

Die Gestaltung einer robusten Datenbank-Schema für soziale Medienplattformen erfordert ein tiefes Verständnis dafür, wie Benutzer miteinander interagieren, Informationen teilen und konsumieren. Im Gegensatz zu traditionellen transaktionalen Systemen beinhalten soziale Netzwerke komplexe Many-to-Many-Beziehungen, rekursive Datenstrukturen und Anforderungen an enorme Skalierbarkeit. Das Entity-Relationship-Diagramm (ERD) dient als Bauplan für diese Interaktionen und gewährleistet die Datenintegrität, während es ein schnelles Wachstum unterstützt. Dieser Leitfaden untersucht die entscheidenden Strategien zur effektiven Modellierung sozialer Medien-Daten.
Das zentrale Problem verstehen 🧩
Soziale Medien-Anwendungen sind nicht einfach nur Speicherorte für Inhalte; sie sind dynamische Netzwerke von Beziehungen. Ein einfacher Blogbeitrag unterscheidet sich erheblich von einem sozialen Medien-Feed aufgrund der Interaktions-Ebene. Likes, Shares, Kommentare und Folge-Beziehungen schaffen ein Netzwerk von Verbindungen, das genau modelliert werden muss. Eine schlechte Modellierung führt zu langsamen Abfrageleistungen, Dateninkonsistenzen und Schwierigkeiten bei der Implementierung von Funktionen wie Nachrichten-Feeds oder Freundschaftsvorschlägen.
- Volumen:Soziale Plattformen erzeugen Millionen von Ereignissen pro Sekunde.
- Geschwindigkeit:Daten treffen in Echtzeit-Streams ein, die sofort verarbeitet werden müssen.
- Vielfalt:Inhalte umfassen Text, Bilder, Videos, Metadaten und Standortdaten.
- Beziehungen:Der Kernwert liegt in den Verbindungen zwischen Entitäten.
Beim Erstellen eines ERD ist das primäre Ziel, die Normalisierung mit der Leistungsfähigkeit abzustimmen. Übermäßige Normalisierung kann Joins zu teuer für häufige Lesezugriffe machen. Übermäßige Denormalisierung kann zu Datenredundanz und Konsistenzproblemen führen. Die folgenden Abschnitte beschreiben die spezifischen Entitäten und Beziehungen, die dieses Gebiet definieren.
Definition der Kernentitäten 🔑
Jedes soziale Mediensystem dreht sich um einige grundlegende Entitäten. Ihre korrekte Identifizierung ist der erste Schritt bei der Erstellung eines skalierbaren Schemas. Diese Entitäten stellen die zentralen Bausteine der Anwendung dar.
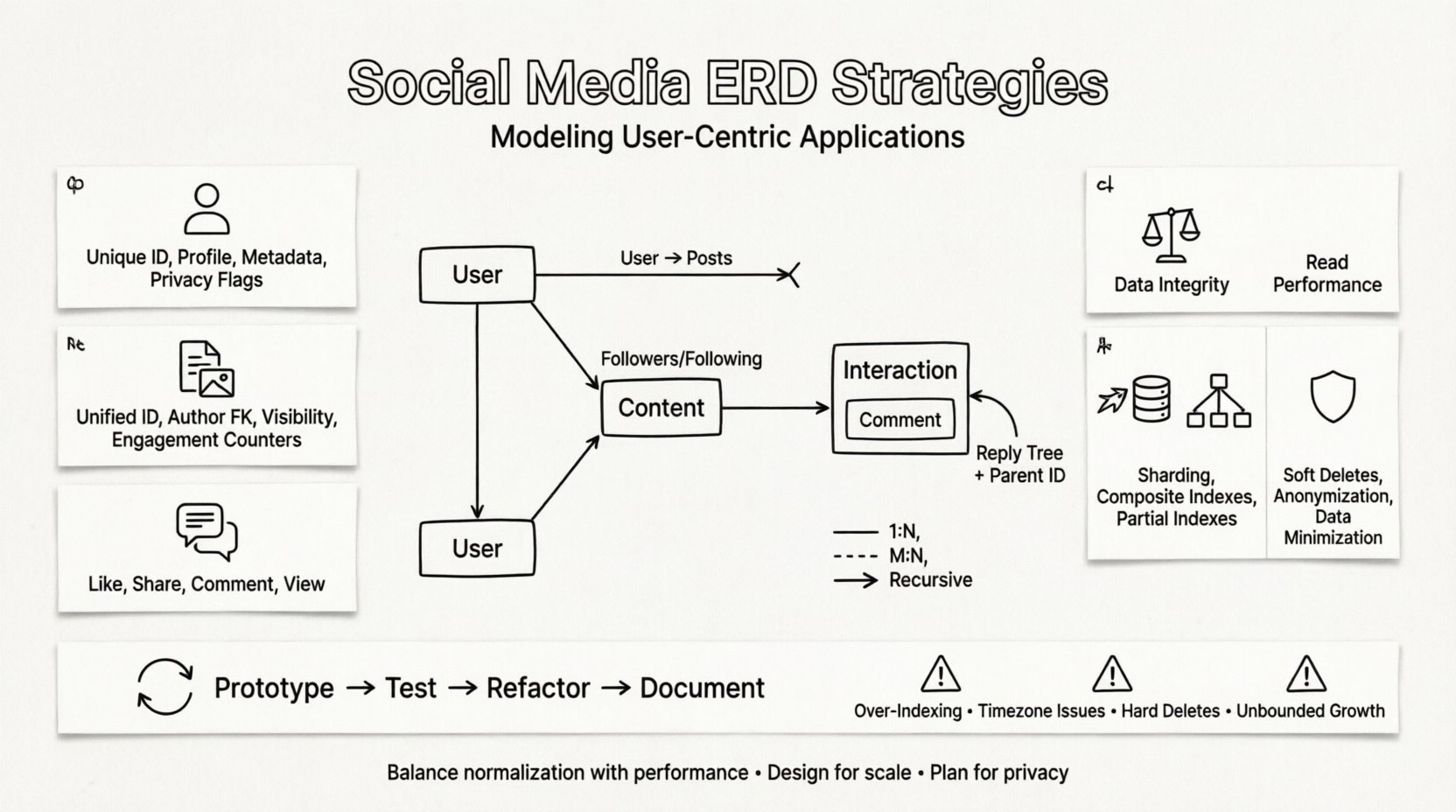
1. Die Benutzer-Entität 👤
Der Benutzer ist der zentrale Knoten im Netzwerk. Diese Entität speichert Authentifizierungsdaten, Profilinformationen und Einstellungen. Sie muss so gestaltet sein, dass sie Millionen von Datensätzen effizient verarbeiten kann.
- Eindeutige Kennung:Ein künstlicher Schlüssel wird natürlichen Schlüsseln gegenüber bevorzugt, um Leistung und Anonymität zu gewährleisten.
- Profildaten:Name, Bio, Avatar und Überprüfungsstatus.
- Metadaten:Zeitstempel für Kontenerstellung, letzten Anmeldedatum und Löschung.
- Datenschutz-Flags:Einstellungen, die steuern, welche Daten anderen Benutzern sichtbar sind.
2. Die Inhalts-Entität 📝
Inhalte sind der Treibstoff sozialer Plattformen. Sie umfassen Beiträge, Geschichten, Bilder, Videos und Kommentare. Ein flexibles Schema ist erforderlich, da verschiedene Inhaltsarten unterschiedliche Attribute haben.
- Einheitliche ID:Eine generische ID, die auf spezifische Inhalts-Tabellen verweist.
- Autor-Verweis: Ein Fremdschlüssel, der auf die Benutzerentität verweist.
- Sichtbarkeitsbereich: Öffentlich, privat, nur Freunde oder bestimmte Gruppen.
- Engagement-Zähler: Gecachte Zähler für Likes und Kommentare, um die Abfragebelastung zu reduzieren.
3. Die Interaktionsentität 💬
Interaktionen stellen die Aktionen dar, die Benutzer gegenüber Inhalten oder anderen Benutzern durchführen. Es handelt sich um Transaktionen mit hohem Volumen, die oft die Leistungsanforderungen des Systems bestimmen.
- Gefällt mir: Ein binärer Zustand zwischen einem Benutzer und Inhalt.
- Teilen: Ein Verweis auf den ursprünglichen Inhalt mit einem neuen Kontext.
- Kommentar: Eine hierarchische oder verkettete Beziehung zu Inhalten.
- Ansicht: Oft separat protokolliert aufgrund hoher Volumina und geringerer Bedeutung für die Integrität.
Modellierung von Beziehungen 🕸️
Die wahre Komplexität sozialer Medien liegt in den Beziehungen zwischen Entitäten. Standardmethoden der relationalen Modellierung stoßen oft an ihre Grenzen bei der rekursiven Natur sozialer Graphen. Besondere Aufmerksamkeit muss darauf verwendet werden, wie diese Verbindungen gespeichert werden.
Ein-zu-Viele-Beziehungen
Dies sind die häufigsten und einfachsten. Zum Beispiel kann ein Benutzer viele Beiträge haben, aber ein Beitrag gehört nur zu einem Benutzer. Dies wird durch einen Fremdschlüssel in der Kindtabelle modelliert.
- Beispiel: Benutzer-ID in der Beiträge-Tabelle.
- Vorteil: Schnelle Abrufbarkeit aller Beiträge für ein bestimmtes Profil.
- Einschränkung: Stellt die Referenzintegrität automatisch sicher.
Viele-zu-Viele-Beziehungen
Follower und Folgen sind das klassische Beispiel. Ein Benutzer folgt vielen anderen, und ein Benutzer wird von vielen anderen gefolgt. Hierfür ist eine Verbindungstabelle erforderlich, um die Beziehung aufzulösen.
- Verbindungstabelle: Enthält Benutzer-ID A und Benutzer-ID B.
- Zeitstempel: Als die folgende Aktion erfolgte.
- Status: Ausstehend, akzeptiert oder blockiert.
- Leistung: Die Indizierung ist bei beiden Fremdschlüsseln entscheidend.
Rekursive Beziehungen
Einige Beziehungen beinhalten den gleichen Entitätstyp. Ein Kommentar kann Antworten auf Antworten haben. Dies erzeugt eine Baumstruktur, die in standardmäßigen relationalen Modellen schwer abfragbar ist.
- Eltern-ID: Ein Fremdschlüssel, der auf die Kommentar-ID verweist.
- Tiefe: Die Beschränkung der Rekursionstiefe verhindert Endlosschleifen.
- Materialisierte Pfade: Speichern des Pfads des Baums für eine schnellere Durchquerung.
| Beziehungstyp | Beispiel | Implementierungsstrategie | Leistungseinfluss |
|---|---|---|---|
| Eins-zu-Viele | Benutzer – Beiträge | Fremdschlüssel im Kind | Niedrig (Standardindizierung) |
| Viele-zu-Viele | Benutzer – Folgt | Zwischentabelle | Mittel (Join-Aufwand) |
| Rekursiv | Kommentar – Antwort | Selbstverweisender Fremdschlüssel | Hoch (komplexe Abfragen) |
| Assoziativ | Tag – Benutzer | Komposite Schlüssel | Mittel (Suche intensiv) |
Normalisierung vs. Denormalisierung ⚖️
In sozialen Mediensystemen überwiegt die Leseleistung oft die Schreibleistung. Benutzer erwarten, dass Feeds sofort geladen werden, selbst wenn Millionen von Datensätzen betroffen sind. Dies erfordert ein sorgfältiges Gleichgewicht zwischen Normalisierung und Denormalisierung.
Der Fall für Normalisierung
Die Normalisierung gewährleistet die Datenintegrität und reduziert Redundanz. Sie ist für zentrale Daten unerlässlich, die sich nicht häufig ändern.
- Datenkonsistenz: Aktualisierungen erfolgen an einer Stelle.
- Speichereffizienz: Weniger Speicherplatz für doppelte Daten.
- Wartbarkeit: Einfacher, Geschäftsregeln durchzusetzen.
Der Fall für Denormalisierung
Die Denormalisierung beinhaltet die Duplizierung von Daten, um die Anzahl der benötigten Joins bei Lesevorgängen zu reduzieren. Dies ist bei sozialen Feeds üblich.
- Lesegeschwindigkeit: Weniger Joins bedeuten schnellere Abfrageausführung.
- Caching: Aggregierte Zähler (z. B. Gesamtanzahl an Likes) direkt gespeichert.
- Schreibaufwand: Aktualisierungen müssen auf alle Kopien übertragen werden.
Hybrider Ansatz
Eine praktische Strategie besteht darin, das Kernschema zu normalisieren, während häufig gelesene Metriken denormalisiert werden. Zum Beispiel kann der Benutzernamen in der Post-Tabelle neben der Benutzer-ID gespeichert werden. Dadurch wird ein Join beim Anzeigen des Beitrags vermieden, allerdings mit dem Preis einer gelegentlichen Synchronisationslogik.
Skalierungsstrategien für ERDs 🚀
Wenn die Benutzerbasis wächst, muss das Schema sich weiterentwickeln, um den steigenden Lasten gerecht zu werden. Vertikale Skalierung hat Grenzen; horizontale Skalierung erfordert spezifische Überlegungen bezüglich des Schemas.
Partitionierung
Die Partitionierung teilt große Tabellen in kleinere, handhabbare Teile auf. In sozialen Medien wird die Daten oft nach Benutzer-ID oder Datum partitioniert.
- Horizontale Partitionierung: Aufteilung der Benutzer auf verschiedene Shards basierend auf ID-Bereichen.
- Vertikale Partitionierung: Verschieben von selten genutzten Spalten in eine separate Tabelle.
- Datumspartitionierung:Archivierung alter Beiträge in Tabellen für kalt gespeicherte Daten.
Indizierungsstrategien
Indizes sind entscheidend für die Abfrageleistung, verlangsamen aber das Schreiben. Es ist ein strategischer Ansatz für die Indizierung erforderlich.
- Komposite Indizes:Abdecken häufiger Abfragemuster (z. B. Benutzer-ID + Zeitstempel).
- Teilweise Indizes:Indizierung nur relevanter Zeilen (z. B. aktive Beiträge).
- Suchindizes:Verwendung von Volltext-Suchmaschinen zur Inhaltsentdeckung.
Datenschutz- und Compliance-Betrachtungen 🛡️
Modernes Datenmodellieren muss Datenschutzvorschriften wie DSGVO und CCPA berücksichtigen. Die Schema-Design beeinflusst, wie leicht Daten anonymisiert oder gelöscht werden können.
Recht auf Vergessenwerden
Benutzer können die Löschung ihrer Daten anfordern. Das ERD muss kaskadierende Löschungen oder weiche Löschungen unterstützen, ohne die Referenzintegrität zu verletzen.
- Weiche Löschungen:Hinzufügen eines „is_deleted“-Flags anstelle des Entfernens von Zeilen.
- Verwaiste Daten:Behandlung von Daten, die auf einen gelöschten Benutzer verweisen.
- Anonymisierung:Ersetzen von persönlichen Kennungen durch Hashwerte.
Datenminimierung
Speichern Sie nur Daten, die strikt notwendig sind. Die übermäßige Sammlung von Metadaten erhöht die Speicherkosten und Datenschutzrisiken.
- Aufbewahrungsrichtlinien:Automatische Löschung von Protokollen nach einer festgelegten Zeitspanne.
- Feingranulare Berechtigungen:Zugriffssteuerungen auf Zeilenebene.
- Verschlüsselung:Sensible Felder werden ruhend verschlüsselt.
Umgang mit Metadaten und Protokollen 📉
Jenseits der zentralen Entitäten generieren Systeme riesige Mengen an Metadaten. Dazu gehören Analysen, Fehlerprotokolle und Prüfverläufe. Diese sollten die Haupttransaktionsstruktur nicht verunreinigen.
Trennung der Anliegen
Halten Sie die transaktionsbasierte Datenbank sauber. Übertragen Sie umfangreiche Protokollierung und Analysen auf getrennte Systeme.
- Ereignisströme:Verwenden Sie Nachrichtenwarteschlangen für asynchrone Protokollierung.
- Analysentabellen:Getrennte Tabellen für historische Trends.
- Zeitreihendaten:Spezifische Speicherung für Metriken über die Zeit.
Iterativer Gestaltungsprozess 🔄
ERDs sind selten beim ersten Entwurf perfekt. Die Anforderungen an soziale Medien entwickeln sich schnell, wenn neue Funktionen eingeführt werden. Der Gestaltungsprozess sollte iterativ sein.
- Prototyp:Erstellen Sie ein minimales, funktionsfähiges Schema für die zentrale Funktion.
- Test:Durchführen eines Lasttests mit realistischen Datenmengen.
- Refaktorisieren:Passen Sie die Beziehungen anhand von Leistungsengpässen an.
- Dokumentieren:Stellen Sie sicher, dass Diagramme für zukünftige Entwickler aktuell bleiben.
Häufige Fallen, die vermieden werden sollten ⚠️
Selbst erfahrene Architekten begehen Fehler bei der Modellierung sozialer Daten. Die Erkennung dieser Muster hilft, zukünftige Probleme zu vermeiden.
- Überindizierung:Zu viele Indizes verlangsamen Schreibvorgänge erheblich.
- Ignorieren von Zeitzonen:Das Speichern von Zeitstempeln ohne Zeitzonenkontext führt zu Verwirrung.
- Hartkodierte Werte:Vermeiden Sie die Einbettung von Geschäftslogik in das Schema (z. B. spezifische Statuswerte).
- Ignorieren von Weichlöschungen:Harte Löschungen können Fremdschlüsselbeschränkungen über das Netzwerk hinweg brechen.
- Unbegrenztes Wachstum: Das Nicht-Archivieren alter Daten führt zu Tabellen-Schwellenbildung.
Abschließende Überlegungen für zukünftiges Wachstum 🔮
Der Aufbau einer sozialen Medienplattform ist ein langfristiges Unterfangen. Das Datenmodell muss flexibel genug sein, um Änderungen zu ermöglichen, ohne eine vollständige Neuschreibung zu erfordern. Konzentrieren Sie sich auf Klarheit, Skalierbarkeit und Wartbarkeit. Regelmäßige Überprüfungen des Schemas anhand realer Nutzungsmuster stellen sicher, dass das System auch bei Wachstum stabil bleibt.
- Versionsverwaltung: Planen Sie Schema-Migrationen, die Rückwärtskompatibilität unterstützen.
- Überwachung: Verfolgen Sie die Abfrageleistung, um frühzeitig Schwächen im Schema zu erkennen.
- Feedback aus der Community: Hören Sie darauf, wie die Daten tatsächlich von dem Ingenieurteam genutzt werden.
Durch die Einhaltung dieser Strategien können Entwickler eine solide Grundlage für benutzerzentrierte Anwendungen schaffen. Das ERD ist nicht nur ein Diagramm; es ist die strukturelle Integrität der gesamten Plattform. Sorgfältige Planung heute verhindert erhebliche technische Schulden in Zukunft.