



Concevoir un modèle de données robuste exige plus que la simple cartographie des entités et des relations. Il exige une compréhension de la manière dont les données évoluent au fil du temps. Dans les diagrammes entité-association traditionnels (MCD), nous capturons souvent l’état d’un enregistrement à un instant donné. Nous stockons la valeur actuelle d’un salaire, l’état actif d’un utilisateur ou le prix le plus récent d’un produit. Toutefois, l’intelligence d’affaires et la conformité réglementaire exigent souvent de savoir non seulement ce qui est vrai aujourd’hui, mais aussi ce qui était vrai dans le passé.
C’est là que la modélisation des données temporelles entre en jeu. Elle transforme un schéma statique en un suivi dynamique de l’historique. En intégrant directement des dimensions temporelles dans votre MCD, vous vous assurez que chaque modification est documentée, auditable et consultable sans perdre le contexte du moment où ces changements ont eu lieu. Ce guide explore les techniques structurelles nécessaires pour construire des systèmes de bases de données sensibles au temps.
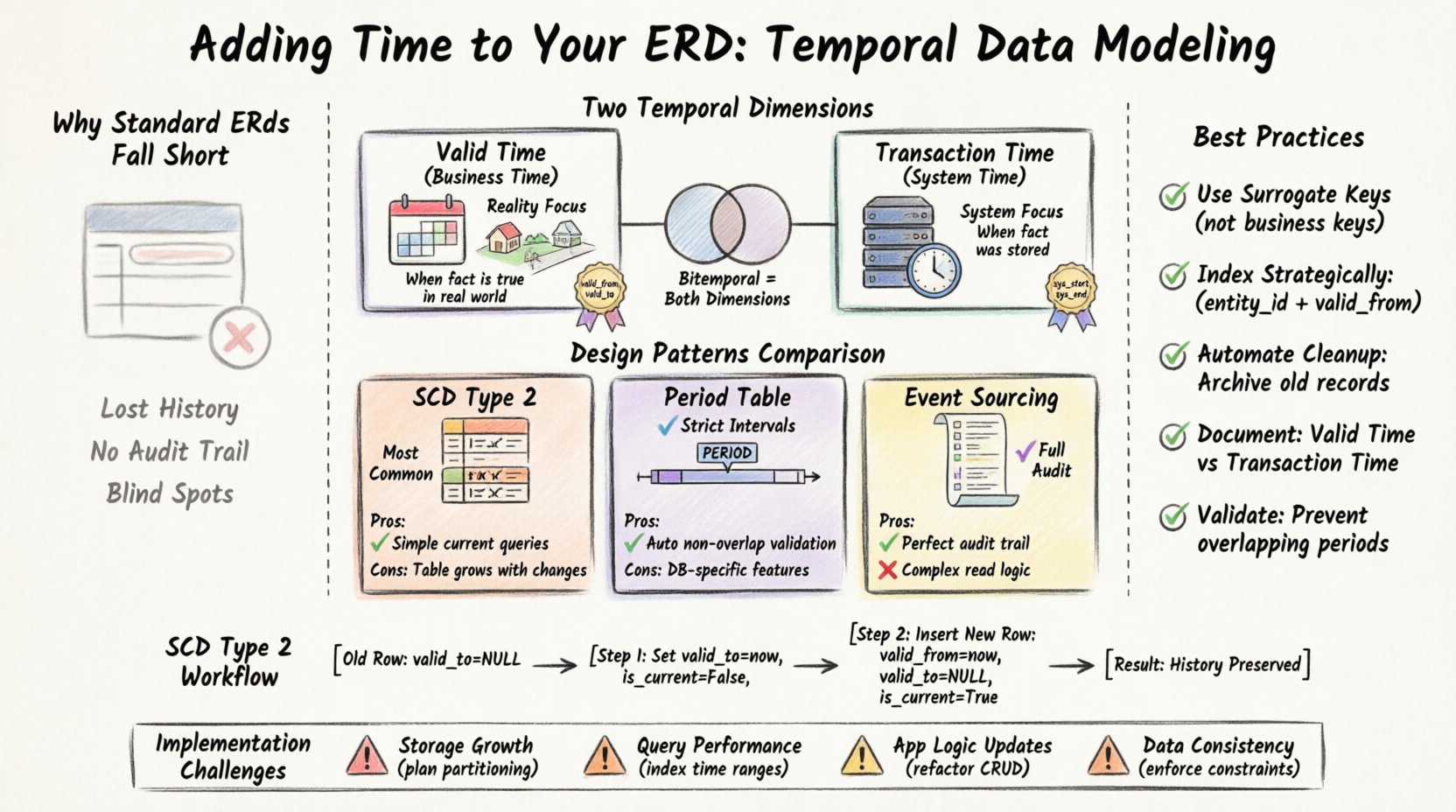
Pourquoi les MCD standards sont insuffisants pour l’historique 📉
Un MCD conventionnel se concentre sur l’état actuel. Lorsqu’un enregistrement est mis à jour, la valeur ancienne est généralement écrasée. Bien que cela fonctionne pour les systèmes opérationnels simples, cela crée des points aveugles importants pour les besoins analytiques. Prenons un scénario où vous devez reconstruire l’historique des facturations d’un client au cours des cinq dernières années. Une table standard ne montrerait peut-être que l’adresse actuelle ou le niveau d’abonnement actuel.
Sans modélisation temporelle, vous faites face à plusieurs défis :
- Perte de contexte : Vous ne pouvez pas déterminer quand un changement de prix a réellement pris effet dans le monde réel par rapport au moment où il a été saisi dans le système.
- Complexité de l’audit : La création d’une table de journalisation d’audit séparée exige une implémentation manuelle des déclencheurs et ajoute une surcharge à chaque opération d’écriture.
- Difficulté des requêtes : La reconstruction d’une chronologie nécessite souvent des jointures complexes ou des auto-jointures difficiles à maintenir et à optimiser.
- Intégrité des données : Sans contraintes temporelles explicites, il est facile d’écraser accidentellement des données historiques lors de mises à jour en masse.
En intégrant directement le temps dans le schéma, vous déplacez la responsabilité du suivi de l’historique de la logique d’application vers la structure des données elle-même.
Comprendre les dimensions temporelles ⏳
Pour modéliser le temps de manière efficace, vous devez distinguer les différentes façons dont le temps existe dans une base de données. Il existe deux dimensions principales à considérer : le temps valide et le temps de transaction. Comprendre la différence est crucial pour choisir la bonne technique de modélisation.
1. Temps valide (temps métier)
Le temps valide représente la période pendant laquelle un fait est vrai dans le monde réel. Cela est indépendant du système de base de données. Par exemple, si le département d’un employé a changé de Ventes en Ingénierie le 1er janvier, le temps valide pour l’affectation en Ingénierie commence à cette date, quelle que soit l’heure à laquelle le responsable RH l’a saisie dans le système.
- Focus : La réalité.
- Cas d’utilisation : Rapports historiques, audit de conformité, reconstruction d’états passés.
- Attributs : Typiquement implémenté avec
valid_frometvalid_todes horodatages.
2. Temps de transaction (temps système)
Le temps de transaction suit le moment où un fait a été stocké dans la base de données. Il est entièrement géré par le système. Si un utilisateur modifie un enregistrement aujourd’hui, le temps de transaction enregistre cet instant précis. Si l’enregistrement est supprimé, le temps de transaction garantit que le système sait quand il a cessé d’être visible dans l’ensemble actif.
- Focus : Opérations du système.
- Cas d’utilisation :Débogage des problèmes de données, compréhension de l’état du système à un moment donné, fonctionnalités de retour arrière.
- Attributs : Généralement géré automatiquement par le moteur de base de données comme
sys_startetsys_end.
3. Données bitemporales
Lorsque vous avez besoin à la fois du temps valide et du temps de transaction, vous construisez une table bitemporale. Il s’agit de la forme la plus complète de modélisation temporelle. Elle vous permet de poser des questions telles que : « Que le système croyait-il être vrai le 1er mars 2023, concernant l’état réel du monde le 1er janvier 2023 ? »
Modèles de conception pour des schémas sensibles au temps 🛠️
Il existe plusieurs modèles architecturaux pour implémenter des données temporelles dans un modèle ERD. Le choix dépend de vos modèles de requêtes et de vos contraintes de stockage.
Le modèle de dimension à changement lent (SCD) de type 2
Il s’agit de la technique la plus courante pour le suivi historique dans les entrepôts de données. Au lieu de mettre à jour une ligne, vous insérez une nouvelle ligne avec un nouvel identifiant de version. La ligne ancienne est marquée comme inactive.
- Ajout clé :
surrogate_key(pour lier à la nouvelle version) etis_activeindicateur. - Avantage :Requêtes simples pour trouver l’enregistrement actuel en utilisant un filtre.
- Inconvénient :La table croît linéairement avec les modifications. La suppression d’une ligne nécessite de mettre à jour toutes les versions précédentes ou de les marquer.
Le modèle de table de période
Dans cette approche, le temps est stocké sous forme de type période plutôt que sous deux colonnes distinctes. Cela est souvent pris en charge nativement par les moteurs de base de données modernes. Il impose que les périodes ne se chevauchent pas.
- Ajout clé : Un
PÉRIODEcontrainte de type de données. - Avantage :Application automatique de plages horaires non chevauchantes.
- Inconvénient : Nécessite des fonctionnalités spécifiques de base de données qui peuvent ne pas être disponibles sur tous les systèmes.
Le modèle de sourcing d’événements
Plutôt que de stocker l’état actuel, vous stockez une séquence d’événements. L’état est reconstruit en rejouant ces événements. Cela est très détaillé, mais peut être coûteux en termes de calcul lors de la lecture.
- Ajout clé : Une table de journal en écriture seule.
- Avantage : Traçabilité parfaite ; aucune donnée n’est jamais supprimée.
- Inconvénient : Logique de lecture complexe ; la reconstruction de l’état n’est pas immédiate.
L’approche SCD Type 2 en détail 🔄
Pour la plupart des applications d’entreprise, le SCD Type 2 offre le meilleur équilibre entre complexité et utilité. Voyons comment cela se traduit dans une structure de modèle entité-relation (ERD).
Imaginez une Client entité. Dans un modèle standard, vous avez une ligne par identifiant client. Dans un modèle temporel, vous avez plusieurs lignes pour le même identifiant client, différenciées par le temps.
Attributs requis :
identifiant_client: La clé naturelle métier.identifiant_version: Un identifiant unique pour chaque instance de registre spécifique.valide_depuis: L’horodatage à partir duquel cet enregistrement est devenu effectif.valide_jusqu'à: L’horodatage à partir duquel cet enregistrement a cessé d’être effectif. Souvent défini à NULL pour l’enregistrement actuel.est_actuel: Un indicateur booléen pour identifier rapidement l’état le plus récent.
Lorsqu’un client change son adresse, vous ne mettez pas à jour la ligne existante. Au lieu de cela, vous :
- Mettez à jour le
valid_tode la ligne ancienne adresse à l’horodatage actuel. - Définissez
is_currentsur False pour la vieille ligne. - Insérez une nouvelle ligne avec la nouvelle adresse.
- Définissez
valid_fromà l’horodatage actuel. - Définissez
valid_tosur NULL. - Définissez
is_currentsur True.
Tables de période et temps valide 🗓️
Bien que le SCD Type 2 soit souple, les tables de période offrent une définition plus stricte du temps. Dans ce modèle, l’intervalle de temps est un seul attribut. Cela aide à éviter les erreurs logiques où valid_from est supérieur à valid_to.
Considérez la structure de schéma suivante pour une table de période :
| Nom de la colonne | Type | Description |
|---|---|---|
entity_id |
UUID | Clé primaire de l’entité |
valeur_donnée |
VARCHAR | L’attribut suivi |
période_temporelle |
PÉRIODE(TIMESTAMP) | Début et fin de validité |
version_système |
ENTIER | Numéro de séquence pour la ligne |
Cette structure garantit que le moteur de base de données valide les intervalles de temps avant l’insertion. Si vous tentez d’insérer un enregistrement qui chevauche une période existante pour la même entité, l’opération échouera, sauf si elle est explicitement autorisée.
Gestion du temps de transaction 📝
Le temps valide vous indique ce qui était vrai. Le temps de transaction vous indique quand vous le saviez. Parfois, vous devez savoir que la base de données croyait qu’un fait était vrai, même si ce fait s’est révélé faux dans le monde réel plus tard.
Par exemple, un utilisateur pourrait saisir une mauvaise adresse. Le système l’enregistre avec un temps de transaction. Plus tard, l’utilisateur la corrige. Si vous ne suivez que le temps valide, vous perdez l’enregistrement de l’erreur initiale. Si vous suivez le temps de transaction, vous préservez l’historique des saisies du système.
La mise en œuvre du temps de transaction implique généralement de masquer les colonnes de l’interface utilisateur. Ces colonnes sont gérées par le moteur de base de données. Lors de la requête de l’état « actuel », le système filtre automatiquement les enregistrements dont le temps de transaction est expiré (c’est-à-dire que l’enregistrement a été supprimé).
Modélisation bitemporale expliquée ⚖️
La modélisation bitemporale combine le temps valide et le temps de transaction. C’est la norme de référence pour la conformité réglementaire et l’analyse forensique des données.
Implications du schéma :
- Vous avez besoin de quatre colonnes liées au temps :
valide_depuis,valide_jusqu'à,transaction_depuis,transaction_jusqu'à. - Votre stratégie d’indexation doit tenir compte des deux dimensions.
- Vos requêtes deviennent plus complexes, souvent nécessitant des jointures par plage.
Logique d’exemple de requête :
Pour trouver l’état d’un enregistrement tel qu’il était connu à un instant donné, vous filtrez sur le temps de transaction. Pour trouver l’état du monde à un instant donné, vous filtrez sur le temps valide. Pour trouver l’état du monde tel que le système le comprenait à un instant donné, vous filtrez sur les deux.
Ce niveau de granularité est essentiel pour des secteurs comme la finance, la santé et les services juridiques, où l’origine des données est aussi importante que les données elles-mêmes.
Défis de mise en œuvre ⚠️
Ajouter le temps à votre modèle ER introduit une complexité qui doit être gérée avec soin.
1. Surdimensionnement du stockage
Chaque modification crée une nouvelle ligne. Au fil des années, une table peut devenir significativement plus grande que sa contrepartie non temporelle. Vous devez prévoir des besoins de stockage accrus. Le partitionnement par plages de temps (par exemple mensuelles ou annuelles) est une stratégie courante pour maintenir les requêtes rapides et la maintenance simple.
2. Performances des requêtes
Le filtrage par plages de temps est généralement rapide si les index sont correctement définis. Toutefois, la reconstruction d’états historiques nécessite souvent la jointure de plusieurs tables. Une requête qui prenait auparavant quelques millisecondes peut prendre plusieurs secondes si elle implique le balayage d’une table d’historique contenant des millions de lignes.
3. Modifications de la logique d’application
Le code d’application existant qui suppose une seule ligne par entité va cesser de fonctionner. Vous devez refactoriser toutes les opérations CRUD pour gérer les attributs temporels. Les opérations d’insertion deviennent des mises à jour conditionnelles.
4. Cohérence des données
Assurer que valide_depuis est toujours inférieur à valide_jusqu'àexige des contraintes de base de données. Sans ces contraintes, vous risquez de créer des périodes temporelles invalides qui perturbent le reporting historique.
Meilleures pratiques pour la maintenance 🧹
Pour maintenir un modèle temporel en bon état, suivez ces recommandations.
- Utilisez des clés surrogates :Utilisez toujours un ID interne pour la table d’historique, et non la clé métier. Cela permet à la clé métier de changer sans compromettre l’intégrité référentielle.
- Indexez de manière stratégique : Créez des index composés sur (
id_entité,valide_depuis). Cela accélère les recherches pour les enregistrements actuels et les instantanés historiques. - Automatisez le nettoyage : Mettez en place des politiques d’archivage. Si un enregistrement a plus de 10 ans, déplacez-le vers une table de stockage froid pour garder la table active légère.
- Documentez le calendrier : Documentez clairement la différence entre le temps valide et le temps de transaction dans votre dictionnaire de données. Les développeurs doivent savoir quel horodatage s’applique à leur cas d’utilisation.
- Validez les chevauchements : Utilisez des contraintes de base de données pour empêcher les périodes valides chevauchantes pour la même entité.
Comparaison des stratégies temporelles
Le choix du bon modèle dépend de vos besoins spécifiques. Le tableau ci-dessous résume les compromis.
| Stratégie | Complexité | Coût de stockage | Vitesse des requêtes | Meilleur cas d’utilisation |
|---|---|---|---|---|
| SCD Type 2 | Moyen | Moyen | Élevé | Suivi général de l’historique des affaires |
| Tables de période | Élevé | Moyen | Élevé | Conformité stricte réglementaire |
| Bitemporal | Très élevé | Élevé | Moyen | Analyse forensic, audit système |
| Event Sourcing | Élevé | Très élevé | Faible (lecture) | Reconstruction d’état, flux en temps réel |
Considérations finales pour les architectes de données
Intégrer le temps dans votre diagramme d’entités et de relations est une décision qui impacte le cycle de vie de vos données. Ce n’est pas simplement un ajustement technique ; c’est un changement dans la manière dont vous percevez l’information.
Lorsque vous concevez en gardant le temps à l’esprit, vous reconnaissez que les données ne sont pas statiques. Elles circulent. Elles évoluent. Elles vieillissent. En intégrant ces capacités dans la fondation de votre schéma, vous protégez votre système à l’avenir contre la nécessité d’analyses rétrospectives.
Commencez par identifier les attributs de votre système qui nécessitent réellement un historique. Toute colonne n’a pas besoin d’une horodatage. Concentrez-vous sur les points de données à forte valeur tels que les soldes financiers, les affectations du personnel et les prix des produits. Appliquez les modèles temporels de manière sélective pour éviter un surcroît inutile.
Au fur et à mesure que votre système mûrit, vous pourriez constater que la conception initiale nécessite des ajustements. Les modèles de données temporelles sont itératifs. Surveillez les performances de vos requêtes et la croissance de votre stockage. Ajustez vos stratégies de partitionnement et d’indexation au fur et à mesure que le volume de données historiques s’accumule.
En fin de compte, un schéma ER conscient du temps fournit une source unique de vérité qui respecte le passé tout en servant le présent. Il garantit que lorsque des questions surgissent sur le « pourquoi » d’un événement, la réponse est déjà inscrite dans votre base de données, en attente d’être récupérée.