











Dans le paysage de l’architecture des données, peu de concepts suscitent autant de confusion que la relation many-to-many. Lors de la conception d’un diagramme entité-association (ERD), rencontrer une situation où une entité se connecte à plusieurs instances d’une autre entité, et inversement, nécessite une approche structurelle spécifique. Les systèmes de gestion de bases de données relationnelles ne supportent pas nativement les associations many-to-many directes. Ils exigent une structure intermédiaire pour préserver l’intégrité des données et assurer une interrogation efficace. Ce guide explore les méthodes autoritatives pour résoudre ces associations, garantissant que votre modèle de données reste robuste, évolutif et normalisé.
Que vous conceviez un système pour les dossiers académiques, la gestion des stocks ou les autorisations d’utilisateur, les principes de résolution de ces cardinalités restent constants. Comprendre les mécanismes sous-jacents évite les anomalies futures et simplifie la maintenance. Nous allons aller au-delà des définitions superficielles pour examiner les exigences structurelles, les règles de normalisation et les stratégies d’implémentation qui définissent la modélisation professionnelle des données.
🔍 Comprendre la cardinalité dans les ERD
La cardinalité définit la relation numérique entre les entités dans une base de données. Elle précise le nombre d’instances d’une entité qui peuvent ou doivent être associées à chaque instance d’une autre entité. Dans la notation des ERD, cela est souvent représenté par des lignes reliant les entités, les crocs de corbeau indiquant le côté « plusieurs » et les lignes droites ou les traits simples indiquant le côté « un ».
Il existe trois cardinalités principales :
- Un à un (1:1) :Un seul enregistrement dans l’entité A est lié à un seul enregistrement dans l’entité B. Exemple : une personne et son passeport.
- Un à plusieurs (1:M) :Un seul enregistrement dans l’entité A est lié à plusieurs enregistrements dans l’entité B. Exemple : un client passant plusieurs commandes.
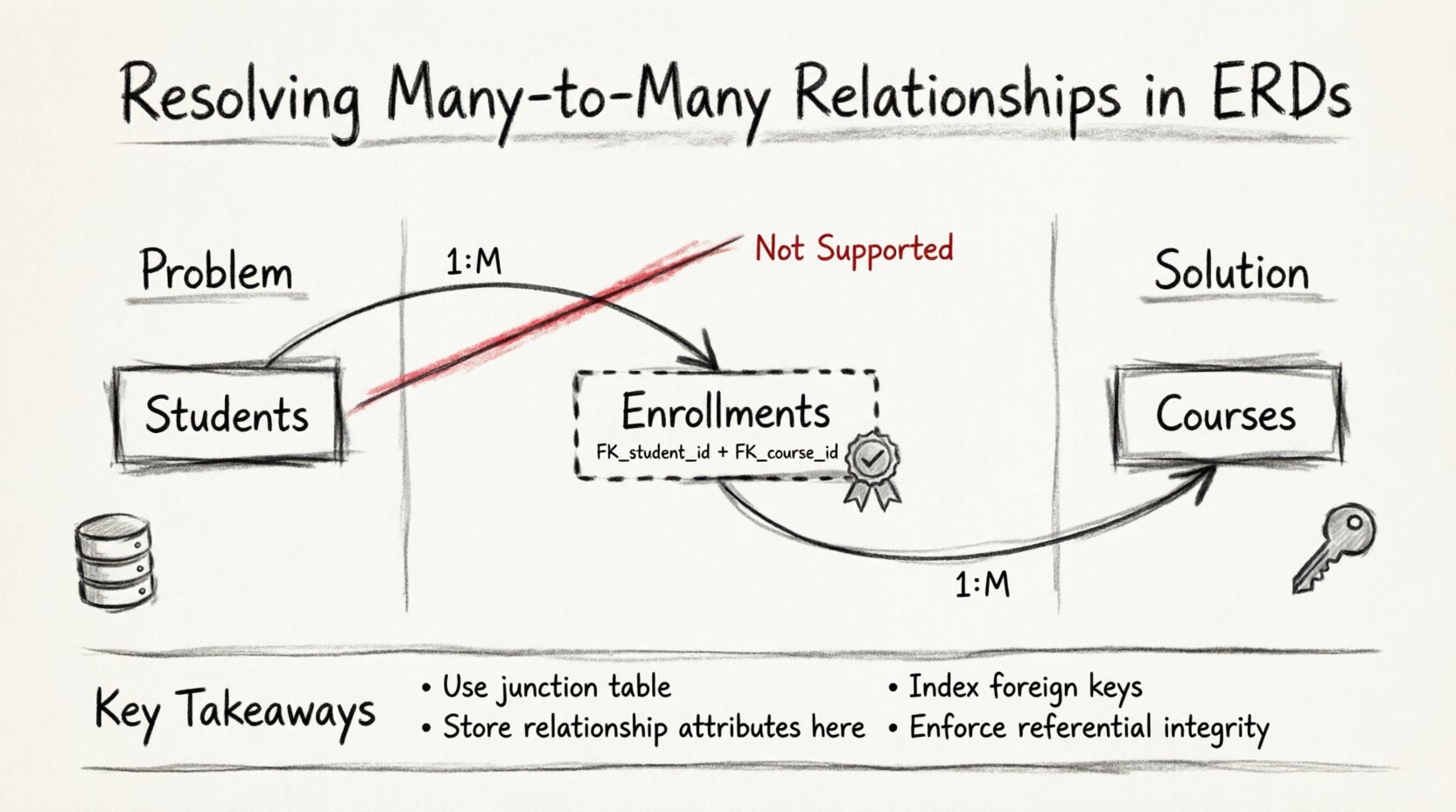
- Plusieurs à plusieurs (M:N) :Plusieurs enregistrements dans l’entité A sont liés à plusieurs enregistrements dans l’entité B. Exemple : des étudiants s’inscrivant à plusieurs cours, et des cours contenant plusieurs étudiants.
Bien que les relations 1:1 et 1:M soient faciles à implémenter dans un schéma physique de base de données, la relation M:N pose un défi unique. La théorie relationnelle stipule qu’une cellule de table ne doit contenir que des valeurs atomiques. Un lien direct entre deux tables où une seule ligne dans la table A pourrait théoriquement référencer plusieurs lignes dans la table B viole ce principe au niveau physique.
🚫 Pourquoi les relations M:M directes échouent dans les modèles relationnels
Le modèle relationnel, établi par E.F. Codd, repose sur le concept de relations (tables) où chaque colonne représente un attribut spécifique et chaque ligne représente une instance unique. Il existe deux raisons principales pour lesquelles un lien many-to-many direct est impossible dans une base de données relationnelle standard :
- Absence de prise en charge native :Les moteurs de base de données n’autorisent pas une colonne de clé étrangère à contenir plusieurs valeurs. Une clé étrangère doit pointer vers une seule clé primaire dans une autre table. Elle ne peut pas pointer vers une liste de clés.
- Anomalies d’insertion et de suppression :Si vous tentez de stocker plusieurs identifiants dans une seule cellule (par exemple, « Student_ID : 101, 102, 103 »), vous commettez une violation de la Première Forme Normale (1NF). Cela rend l’interrogation, la mise à jour et la suppression des relations spécifiques coûteuses en termes de calcul et sujettes aux erreurs.
Par conséquent, pour stocker ces données de manière efficace, la relation elle-même doit être traitée comme une entité. Cette transformation est la technique fondamentale pour résoudre cette complexité.
🧱 Technique 1 : L’entité associative (table de jonction)
La solution standard pour résoudre une relation many-to-many est la création d’une entité associative, communément appelée table de jonction ou table de pont. Cette table est placée physiquement entre les deux entités principales et transforme la connexion directe en deux relations un-à-plusieurs.
Lorsque vous introduisez une table de jonction, la relation M:N d’origine est décomposée en :
- Une relation un-à-plusieurs entre l’entité A et la table de jonction.
- Une relation un-à-plusieurs entre l’entité B et la table de jonction.
Structure d’une table de jonction :
- Clés étrangères :Elle doit contenir au moins deux colonnes de clés étrangères. L’une fait référence à la clé primaire de l’entité A, et l’autre à la clé primaire de l’entité B.
- Clé primaire composée :Souvent, la combinaison de ces deux clés étrangères sert de clé primaire pour la table de jonction. Cela garantit qu’une paire spécifique d’entités ne peut pas être liée plus d’une fois, sauf si la relation est intrinsèquement multivaluée.
- Clés de substitution : Dans certains cas, un ID unique auto-incrémenté est ajouté à la table de jonction. Cela est utile si la relation peut avoir plusieurs instances avec des attributs différents (par exemple, un étudiant peut être inscrit à un cours à plusieurs reprises avec des notes différentes au fil des années).
Scénario d’exemple :
Prenons un système de bibliothèque. Un Livre peut être emprunté par de nombreux Usagers. Un Usager peut emprunter de nombreux Livres.
- Sans résolution : vous ne pouvez pas lier directement une ligne de livre à plusieurs lignes d’usagers.
- Avec résolution : créez une Journal_des_emprunts table.
- Le Journal_des_emprunts contient
ID_LivreetID_Usager.
Cette structure permet à la base de données de suivre exactement quel usager possède quel livre à tout moment donné, sans dupliquer les données de livre ou d’usager.
📝 Technique 2 : Gestion des attributs sur les relations
Une distinction cruciale dans la modélisation des diagrammes entité-association est de savoir si la relation entre les entités possède ses propres données. Dans un lien simple, la connexion existe ou non. Toutefois, dans de nombreux scénarios du monde réel, la relation elle-même possède des propriétés.
Par exemple, dans un Projet et Employé scénario, un employé peut travailler sur plusieurs projets, et un projet peut avoir plusieurs employés. Mais la relation pourrait inclure :
- Rôle : L’employé est-il développeur, concepteur ou gestionnaire sur ce projet spécifique ?
- Heures attribuées : Combien d’heures par semaine sont attribuées à ce projet ?
- Date de début : Quand a commencé cette affectation ?
Si vous traitez la relation simplement comme un indicateur binaire, vous perdez ces données essentielles. La table d’association devient l’endroit idéal pour stocker ces attributs.
Règles d’implémentation :
- Ne stockez pas les attributs de relation dans les entités parentes. Ils n’appartiennent ni uniquement au Projet, ni uniquement à l’Employé.
- Placez toutes les données spécifiques à la relation dans la table d’association.
- Assurez-vous que la table d’association dispose d’un identifiant unique (composé ou artificiel) afin de permettre la mise à jour de ces attributs sans affecter les entités parentes.
Cette approche garantit la normalisation des données. Si vous deviez ajouter une Rôle colonne dans la Employé table, cela créerait une redondance si l’employé a plusieurs rôles sur des projets différents. La table d’association isole cette variation.
⚖️ Technique 3 : Normalisation et intégrité des données
Résoudre les relations M:N ne consiste pas seulement à lier des tables ; c’est respecter les principes de normalisation pour éviter les anomalies de données. La Troisième Forme Normale (3NF) est la cible standard pour la plupart des systèmes transactionnels.
Exigences de la Troisième Forme Normale (3NF) :
- La table doit être en Deuxième Forme Normale (2NF).
- Tous les attributs non clés doivent dépendre uniquement de la clé primaire.
En créant une table d’association, vous assurez que les données de relation dépendent de la clé composite de la table d’association, et non des clés individuelles des entités. Cela élimine les dépendances transitives.
Intégrité référentielle :
Les contraintes de clé étrangère sont essentielles dans la table d’association. Elles imposent les règles suivantes :
- Un
ID_Livredans le journal des emprunts doit exister dans la Livres table. - Un
ID_Patrondans le journal des emprunts doit exister dans la table Usagers table.
Cela empêche les enregistrements orphelins. Vous ne pouvez pas enregistrer un événement d’emprunt pour un livre qui n’existe pas dans le catalogue. Les moteurs de base de données imposent cela grâce aux actions CASCADE ou RESTREINDRE lors de la suppression.
📊 Comparaison des types de relations
Visualiser les différences entre les types de relations aide à choisir la bonne stratégie de modélisation. Le tableau ci-dessous résume les exigences structurelles et la complexité d’implémentation.
| Type de relation | Implémentation physique | Emplacement de la clé primaire | Complexité |
|---|---|---|---|
| Un à un (1:1) | Clé étrangère dans une table | L’une ou l’autre table | Faible |
| Un à plusieurs (1:M) | Clé étrangère dans la table « plusieurs » | Table primaire | Moyen |
| Plusieurs à plusieurs (M:N) | Table d’association séparée | Table d’association (composée) | Élevé |
Comme indiqué, la relation M:N nécessite le plus de surcharge structurelle. Cependant, cette surcharge est nécessaire pour garantir l’intégrité des données. Le coût d’un jointure supplémentaire lors d’une requête est souvent compensé par le coût d’une incohérence des données dans un schéma mal conçu.
🚀 Considérations sur les performances
L’ajout d’une table de jonction ajoute une couche d’indirection à vos requêtes. Lors de la récupération des données, vous devez joindre trois tables au lieu de deux. Dans les systèmes à fort volume, cela peut avoir un impact sur les performances si cela n’est pas correctement géré.
- Indexation : Chaque clé étrangère dans la table de jonction doit être indexée. Cela permet au moteur de base de données de localiser rapidement les lignes pour une entité spécifique sans scanner toute la table de jonction.
- Index composés : Dans certains cas, la création d’un index sur la combinaison des deux clés étrangères est plus efficace que des index séparés. Cela permet de soutenir les requêtes qui filtrent par les deux entités simultanément.
- Lecture vs. écriture : Les tables de jonction sont généralement très utilisées pour les écritures si les relations sont dynamiques. Elles sont très utilisées pour les lectures lors de la génération de rapports. Assurez-vous que votre stratégie d’indexation soutient le modèle d’opération dominant de votre application.
⚠️ Pièges courants et solutions
Même les modélisateurs expérimentés commettent des erreurs lors de la résolution des cardinalités. La prise de conscience des erreurs courantes peut éviter un temps de refonte considérable plus tard.
1. L’erreur « Une seule colonne »
Essayer de stocker plusieurs identifiants dans une seule colonne en utilisant des valeurs séparées par des virgules (par exemple, « 1, 2, 3 »). Cela viole les principes de base de données et rend les requêtes impossibles sans fonctions de traitement de chaînes. Utilisez toujours une ligne distincte pour chaque instance de relation.
2. Attributs redondants
Copier des attributs depuis les entités parentes vers la table de jonction sans nécessité. Si un attribut appartient à l’entité (par exemple, le nom d’un étudiant), il doit se trouver dans la table Étudiant, et non dans la table Inscription. Placez uniquement les données qui décrivent le lien lui-même.
3. Ignorer la nullabilité
Définir les clés étrangères comme pouvant être nulles alors qu’elles devraient être obligatoires. Si une relation est obligatoire (par exemple, une commande doit avoir un client), la clé étrangère ne doit pas autoriser les valeurs nulles. Cela impose les règles métier au niveau de la base de données.
4. Références circulaires
Créer une table de jonction qui se référence elle-même de manière inutile. Assurez-vous que la table de jonction ne lie que les deux entités distinctes impliquées dans la relation. Évitez de créer des boucles qui n’ont pas de fonctionnement utile.
🎨 Meilleures pratiques pour la représentation visuelle
Lors de la documentation de votre MCD, la clarté est primordiale. La représentation visuelle doit transmettre immédiatement la structure résolue à toute personne lisant le schéma.
- Nommez la table de jonction :Donnez-lui un nom descriptif. Au lieu de « Table3 », utilisez « Inscription_Etudiant_Cours ».
- Indiquez la cardinalité : Marquez clairement les lignes reliant la table de jonction aux entités parentes. Utilisez des crocs de corbeau du côté de la table de jonction pour montrer la relation « plusieurs » du point de vue des entités parentes.
- Affichez les attributs : Si la table de jonction possède des attributs (comme « Note » ou « Date »), indiquez-les explicitement dans le schéma. Cela met en évidence que la relation est plus qu’une simple liaison.
- Utilisez des styles de ligne différents : Certains outils de modélisation permettent d’utiliser des lignes pointillées pour les relations facultatives et des lignes pleines pour les relations obligatoires. La cohérence ici facilite la compréhension.
🔄 Relations récursives et M:N
Parfois, une relation plusieurs à plusieurs existe au sein d’une seule entité. Par exemple, un Employé peut gérer plusieurs autres Employés, et ces employés peuvent en gérer d’autres. Il s’agit d’une relation récursive M:N.
La résolution reste la même qu’une relation M:N standard. Vous créez toujours une table de jonction, mais les deux clés étrangères de cette table font référence à la clé primaire de la même entité.
- Entité : Employé
- Table de jonction : Gestion_Employé
- Clef étrangère 1 : ID_Gestionnaire (référence Employé)
- Clef étrangère 2 : ID_Subordonné (référence Employé)
Cette structure permet des hiérarchies organisationnelles complexes sans violer les règles de normalisation. Elle permet aux requêtes de parcourir plusieurs niveaux de profondeur de gestion.
🛡️ Contraintes de données et règles métiers
Les contraintes techniques ne suffisent pas ; les règles métiers doivent être appliquées. Une table de jonction constitue un endroit naturel pour appliquer ces règles.
- Contraintes uniques :Assurez-vous qu’une relation spécifique ne puisse pas être créée deux fois sauf si cela est intentionnel. Par exemple, un étudiant ne doit pas être inscrit deux fois dans le même groupe de cours au même semestre. Une contrainte unique sur la combinaison de Student_ID et Course_ID impose cela.
- Contraintes de vérification :Validez les données numériques. Par exemple, les « Heures_Affectées » dans une table de jonction de projet doivent être supérieures à zéro et inférieures à 40.
- Déclencheurs :Dans les systèmes complexes, des déclencheurs peuvent être nécessaires pour mettre à jour les tables de synthèse. Si la table de jonction change, une table de synthèse dans l’entité parente (par exemple, « Total_Projets_Par_Employé ») pourrait nécessiter une mise à jour automatique.
📈 Évolution du modèle
Les modèles évoluent au fur et à mesure que les exigences changent. Une relation qui commence par être plusieurs-à-plusieurs peut se simplifier en une-à-plusieurs si une règle métier change. Par exemple, si une politique change de manière à ce qu’un étudiant ne puisse s’inscrire qu’à un seul cours à la fois, la table de jonction peut être fusionnée à nouveau dans la table des étudiants.
Cependant, commencer par la table de jonction est généralement plus sûr. Elle offre la flexibilité maximale. Si la demande change plus tard pour autoriser plusieurs inscriptions, le schéma est déjà prêt. Si vous commencez par une table fusionnée, vous devrez effectuer une refonte ultérieurement.
📝 Résumé des points clés
Résoudre les relations plusieurs-à-plusieurs est une compétence fondamentale dans la conception de bases de données. Cela nécessite la création d’une structure intermédiaire pour maintenir l’intégrité des données et soutenir des requêtes efficaces. La table de jonction est la solution standard, qui décompose les associations complexes en liens un-à-plusieurs gérables.
- Résolvez toujours les M:N :Ne tentez jamais de stocker plusieurs clés étrangères dans une seule colonne.
- Utilisez des clés composées :La combinaison des clés étrangères sert souvent d’identifiant unique pour la relation.
- Stocker les données de relation :Placez les attributs spécifiques au lien dans la table de jonction.
- Indexer les clés étrangères :Les performances dépendent des recherches rapides des lignes de la table de jonction.
- Appliquer des contraintes :Utilisez des contraintes uniques et des références de clés étrangères pour éviter les données invalides.
En suivant ces techniques, vous assurez que votre schéma de base de données est résilient aux changements et capable de gérer des interactions de données complexes. L’effort investi dans une modélisation adéquate pendant la phase de conception porte ses fruits en termes de maintenabilité et de performance tout au long du cycle de vie du système.