











La construction d’une infrastructure de base de données robuste exige une précision à chaque étape du développement. Le diagramme Entité-Relation (MDE) sert de plan directeur pour cette structure. Il définit comment les entités de données interagissent, comment les informations circulent et comment l’intégrité est maintenue tout au long du cycle de vie du système. Sauter une revue approfondie du MDE peut entraîner un restructurage coûteux, une corruption des données et des goulets d’étranglement de performance à long terme. Ce guide fournit une liste de contrôle détaillée et opérationnelle pour valider votre schéma avant de procéder à la mise en œuvre.
Les architectes de bases de données et les développeurs doivent aborder la conception du schéma avec une rigueur critique. Le coût de correction d’une erreur structurelle en production est nettement plus élevé que l’effort requis pour la corriger pendant la phase de conception. En suivant un processus de revue structuré, les équipes s’assurent que la base de données résultante soutient la logique métier, respecte les principes de normalisation et reste évolutif.
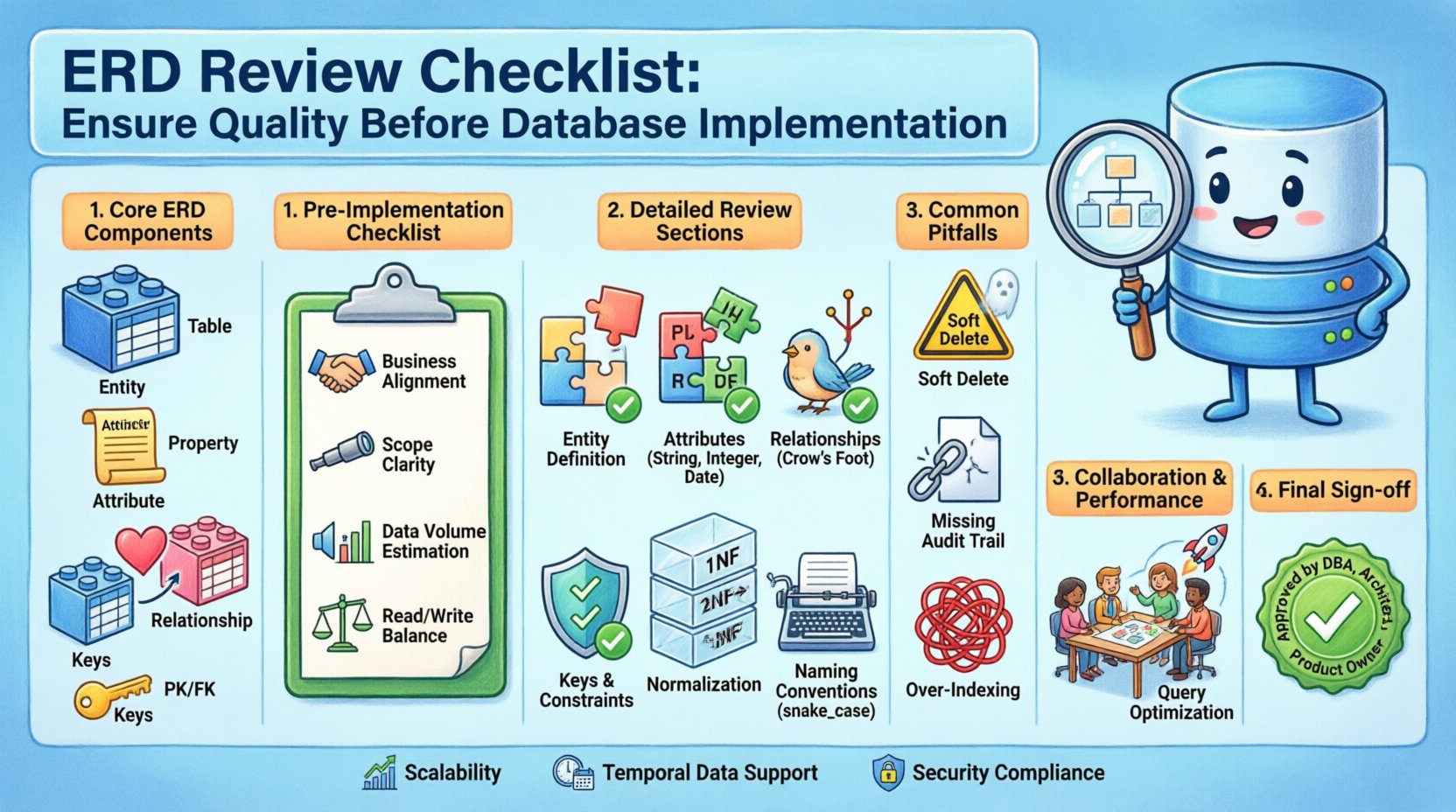
Comprendre les composants fondamentaux d’un MDE 🔍
Avant de plonger dans la liste de contrôle, il est essentiel de comprendre les éléments fondamentaux qui constituent un diagramme Entité-Relation standard. Ces composants forment le vocabulaire de votre modèle de données.
- Entités : Elles représentent les objets ou concepts du monde réel dont les données sont stockées. Dans un contexte relationnel, les entités correspondent généralement aux tables.
- Attributs : Ils décrivent les propriétés ou caractéristiques d’une entité. Ils correspondent aux colonnes au sein d’une table.
- Relations : Elles définissent les associations entre les entités. Elles indiquent comment les données d’une table sont liées aux données d’une autre.
- Cardinalités et clés : La cardinalité définit la relation numérique entre les entités (par exemple, un-à-un, un-à-plusieurs, plusieurs-à-plusieurs). Les clés assurent une identification unique et une connectivité.
Un MDE de haute qualité doit clairement articuler ces éléments. L’ambiguïté dans le diagramme se traduit directement par de l’ambiguïté dans le code, entraînant des erreurs d’implémentation.
Étapes de validation pré-implémentation ✅
Avant d’appliquer les éléments spécifiques de la liste de contrôle, le contexte global de la base de données doit être aligné sur les exigences métiers. Cette phase garantit que le modèle est adapté à son objectif.
- Alignement avec les exigences métiers : Vérifiez que chaque entité et relation correspond à une règle métier ou une histoire utilisateur spécifique.
- Définition du périmètre : Confirmez les limites des données. Concevons-nous pour une seule application, un microservice ou un entrepôt à l’échelle de l’entreprise ?
- Estimation du volume de données : Prenez en compte le volume attendu des enregistrements. Cela influence les décisions concernant les stratégies d’indexation et de partitionnement.
- Ratio lecture/écriture : Comprenez le profil de charge. Une application fortement en lecture peut nécessiter une dénormalisation, tandis qu’un système fortement en écriture privilégie une intégrité stricte.
Liste de contrôle détaillée de revue du MDE 📝
Cette section détaille les attributs techniques spécifiques qui nécessitent une attention particulière. Utilisez cette liste comme outil de vérification lors de vos séances de revue de conception.
1. Définition de l’entité et de la table
Chaque entité du diagramme doit être distincte et bien définie. Une erreur courante consiste à créer des entités superposées qui devraient être fusionnées, ou à diviser un concept unique sur plusieurs tables de manière inutile.
- Distinctivité : Assurez-vous que chaque table représente un concept unique. Évitez les tables qui stockent des données similaires à des fins différentes sans distinction claire.
- Granularité : Vérifiez si les tables sont trop granulaires. Un fractionnement excessif peut entraîner des jointures complexes et une dégradation des performances.
- Conventions de nommage :Vérifiez la cohérence. Les tables doivent utiliser des noms au singulier (par exemple,
Clientau lieu deClients) afin de s’aligner sur les modèles de mappage orientés objet. - Métadonnées : Assurez-vous que les horodatages de création et de modification sont inclus dans chaque table afin de soutenir l’audit et le suivi de l’origine des données.
2. Attributs et types de données
Les attributs définissent la nature des données stockées. Sélectionner le bon type de données est crucial pour l’efficacité du stockage et les performances des requêtes.
- Types de données principaux : Assurez-vous que les entiers, les chaînes et les booléens sont utilisés correctement. Évitez d’utiliser des chaînes pour les dates ou les nombres.
- Contraintes de longueur : Définissez des longueurs maximales pour les champs chaîne. Cela empêche l’accumulation inutile de stockage et assure la cohérence lors de la validation des entrées.
- Nullabilité : Définissez explicitement si un champ peut être nul. La plupart des champs ne devraient pas être nuls, sauf si la logique métier le permet.
- Valeurs par défaut : Vérifiez si des valeurs par défaut sont nécessaires. Par exemple, un champ d’état pourrait avoir par défaut la valeur « actif » au lieu de nécessiter une insertion initiale.
- Valeurs énumérées : Lorsque cela est pertinent, utilisez des listes énumérées pour restreindre les valeurs. Cela empêche les entrées de données non valides à la source.
3. Relations et cardinalité
Les relations sont le ciment qui maintient le modèle de données ensemble. Les erreurs ici entraînent des enregistrements orphelins ou une duplication des données.
| Type de relation | Description | Note d’implémentation |
|---|---|---|
| Un à un (1:1) | Un enregistrement dans la table A est lié à exactement un enregistrement dans la table B. | Généralement implémenté en plaçant la clé primaire de A comme clé étrangère dans B. |
| Un vers plusieurs (1:N) | Un enregistrement dans la table A est lié à plusieurs enregistrements dans la table B. | Placez la clé primaire de A comme clé étrangère dans B. |
| Plusieurs vers plusieurs (M:N) | Les enregistrements de A peuvent être liés à plusieurs de B, et inversement. | Exige une table de jonction reliant les deux clés primaires. |
- Vérification de la cardinalité : Revoyez la notation en forme de pied de corbeau ou son équivalent pour vous assurer que la direction de la relation est correcte.
- Optionnalité : Différenciez les relations obligatoires et optionnelles. Une contrainte de clé étrangère doit refléter si un enregistrement lié doit exister.
- Relations récursives : Vérifiez les tables auto-référentielles (par exemple, une
Employétable liée à unDirecteurID au sein de la même table). - Dépendances circulaires : Assurez-vous que les relations ne créent pas de boucles circulaires qui compliquent le chargement ou la requête des données.
4. Clés et contraintes
Les clés sont le mécanisme de l’unicité et de la connexion. Sans clés appropriées, l’intégrité des données s’effondre.
- Clés primaires : Chaque table doit avoir une clé primaire. Elle doit être unique et jamais nulle.
- Clés de substitution : Pensez à utiliser des identifiants générés par le système (clés de substitution) plutôt que des clés métier naturelles. Cela évite que les modifications de la logique métier n’affectent la structure de la base de données.
- Clés étrangères : Vérifiez que toutes les clés étrangères font référence à des clés primaires valides dans les tables parentes.
- Contraintes d’unicité : Identifiez les champs qui doivent être uniques (par exemple, adresses e-mail, numéros de compte) mais qui ne sont pas la clé primaire.
- Contraintes de vérification : Recherchez des règles logiques qui ne peuvent pas être imposées uniquement par les types de données (par exemple,
date_de_debutdoit être antérieur àdate_de_fin).
5. Normalisation
La normalisation réduit la redondance et améliore l’intégrité des données. Bien que la sur-normalisation puisse nuire aux performances, la sous-normalisation crée des anomalies.
- Première forme normale (1NF) : Assurez-vous des valeurs atomiques. Aucun groupe répétitif ou tableau dans une seule cellule.
- Deuxième forme normale (2NF) : Assurez-vous que toutes les attributs non clés dépendent entièrement de la clé primaire, et non seulement d’une partie de celle-ci.
- Troisième forme normale (3NF) : Assurez-vous qu’il n’y ait pas de dépendances transitives. Les attributs non clés doivent dépendre uniquement de la clé primaire, et non d’autres attributs non clés.
- Stratégie de dénormalisation : Si les performances sont une préoccupation, documentez où et pourquoi la dénormalisation est appliquée. Il s’agit d’une décision consciente, et non d’une négligence.
6. Conventions de nommage
Un nommage cohérent réduit la charge cognitive pour les développeurs et diminue la probabilité d’erreurs.
- Noms de table : Utilisez des noms au singulier (par exemple,
Commande, et nonCommandes). - Noms de colonne : Utilisez snake_case pour assurer la cohérence (par exemple,
created_at). - Évitez les mots réservés : Assurez-vous qu’aucun nom de colonne ne contredit les mots-clés SQL (par exemple,
utilisateur,ordre,groupe). - Clarté : Les noms doivent être descriptifs. Évitez les abréviations sauf si elles sont standard dans l’industrie.
Péchés courants à éviter ⚠️
Même les designers expérimentés peuvent négliger des détails importants. Être conscient des pièges courants aide à maintenir un schéma propre.
- Ignorer les suppressions douces : Décidez si les données doivent être supprimées de manière permanente ou marquées logiquement comme inactives. Un
is_deletedindicateur est souvent plus sûr que la suppression physique. - Absence de traçabilité des modifications : Assurez-vous qu’il existe un mécanisme pour suivre qui a modifié les données et quand. Cela est crucial pour le respect des réglementations.
- Sur-indexation : Ajouter trop d’index ralentit les opérations d’écriture. Revoyez les modèles de requêtes pour justifier l’emplacement des index.
- Valeurs codées en dur : Évitez de stocker des valeurs spécifiques comme les codes pays sous forme de chaînes de caractères si elles peuvent être mappées à une table de référence.
- Hypothèses implicites : N’assumez pas qu’un champ est facultatif si la logique métier l’exige. Documentez clairement les hypothèses.
Collaboration et documentation 🤝
Un schéma ER n’est pas seulement un artefact technique ; c’est un outil de communication. Il doit être compris par les parties prenantes, et non seulement par les administrateurs de base de données.
- Revue par les parties prenantes : Faites revue du schéma par des analystes métier pour confirmer qu’il correspond à leur modèle mental du processus.
- Contrôle de version : Traitez le schéma ER comme du code. Stockez-le dans un système de contrôle de version pour suivre les modifications au fil du temps.
- Documentation : Incluez un dictionnaire des données aux côtés du schéma. Définissez ce que signifie chaque champ et sa plage autorisée.
- Gestion des modifications : Établissez un processus pour modifier le schéma. Les modifications doivent être revues et approuvées, et non appliquées de manière improvisée.
Considérations de performance 🚀
Bien que le MCD soit logique, il doit soutenir des objectifs de performance physique. Certaines décisions de conception ont des implications directes sur les performances.
- Complexité des jointures : Minimisez le nombre de jointures nécessaires pour les requêtes courantes. Les jointures complexes peuvent surcharger l’optimiseur de requêtes.
- Préparation au partitionnement : Concevez les tables en tenant compte du partitionnement si le jeu de données est susceptible de croître de manière massive.
- Recherchabilité : Assurez-vous que les champs fréquemment recherchés sont indexés. Prenez en compte les exigences de recherche full-text pour les champs riches en texte.
- Concurrence : Évaluez les stratégies de verrouillage. Les environnements à haute concurrence peuvent nécessiter des niveaux d’isolation spécifiques ou des conceptions de tables particulières.
Critères de validation finale 🏁
Avant de passer à l’implémentation, le MCD doit satisfaire des critères d’acceptation spécifiques. Cela garantit une transition fluide du design au développement.
- Complétude : Toutes les entités et relations requises par le périmètre sont présentes.
- Consistance : Les conventions de nommage et les types de données sont appliqués de manière uniforme.
- Intégrité : Les contraintes de clés primaires et étrangères sont correctement définies.
- Clarté : Le diagramme est lisible et compréhensible par l’équipe d’ingénierie.
- Approbation : Les parties prenantes clés ont validé la conception.
Respecter cette liste de vérification garantit que la fondation de la base de données est solide. Elle réduit la dette technique et facilite des cycles de développement plus fluides. Un MCD bien revu est la première étape vers une architecture de données résiliente.
Examen du MCD pour une évolutivité future
Concevoir pour le présent est insuffisant. Le modèle de données doit pouvoir supporter la croissance sans nécessiter une reconstruction complète.
- Mise à l’échelle horizontale : Prenez en compte l’impact du fractionnement (sharding) sur les relations. Les clés étrangères entre shards sont complexes et souvent évitées.
- Mise à l’échelle verticale : Assurez-vous que les types de données peuvent gérer des valeurs plus grandes. Par exemple, utiliser
BIGINTau lieu deENTpour les compteurs. - Drapeaux de fonctionnalité : Concevez des tables pour prendre en charge les drapeaux de fonctionnalité douce. Cela permet d’activer ou de désactiver de nouvelles fonctionnalités sans modifier le schéma.
- Compatibilité descendante : Prévoyez les migrations de schéma. L’ajout de colonnes ne doit pas rompre les requêtes existantes.
Gestion des cas particuliers tels que les données temporelles
Le temps est une dimension critique dans la modélisation des données. Gérer l’historique correctement est souvent négligé.
- Dates effectives : Pour les entités qui évoluent au fil du temps, incluez des dates de début et de fin pour suivre l’historique.
- Fuseaux horaires : Stockez les horodatages en UTC pour éviter toute ambiguïté entre les régions.
- Instantanés : Décidez si des instantanés historiques sont nécessaires. Cela pourrait nécessiter une table d’historique distincte.
- Tables temporelles : Certains systèmes prennent en charge les tables temporelles natives. Évaluez si cela correspond aux contraintes architecturales.
Sécurité et conformité dans le schéma
La sécurité des données commence au niveau de la table. La structure doit supporter les exigences de confidentialité et de protection.
- Gestion des données personnelles : Identifiez les champs contenant des informations personnelles. Ces champs nécessitent un chiffrement ou un masquage.
- Contrôle d’accès : Concevez des rôles et des autorisations en fonction de la sensibilité des données définie dans le schéma.
- Chiffrement au repos : Assurez-vous que le moteur de base de données prend en charge le chiffrement pour les champs sensibles.
- Politiques de rétention : Définissez des champs indiquant quand les données peuvent être supprimées conformément aux exigences légales.
En appliquant rigoureusement ces contrôles, la base de données devient un actif fiable plutôt qu’une charge. L’effort investi dans la phase de revue du MCD porte ses fruits en termes de maintenabilité et de performance.