











Construir una infraestructura de base de datos sólida requiere precisión en cada etapa del desarrollo. El Diagrama de Entidad-Relación (ERD) sirve como plano de esta estructura. Define cómo interactúan las entidades de datos, cómo fluye la información y cómo se mantiene la integridad a lo largo de todo el ciclo de vida del sistema. Saltarse una revisión exhaustiva del ERD puede conducir a reingenierías costosas, corrupción de datos y cuellos de botella de rendimiento en el futuro. Esta guía proporciona una lista de verificación detallada y accionable para validar su esquema antes de comprometerse con la implementación.
Los arquitectos de bases de datos y los desarrolladores deben abordar el diseño de esquemas con una mirada crítica. El costo de corregir un error estructural en producción es significativamente mayor que el esfuerzo necesario para arreglarlo durante la fase de diseño. Al seguir un proceso de revisión estructurado, los equipos aseguran que la base de datos resultante respalde la lógica de negocio, cumpla con los principios de normalización y permanezca escalable.
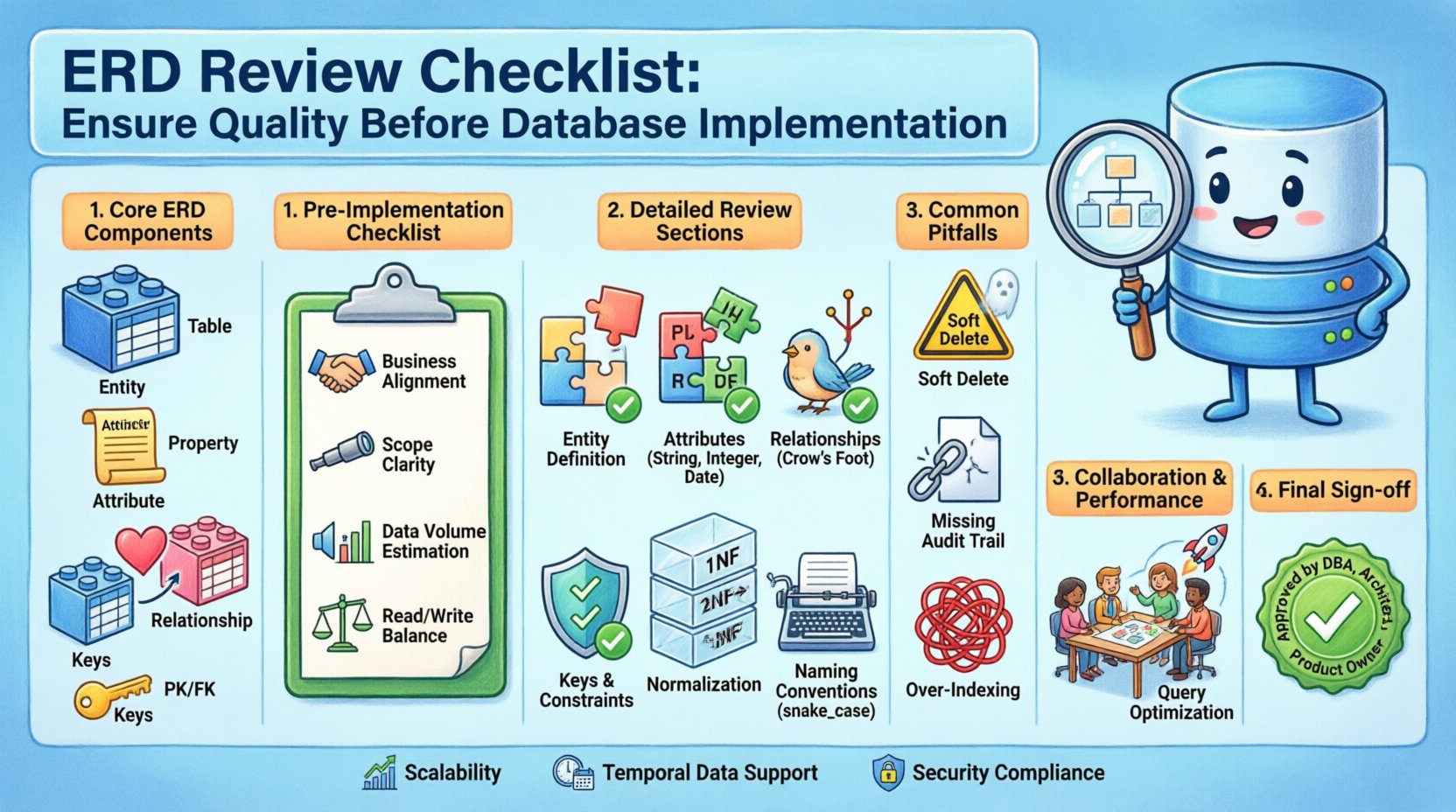
Comprender los componentes principales de un ERD 🔍
Antes de adentrarse en la lista de verificación, es esencial comprender los bloques de construcción fundamentales que conforman un Diagrama de Entidad-Relación estándar. Estos componentes forman el vocabulario de su modelo de datos.
- Entidades: Estas representan los objetos o conceptos del mundo real sobre los cuales se almacena información. En un contexto relacional, las entidades suelen mapearse a tablas.
- Atributos: Estos describen las propiedades o características de una entidad. Se mapean a columnas dentro de una tabla.
- Relaciones: Estas definen las asociaciones entre entidades. Indican cómo los datos en una tabla se conectan con los datos en otra.
- Cardinalidades y claves: La cardinalidad define la relación numérica entre entidades (por ejemplo, uno a uno, muchos a muchos). Las claves aseguran la identificación única y la conectividad.
Un ERD de alta calidad debe articular claramente estos elementos. La ambigüedad en el diagrama se traduce directamente en ambigüedad en el código, lo que conduce a errores de implementación.
Pasos de validación previa a la implementación ✅
Antes de aplicar cualquier ítem específico de la lista de verificación, el contexto general de la base de datos debe alinearse con los requisitos del negocio. Esta fase asegura que el modelo sea adecuado para su propósito.
- Alineación con los requisitos del negocio: Verifique que cada entidad y relación se asocie con una regla de negocio o historia de usuario específica.
- Definición del alcance: Confirme los límites de los datos. ¿Estamos diseñando para una sola aplicación, un microservicio o un almacén a nivel empresarial?
- Estimación del volumen de datos: Considere el volumen esperado de registros. Esto influye en las decisiones sobre estrategias de indexación y particionado.
- Relación de lectura/escritura: Comprenda el perfil de carga de trabajo. Una aplicación con alta carga de lectura puede requerir desnormalización, mientras que un sistema con alta carga de escritura prioriza una integridad estricta.
Lista de verificación detallada para revisar el ERD 📝
Esta sección desglosa los atributos técnicos específicos que requieren una revisión detallada. Utilice esta lista como herramienta de verificación durante sus sesiones de revisión de diseño.
1. Definición de entidad y tabla
Cada entidad en el diagrama debe ser distinta y bien definida. Un error común es crear entidades superpuestas que deberían fusionarse, o dividir un concepto único en múltiples tablas innecesariamente.
- Distinción: Asegúrese de que cada tabla represente un concepto único. Evite tablas que almacenen datos similares para propósitos diferentes sin una distinción clara.
- Granularidad: Verifique si las tablas son demasiado granulares. Una división excesiva puede provocar combinaciones complejas y degradación del rendimiento.
- Convenciones de nomenclatura:Verifique la consistencia. Las tablas deben usar nombres en singular (por ejemplo,
Clienteen lugar deClientes) para alinearse con los patrones de mapeo orientados a objetos. - Metadatos: Asegúrese de que las marcas de tiempo de creación y modificación se incluyan en cada tabla para respaldar la auditoría y el seguimiento de la trazabilidad de los datos.
2. Atributos y tipos de datos
Los atributos definen la naturaleza de los datos almacenados. Seleccionar el tipo de datos correcto es fundamental para la eficiencia de almacenamiento y el rendimiento de las consultas.
- Tipos de datos principales: Asegúrese de que los enteros, cadenas y booleanos se usen correctamente. Evite usar cadenas para fechas o números.
- Límites de longitud: Defina longitudes máximas para los campos de cadena. Esto evita el crecimiento excesivo del almacenamiento y garantiza la consistencia durante la validación de entrada.
- Posibilidad de nulidad: Defina explícitamente si un campo puede ser nulo. La mayoría de los campos no deberían permitir valores nulos a menos que la lógica de negocio lo permita.
- Valores por defecto: Verifique si los valores por defecto son necesarios. Por ejemplo, un campo de estado podría tener como valor predeterminado ‘activo’ en lugar de requerir una inserción inicial.
- Valores enumerados: Cuando sea apropiado, use listas enumeradas para restringir los valores. Esto evita la entrada de datos inválidos en la fuente.
3. Relaciones y cardinalidad
Las relaciones son el pegamento que mantiene unido el modelo de datos. Los errores aquí provocan registros huérfanos o duplicación de datos.
| Tipo de relación | Descripción | Nota de implementación |
|---|---|---|
| Uno a uno (1:1) | Un registro en la tabla A se vincula con exactamente un registro en la tabla B. | Normalmente se implementa colocando la clave primaria de A como clave foránea en B. |
| Uno a muchos (1:N) | Un registro en la tabla A se vincula con muchos registros en la tabla B. | Coloque la clave primaria de A como clave foránea en B. |
| Muchos a muchos (M:N) | Los registros en A pueden vincularse con muchos en B, y viceversa. | Requiere una tabla de unión que enlace las dos claves primarias. |
- Verificación de cardinalidad:Revise la notación de pie de cuervo o equivalente para asegurarse de que la dirección de la relación sea correcta.
- Opcionalidad:Distinga entre relaciones obligatorias y opcionales. Una restricción de clave foránea debe reflejar si un registro relacionado debe existir.
- Relaciones recursivas:Verifique la existencia de tablas que se refieran a sí mismas (por ejemplo, una
Empleadotabla que se vincula con unGerenteID dentro de la misma tabla). - Dependencias circulares:Asegúrese de que las relaciones no creen bucles circulares que complejen la carga o la consulta de datos.
4. Claves y restricciones
Las claves son el mecanismo para la unicidad y la conexión. Sin claves adecuadas, la integridad de los datos colapsa.
- Claves primarias:Cada tabla debe tener una clave primaria. Debe ser única y nunca nula.
- Claves sustitutas:Considere el uso de identificadores generados por el sistema (claves sustitutas) en lugar de claves de negocio naturales. Esto evita que los cambios en la lógica de negocio afecten la estructura de la base de datos.
- Claves foráneas:Verifique que todas las claves foráneas hagan referencia a claves primarias válidas en las tablas padres.
- Restricciones únicas:Identifique los campos que deben ser únicos (por ejemplo, direcciones de correo electrónico, números de cuenta) pero que no sean la clave primaria.
- Restricciones de verificación:Busque reglas lógicas que no puedan ser impuestas únicamente por los tipos de datos (por ejemplo,
fecha_iniciodebe ser anterior afecha_fin).
5. Normalización
La normalización reduce la redundancia y mejora la integridad de los datos. Mientras que la sobre-normalización puede afectar el rendimiento, la sub-normalización genera anomalías.
- Primera Forma Normal (1FN): Asegúrese de valores atómicos. No grupos repetidos ni arreglos dentro de una sola celda.
- Segunda Forma Normal (2FN): Asegúrese de que todos los atributos no clave dependan completamente de la clave primaria, no solo de parte de ella.
- Tercera Forma Normal (3FN): Asegúrese de que no existan dependencias transitivas. Los atributos no clave deben depender únicamente de la clave primaria, no de otros atributos no clave.
- Estrategia de Denormalización: Si el rendimiento es una preocupación, documente dónde y por qué se aplica la denormalización. Esta debe ser una decisión consciente, no un descuido.
6. Convenciones de Nomenclatura
Una nomenclatura consistente reduce la carga cognitiva para los desarrolladores y disminuye la probabilidad de errores.
- Nombres de Tablas: Use sustantivos en singular (por ejemplo,
Orden, noOrdenes). - Nombres de Columnas: Use snake_case para mantener la consistencia (por ejemplo,
creado_en). - Evite palabras reservadas: Asegúrese de que ningún nombre de columna entre en conflicto con palabras clave de SQL (por ejemplo,
usuario,orden,grupo). - Claridad:Los nombres deben ser descriptivos. Evite las abreviaturas a menos que sean estándar en la industria.
Errores comunes que deben evitarse ⚠️
Incluso los diseñadores con experiencia pueden pasar por alto detalles críticos. Ser consciente de las trampas comunes ayuda a mantener un esquema limpio.
- Ignorar las eliminaciones suaves: Decida si los datos deben eliminarse permanentemente o marcarse lógicamente como inactivos. Una
is_deletedbandera suele ser más segura que la eliminación física. - Falta de registros de auditoría: Asegúrese de que exista un mecanismo para rastrear quién modificó los datos y cuándo. Esto es crucial para el cumplimiento.
- Sobrecarga de índices:Agregar demasiados índices ralentiza las operaciones de escritura. Revise los patrones de consulta para justificar la colocación de índices.
- Valores codificados: Evite almacenar valores específicos como códigos de país como cadenas si pueden asignarse a una tabla de referencia.
- Suposiciones implícitas: No asuma que un campo es opcional si la lógica de negocio lo requiere. Documente las suposiciones con claridad.
Colaboración y documentación 🤝
Un diagrama ER no es solo un artefacto técnico; es una herramienta de comunicación. Debe ser comprendido por los interesados, no solo por los administradores de bases de datos.
- Revisión por parte de los interesados: Haga que los analistas de negocios revisen el diagrama para confirmar que coincide con su modelo mental del proceso.
- Control de versiones: Trátelo como código. Guárdelo en control de versiones para rastrear los cambios con el tiempo.
- Documentación: Incluya un diccionario de datos junto con el diagrama. Defina el significado de cada campo y su rango permitido.
- Gestión de cambios: Establezca un proceso para modificar el esquema. Los cambios deben revisarse y aprobarse, no aplicarse de forma improvisada.
Consideraciones de rendimiento 🚀
Aunque el ERD es lógico, debe respaldar objetivos de rendimiento físico. Algunas decisiones de diseño tienen implicaciones directas en el rendimiento.
- Complejidad de unión:Minimice el número de uniones necesarias para consultas comunes. Las uniones complejas pueden sobrecargar al optimizador de consultas.
- Preparación para particionar:Diseñe las tablas teniendo en cuenta la partición si se espera que el conjunto de datos crezca enormemente.
- Búsqueda:Asegúrese de que los campos que se buscan con frecuencia estén indexados. Considere los requisitos de búsqueda de texto completo para campos con muchos textos.
- Concurrencia:Evalúe las estrategias de bloqueo. Los entornos de alta concurrencia pueden requerir niveles de aislamiento específicos o diseños de tablas.
Criterios finales de aprobación 🏁
Antes de proceder con la implementación, el ERD debe cumplir con criterios específicos de aceptación. Esto garantiza una transición fluida desde el diseño hasta el desarrollo.
- Completitud: Todas las entidades y relaciones requeridas por el alcance están presentes.
- Consistencia:Las convenciones de nomenclatura y los tipos de datos se aplican de forma uniforme.
- Integridad:Las restricciones de clave primaria y clave foránea están correctamente definidas.
- Claridad: El diagrama es legible y comprensible para el equipo de ingeniería.
- Aprobación: Los principales interesados han aprobado el diseño.
Cumplir con esta lista de verificación asegura que la base de datos sea sólida. Reduce la deuda técnica y facilita ciclos de desarrollo más fluidos. Un ERD bien revisado es el primer paso hacia una arquitectura de datos resiliente.
Revisión del ERD para escalabilidad futura
Diseñar para el presente es insuficiente. El modelo de datos debe acomodar el crecimiento sin requerir una reconstrucción completa.
- Escalabilidad horizontal:Considere cómo la fragmentación podría afectar las relaciones. Las claves foráneas entre fragmentos son complejas y a menudo se evitan.
- Escalabilidad vertical:Asegúrese de que los tipos de datos puedan manejar valores más grandes. Por ejemplo, usar
BIGINTen lugar deINTpara contadores. - Banderas de funcionalidad: Diseñe tablas para admitir banderas de funcionalidad suaves. Esto permite activar o desactivar nuevas funcionalidades sin cambios en el esquema.
- Compatibilidad hacia atrás: Planee las migraciones de esquema. Añadir columnas no debe romper las consultas existentes.
Manejo de casos especiales como datos temporales
El tiempo es una dimensión crítica en el modelado de datos. Manejar correctamente la historia a menudo se pasa por alto.
- Fechas efectivas: Para entidades que cambian con el tiempo, incluya fechas de inicio y fin para rastrear la historia.
- Zonas horarias: Almacene las marcas de tiempo en UTC para evitar ambigüedades entre regiones.
- Instantáneas: Decida si se requieren instantáneas históricas. Esto podría requerir una tabla de historial separada.
- Tablas temporales: Algunos sistemas admiten tablas temporales nativas. Evalúe si esto se ajusta a las restricciones arquitectónicas.
Seguridad y cumplimiento en el esquema
La seguridad de los datos comienza a nivel de tabla. La estructura debe respaldar los requisitos de privacidad y protección.
- Manejo de información personal identificable (PII): Identifique los campos de información personal identificable. Estos requieren cifrado o enmascaramiento.
- Control de acceso: Diseñe roles y permisos basados en la sensibilidad de los datos definida en el esquema.
- Cifrado en reposo: Asegúrese de que el motor de base de datos admita el cifrado para campos sensibles.
- Políticas de retención: Defina campos que indiquen cuándo se puede eliminar la data según los requisitos legales.
Al aplicar rigurosamente estas verificaciones, la base de datos se convierte en un activo confiable en lugar de una carga. La inversión de esfuerzo en la fase de revisión del ERD rinde dividendos en mantenibilidad y rendimiento.