











La arquitectura de bases de datos comienza con una visión. Antes de escribir una sola línea de código, las estructuras de datos deben ser conceptualizadas, organizadas y validadas. El Diagrama Entidad-Relación (ERD) sirve como plano para esta estructura, traduciendo los requisitos del mundo real en un modelo visual. Sin embargo, un diagrama por sí solo no almacena datos. El esquema lógico es la implementación tangible que rige cómo se almacena, recupera y protege la información de forma física.
Transitar desde el ERD abstracto hasta el esquema concreto requiere precisión. Implica mapear entidades a tablas, relaciones a claves y atributos a columnas. Este proceso determina la integridad y el rendimiento de todo el sistema. Comprender los matices de esta traducción asegura que la base de datos permanezca robusta bajo carga y adaptable a necesidades futuras.
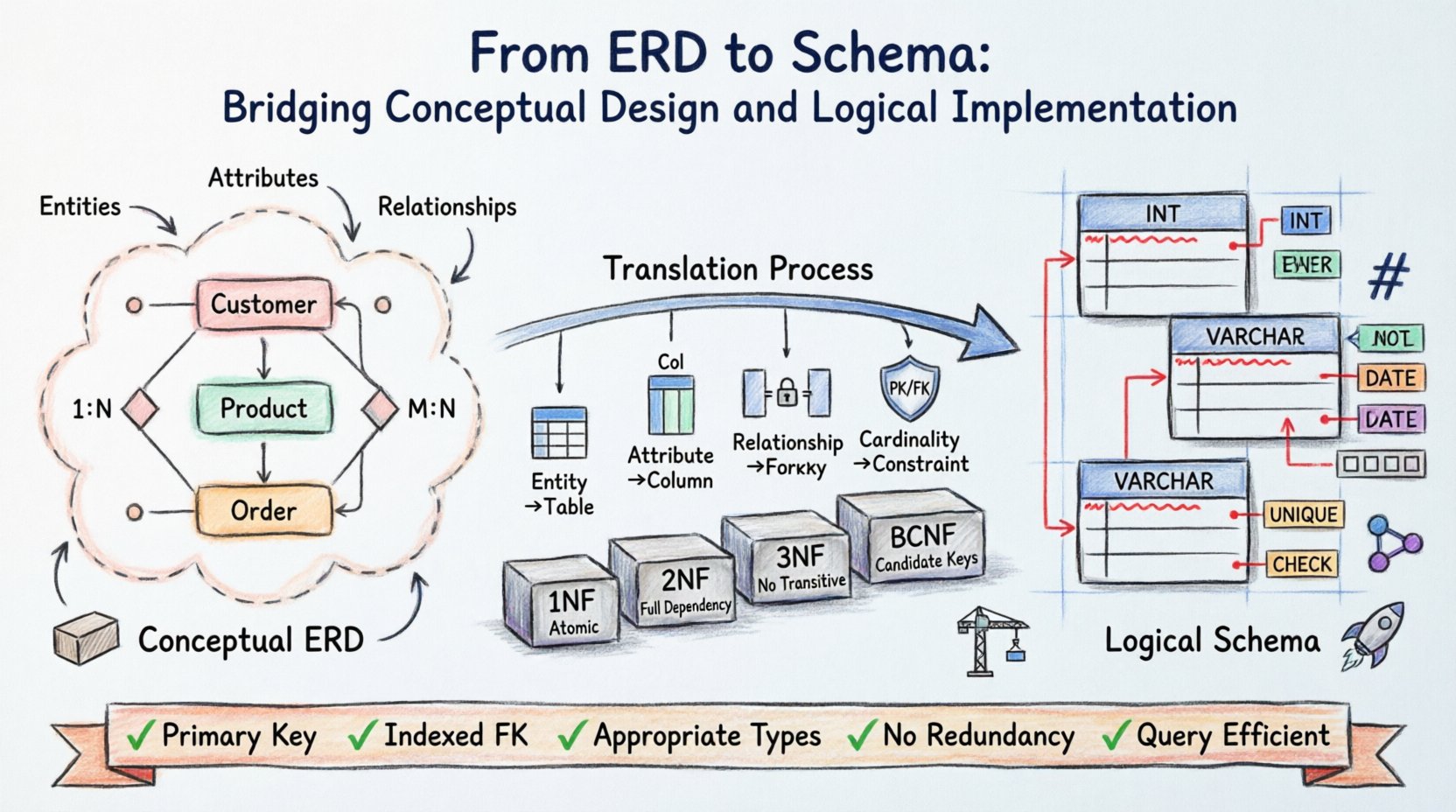
Comprender la fundación conceptual 🧱
El Diagrama Entidad-Relación opera a nivel conceptual. Se enfoca en el ‘qué’ más que en el ‘cómo’. En esta fase, los interesados y arquitectos identifican los objetos centrales de interés dentro del dominio.
- Entidades: Estas representan objetos o conceptos distintos, como un Cliente, Producto o Pedido.
- Atributos: Estos definen las propiedades de una entidad, como un Nombre, Precio o Fecha.
- Relaciones: Estas describen cómo interactúan las entidades, como un Cliente realizando un Pedido.
En esta etapa, las restricciones técnicas son secundarias. El objetivo es la claridad. Si el modelo conceptual es ambiguo, el esquema resultante será defectuoso. Los errores comunes incluyen confundir atributos con entidades o no definir correctamente la cardinalidad.
Cardinalidad y Participación
Uno de los aspectos más críticos del diseño de ERD es definir la cardinalidad. Esto determina la relación cuantitativa entre entidades.
- Uno a uno (1:1): Un registro único en la Tabla A se relaciona con exactamente un registro en la Tabla B.
- Uno a muchos (1:N): Un registro único en la Tabla A se relaciona con múltiples registros en la Tabla B.
- Muchos a muchos (M:N): Varios registros en la Tabla A se relacionan con varios registros en la Tabla B.
Las restricciones de participación refinen aún más este modelo. ¿La relación es obligatoria o opcional? Si un Cliente debe realizar un Pedido, la participación es obligatoria. Si puede existir sin un Pedido, es opcional. Estas distinciones influyen directamente en la posibilidad de valores nulos en las columnas del esquema lógico.
El Esquema Lógico: Implementación estructural 🏗️
El esquema lógico cierra la brecha entre la teoría y el almacenamiento físico. Mientras que el ERD es independiente de la plataforma, el esquema lógico prepara los datos para mecanismos de almacenamiento específicos. Esta capa introduce reglas específicas sobre tipos de datos, restricciones y normalización.
A diferencia del modelo conceptual, el esquema lógico debe abordar explícitamente la integridad de los datos. Esto se logra mediante claves primarias, claves foráneas y restricciones únicas. Estas reglas evitan registros huérfanos y aseguran que las relaciones permanezcan consistentes.
Reglas clave de traducción
Traducir claves desde el ERD hasta el esquema requiere un cumplimiento estricto de la teoría relacional.
- Claves primarias: Cada entidad debe tener un identificador único. En el ERD, esto suele subrayarse. En el esquema, se convierte en la restricción PRIMARY KEY.
- Claves foráneas: Las relaciones se implementan mediante claves foráneas. Una relación muchos a muchos generalmente requiere una tabla asociativa con dos claves foráneas para resolver la cardinalidad.
- Claves compuestas: Si una entidad depende de múltiples atributos para su unicidad, estos deben combinarse en la definición lógica.
Mapeo de entidades a tablas 🔄
El proceso de convertir una entidad en una tabla es sencillo, pero requiere atención al detalle. Cada entidad generalmente se mapea en una tabla. Sin embargo, escenarios complejos pueden exigir dividir o fusionar tablas.
Manejo de especialización y generalización
Cuando las entidades comparten atributos comunes, pueden modelarse como subclases. Por ejemplo, una Vehículo entidad podría tener subclases como Coche y Camión.
Existen dos estrategias principales para implementar esto en un esquema:
- Herencia de tabla única: Todas las subclases se almacenan en una sola tabla con una columna discriminadora. Esto reduce las uniones, pero aumenta los valores NULL.
- Herencia de tabla de clases: Cada subclase obtiene su propia tabla vinculada al padre mediante una clave foránea. Esto es más normalizado, pero requiere consultas más complejas.
Mapeo de atributos
Los atributos del diagrama ER deben mapearse a definiciones de columnas. No todos los atributos se traducen directamente.
- Atributos simples: Se mapean directamente a columnas.
- Atributos compuestos: Deben dividirse en columnas individuales (por ejemplo, Dirección se divide en Calle, Ciudad, Código Postal).
- Atributos multivaluados: No pueden almacenarse en una sola columna. Estos requieren una tabla separada vinculada mediante una clave foránea (por ejemplo, Números de teléfono para un Usuario).
- Atributos derivados: Estos se calculan a partir de otros datos (por ejemplo, Edad a partir de la Fecha de Nacimiento). A menudo se omiten del esquema para evitar redundancia, a menos que la optimización del rendimiento sea crítica.
Profundización en la normalización 📊
La normalización es el proceso de organizar los datos para reducir la redundancia y mejorar la integridad. Al pasar del diagrama ER al esquema, los diseñadores deben asegurarse de que el modelo cumpla con formas normales específicas.
Primera forma normal (1FN)
Una tabla está en 1FN si contiene valores atómicos. Ninguna columna debe contener una lista o un conjunto de valores. Si una entidad tiene múltiples valores para un único atributo, se debe crear una nueva tabla.
Segunda Forma Normal (2FN)
La 2FN requiere que la tabla esté en 1FN y no tenga dependencias parciales. Todos los atributos no clave deben depender de toda la clave primaria, no solo de parte de ella. Esto es crucial para tablas con claves compuestas.
Tercera Forma Normal (3FN)
La 3FN requiere que no existan dependencias transitivas. Un atributo no clave no debe depender de otro atributo no clave. Por ejemplo, si Ciudad depende de Código Postal, y Código Postal depende de ID del Cliente, Ciudad debe moverse a una tabla separada.
Forma Normal de Boyce-Codd (BCNF)
La BCNF es una versión más estricta de la 3FN. Maneja casos en los que una tabla tiene múltiples claves candidatas y un atributo no clave depende de un subconjunto de esas claves.
| Forma Normal | Requisito | Enfoque |
|---|---|---|
| 1FN | Valores Atómicos | Eliminar grupos repetidos |
| 2FN | Dependencia Completa | Eliminar dependencias parciales |
| 3FN | Sin Dependencia Transitiva | Eliminar dependencias indirectas |
| BCNF | Dependencia de clave candidata | Elimine las claves superpuestas |
Tipos de datos y restricciones 🔒
Elegir el tipo de datos correcto es fundamental para la eficiencia de almacenamiento y el rendimiento de las consultas. El diagrama ER rara vez especifica tipos de datos exactos, dejando esto para la fase de diseño lógico.
Entero frente a numérico
Los enteros almacenan números enteros y son más rápidos para cálculos. Los tipos numéricos o decimales se utilizan para datos financieros para preservar la precisión. Usar enteros para el dinero puede provocar errores de redondeo.
Fecha y hora
Las marcas de tiempo deben distinguir entre UTC y la hora local. Almacenar fechas como cadenas es un error común que impide una clasificación y filtrado eficientes. Utilice los tipos de fecha estándar proporcionados por el motor de base de datos.
Restricciones
Las restricciones hacen cumplir las reglas del negocio a nivel de base de datos.
- NO NULO:Asegura que una columna siempre contenga un valor.
- ÚNICO:Evita valores duplicados en una columna.
- CHECK:Valida los datos frente a una condición específica (por ejemplo, Edad > 0).
- VALOR POR DEFECTO:Proporciona un valor predeterminado si no se suministra ninguno.
Errores comunes y validación ⚠️
Aunque se tenga un plan sólido, pueden ocurrir errores durante la implementación. Reconocer estos errores temprano ahorra mucho tiempo más adelante.
- Sobrenormalización:Crear demasiadas tablas puede hacer que las consultas sean lentas y complejas. La desnormalización puede ser necesaria para cargas de trabajo con muchas lecturas.
- Claves débiles:Usar claves naturales (como direcciones de correo electrónico) como claves primarias es arriesgado. Pueden cambiar y causar problemas en cadena. Las claves de sustitución (IDs autoincrementales) suelen ser más seguras.
- Índices faltantes:Las claves foráneas deben estar indexadas. Sin ellas, la unión de tablas se convierte en un cuello de botella de rendimiento.
- Dependencias circulares:Asegurarse de que las tablas no creen bucles en las relaciones es fundamental para mantener la integridad referencial.
Lista de verificación de validación
Antes de finalizar el esquema, revise esta lista de verificación:
- ¿Tiene cada tabla una clave primaria?
- ¿Están todas las claves foráneas correctamente indexadas?
- ¿Son los tipos de datos adecuados para el volumen esperado?
- ¿Hay columnas redundantes que se puedan eliminar?
- ¿El esquema permite ejecutar las consultas requeridas de forma eficiente?
Consideraciones de rendimiento 🚀
El esquema lógico no se trata solo de corrección; también se trata de velocidad. A medida que los datos crecen, la estructura debe manejar una carga mayor.
Particionamiento
Las tablas grandes pueden dividirse en piezas más pequeñas y manejables. Esto se puede hacer horizontalmente (por filas) o verticalmente (por columnas). El particionamiento permite que las consultas accedan solo a los segmentos de datos relevantes.
Patrones arquitectónicos
Patrones de diseño como el particionamiento distribuyen los datos entre múltiples servidores. Esto requiere una planificación cuidadosa durante la fase de diseño lógico para asegurar que los datos relacionados permanezcan juntos cuando sea posible.
Resumen de las mejores prácticas ✅
Construir un esquema de base de datos es un proceso iterativo. Requiere equilibrar la pureza teórica con las limitaciones prácticas.
- Documente todo:Mantenga una documentación clara que vincule los elementos del diagrama ERD con las definiciones del esquema.
- Control de versiones:Trate los cambios en el esquema como código. Utilice scripts de migración para rastrear las modificaciones con el tiempo.
- Revise periódicamente:A medida que evolucionan las necesidades del negocio, también debe evolucionar el esquema. Programa auditorías periódicas para asegurar que esté alineado con los requisitos actuales.
- Colabore:Involucre a desarrolladores, analistas y partes interesadas desde temprano. Perspectivas diferentes revelan casos extremos que un solo diseñador podría pasar por alto.
La transición del diagrama Entidad-Relación al esquema lógico es la columna vertebral de la ingeniería de datos. Transforma ideas abstractas en un sistema funcional. Al seguir las reglas de normalización, seleccionar tipos de datos adecuados y anticipar las necesidades de rendimiento, la base de datos resultante servirá como una fundación confiable para las aplicaciones.
En última instancia, la calidad del esquema determina la longevidad del sistema. Un diseño bien estructurado minimiza la deuda técnica y facilita el crecimiento futuro. Enfóquese en la claridad, la integridad y la escalabilidad para construir sistemas que resistan la prueba del tiempo.