










La construction d’une base de données robuste commence bien avant d’écrire la première ligne de code. La fondation réside dans la compréhension de la logique qui anime les opérations commerciales. Lorsque les exigences métier sont floues ou mal comprises, la structure de données résultante devient fragile. Ce guide propose une approche structurée pour convertir les règles métier en diagramme entité-association (ERD). Ce processus garantit que le schéma de base de données reflète fidèlement les besoins organisationnels, sans dépendre d’outils ou de plateformes spécifiques.
Traduire des concepts abstraits en modèles de données concrets exige une précision. Une règle métier pourrait stipuler :« Un client peut passer plusieurs commandes, mais chaque commande appartient à exactement un client ». Sans une traduction appropriée, cette logique pourrait être perdue ou mal interprétée lors de la mise en œuvre. En suivant un cadre systématique, les équipes techniques peuvent créer des schémas évolutifs, maintenables et alignés sur les réalités opérationnelles.
Comprendre les composants fondamentaux des règles métier 🧩
Avant de dessiner des diagrammes, il faut analyser les informations fournies par les parties prenantes. Les règles métier ne sont pas simplement des préférences ; elles sont des contraintes et des définitions qui régissent l’utilisation et le traitement des données. Elles se divisent en plusieurs catégories, chacune influant différemment sur la conception de la base de données.
- Règles structurelles : Définissent quelles données existent. Par exemple, « Chaque employé doit avoir un numéro d’identification unique. »
- Règles procédurales : Définissent comment les données sont traitées. Par exemple, « Les commandes supérieures à 1000 $ nécessitent l’approbation du responsable avant l’expédition. »
- Règles d’état : Définissent les conditions qui doivent être remplies pour des actions spécifiques. Par exemple, « Un compte ne peut pas être fermé si le solde n’est pas nul. »
- Règles de transformation : Définissent comment les données évoluent. Par exemple, « Les taux de taxation doivent être recalculés si l’adresse de livraison change. »
Reconnaître ces distinctions permet de déterminer où elles doivent être placées dans le modèle de données. Les règles structurelles deviennent souvent des entités et des attributs. Les règles procédurales peuvent devenir des déclencheurs ou des procédures stockées, mais elles influencent les relations entre les tables. Les règles d’état définissent souvent des contraintes et de la logique de validation.
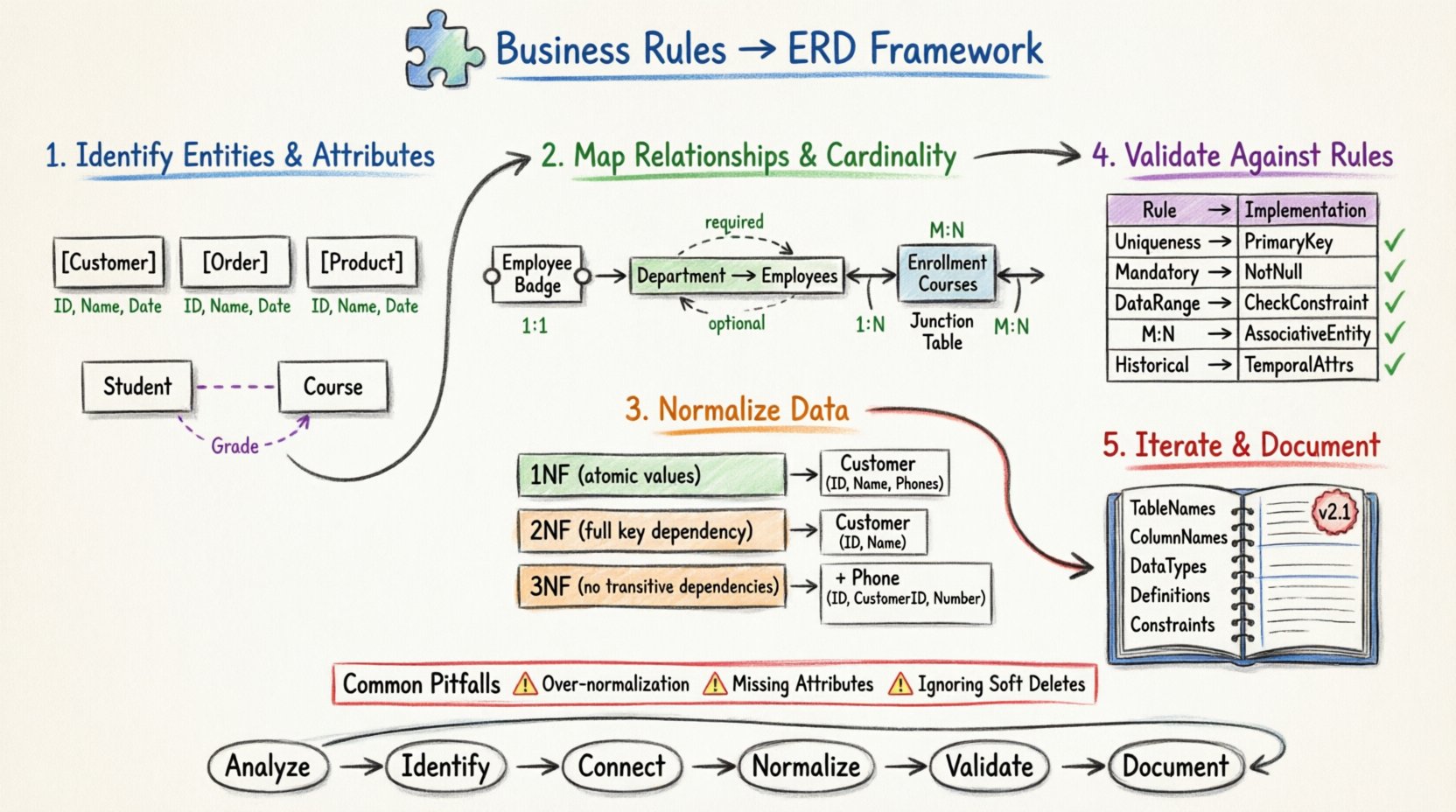
Étape 1 : Identification des entités et des attributs 🏢
La première étape majeure de la modélisation des données consiste à identifier les noms propres dans les règles métier. Ces noms représentent généralement les entités. Les entités sont les objets ou concepts du monde réel dont les données sont stockées. Une fois les entités identifiées, les adjectifs et les descripteurs associés deviennent des attributs.
1.1 Extraction des entités potentielles
Examinez la documentation ou les transcriptions d’entretiens à la recherche de mots-clés. Recherchez les noms qui sont fréquemment mentionnés. Par exemple, dans un contexte de vente au détail, les mots tels queProduit, Magasin, Fournisseur, et Client sont de forts candidats.
- Examinez le texte : Mettez en évidence chaque nom qui représente un objet distinct.
- Filtrer les doublons : Assurez-vous que « Article » et « Produit » ne soient pas traités comme des entités distinctes si elles font référence au même concept.
- Vérifier les associations : Certains noms peuvent être des attributs d’autres. « Adresse » est souvent un attribut de « Client », et non une entité distincte, sauf si le système suit plusieurs adresses par client.
1.2 Définition des attributs
Une fois les entités établies, définissez les points de données qui les décrivent. Les attributs fournissent les détails nécessaires pour identifier et décrire l’entité.
- Clés primaires : Identifiez l’identifiant unique pour chaque entité. Cela est crucial pour l’intégrité des données.
- Attributs descriptifs : Liste les propriétés telles que les noms, les dates ou les descriptions.
- Attributs calculés : Notez les valeurs qui pourraient nécessiter un calcul, bien qu’elles soient souvent gérées au niveau de la couche d’application.
Considérez la règle :« Un étudiant s’inscrit à un cours et reçoit une note. »
- Entités : Étudiant, Cours, Inscription.
- Attributs : Numéro d’étudiant, Nom, Numéro de cours, Titre, Note, Date d’inscription.
Notez que Note n’est pas un attribut de Étudiant ou Cours seul. Il est spécifique à la relation entre eux. Cette prise de conscience conduit souvent à la création d’une entité associative.
Étape 2 : Mappage des relations et de la cardinalité 🔗
Les relations définissent comment les entités interagissent entre elles. La source la plus courante d’erreurs dans la modélisation des données survient lorsque les relations ne sont pas clairement définies ou lorsque la cardinalité est mal comprise. La cardinalité précise le nombre d’instances d’une entité qui peuvent ou doivent être liées à des instances d’une autre entité.
2.1 Identification des relations
Recherchez les verbes dans les règles métier. Les verbes indiquent souvent la relation entre les entités. Les verbes courants incluent affecte, contient, emploie, ou achète.
- Un à un (1:1) : Une instance de l’entité A est liée à exactement une instance de l’entité B. Exemple : Un employé possède exactement une badge.
- Un à plusieurs (1:N) : Une instance de l’entité A est liée à de nombreuses instances de l’entité B. Exemple : Un département emploie de nombreux employés.
- Plusieurs à plusieurs (M:N) : De nombreuses instances de l’entité A sont liées à de nombreuses instances de l’entité B. Exemple : Les étudiants s’inscrivent à de nombreux cours, et les cours ont de nombreux étudiants.
2.2 Gestion des relations plusieurs à plusieurs
Dans la conception des bases de données relationnelles, une relation plusieurs à plusieurs directe n’est pas physiquement possible. Elle doit être résolue en introduisant une entité d’association (appelée également table de jonction ou table de pont).
Lorsqu’une règle métier stipule que « Une pièce est utilisée dans de nombreux assemblages, et un assemblage contient de nombreuses pièces », la traduction nécessite une nouvelle entité, telle que Utilisation_Pièce_Assemblage. Cette nouvelle entité contient les clés étrangères provenant à la fois de la Pièce et Assemblage des entités, ainsi que toutes les attributs spécifiques à cette relation, tels que la quantité.
2.3 Détermination de l’optionnalité
La cardinalité ne concerne pas seulement la quantité ; elle concerne aussi la nécessité. La relation exige-t-elle un correspondant ?
- Requis : Une relation doit exister. Exemple : Une commande doit avoir un client.
- Facultatif : Une relation peut exister ou non. Exemple : Un client peut avoir ou non un prénom intermédiaire.
Documenter cette distinction empêche les erreurs de valeurs nulles et assure que les contraintes d’intégrité référentielle sont appliquées correctement.
Étape 3 : Normalisation et application des contraintes ⚖️
Une fois le diagramme initial esquissé, les données doivent être affinées. La normalisation est le processus d’organisation des données afin de réduire la redondance et d’améliorer l’intégrité. Ce n’est pas simplement un exercice technique ; c’est un reflet de l’efficacité de la logique métier.
3.1 Première forme normale (1NF)
Tous les attributs doivent contenir des valeurs atomiques. Il ne doit pas y avoir de groupes répétitifs. Si une règle métier stipule« Un client possède plusieurs numéros de téléphone », ne les stockez pas dans une seule colonne commephone_numbers : '555-1234, 555-5678'. Au lieu de cela, créez une ligne séparée ou une table liée pour les numéros de téléphone.
3.2 Deuxième forme normale (2NF)
Les attributs doivent dépendre entièrement de la clé primaire. Si une entité possède une clé composite, aucun attribut ne doit dépendre uniquement d’une partie de cette clé. Par exemple, si une clé composite est formée parStudent_ID et Course_ID, un attribut tel queStudent_Name ne doit pas être stocké dans la table d’inscription. Il appartient à la table Étudiant.
3.3 Troisième forme normale (3NF)
Les attributs doivent être indépendants des autres attributs non clés. Cela élimine les dépendances transitives. SiVille dépend deCode postal, etCode postal est un attribut deAdresse, alorsVilleVille devrait idéalement être stockée dans l’entité Adresse ou dans une entité liée Code postal, et non dupliquée dans plusieurs tables.
Étape 4 : Validation du modèle par rapport aux règles ✅
Après la construction du diagramme, il doit être validé. Cette phase garantit que le modèle technique n’a pas dévié des exigences commerciales initiales. Une liste de contrôle est un outil efficace pour cette validation.
| Type de règle métier | Composant du MCD | Vérification de validation |
|---|---|---|
| Contrainte d’unicité | Clé primaire / Index unique | Chaque entité est-elle identifiable de manière unique ? |
| Relation obligatoire | Contrainte NOT NULL | Les clés étrangères sont-elles nécessaires là où elles sont requises ? |
| Plage de données | Contraintes de vérification / Types de données | Les champs numériques correspondent-ils aux limites commerciales attendues ? |
| Relations multiples | Entité d’association | Les relations M:N sont-elles résolues en relations 1:N ? |
| Données historiques | Attributs temporels | Les dates effectives sont-elles incluses pour suivre les modifications ? |
Examiner ce tableau aide à identifier les lacunes. Par exemple, si une règle stipule « Les prix ne peuvent pas être négatifs »« Les prix ne peuvent pas être négatifs », la vérification de validation confirme que le type de données et les contraintes empêchent cela. Si la règle stipule « Un produit doit appartenir à une catégorie »« Un produit doit appartenir à une catégorie », la vérification de validation garantit que la clé étrangère n’est pas nulle.
Péchés courants dans la traduction 🚧
Même les modélisateurs expérimentés rencontrent des problèmes récurrents. Être conscient de ces pièges courants peut faire gagner énormément de temps pendant la phase de développement.
- Sur-normalisation :Diviser les tables trop loin peut entraîner des jointures excessives, ralentissant les performances des requêtes. Il faut trouver un équilibre entre l’intégrité et les besoins de performance.
- Attributs manquants :Se concentrer sur les relations tout en oubliant les données descriptives nécessaires à l’entité.
- Supposition de relations 1:1 :Traiter une relation 1:1 comme une seule table alors qu’elles devraient être séparées pour une séparation logique ou une sécurité.
- Ignorer les suppressions douces :Les règles métier exigent souvent que les données soient conservées pour des raisons historiques, même si elles sont marquées comme inactives. Le modèle doit tenir compte d’un
is_activeindicateur ou d’une table d’archivage distincte. - Confondre les attributs avec des entités :Traiter une liste d’options (par exemple, « Statut ») comme une entité alors qu’elle devrait être une contrainte de domaine ou une valeur d’énumération.
Étape 5 : Itération et documentation 📝
La conception de base de données est rarement un processus linéaire. Les exigences évoluent, et le modèle initial peut nécessiter des ajustements. La documentation est cruciale ici. Elle sert de pont entre l’équipe technique et les parties prenantes métier.
5.1 Maintenance du dictionnaire des données
Un dictionnaire des données définit les métadonnées de la base de données. Il doit inclure :
- Noms des tables :Convention singulier ou pluriel.
- Noms des colonnes :Conventions claires de nommage (par exemple,
customer_idvscust_id). - Types de données :Entiers, Varchars, Dates, etc.
- Définitions métiers :Explications en anglais courant de ce que représentent les données.
- Contraintes :Règles appliquées aux données.
5.2 Contrôle de version des modèles
Tout comme le code d’application, les modèles de données doivent être versionnés. Les modifications du schéma doivent être suivies. Cela garantit que, si une régression se produit, l’équipe peut revenir à un état antérieur qui correspondait aux règles métier à ce moment-là.
Pensées finales sur l’alignement 🎯
La traduction des règles métier en un diagramme d’entité-association est une discipline essentielle. Elle exige d’écouter les parties prenantes, d’interpréter leurs besoins de manière technique, et de construire un modèle qui résiste au temps. Une base de données bien structurée réduit la dette technique et soutient la croissance de l’entreprise.
Lorsque le modèle est en accord avec les règles, les requêtes deviennent prévisibles, les rapports deviennent précis, et le système devient plus facile à maintenir. L’effort investi dans la phase de traduction porte ses fruits pendant le développement et la maintenance. Concentrez-vous sur la clarté, la cohérence et la validation à chaque étape.
En s’attachant à ce cadre, les équipes peuvent éviter le piège courant de construire une base de données qui fonctionne techniquement mais qui échoue à soutenir les opérations réelles de l’entreprise. L’objectif n’est pas seulement de stocker des données, mais de structurer l’information de manière à permettre la prise de décision.
Résumé du cadre 📋
- Analyser : Catégoriser les règles métier en types structurels, procéduraux et d’état.
- Identifier : Extraire les noms pour les entités et les adjectifs pour les attributs.
- Connecter : Cartographier les relations et résoudre les scénarios many-to-many.
- Normaliser : Appliquer la 1NF, la 2NF et la 3NF pour réduire la redondance.
- Valider : Vérifier le modèle par rapport aux règles d’origine.
- Documenter : Maintenir un dictionnaire de données vivant et un contrôle de version.
Cette approche structurée garantit que le schéma de base de données résultant n’est pas simplement une collection de tables, mais un reflet de la logique et des objectifs de l’organisation. Elle transforme les exigences abstraites en un actif concret qui favorise l’efficacité.