











L’architecture des bases de données commence par une vision. Avant qu’une seule ligne de code ne soit écrite, les structures de données doivent être conceptualisées, organisées et validées. Le diagramme Entité-Relation (ERD) sert de plan directeur pour cette structure, traduisant les exigences du monde réel en un modèle visuel. Toutefois, un schéma seul ne stocke pas de données. Le schéma logique est l’implémentation concrète qui régule le stockage physique, la récupération et la sécurisation des informations.
Passer du ERD abstrait au schéma concret exige une précision. Il s’agit de mapper les entités aux tables, les relations aux clés, et les attributs aux colonnes. Ce processus détermine l’intégrité et les performances de l’ensemble du système. Comprendre les subtilités de cette traduction garantit que la base de données reste robuste sous charge et adaptable aux besoins futurs.
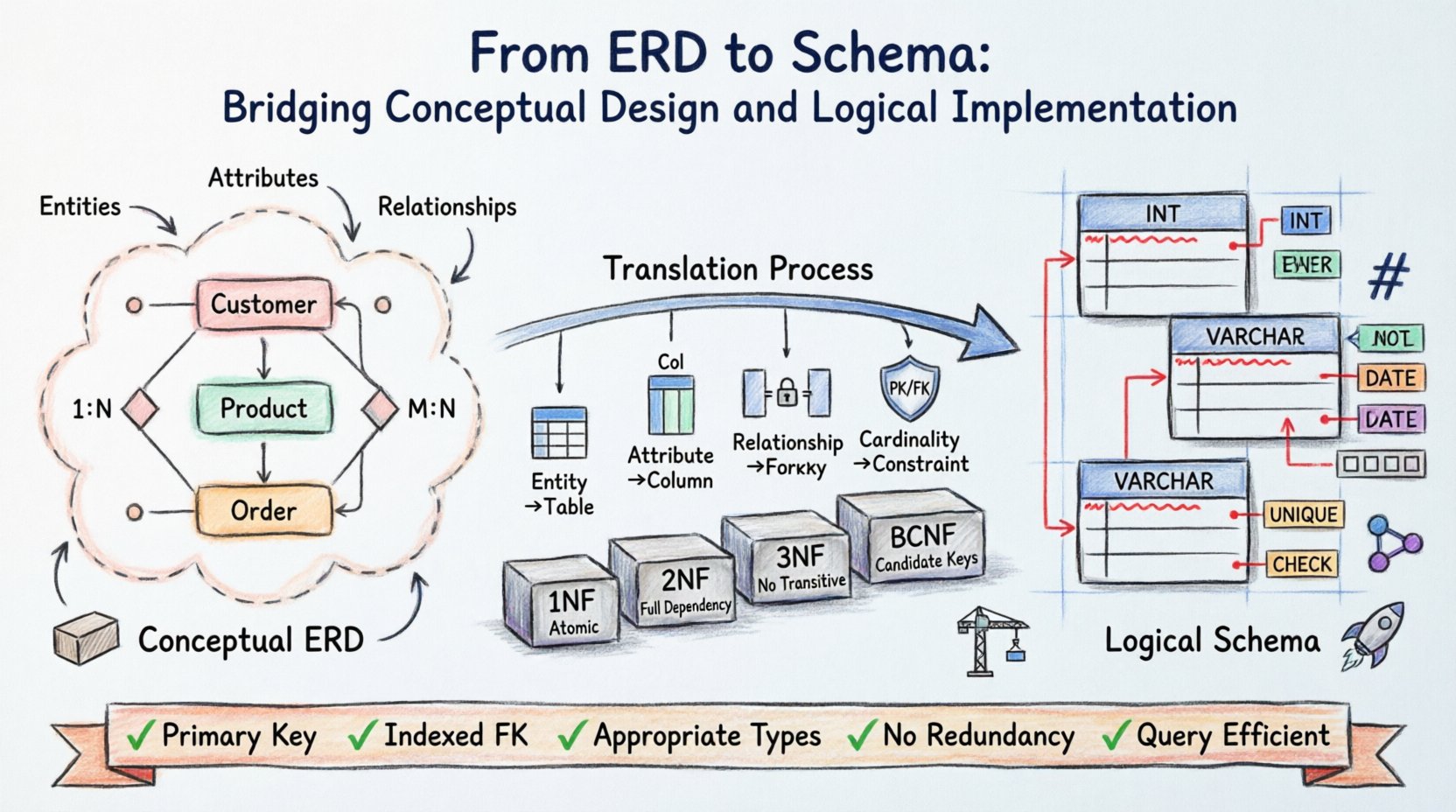
Comprendre la fondation conceptuelle 🧱
Le diagramme Entité-Relation fonctionne au niveau conceptuel. Il se concentre sur le « quoi » plutôt que sur le « comment ». À cette phase, les parties prenantes et les architectes identifient les objets centraux d’intérêt au sein du domaine.
- Entités : Elles représentent des objets ou des concepts distincts, tels qu’un Client, un Produit ou une Commande.
- Attributs : Ils définissent les propriétés d’une entité, comme un Nom, un Prix ou une Date.
- Relations : Elles décrivent la manière dont les entités interagissent, par exemple un Client passant une Commande.
À ce stade, les contraintes techniques sont secondaires. L’objectif est la clarté. Si le modèle conceptuel est ambigu, le schéma résultant sera défectueux. Les erreurs courantes incluent la confusion entre attributs et entités, ou l’oubli de définir correctement la cardinalité.
Cardinalité et participation
L’un des aspects les plus critiques de la conception d’un ERD est la définition de la cardinalité. Elle détermine la relation quantitative entre les entités.
- Un pour un (1:1) : Un enregistrement unique dans la table A est lié à exactement un enregistrement dans la table B.
- Un pour plusieurs (1:N) : Un enregistrement unique dans la table A est lié à plusieurs enregistrements dans la table B.
- Plusieurs pour plusieurs (M:N) : Plusieurs enregistrements dans la table A sont liés à plusieurs enregistrements dans la table B.
Les contraintes de participation affinent davantage ce modèle. La relation est-elle obligatoire ou facultative ? Si un Client doit passer une Commande, la participation est obligatoire. Si un Client peut exister sans commande, elle est facultative. Ces distinctions influencent directement la possibilité de valeurs nulles dans les colonnes du schéma logique.
Le schéma logique : mise en œuvre structurale 🏗️
Le schéma logique comble le fossé entre la théorie et le stockage physique. Alors que l’ERD est indépendant de la plateforme, le schéma logique prépare les données pour des mécanismes de stockage spécifiques. Ce niveau introduit des règles spécifiques concernant les types de données, les contraintes et la normalisation.
Contrairement au modèle conceptuel, le schéma logique doit traiter explicitement l’intégrité des données. Cela est réalisé grâce aux clés primaires, aux clés étrangères et aux contraintes uniques. Ces règles empêchent les enregistrements orphelins et garantissent que les relations restent cohérentes.
Règles de traduction des clés
Traduire les clés du ERD vers le schéma exige une stricte application de la théorie relationnelle.
- Clés primaires : Chaque entité doit posséder un identifiant unique. Dans l’ERD, cela est souvent souligné. Dans le schéma, cela devient la contrainte PRIMARY KEY.
- Clés étrangères : Les relations sont implémentées via des clés étrangères. Une relation plusieurs pour plusieurs nécessite généralement une table d’association avec deux clés étrangères pour résoudre la cardinalité.
- Clés composées : Si une entité dépend de plusieurs attributs pour l’unicité, ceux-ci doivent être combinés dans la définition logique.
Mappage des entités aux tables 🔄
Le processus de conversion d’une entité en table est simple mais nécessite une attention aux détails. Chaque entité correspond généralement à une seule table. Toutefois, des scénarios complexes peuvent nécessiter une séparation ou une fusion.
Gestion de la spécialisation et de la généralisation
Lorsque des entités partagent des attributs communs, elles peuvent être modélisées comme des sous-classes. Par exemple, une Véhicule entité pourrait avoir des sous-classes telles que Voiture et Camion.
Il existe deux stratégies principales pour implémenter cela dans un schéma :
- Héritage sur une seule table : Toutes les sous-classes sont stockées dans une seule table avec une colonne discriminante. Cela réduit les jointures, mais augmente les valeurs NULL.
- Héritage sur des tables de classes : Chaque sous-classe obtient sa propre table liée à la parente par une clé étrangère. Cela est plus normalisé, mais nécessite des requêtes plus complexes.
Mappage des attributs
Les attributs du diagramme entité-relation doivent être mappés aux définitions de colonnes. Tous les attributs ne se traduisent pas directement.
- Attributs simples : S’attribuent directement aux colonnes.
- Attributs composés : Doivent être divisés en colonnes individuelles (par exemple, Adresse se divise en Rue, Ville, Code postal).
- Attributs multivalués : Ne peuvent pas être stockés dans une seule colonne. Ils nécessitent une table séparée liée par une clé étrangère (par exemple, les numéros de téléphone pour un utilisateur).
- Attributs dérivés : Ce sont des attributs calculés à partir d’autres données (par exemple, l’âge à partir de la date de naissance). Ils sont souvent omis du schéma pour éviter la redondance, sauf si l’optimisation des performances est critique.
Approfondissement de la normalisation 📊
La normalisation est le processus d’organisation des données afin de réduire la redondance et d’améliorer l’intégrité. En passant du diagramme entité-relation au schéma, les concepteurs doivent s’assurer que le modèle respecte des formes normales spécifiques.
Première forme normale (1NF)
Une table est en 1NF si elle contient des valeurs atomiques. Aucune colonne ne doit contenir une liste ou un ensemble de valeurs. Si une entité possède plusieurs valeurs pour un attribut unique, une nouvelle table doit être créée.
Deuxième forme normale (2NF)
La 2NF exige que la table soit en 1NF et qu’elle n’ait pas de dépendances partielles. Tous les attributs non clés doivent dépendre de la clé primaire entière, et non seulement d’une partie de celle-ci. Cela est crucial pour les tables possédant des clés composées.
Troisième forme normale (3NF)
La 3NF exige qu’il n’y ait pas de dépendances transitives. Un attribut non clé ne doit pas dépendre d’un autre attribut non clé. Par exemple, si Ville dépend de Code postal, et Code postal dépend de ID client, Ville doit être déplacé dans une table séparée.
Forme normale de Boyce-Codd (BCNF)
La BCNF est une version plus stricte de la 3NF. Elle traite les cas où une table possède plusieurs clés candidates et où un attribut non clé dépend d’un sous-ensemble de ces clés.
| Forme normale | Exigence | Objectif |
|---|---|---|
| 1NF | Valeurs atomiques | Éliminer les groupes répétitifs |
| 2NF | Dépendance complète | Éliminer les dépendances partielles |
| 3NF | Pas de dépendance transitive | Éliminer les dépendances indirectes |
| BCNF | Dépendance de clé candidate | Éliminer les clés chevauchantes |
Types de données et contraintes 🔒
Choisir le bon type de données est essentiel pour l’efficacité du stockage et les performances des requêtes. Le modèle entité-association précise rarement les types de données exacts, laissant cette tâche à l’étape de conception logique.
Entier vs. Numérique
Les entiers stockent des nombres entiers et sont plus rapides pour les calculs. Les types numériques ou décimaux sont utilisés pour les données financières afin de préserver la précision. Utiliser des entiers pour les devises peut entraîner des erreurs d’arrondi.
Date et heure
Les horodatages doivent distinguer entre UTC et l’heure locale. Stocker les dates sous forme de chaînes de caractères est une erreur courante qui empêche un tri et un filtrage efficaces. Utilisez les types de date standard fournis par le moteur de base de données.
Contraintes
Les contraintes imposent des règles métier au niveau de la base de données.
- NOT NULL :Assure qu’une colonne contient toujours une valeur.
- UNIQUE :Empêche les valeurs en double dans une colonne.
- CHECK :Valide les données par rapport à une condition spécifique (par exemple, Age > 0).
- DEFAULT :Fournit une valeur par défaut si aucune n’est fournie.
Péchés courants et validation ⚠️
Même avec un plan solide, des erreurs peuvent survenir lors de la mise en œuvre. Reconnaître ces pièges tôt permet d’économiser beaucoup de temps plus tard.
- Sur-normalisation :Créer trop de tables peut ralentir et compliquer les requêtes. Une dénormalisation peut être nécessaire pour les charges de travail intensives en lecture.
- Clés faibles :Utiliser des clés naturelles (comme les adresses e-mail) comme clés primaires est risqué. Elles peuvent changer et entraîner des problèmes en chaîne. Les clés de substitution (identifiants auto-incrémentés) sont souvent plus sûres.
- Index manquants :Les clés étrangères doivent être indexées. Sans elles, la jointure des tables devient un goulot d’étranglement des performances.
- Dépendances circulaires :S’assurer que les tables ne créent pas de boucles dans les relations est essentiel pour maintenir l’intégrité référentielle.
Liste de contrôle de validation
Avant de finaliser le schéma, passez en revue cette liste de vérification :
- Chaque table dispose-t-elle d’une clé primaire ?
- Toutes les clés étrangères sont-elles correctement indexées ?
- Les types de données sont-ils adaptés au volume attendu ?
- Y a-t-il des colonnes redondantes pouvant être supprimées ?
- Le schéma permet-il de répondre efficacement aux requêtes nécessaires ?
Considérations sur les performances 🚀
Le schéma logique ne concerne pas seulement la correction ; il concerne aussi la vitesse. À mesure que les données augmentent, la structure doit pouvoir gérer une charge accrue.
Partitionnement
Les grandes tables peuvent être divisées en morceaux plus petits et plus faciles à gérer. Cela peut se faire horizontalement (par lignes) ou verticalement (par colonnes). Le partitionnement permet aux requêtes d’accéder uniquement aux segments de données pertinents.
Modèles architecturaux
Des modèles de conception comme le fractionnement (sharding) répartissent les données sur plusieurs serveurs. Cela nécessite une planification soigneuse pendant la phase de conception logique afin de garantir que les données liées restent ensemble, lorsque cela est possible.
Résumé des meilleures pratiques ✅
La construction d’un schéma de base de données est un processus itératif. Elle exige un équilibre entre la pureté théorique et les contraintes pratiques.
- Documentez tout :Maintenez une documentation claire reliant les éléments du diagramme entité-relation à leurs définitions dans le schéma.
- Contrôle de version :Traitez les modifications du schéma comme du code. Utilisez des scripts de migration pour suivre les modifications au fil du temps.
- Revoyez régulièrement :À mesure que les besoins métiers évoluent, le schéma doit aussi évoluer. Prévoyez des audits périodiques pour garantir l’alignement avec les exigences actuelles.
- Collaborez :Impliquez les développeurs, les analystes et les parties prenantes dès le début. Des points de vue différents révèlent des cas limites que peut manquer un seul concepteur.
La transition du diagramme entité-relation au schéma logique est le pilier du génie des données. Elle transforme des idées abstraites en un système fonctionnel. En respectant les règles de normalisation, en choisissant des types de données appropriés et en anticipant les besoins de performance, la base de données résultante servira de fondation fiable aux applications.
En fin de compte, la qualité du schéma détermine la durée de vie du système. Une conception bien structurée minimise la dette technique et facilite la croissance future. Concentrez-vous sur la clarté, l’intégrité et la scalabilité pour construire des systèmes capables de résister au fil du temps.