfrage zu ermöglichen. Dieser Leitfaden untersucht die autoritativen Methoden zur Lösung dieser Verbindungen und stellt sicher, dass Ihr Datenmodell robust, skalierbar und normalisiert bleibt.
Unabhängig davon, ob Sie ein System für akademische Daten, Bestandsverwaltung oder Benutzerberechtigungen entwerfen – die Prinzipien zur Lösung dieser Kardinalitäten bleiben konstant. Das Verständnis der zugrundeliegenden Mechanismen verhindert zukünftige Anomalien und vereinfacht die Wartung. Wir werden über oberflächliche Definitionen hinausgehen, um die strukturellen Anforderungen, Normalisierungsregeln und Implementierungsstrategien zu untersuchen, die professionelles Datenmodellieren ausmachen.
🔍 Verständnis der Kardinalität in ERDs
Die Kardinalität definiert die numerische Beziehung zwischen Entitäten in einer Datenbank. Sie legt fest, wie viele Instanzen einer Entität mit jeder Instanz einer anderen Entität assoziiert sein können oder müssen. In der ERD-Notation wird dies oft durch Linien dargestellt, die Entitäten verbinden, wobei Krähenfüße die „mehrere“-Seite und gerade Linien oder einzelne Striche die „eine“-Seite anzeigen.
Es gibt drei primäre Kardinalitäten:
- Ein-zu-Eins (1:1):Ein einzelner Datensatz in Entität A steht mit einem einzelnen Datensatz in Entität B in Beziehung. Beispiel: Eine Person und ihre Passnummer.
- Ein-zu-Viele (1:M):Ein einzelner Datensatz in Entität A steht mit mehreren Datensätzen in Entität B in Beziehung. Beispiel: Ein Kunde, der mehrere Bestellungen aufgibt.
- Viele-zu-Viele (M:N):Mehrere Datensätze in Entität A stehen mit mehreren Datensätzen in Entität B in Beziehung. Beispiel: Studierende, die sich in mehrere Kurse einschreiben, und Kurse, die mehrere Studierende enthalten.
Während 1:1- und 1:M-Beziehungen in einem physischen Datenbankschema einfach zu implementieren sind, stellt die M:N-Beziehung eine einzigartige Herausforderung dar. Die relationale Theorie verlangt, dass eine Tabellenzelle nur atomare Werte enthalten darf. Eine direkte Verbindung zwischen zwei Tabellen, bei der eine einzelne Zeile in Tabelle A theoretisch mehrere Zeilen in Tabelle B referenzieren könnte, verstößt gegen dieses Prinzip auf der physischen Ebene.
🚫 Warum direkte M:M-Beziehungen in relationalen Modellen scheitern
Das relationale Modell, das von E.F. Codd etabliert wurde, basiert auf dem Konzept von Relationen (Tabellen), bei denen jede Spalte ein bestimmtes Attribut darstellt und jede Zeile eine eindeutige Instanz repräsentiert. Es gibt zwei Hauptgründe, warum eine direkte Many-to-Many-Verbindung in einem Standard-Relationalen Datenbankmodell unmöglich ist:
- Fehlende native Unterstützung:Datenbank-Engines erlauben es nicht, dass eine Fremdschlüsselspalte mehrere Werte enthält. Ein Fremdschlüssel muss auf einen einzelnen Primärschlüssel in einer anderen Tabelle verweisen. Er kann nicht auf eine Liste von Schlüsseln verweisen.
- Einfüge- und Löschanomalien:Wenn Sie versuchen, mehrere IDs in einer einzigen Zelle zu speichern (z. B. „Student_ID: 101, 102, 103“), verletzen Sie die Erste Normalform (1NF). Dies macht die Abfrage, Aktualisierung und Löschung spezifischer Beziehungen rechnerisch aufwendig und fehleranfällig.
Daher muss die Beziehung selbst als Entität behandelt werden, um diese Daten effizient speichern zu können. Diese Umwandlung ist die zentrale Technik zur Lösung der Komplexität.
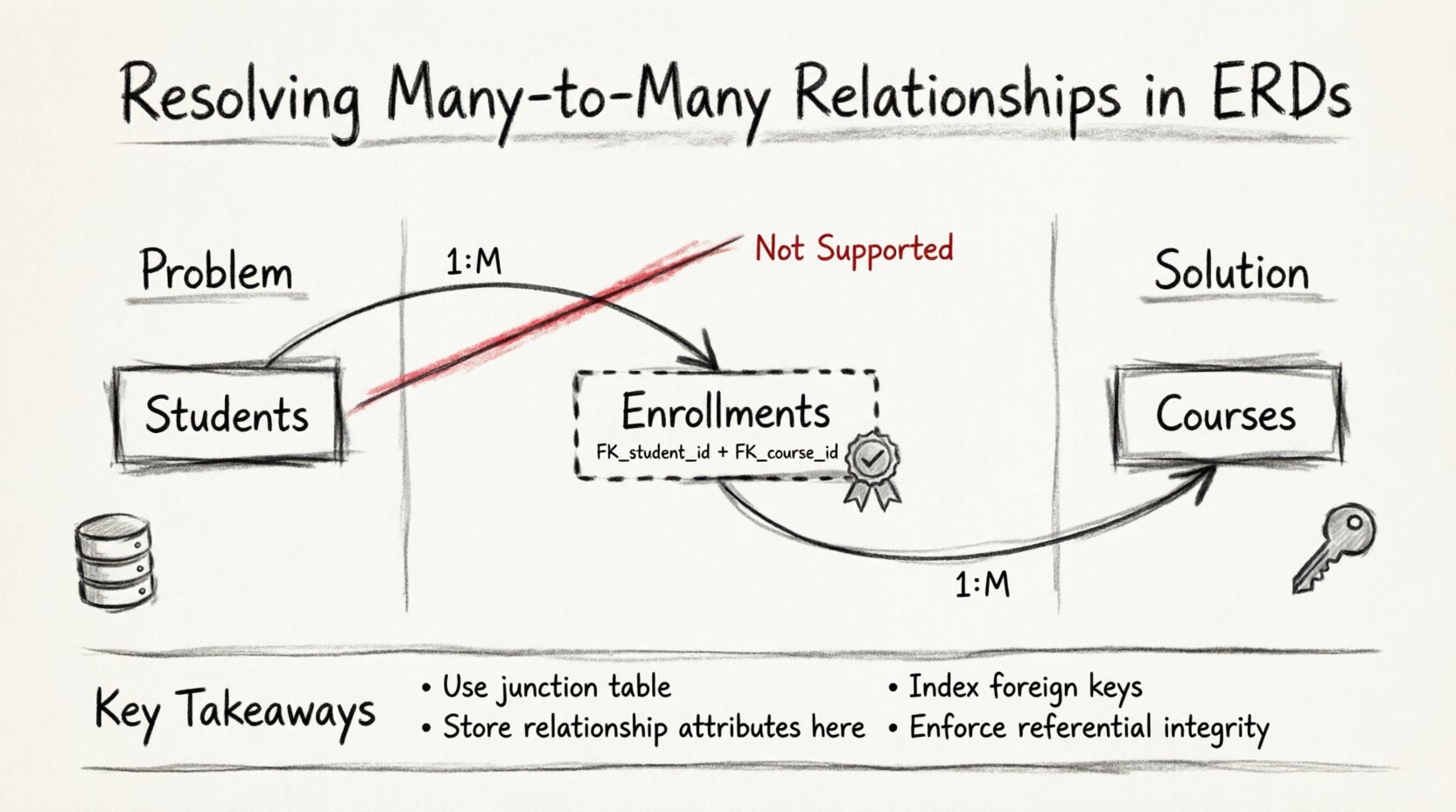
🧱 Technik 1: Die assoziative Entität (Verknüpfungstabelle)
Die Standardlösung zur Auflösung einer Many-to-Many-Beziehung ist die Erstellung einer assoziativen Entität, die allgemein als Verknüpfungstabelle oder Brückentabelle bekannt ist. Diese Tabelle befindet sich physisch zwischen den beiden primären Entitäten und zerlegt die direkte Verbindung in zwei Ein-zu-Viele-Beziehungen.
Wenn Sie eine Verknüpfungstabelle einführen, wird die ursprüngliche M:N-Beziehung in folgende Beziehungen zerlegt:
- Eine Ein-zu-Viele-Beziehung zwischen Entität A und der Verknüpfungstabelle.
- Eine Ein-zu-Viele-Beziehung zwischen Entität B und der Verknüpfungstabelle.
Aufbau einer Verknüpfungstabelle:
- Fremdschlüssel:Sie muss mindestens zwei Fremdschlüsselspalten enthalten. Eine verweist auf den Primärschlüssel von Entität A, die andere auf den Primärschlüssel von Entität B.
- Kompositer Primärschlüssel:Häufig dient die Kombination dieser beiden Fremdschlüssel als Primärschlüssel für die Verknüpfungstabelle. Dies stellt sicher, dass ein bestimmtes Paar von Entitäten nicht mehr als einmal verknüpft werden kann, es sei denn, die Beziehung ist intrinsisch mehrwertig.
- Ersatzschlüssel: In einigen Fällen wird eine eindeutige, automatisch erhöhende ID zur Verbindungstabelle hinzugefügt. Dies ist nützlich, wenn die Beziehung mehrere Instanzen mit unterschiedlichen Attributen haben kann (z. B. kann ein Schüler mehrmals in ein Kurs eingeschrieben sein, jeweils mit unterschiedlichen Noten über verschiedene Jahre).
Beispielszenario:
Betrachten Sie ein Bibliothekssystem. Ein Buch kann von vielen Bürgern. Ein Bürger kann viele Bücher.
- Ohne Lösung: Sie können eine Buchzeile nicht direkt mit mehreren Bürgerspalten verknüpfen.
- Mit Lösung: Erstellen Sie eine AusleiheprotokollTabelle.
- Das Ausleiheprotokollenthält
Buch_IDundBürger_ID.
Diese Struktur ermöglicht es der Datenbank, genau zu verfolgen, welcher Bürger zu jedem Zeitpunkt welches Buch ausgeliehen hat, ohne Buch- oder Bürgerdaten zu vervielfachen.
📝 Technik 2: Behandlung von Attributen in Beziehungen
Ein entscheidender Unterschied bei der ERD-Modellierung ist, ob die Beziehung zwischen Entitäten eigene Daten trägt. Bei einem einfachen Link besteht die Verbindung oder nicht. In vielen realen Szenarien hat die Beziehung selbst jedoch Eigenschaften.
Zum Beispiel bei einer Projekt und Mitarbeiter Szenario, ein Mitarbeiter kann an mehreren Projekten arbeiten, und ein Projekt hat mehrere Mitarbeiter. Aber die Beziehung könnte enthalten:
- Rolle: Ist der Mitarbeiter auf diesem spezifischen Projekt ein Entwickler, Designer oder Manager?
- Stunden_zugewiesen: Wie viele Stunden pro Woche sind diesem Projekt zugewiesen?
- Startdatum: Wann begann diese Zuweisung?
Wenn Sie die Beziehung lediglich als binären Schalter behandeln, verlieren Sie diese essenziellen Daten. Die Verbindungstabelle wird zum perfekten Ort, um diese Attribute zu speichern.
Implementierungsregeln:
- Speichern Sie Beziehungseigenschaften nicht in den übergeordneten Entitäten. Sie gehören weder allein dem Projekt noch allein dem Mitarbeiter.
- Stellen Sie alle beziehungsspezifischen Daten in der Verbindungstabelle ab.
- Stellen Sie sicher, dass die Verbindungstabelle einen eindeutigen Bezeichner (zusammengesetzt oder künstlich) hat, um Aktualisierungen dieser Attribute vorzunehmen, ohne die übergeordneten Entitäten zu beeinflussen.
Dieser Ansatz gewährleistet die Datennormalisierung. Wenn Sie eine RolleSpalte in die MitarbeiterTabelle hinzufügen würden, entstünde Redundanz, wenn der Mitarbeiter über verschiedene Projekte hinweg mehrere Rollen hat. Die Verbindungstabelle isoliert diese Variation.
⚖️ Technik 3: Normalisierung und Datenintegrität
Die Auflösung von M:N-Beziehungen geht nicht nur darum, Tabellen zu verknüpfen; es geht darum, Normalisierungsprinzipien zu befolgen, um Datenanomalien zu vermeiden. Die Dritte Normalform (3NF) ist der Standardzielwert für die meisten transaktionalen Systeme.
Anforderungen der Dritten Normalform (3NF):
- Die Tabelle muss in der Zweiten Normalform (2NF) sein.
- Alle nicht-schlüsselbasierten Attribute müssen sich ausschließlich auf den Primärschlüssel beziehen.
Durch die Erstellung einer Verbindungstabelle stellen Sie sicher, dass die Beziehungsinformationen sich auf den zusammengesetzten Schlüssel der Verbindungstabelle beziehen, nicht auf die einzelnen Entitätsschlüssel. Dadurch werden transitive Abhängigkeiten beseitigt.
Referenzielle Integrität:
Fremdschlüsselbeschränkungen sind in der Verbindungstabelle unerlässlich. Sie setzen die folgenden Regeln durch:
- Eine
Buch_IDim Ausleihprotokoll muss in der BücherTabelle existieren. - A
Patron_IDim Ausleihprotokoll muss in der Patrons Tabelle existieren.
Dies verhindert verwaiste Datensätze. Sie können kein Ausleihereignis für ein Buch protokollieren, das nicht im Katalog vorhanden ist. Datenbank-Engines setzen dies durch CASCADE oder RESTRICT Aktionen beim Löschen durch.
📊 Vergleich der Beziehungstypen
Die Visualisierung der Unterschiede zwischen Beziehungstypen hilft bei der Auswahl der richtigen Modellierungsstrategie. Die folgende Tabelle fasst die strukturellen Anforderungen und die Implementierungskomplexität zusammen.
| Beziehungstyp | Physische Implementierung | Lage des Primärschlüssels | Komplexität |
|---|---|---|---|
| Ein-zu-Eins (1:1) | Fremdschlüssel in einer Tabelle | Beliebige Tabelle | Niedrig |
| Ein-zu-Viele (1:M) | Fremdschlüssel in der „Viele“-Tabelle | Primäre Tabelle | Mittel |
| Viele-zu-Viele (M:N) | Separate Verbindungstabelle | Verbindungstabelle (zusammengesetzt) | Hoch |
Wie gezeigt, erfordert die M:N-Beziehung den größten strukturellen Aufwand. Dieser Aufwand ist jedoch notwendig, um die Datenintegrität zu gewährleisten. Die Kosten eines zusätzlichen Joins bei einer Abfrage werden oft durch die Kosten einer Dateninkonsistenz in einer schlecht modellierten Struktur überkompensiert.
🚀 Leistungsüberlegungen
Die Einführung einer Verbindungstabelle fügt Ihren Abfragen eine zusätzliche Abstraktionsebene hinzu. Beim Abrufen von Daten müssen Sie drei Tabellen statt zwei verknüpfen. In Systemen mit hohem Datenverkehr kann dies die Leistung beeinträchtigen, wenn dies nicht korrekt verwaltet wird.
- Indizierung:Jeder Fremdschlüssel in der Verbindungstabelle sollte indiziert werden. Dadurch kann die Datenbankengine schnell Zeilen für eine bestimmte Entität finden, ohne die gesamte Verbindungstabelle durchsuchen zu müssen.
- Komposite Indizes:In einigen Fällen ist die Erstellung eines Indexes auf der Kombination beider Fremdschlüssel effizienter als getrennte Indizes. Dies unterstützt Abfragen, die gleichzeitig nach beiden Entitäten filtern.
- Lesen gegenüber Schreiben:Verbindungstabellen sind typischerweise schreiblastig, wenn die Beziehungen dynamisch sind. Sie sind leselastig beim Generieren von Berichten. Stellen Sie sicher, dass Ihre Indizierungsstrategie dem vorherrschenden Operationsmuster Ihrer Anwendung entspricht.
⚠️ Häufige Fehler und Lösungen
Selbst erfahrene Modellierer begehen Fehler bei der Auflösung von Kardinalitäten. Die Aufmerksamkeit für häufige Fehler kann später erhebliche Refaktorierungszeit sparen.
1. Der „Einspaltige“ Fehler
Versuch, mehrere IDs in einer einzigen Spalte mit kommagetrennten Werten (z. B. „1, 2, 3“) zu speichern. Dies verstößt gegen Datenbankprinzipien und macht das Abfragen unmöglich, ohne String-Parser-Funktionen einzusetzen. Verwenden Sie immer eine separate Zeile für jedes Beziehungs-Instanz.
2. Redundante Attribute
Kopieren von Attributen aus den übergeordneten Entitäten in die Verbindungstabelle, ohne dass dies notwendig ist. Wenn ein Attribut der Entität gehört (z. B. der Name eines Schülers), gehört es in die Schüler-Tabelle, nicht in die Einschreibungs-Tabelle. Legen Sie nur Daten ab, die die Verbindung selbst beschreiben.
3. Ignorieren der NULL-Behandlung
Fremdschlüssel als nullable definieren, obwohl sie obligatorisch sein sollten. Wenn eine Beziehung obligatorisch ist (z. B. eine Bestellung muss einen Kunden haben), sollte der Fremdschlüssel keine NULL-Werte zulassen. Dies setzt Geschäftsregeln auf Datenbankebene durch.
4. Zirkuläre Referenzen
Erstellen einer Verbindungstabelle, die sich selbst unnötigerweise referenziert. Stellen Sie sicher, dass die Verbindungstabelle nur die beiden unterschiedlichen Entitäten verknüpft, die an der Beziehung beteiligt sind. Vermeiden Sie Schleifen, die keinen funktionalen Zweck erfüllen.
🎨 Best Practices für die visuelle Darstellung
Beim Dokumentieren Ihres ERD ist Klarheit entscheidend. Die visuelle Darstellung sollte sofort die aufgelöste Struktur für jeden Leser des Diagramms vermitteln.
- Benennen Sie die Verbindungstabelle:Benennen Sie die Tabelle beschreibend. Verwenden Sie statt „Table3“ beispielsweise „Student_Course_Enrollment“.
- Geben Sie die Kardinalität an:Markieren Sie die Linien, die die Verbindungstabelle mit den übergeordneten Entitäten verbinden, deutlich. Verwenden Sie auf der Seite der Verbindungstabelle Krähenfüße, um die „vielen“ Beziehung aus der Perspektive der übergeordneten Entität darzustellen.
- Zeigen Sie Attribute:Wenn die Verbindungstabelle Attribute hat (z. B. „Note“ oder „Datum“), listen Sie diese explizit im Diagramm auf. Dies macht deutlich, dass die Beziehung mehr ist als nur eine Verbindung.
- Verwenden Sie unterschiedliche Linienstile:Einige Modellierungstools ermöglichen gestrichelte Linien für optionale Beziehungen und durchgezogene Linien für obligatorische. Konsistenz hierbei erleichtert das Verständnis.
🔄 Rekursive Beziehungen und M:N
Gelegentlich existiert eine many-to-many-Beziehung innerhalb einer einzelnen Entität. Zum Beispiel ein Mitarbeiter kann mehrere andere verwalten Mitarbeiter, und diese Mitarbeiter können andere verwalten. Dies ist eine rekursive M:N-Beziehung.
Die Lösung bleibt die gleiche wie bei einer standardmäßigen M:N-Beziehung. Sie erstellen weiterhin eine Verbindungstabelle, aber beide Fremdschlüssel in dieser Tabelle verweisen auf den Primärschlüssel derselben Entität.
- Entität: Mitarbeiter
- Verbindungstabelle: Mitarbeiter_Verwaltung
- FK1: Manager_ID (verweist auf Mitarbeiter)
- FK2: Unterstellte_ID (verweist auf Mitarbeiter)
Diese Struktur ermöglicht komplexe Organisationshierarchien, ohne die Normalisierungsregeln zu verletzen. Sie ermöglicht Abfragen, die mehrere Ebenen der Managementtiefe durchlaufen.
🛡️ Datenbeschränkungen und Geschäftsvorschriften
Technische Beschränkungen reichen nicht aus; Geschäftsvorschriften müssen durchgesetzt werden. Eine Verbindungstabelle bietet einen natürlichen Ort, um diese Regeln anzuwenden.
- Eindeutigkeitsbeschränkungen: Stellen Sie sicher, dass eine bestimmte Beziehung nicht zweimal erstellt werden kann, es sei denn, dies ist beabsichtigt. Zum Beispiel sollte ein Student nicht zweimal im selben Kursabschnitt im selben Semester eingeschrieben werden. Eine eindeutige Beschränkung auf die Kombination aus Student_ID und Course_ID setzt dies durch.
- Prüfbeschränkungen: Überprüfen Sie numerische Daten. Zum Beispiel muss der Wert „Hours_Allocated“ in einer Projekt-Verbindungstabelle größer als null und kleiner als 40 sein.
- Auslöser: In komplexen Systemen können Auslöser erforderlich sein, um Zusammenfassungstabellen zu aktualisieren. Wenn sich die Verbindungstabelle ändert, könnte eine Zusammenfassungstabelle in der übergeordneten Entität (z. B. „Total_Projects_Per_Employee“) automatisch aktualisiert werden müssen.
📈 Entwicklung des Modells
Modelle entwickeln sich weiter, je nachdem, wie sich die Anforderungen ändern. Eine Beziehung, die ursprünglich viele-zu-viele ist, könnte sich vereinfachen, wenn sich eine Geschäftsregel ändert. Zum Beispiel, wenn eine Richtlinie ändert, dass ein Student nur einmal pro Zeitraum in einem Kurs eingeschrieben werden kann, kann die Verbindungstabelle wieder in die Studententabelle integriert werden.
Allerdings ist es in der Regel sicherer, mit der Verbindungstabelle zu beginnen. Sie bietet die maximale Flexibilität. Wenn sich die Anforderung später ändert und mehrfache Einschreibungen erlaubt werden sollen, ist das Schema bereits vorbereitet. Wenn Sie mit einer zusammengeführten Tabelle beginnen, müssen Sie später refaktorisieren.
📝 Zusammenfassung der wichtigsten Erkenntnisse
Die Auflösung von vielen-zu-viele-Beziehungen ist eine grundlegende Fähigkeit im Datenbankdesign. Sie erfordert die Erstellung einer Zwischeneinrichtung, um die Datenintegrität zu gewährleisten und effiziente Abfragen zu unterstützen. Die Verbindungstabelle ist die Standardlösung, die komplexe Beziehungen in handhabbare viele-zu-eins-Verbindungen aufteilt.
- M:N immer auflösen: Versuchen Sie niemals, mehrere Fremdschlüssel in einer einzigen Spalte zu speichern.
- Verwenden Sie zusammengesetzte Schlüssel: Die Kombination aus Fremdschlüsseln dient oft als eindeutiger Bezeichner für die Beziehung.
- Speichern von Beziehungsdaten:Platzieren Sie Attribute, die spezifisch für die Verbindung sind, in der Verbindungstabelle.
- Indizieren von Fremdschlüsseln:Die Leistung hängt von schnellen Abfragen der Zeilen in der Verbindungstabelle ab.
- Durchsetzen von Einschränkungen:Verwenden Sie eindeutige Einschränkungen und Fremdschlüsselverweise, um ungültige Daten zu verhindern.
Durch die Einhaltung dieser Techniken stellen Sie sicher, dass Ihr Datenbank-Schema widerstandsfähig gegenüber Änderungen ist und komplexe Dateninteraktionen bewältigen kann. Die Investition in eine korrekte Modellierung während der Entwurfsphase zahlt sich in Bezug auf Wartbarkeit und Leistung während des gesamten Lebenszyklus des Systems aus.