











Les modèles de bases de données constituent le pilier de toute application robuste. Lorsque les entités, les relations et les attributs évoluent, le schéma sous-jacent doit s’adapter sans compromettre l’intégrité des données. Ce guide explore la discipline de la gestion des modifications des diagrammes Entité-Relation (ERD) grâce au contrôle de version. Nous examinerons comment maintenir la cohérence, suivre l’historique et collaborer efficacement au sein des équipes.
Les cycles de développement modernes exigent de la rapidité, mais la stabilité des données ne peut être sacrifiée au profit de la vitesse. Un schéma de base de données n’est pas simplement une collection de tables ; il s’agit d’un contrat entre l’application et le stockage persistant. Modifier ce contrat sans gouvernance adéquate introduit des risques. En traitant le modèle de base de données comme du code, les équipes peuvent appliquer des pratiques d’ingénierie éprouvées à l’infrastructure des données.
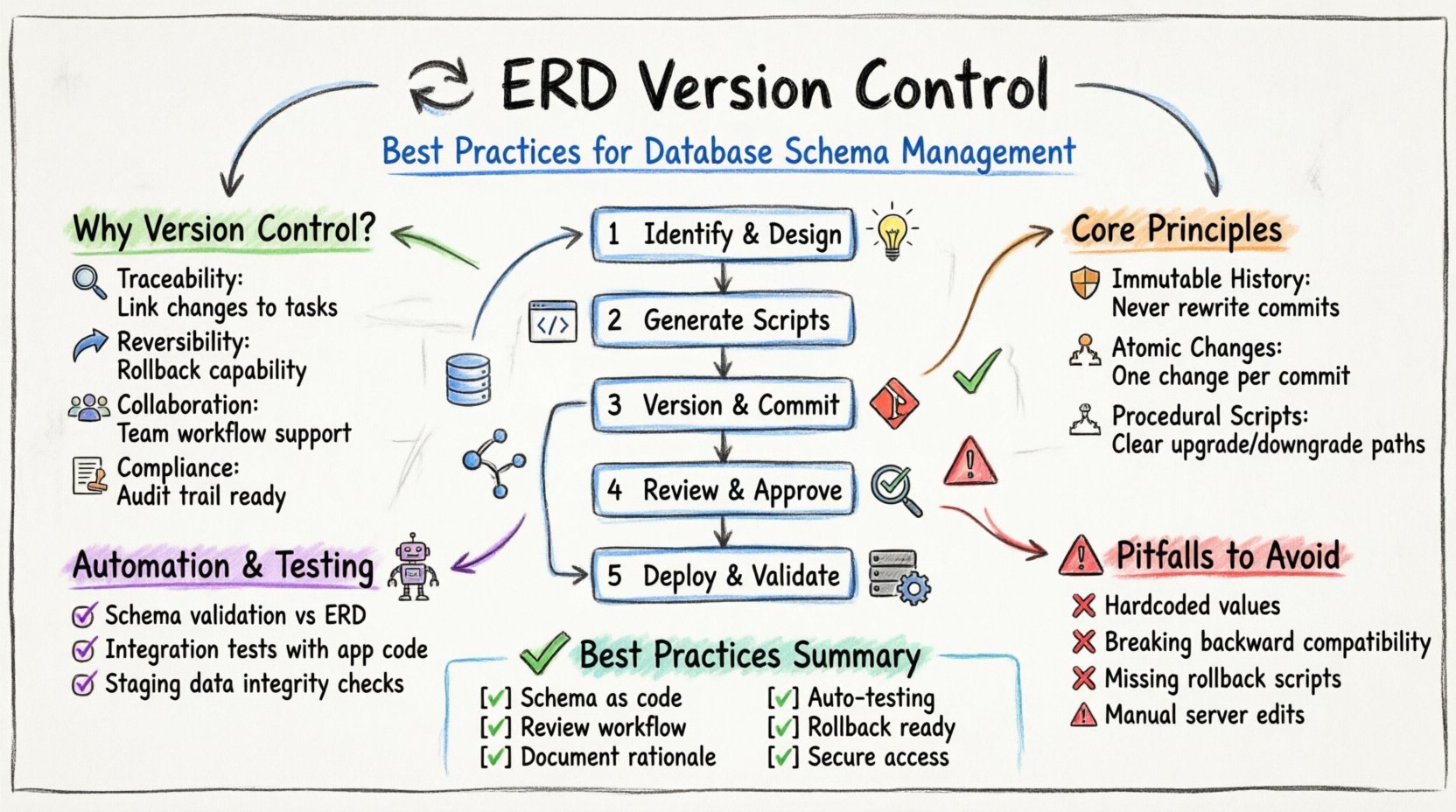
Pourquoi le versionnement du schéma de base de données est-il important 🤔
Le contrôle de version pour les modèles de bases de données est souvent négligé par rapport au code d’application. Les développeurs gèrent fréquemment la logique d’application dans des dépôts tout en traitant les modifications de base de données comme des scripts ponctuels. Ce décalage génère une dette technique et une fragilité opérationnelle. Une approche structurée de l’évolution du schéma garantit que chaque modification est documentée, revue et réversible.
Pensez aux conséquences d’un script de migration manquant. Dans un environnement de production, un changement de schéma inattendu peut bloquer l’ensemble du pipeline de déploiement. Sans historique des modifications, le débogage devient une simple supposition. Cette colonne existait-elle la semaine dernière ? L’index a-t-il été supprimé intentionnellement ? Le contrôle de version répond à ces questions de manière définitive.
- Traçabilité : Chaque modification est associée à une demande ou une tâche spécifique.
- Réversibilité : Si une modification provoque des problèmes, le système peut être restauré à un état antérieur.
- Collaboration : Plusieurs développeurs peuvent travailler sur différentes parties du modèle sans se chevaucher.
- Conformité : Les journaux d’audit satisfont aux exigences réglementaires en matière de gestion et d’accès aux données.
Principes fondamentaux de la stabilité du modèle 🛡️
Un contrôle de version efficace repose sur un ensemble de principes directeurs. Ces règles déterminent comment les modifications sont proposées, mises en œuvre et fusionnées. Le respect de ces normes minimise les conflits et maximise la fiabilité.
1. Historique immuable
Une fois qu’une version du schéma est validée dans le dépôt, elle ne doit jamais être modifiée. Même en cas de découverte d’une erreur, la bonne approche consiste à créer une nouvelle version qui corrige l’état précédent. La réécriture de l’historique brouille la chronologie des décisions et rend difficile l’audit des modifications.
2. Modifications atomiques
Les modifications doivent être effectuées en unités petites et logiques. Un seul commit doit traiter une exigence spécifique. Combiner des modifications non liées dans un seul paquet rend difficile l’isolement des problèmes. Si un déploiement échoue, connaître exactement la modification qui a causé le problème accélère la résolution.
3. Déclaratif vs. Procédural
Il existe deux grandes philosophies pour représenter l’état du schéma. Une approche se concentre sur l’état final souhaité (déclaratif), tandis que l’autre se concentre sur les étapes nécessaires pour atteindre cet état (procédural). Les deux ont leurs mérites, mais les scripts de migration procéduraux sont souvent préférés dans les environnements de production car ils offrent une voie claire pour la mise à jour et le retour en arrière.
Le cycle de vie d’un changement de schéma 🔄
La gestion d’une modification d’ERD implique un flux de travail structuré. Ce processus fait passer un concept d’un diagramme dans un outil de modélisation à un état validé dans une base de données en production. Suivre ce cycle de vie garantit que aucune étape n’est omise.
Étape 1 : Identification et conception
Le processus commence par l’identification du besoin de modification. Cela pourrait être une nouvelle table pour une fonctionnalité, une séparation d’une table existante, ou un changement dans une relation. La conception doit être capturée dans l’outil de modélisation d’ERD. À ce stade, l’accent est mis sur la cohérence logique plutôt que sur les détails d’implémentation physique.
- Définissez clairement l’entité et ses attributs.
- Établissez les clés primaires et étrangères.
- Revoyez les contraintes pour assurer l’intégrité des données.
- Documentez la justification du changement.
Étape 2 : Génération des scripts
Une fois le modèle logique approuvé, il doit être traduit en scripts exécutables. Cela consiste à générer des instructions SQL qui créent, modifient ou suppriment des objets de base de données. Il est essentiel de vérifier que ces scripts sont idempotents lorsque cela est possible, ce qui signifie qu’ils peuvent être exécutés plusieurs fois sans provoquer d’erreurs.
Étape 3 : Gestion de version et validation
Les scripts sont ajoutés au système de gestion de version. Chaque script doit posséder un identifiant unique, souvent une horodatage ou un numéro de séquence. Le message de validation doit décrire de manière complète le changement, en faisant référence à la tâche ou au problème associé. Cela établit un lien clair entre le code et les données.
Étape 4 : Revue et approbation
Avant la fusion, les modifications doivent être revues par des pairs. Cette étape est cruciale pour détecter des erreurs logiques que les outils automatisés pourraient manquer. Les validateurs doivent vérifier les conventions de nommage, les définitions de contraintes et les impacts potentiels sur les performances. Un processus d’approbation formel empêche les modifications non autorisées d’atteindre la branche principale.
Étape 5 : Déploiement et validation
La dernière étape consiste à appliquer les modifications à l’environnement cible. Cela est généralement effectué via une pipeline automatisée. La validation post-déploiement garantit que le schéma correspond à l’état attendu. Cela peut impliquer l’exécution de requêtes pour vérifier le nombre de colonnes ou la vérification des contraintes d’intégrité des données.
Gestion du développement simultané et des conflits ⚔️
Dans les équipes comprenant plusieurs développeurs, les modifications du schéma ont souvent lieu simultanément. Lorsque deux personnes modifient la même table ou relation, un conflit survient. La résolution de ces conflits nécessite une approche systématique.
La résolution des conflits ne consiste pas seulement à fusionner du texte ; elle consiste à fusionner des structures de données. La fusion de deux diagrammes ER est plus complexe que la fusion de deux fichiers de code source. Vous devez vous assurer que le modèle combiné reste logiquement cohérent.
- Communication : Les développeurs doivent coordonner leurs actions sur les entités partagées avant d’apporter des modifications.
- Stratégie de branche : Utilisez des branches fonctionnalités pour isoler les modifications. Fusionnez ces branches dans une branche d’intégration partagée avant la production.
- Fusion manuelle : Les outils automatisés ont souvent du mal à gérer les conflits de schéma. Une intervention humaine est fréquemment nécessaire pour reconcilier les différences.
- Résolution des conflits : Lorsqu’un conflit survient, l’équipe doit décider quelle version du changement a la priorité. Cette décision doit être documentée.
Scénarios courants de conflits
| Scénario | Description | Stratégie de résolution |
|---|---|---|
| Renommage de colonne | Deux développeurs renomment la même colonne différemment. | Convenez d’une convention de nommage standard et revenez au nom convenu. |
| Suppression de table | Un développeur supprime une table que quelqu’un d’autre est en train de modifier. | Assurez-vous que toutes les dépendances sont supprimées avant la suppression. Annulez la suppression si la table est encore nécessaire. |
| Migration de données | Les scripts déplacent les données dans des directions contradictoires. | Combinez la logique dans un seul script qui gère correctement toutes les transformations. |
| Ajout de contraintes | Deux développeurs ajoutent des contraintes à la même colonne. | Fusionnez les contraintes si elles sont compatibles, ou regroupez-les en une seule définition de contrainte. |
Automatisation de la validation et des tests 🤖
Les tests manuels sont sujets aux erreurs. L’automatisation garantit que les modifications de schéma répondent aux normes de qualité avant leur déploiement. L’intégration avec un pipeline d’intégration continue permet un retour immédiat sur chaque validation.
Validation du schéma
Les outils automatisés peuvent vérifier le SQL généré par rapport au modèle ERD. Cela garantit que la mise en œuvre physique correspond au design logique. Toute incohérence déclenche un échec dans le pipeline de construction, alertant immédiatement le développeur.
Tests d’intégration
Les modifications de schéma doivent être testées par rapport au code de l’application. Si une colonne est supprimée, l’application doit échouer à la compilation ou à l’exécution si elle fait toujours référence à cette colonne. Ce lien empêche les modifications destructrices de passer inaperçues.
Vérifications de l’intégrité des données
Exécuter la migration sur une base de données de préproduction avec des volumes de données similaires à la production aide à identifier les problèmes de performance. Les requêtes longues ou les conflits d’attente peuvent être détectés avant d’affecter les utilisateurs en direct. Cette étape est essentielle pour les environnements de base de données à grande échelle.
Documentation et traçabilité des modifications 📜
La documentation est souvent la première chose à être sacrifiée lorsque les délais approchent. Cependant, pour les modèles de base de données, la documentation est une forme d’assurance. Elle explique le « pourquoi » derrière le « quoi ».
Chaque modification doit être accompagnée d’une description. Cette description doit être stockée aux côtés des scripts dans le système de gestion de version. Elle doit répondre aux questions suivantes :
- Pourquoi cette modification est-elle nécessaire ?
- Quelles données sont concernées ?
- Y a-t-il des dépendances vis-à-vis d’autres systèmes ?
- Quelle est la durée prévue d’indisponibilité ?
Les traçabilités fournissent un historique des modifications effectuées et de leur date. Cela est essentiel pour la sécurité et la conformité. Si une fuite de données survient ou qu’une requête fonctionne mal, connaître la source du changement de schéma facilite le dépannage.
Péchés courants à éviter 🚫
Même avec un processus solide, des erreurs surviennent. Être conscient des pièges courants aide les équipes à les éviter.
Durcir les valeurs
Évitez d’incorporer des valeurs spécifiques à l’environnement dans les scripts de migration. Un script qui fonctionne en développement peut échouer en production si les chemins ou les identifiants sont durcis. Utilisez la gestion de configuration pour gérer ces différences.
Ignorer la compatibilité descendante
Les modifications destructrices doivent être évitées autant que possible. Si une colonne est supprimée, assurez-vous que l’application peut encore fonctionner. Une stratégie courante consiste à ajouter une nouvelle colonne, migrer les données, puis déprécié l’ancienne dans une version ultérieure.
Absence de plans de retour en arrière
Chaque script de migration doit avoir un script de retour en arrière correspondant. Si un déploiement échoue, vous devez pouvoir annuler la modification rapidement. Sans plan de retour en arrière, un déploiement infructueux peut laisser la base de données dans un état incohérent.
Édition manuelle des scripts
Ne modifiez jamais directement les scripts de base de données sur le serveur. Effectuez toujours les modifications dans le système de gestion de versions et déployez-les. Les modifications directes sont perdues au redémarrage et ne laissent aucune trace du changement.
Résumé des meilleures pratiques 🏁
Maintenir un modèle de base de données sain exige de la discipline. Il ne suffit pas de simplement écrire du code ; la couche de données doit être traitée avec le même rigueur. Le tableau suivant résume les points clés pour gérer les modifications du schéma ERD.
| Domaine | Meilleure pratique |
|---|---|
| Gestion des versions | Traitez le schéma comme du code dans un dépôt. |
| Flux de travail | Utilisez un processus défini de revue et d’approbation. |
| Tests | Automatisez les tests de validation et d’intégration. |
| Communication | Documentez la justification de chaque modification. |
| Récupération | Maintenez toujours des scripts de retour arrière. |
| Sécurité | Restreignez l’accès direct aux bases de données de production. |
En mettant en œuvre ces pratiques, les équipes peuvent réduire les risques et renforcer leur confiance dans leur infrastructure de données. L’objectif est de rendre la base de données aussi fiable et prévisible que le code d’application qui s’exécute dessus.