











In der komplexen Architektur der Datenbankgestaltung stellen wenige Konzepte Ingenieure so sehr vor Herausforderungen wie die selbstverweisende Entität. Auch als rekursive Beziehung bekannt, ermöglicht dieses Muster, dass eine Tabelle auf sich selbst verweist, wodurch die Modellierung von Hierarchien und komplexen Strukturen innerhalb eines flachen Schemas möglich wird. Das Verständnis der korrekten Implementierung ist entscheidend, um Datenintegrität und Abfrageleistung zu gewährleisten.
Beim Entwerfen eines Entitäts-Beziehungs-Diagramms (ERD) verbinden die meisten Beziehungen zwei verschiedene Entitäten. In der Praxis erfordert jedoch oft die Datenwelt, dass eine einzelne Entität sich selbst zurückverweist. Ein Manager verwaltet Mitarbeiter, eine Kategorie enthält Unterkategorien, und ein Produkt kann Teil eines Sets sein. Diese Szenarien erfordern eine rekursive Beziehung.
Dieser Leitfaden untersucht die Mechanik, Gestaltungsprinzipien und bewährte Praktiken zur Handhabung selbstverweisender Entitäten. Wir werden untersuchen, wie diese Beziehungen strukturiert werden können, ohne sich auf spezifische Softwarewerkzeuge zu verlassen, und uns stattdessen auf universelle Datenbankprinzipien konzentrieren.
🧐 Was ist eine selbstverweisende Entität?
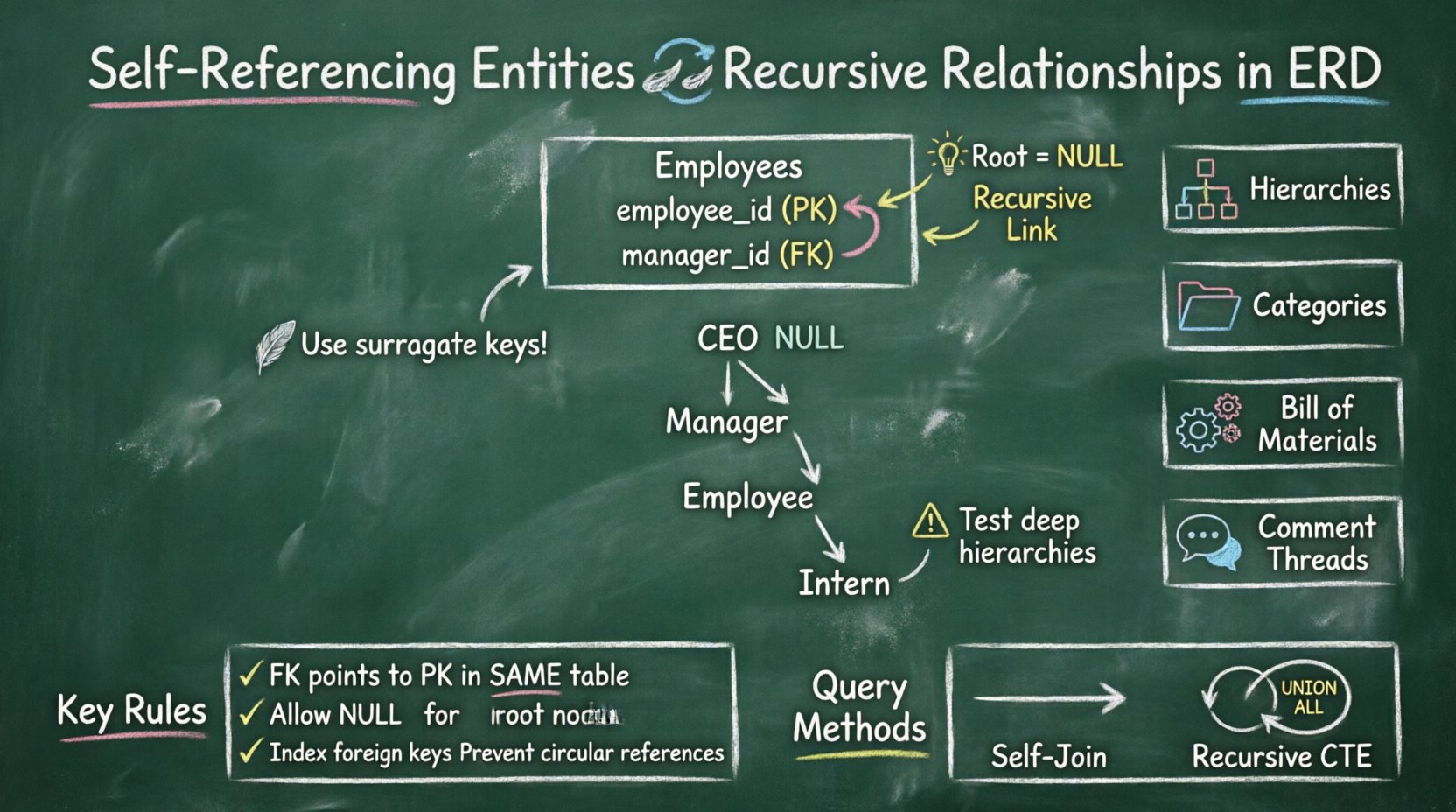
Eine selbstverweisende Entität tritt auf, wenn ein Fremdschlüssel in einer Tabelle auf den Primärschlüssel derselben Tabelle verweist. Dadurch entsteht eine Schleife, bei der Datensätze innerhalb einer einzigen Tabelle auf andere Datensätze innerhalb derselben Tabelle verweisen können. Es handelt sich um eine grundlegende Technik zur Modellierung hierarchischer Datenstrukturen.
Wichtige Merkmale:
- Einzelne Tabelle: Die Beziehung existiert vollständig innerhalb einer einzigen Tabellenstruktur.
- Eltern-Kind-Verbindung: Eine Zeile fungiert als Eltern- und eine andere als Kind-Element.
- Behandlung von Nullwerten: Der Wurzelknoten der Hierarchie hat in der Fremdschlüsselspalte typischerweise einen Nullwert.
- Zirkuläre Logik: Es muss darauf geachtet werden, um endlose Schleifen während der Datenabrufvorgänge zu vermeiden.
🏗️ Kernkomponenten rekursiver Beziehungen
Um diese Beziehung effektiv umzusetzen, müssen bestimmte Datenbankkomponenten abgestimmt werden. Die Schema-Design-Entwicklung beruht stark auf der Interaktion zwischen Primärschlüsseln und Fremdschlüsseln.
🔑 Der Primärschlüssel
Jede Zeile in der Tabelle muss einen eindeutigen Bezeichner haben. Dies ist der Ankerpunkt. Wenn eine Zeile auf eine andere Zeile verweist, tut sie dies, indem sie die eindeutige Kennung der übergeordneten Zeile speichert.
- Er muss stabil sein. Die Änderung eines Primärschlüssels ist eine komplexe Operation.
- Er sollte indiziert sein, um eine schnelle Abfrageleistung zu gewährleisten.
- Häufig handelt es sich um eine automatisch hochzählende Ganzzahl oder eine UUID.
🔗 Der Fremdschlüssel
Die Fremdschlüsselspalte befindet sich in derselben Tabelle wie der Primärschlüssel. Sie enthält den Wert des Primärschlüssels der übergeordneten Zeile. Diese Spalte definiert die Richtung der Beziehung.
- Nullable: In einer Hierarchie hat das oberste Element (die Wurzel) keinen Elternknoten. Daher muss diese Spalte Nullwerte zulassen.
- Einschränkung: Eine Fremdschlüssel-Einschränkung stellt sicher, dass der gespeicherte Wert mit einem vorhandenen Primärschlüssel in derselben Tabelle übereinstimmt.
- Indizierung: Obwohl die Indizierung nicht immer zwingend erforderlich ist, beschleunigt sie die Abfragen, die die Hierarchie durchlaufen, erheblich.
📐 Visualisierung in einem Entity-Relationship-Diagramm
Beim Zeichnen eines ERD zur Darstellung einer selbstreferenzierenden Entität kann die Notation auf den ersten Blick verwirrend sein. Standard-ERD-Tools verwenden spezifische Linien, um die Verbindung zu kennzeichnen.
Visuelle Notationsregeln:
- Das Entitätsfeld wird nur einmal gezeichnet.
- Eine Beziehungslinie verbindet den Primärschlüssel mit dem Fremdschlüssel innerhalb desselben Feldes.
- Die Linie schließt sich oft wieder an die Entität an und erzeugt eine visuelle Schleife.
- Kardinalitätsmarken (1:1, 1:M) werden auf der Linie platziert, um anzugeben, wie viele Kinder ein Elternknoten haben kann.
Beispiel: Organisationsstruktur
| Konzept | Beschreibung | ERD-Notation |
|---|---|---|
| Mitarbeiter | Die zu modellierende Entität | Feld mit der Beschriftung “Mitarbeiter” |
| Leiter | Die Rolle, die auf dieselbe Tabelle verweist | Linie von Manager-ID zu Mitarbeiter-ID |
| Berichtslinie | Die rekursive Beziehung | Schleifenpfeil |
| Wurzelknoten | CEO oder oberster Vorgesetzter | Null-Wert in der Manager-ID |
🌳 Häufige Anwendungsfälle für rekursive Daten
Rekursive Beziehungen sind nicht theoretisch; sie lösen konkrete Probleme in der Datenmodellierung. Hier sind die häufigsten Szenarien, in denen dieses Muster angewendet wird.
1️⃣ Organisationshierarchien
Jedes Unternehmen hat eine Struktur. Mitarbeiter berichten an Manager, die wiederum an Direktoren berichten, die an VPs berichten. Diese Kette bildet eine klassische Baumstruktur.
- Datenmodell: Eine Tabelle mit dem Namen “Mitarbeiter”.
- Spalten:
mitarbeiter_id,name,manager_id. - Logik: Die
manager_idSpalte verweist aufmitarbeiter_id. - Vorteil: Das Hinzufügen eines neuen Mitarbeiters erfordert nur das Einfügen einer Zeile. Es ist nicht notwendig, für jede Abteilung eine neue Tabelle zu erstellen.
2️⃣ Kategorienbäume
E-Commerce-Plattformen ordnen Produkte oft in verschachtelte Kategorien ein. Elektronik > Computer > Laptops.
- Datenmodell: Eine Tabelle mit dem Namen “Kategorien”.
- Spalten:
kategorie_id,name,eltern_id. - Logik: Eine Kategorie kann einen Elternknoten haben oder eine Stammkategorie sein (eltern_id ist null).
- Vorteil: Flexibilität, beliebig viele Unterkategorien hinzuzufügen, ohne das Schema zu ändern.
3️⃣ Stückliste (BOM)
Die Fertigung erfordert oft komplexe Teillisten. Ein Auto besteht aus Motoren, die wiederum aus Kolben bestehen. Manchmal ist ein Kolben Teil eines anderen Motortyps.
- Datenmodell: Eine Tabelle mit dem Namen “Teile”.
- Spalten:
teil_id,Beschreibung,baugruppe_id. - Logik: Ein Teil kann selbst eine Baugruppe sein, die andere Teile enthält.
- Vorteil: Erlaubt mehrstufige Fertigungsstrukturen.
4️⃣ Kommentarverläufe
Foren und Blogs ermöglichen es Benutzern, auf Kommentare zu antworten. Ein Kommentar kann einen übergeordneten Kommentar haben, auf den er antwortet, oder er kann ein eigenständiger Kommentar sein.
- Datenmodell: Eine Tabelle mit dem Namen “Kommentare”.
- Spalten:
kommentar_id,benutzer_id,inhalt,eltern_kommentar_id. - Logik: Eine Antwort verweist zurück auf die ID des ursprünglichen Kommentars.
- Vorteil: Unterstützt eine unbegrenzte Verschachtelung von Diskussionen.
⚙️ Implementierungsgesichtspunkte
Die Gestaltung des Schemas ist erst der erste Schritt. Um sicherzustellen, dass die Daten unter verschiedenen Bedingungen korrekt funktionieren, ist sorgfältige Planung erforderlich.
🛑 Vermeidung von zyklischen Verweisen
Ein kritisches Risiko bei rekursiven Beziehungen ist die Bildung einer Schleife. Zum Beispiel verwaltet Mitarbeiter A Mitarbeiter B, und Mitarbeiter B verwaltet Mitarbeiter A. Dadurch entsteht eine unendliche Schleife.
- Anwendungslogik: Beim Einfügen oder Aktualisieren von Daten sollte die Anwendung die Hierarchietiefe überprüfen, um sicherzustellen, dass keine Schleifen entstehen.
- Datenbankbeschränkungen: Obwohl Standard-SQL-Beschränkungen Schleifen nicht leicht verhindern können (da sie den aktuellen Zustand prüfen, nicht den resultierenden Zustand), können in einigen Systemen Trigger verwendet werden, um den Pfad vor dem Schreiben zu überprüfen.
- Wurzelidentifizierung: Stellen Sie sicher, dass jeder gültige Baum genau einen Wurzelknoten hat (wo der Fremdschlüssel null ist).
📉 Umgang mit Nullwerten
Die Wurzel der Hierarchie ist der Ausgangspunkt. Bei einer standardmäßigen rekursiven Beziehung hat die Wurzelzeile einen Nullwert in der Fremdschlüsselspalte.
- Abfragen: Um alle Wurzelknoten zu finden, fragen Sie nach Zeilen, bei denen der Fremdschlüssel NULL ist.
- Standardwerte: Legen Sie keinen Standardwert für den Fremdschlüssel fest, wenn dies einen Elternknoten impliziert. Ein Standardwert von 0 oder -1 kann irreführend sein und zu Integritätsproblemen führen.
- Integrität: Stellen Sie sicher, dass die Datenbankengine NULL-Werte für die Fremdschlüsselspalte zulässt. Eine NOT NULL-Beschränkung würde das Hierarchiemodell zerstören.
📈 Leistung und Indizierung
Je größer die Daten werden, desto langsamer können Abfragen rekursiver Strukturen werden. Eine einfache Abfrage, um alle Nachkommen eines bestimmten Knotens zu finden, kann viele Joins oder rekursive Abfragen erfordern.
Optimierungsstrategien:
- Indizierung von Fremdschlüsseln: Erstellen Sie einen Index auf der Spalte, die die Referenz auf den Elternknoten enthält. Dies beschleunigt das Finden von Kindknoten.
- Materialisierte Pfade: Einige Systeme speichern den vollständigen Pfad der Hierarchie in einer separaten Spalte (z. B. “/1/5/12/20”). Dies ermöglicht eine schnellere filterbasierte Suche anhand von Zeichenketten, erfordert jedoch Aktualisierungen bei jedem Einfügen.
- Verschachtelte Mengen: Ein alternatives Algorithmus, der linke und rechte Zahlen verwendet, um die Tiefe darzustellen. Dies ist schneller für die Abrufung, aber langsamer für die Einfügung.
- Abfrage-Tiefe: Begrenzen Sie die Rekursionstiefe in Ihren Abfragen. Unendliche Schleifen können die Datenbankengine zum Absturz bringen, wenn sie nicht begrenzt werden.
🔍 Abfragen rekursiver Daten
Das Abrufen hierarchischer Daten ist komplexer als das Abrufen flacher Daten. Standard-JOINs funktionieren für eine Ebene, aber mehrere Ebenen erfordern spezialisierte Logik.
🔄 Selbstverknüpfungen
Die häufigste Methode besteht darin, die Tabelle selbst zu verknüpfen. Sie geben der Tabelle einmal den Alias Elternteil und einmal den Alias Kind.
- Eine Ebene:Verknüpfen Sie die Tabelle einmal mit sich selbst, um den unmittelbaren Elternteil zu erhalten.
- Mehrere Ebenen:Benötigt mehrere Verknüpfungen, was sich schnell unübersichtlich gestaltet.
- Nachteil: Die Anzahl der erforderlichen Verknüpfungen entspricht der Tiefe der Hierarchie.
🔁 Rekursive gemeinsame Tabellenausdrücke (CTEs)
Moderne Datenbank-Engines unterstützen rekursive CTEs. Dadurch kann eine Abfrage eine UNION ALL-Operation gegen sich selbst ausführen, bis keine weiteren Zeilen mehr gefunden werden.
- Anker-Mitglied: Der Ausgangspunkt der Rekursion (normalerweise der Wurzelknoten).
- Rekursives Mitglied: Der Teil der Abfrage, der das Ergebnis zurück zur Tabelle verknüpft, um die nächste Ebene zu finden.
- Beendigung: Die Abfrage stoppt, wenn keine weiteren passenden Zeilen mehr gefunden werden.
- Vorteil: Verarbeitet jede Tiefe der Hierarchie, ohne diese im Voraus zu kennen.
🛡️ Datenintegrität und Einschränkungen
Die Aufrechterhaltung der Integrität einer selbstverweisenden Tabelle ist entscheidend. Was geschieht mit den Kindern, wenn ein Elternteil gelöscht wird?
🗑️ Löschkaskade
Wenn eine Elternteilzeile entfernt wird, muss die Datenbank entscheiden, wie mit den Kindzeilen verfahren werden soll.
- RESTRICT: Verhindert die Löschung des Elternteils, wenn Kinder existieren. Dies bewahrt die Daten, kann aber notwendige Bereinigungen blockieren.
- CASCADE: Löscht alle Kindzeilen, wenn der Elternteil gelöscht wird. Dies ist bei tiefen Hierarchien gefährlich, da es versehentlich große Teile der Daten löschen kann.
- SET NULL: Setzt den Fremdschlüssel der Kinder auf NULL, wodurch sie neue Wurzelknoten werden. Dies ist oft die sicherste Option, um die Datenstruktur zu erhalten.
- Standardwert festlegen: Legt den Fremdschlüssel auf einen Standardwert fest (z. B. eine bestimmte verwaiste Kategorie).
🔒 Aktualisierungsbeschränkungen
Die Änderung des Primärschlüssels einer übergeordneten Zeile ist riskant. Wenn Sie die ID eines Managers ändern, müssen Sie diese ID in jeder Mitarbeiteraufzeichnung aktualisieren, die auf sie verweist.
- Anwendungsebene:Führen Sie die Aktualisierung transaktional durch, um sicherzustellen, dass alle Verweise gemeinsam aktualisiert werden.
- Datenbanktrigger: Kann die Weiterleitung von ID-Änderungen automatisieren, was jedoch Komplexität hinzufügt.
- Beste Praxis: Vermeiden Sie die Aktualisierung von Primärschlüsseln in rekursiven Strukturen so weit wie möglich. Verwenden Sie Ersatzschlüssel (Auto-Increment-Integerwerte) anstelle natürlicher Schlüssel (wie Mitarbeitercodes).
🚧 Behebung von häufigen Problemen
Auch bei sorgfältiger Gestaltung können Probleme während der Entwicklung und Wartung auftreten.
❓ Wie finde ich die Tiefe eines Baums?
Um die Ebene einer bestimmten Zeile zu bestimmen, müssen Sie von der Zeile zur Wurzel aufsteigen. Zählen Sie die Anzahl der Sprünge.
- Abfrageansatz:Verwenden Sie eine rekursive Abfrage, die die Zeilen zählt, während sie nach oben wandert.
- Anwendungsansatz:Speichern Sie die Tiefe während der Einfügung in einer Spalte. Dies spart Abfragezeit, erfordert jedoch Wartung.
❓ Wie behandle ich verwaiste Knoten?
Verwaiste Knoten sind Zeilen, bei denen der Fremdschlüssel auf einen nicht existierenden Elternknoten verweist. Dies geschieht meist aufgrund von Fehlern oder manuellen Eingabefehlern.
- Validierung:Führen Sie periodische Integritätsprüfungen durch, um Zeilen zu finden, bei denen der Fremdschlüssel keinem Primärschlüssel entspricht.
- Wiederherstellung:Entscheiden Sie eine Richtlinie: Verschieben Sie sie in eine Stammkategorie, löschen Sie sie oder kennzeichnen Sie sie zur Überprüfung.
❓ Leistungsabfall im Laufe der Zeit
Je größer der Baum wird, desto langsamer werden Abfragen, die den gesamten Baum durchsuchen.
- Caching:Speichern Sie häufig abgerufene Hierarchiestrukturen im Anwendungs-Speicher.
- Archivierung:Verschieben Sie historische oder inaktive Teile der Hierarchie in Archivtabellen.
- Partitionierung: Wenn die Daten sehr groß sind, partitionieren Sie die Tabelle nach Stammkategorie.
📝 Zusammenfassung der Best Practices
Um eine robuste Implementierung selbstverweisender Entitäten sicherzustellen, halten Sie sich an diese Richtlinien.
- Verwenden Sie Ersatzschlüssel: Bevorzugen Sie auto-incrementierende Ganzzahlen gegenüber Geschäftsschlüsseln für den Primärschlüssel.
- NULL-Werte zulassen: Stellen Sie sicher, dass die Fremdschlüsselspalte NULL-Werte für Stammknoten zulässt.
- Fremdschlüssel indizieren: Indizieren Sie immer die Spalte, die die Verweisung auf den Elternknoten enthält.
- Zyklen validieren: Implementieren Sie Überprüfungen, um zirkuläre Verweise (A -> B -> A) zu verhindern.
- Rekursion begrenzen: Begrenzen Sie die Rekursionstiefe in Abfragen, um Stapelüberläufe zu vermeiden.
- Dokumentieren Sie das Schema: Markieren Sie deutlich, welche Spalten in Ihrer ERD-Dokumentation selbstverweisend sind.
- Planung für Löschvorgänge: Definieren Sie klare Regeln für das Kaskadieren von Löschvorgängen oder das Setzen von NULL-Werten beim Entfernen des Elternknotens.
- Tiefgehende Hierarchien testen: Testen Sie Ihre Abfragen mit mindestens 10 Ebenen Tiefe, um sicherzustellen, dass die Leistung erhalten bleibt.
🔮 Zukünftige Überlegungen
Datenbanktechnologie entwickelt sich weiter. Während das Konzept einer selbstverweisenden Entität konstant bleibt, verbessern sich die Werkzeuge zur Verwaltung dieser Entitäten.
- Graphdatenbanken: Einige moderne Systeme behandeln Beziehungen als erstklassige Bürger. Sie verarbeiten rekursive Pfade nativ, ohne die Komplexität von SQL.
- JSON-Unterstützung: Neuere Datenbank-Engines erlauben die Speicherung hierarchischer Daten in JSON-Spalten, was die Schema-Designs für stark verschachtelte Strukturen vereinfachen kann.
- Verbesserungen von ORMs: Objekt-Relationale Mapper werden besser darin, rekursive Beziehungen automatisch zu verarbeiten, wodurch Boilerplate-Code reduziert wird.
Trotz dieser Fortschritte bleibt die Grundlogik der rekursiven Beziehung unverändert. Das Verständnis der zugrundeliegenden Mechanismen von Primärschlüsseln, Fremdschlüsseln und Tabellenbeziehungen ist für jeden technischen Fachmann, der mit Datenstrukturen arbeitet, unerlässlich.
Durch Einhaltung dieser Prinzipien können Sie Systeme entwickeln, die flexibel genug sind, um komplexe Hierarchien zu bewältigen, gleichzeitig aber leistungsfähig und wartbar bleiben. Die selbstverweisende Entität ist ein mächtiges Werkzeug in Ihrem Arsenal der Datenmodellierung, vorausgesetzt, sie wird präzise und sorgfältig eingesetzt.