











Dans l’architecture complexe de la conception de bases de données, peu de concepts défient les ingénieurs comme l’entité auto-référentielle. Aussi appelée relation récursive, ce schéma permet à une table de se lier à elle-même, permettant ainsi la modélisation des hiérarchies et des structures complexes dans un schéma plat. Comprendre comment l’implémenter correctement est crucial pour préserver l’intégrité des données et les performances des requêtes.
Lors de la conception d’un diagramme d’entités et de relations (ERD), la plupart des relations connectent deux entités distinctes. Toutefois, les données du monde réel exigent souvent qu’une seule entité se réfère à son propre type. Un manager gère des employés, une catégorie contient des sous-catégories, et un produit peut faire partie d’un kit. Ces scénarios nécessitent une relation récursive.
Ce guide explore les mécanismes, les modèles de conception et les bonnes pratiques pour gérer les entités auto-référentielles. Nous examinerons comment structurer ces relations sans dépendre d’outils logiciels spécifiques, en nous concentrant sur les principes universels des bases de données.
🧐 Qu’est-ce qu’une entité auto-référentielle ?
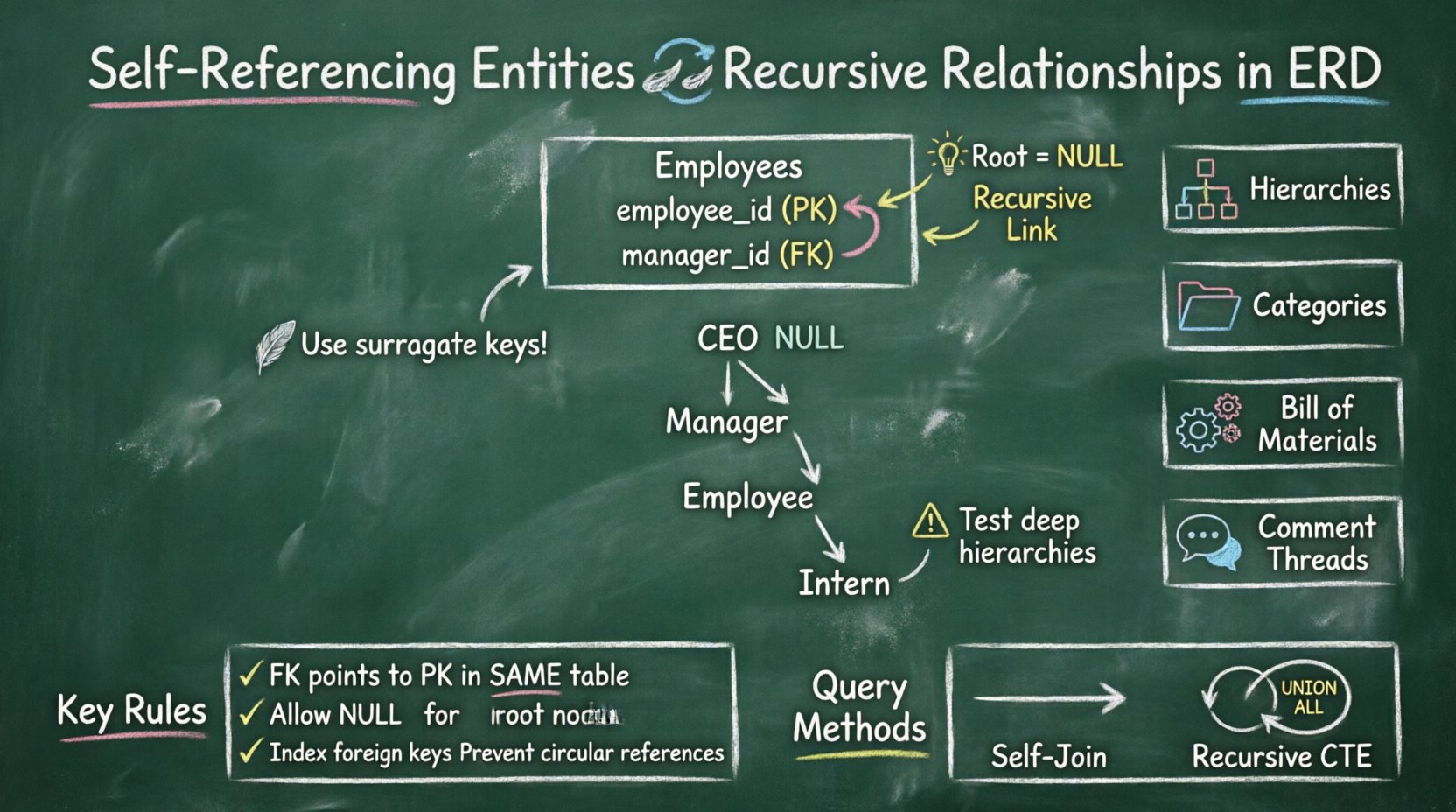
Une entité auto-référentielle se produit lorsque une clé étrangère dans une table pointe vers la clé primaire de la même table. Cela crée une boucle où les lignes de données dans une seule table peuvent référencer d’autres lignes dans cette même table. C’est une technique fondamentale pour modéliser des structures de données hiérarchiques.
Caractéristiques clés :
- Table unique : La relation existe entièrement dans une seule structure de table.
- Lien parent-enfant : Une ligne agit comme parent, tandis qu’une autre agit comme enfant.
- Gestion des valeurs nulles : La racine de la hiérarchie a généralement une valeur nulle dans la colonne de clé étrangère.
- Logique circulaire : Il faut faire preuve de prudence pour éviter les boucles infinies lors de la récupération des données.
🏗️ Composants fondamentaux des relations récursives
Pour implémenter cette relation efficacement, des composants de base de données spécifiques doivent être alignés. La conception du schéma dépend fortement de l’interaction entre les clés primaires et les clés étrangères.
🔑 La clé primaire
Chaque ligne de la table doit avoir un identifiant unique. C’est le point d’ancrage. Lorsqu’une ligne référence une autre ligne, elle le fait en stockant l’identifiant unique de la ligne parente.
- Elle doit être stable. Modifier une clé primaire est une opération complexe.
- Elle devrait être indexée pour une recherche rapide.
- Souvent, il s’agit d’un entier auto-incrémenté ou d’un UUID.
🔗 La clé étrangère
La colonne de clé étrangère se trouve dans la même table que la clé primaire. Elle contient la valeur de la clé primaire de la ligne parente. Cette colonne définit la direction de la relation.
- Peut être nulle :Dans une hiérarchie, l’élément de niveau supérieur (la racine) n’a pas de parent. Par conséquent, cette colonne doit autoriser les valeurs nulles.
- Contrainte : Une contrainte de clé étrangère garantit que la valeur stockée correspond à une clé primaire existante dans la même table.
- Indexation : Bien qu’elle ne soit pas toujours obligatoire, l’indexation de la colonne de clé étrangère accélère considérablement les requêtes qui parcourent la hiérarchie.
📐 Visualisation dans un diagramme entité-association
Lors de la représentation d’une entité auto-référente dans un diagramme entité-association, la notation peut être confuse au premier abord. Les outils standards de diagrammes entité-association utilisent des lignes spécifiques pour indiquer la connexion.
Règles de notation visuelle :
- La boîte d’entité est dessinée une seule fois.
- Une ligne de relation relie la clé primaire à la clé étrangère à l’intérieur de la même boîte.
- La ligne revient souvent vers l’entité, créant un cercle visuel.
- Les indicateurs de cardinalité (1:1, 1:M) sont placés sur la ligne pour indiquer combien d’enfants un parent peut avoir.
Exemple : Structure organisationnelle
| Concept | Description | Notation du diagramme entité-association |
|---|---|---|
| Employé | L’entité modélisée | Boîte étiquetée « Employé » |
| Manager | Le rôle faisant référence à la même table | Ligne du Manager ID vers l’Employee ID |
| Ligne de reporting | La relation récursive | Flèche en boucle |
| Nœud racine | PDG ou patron de niveau supérieur | Valeur nulle dans le Manager ID |
🌳 Cas d’utilisation courants des données récursives
Les relations récursives ne sont pas théoriques ; elles résolvent des problèmes concrets dans la modélisation des données. Voici les scénarios les plus fréquents où ce modèle est appliqué.
1️⃣ Hiérarchies organisationnelles
Toute entreprise possède une structure. Les employés rapportent à des managers, qui rapportent à des directeurs, qui rapportent à des VP. Cette chaîne forme une structure arborescente classique.
- Modèle de données : Une table nommée « Employés ».
- Colonnes :
employee_id,nom,manager_id. - Logique : Le
manager_idla colonne fait référence àemployee_id. - Avantage : L’ajout d’un nouveau salarié nécessite uniquement l’insertion d’une seule ligne. Pas besoin de créer une nouvelle table pour chaque département.
2️⃣ Arbres de catégories
Les plateformes de commerce électronique organisent souvent les produits en catégories imbriquées. Électronique > Ordinateurs > Ordinateurs portables.
- Modèle de données : Une table nommée « Catégories ».
- Colonnes :
category_id,nom,parent_id. - Logique : Une catégorie peut avoir un parent, ou elle peut être une catégorie racine (parent_id est nul).
- Avantage : Flexibilité pour ajouter autant de sous-catégories que nécessaire sans modifier le schéma.
3️⃣ Liste de matériaux (BOM)
La fabrication nécessite souvent des listes de pièces complexes. Une voiture est composée de moteurs, qui sont eux-mêmes composés de pistons. Parfois, un piston fait partie d’un autre type de moteur.
- Modèle de données : Une table nommée « Pièces ».
- Colonnes :
id_pièce,description,id_assemblage. - Logique : Une pièce peut elle-même être un assemblage, contenant d’autres pièces.
- Avantage : Permet des structures de fabrication à plusieurs niveaux.
4️⃣ Fil de commentaires
Les forums et les blogs permettent aux utilisateurs de répondre aux commentaires. Un commentaire peut avoir un commentaire parent auquel il répond, ou bien être un commentaire indépendant.
- Modèle de données : Une table nommée « Commentaires ».
- Colonnes :
id_commentaire,id_utilisateur,contenu,id_commentaire_parent. - Logique : Une réponse fait référence à l’identifiant du commentaire original.
- Avantage : Prise en charge du nesting infini des discussions.
⚙️ Considérations relatives à l’implémentation
Concevoir le schéma n’est que la première étape. Assurer que les données se comportent correctement dans diverses conditions exige une planification soigneuse.
🛑 Prévension des références circulaires
Un risque critique dans les relations récursives est la création d’un cycle. Par exemple, l’employé A gère l’employé B, et l’employé B gère l’employé A. Cela crée une boucle infinie.
- Logique de l’application : Lors de l’insertion ou de la mise à jour des données, l’application doit vérifier la profondeur de la hiérarchie afin de s’assurer qu’aucun cycle n’est formé.
- Contraintes de base de données : Bien que les contraintes SQL standards ne puissent pas facilement empêcher les cycles (car elles vérifient l’état actuel, et non l’état résultant), des déclencheurs peuvent être utilisés dans certains systèmes pour valider le chemin avant l’écriture.
- Identification de la racine : Assurez-vous qu’une arborescence valide possède exactement un nœud racine (où la clé étrangère est nulle).
📉 Gestion des valeurs nulles
La racine de la hiérarchie est le point de départ. Dans une relation récursive standard, la ligne racine a une valeur nulle dans la colonne de clé étrangère.
- Interrogation : Pour trouver tous les nœuds racines, interrogez les lignes où la clé étrangère est NULL.
- Valeurs par défaut : Ne définissez pas de valeur par défaut pour la clé étrangère si elle implique un parent. Une valeur par défaut de 0 ou -1 peut être trompeuse et entraîner des problèmes d’intégrité des données.
- Intégrité : Assurez-vous que le moteur de base de données autorise les valeurs NULL pour la colonne de clé étrangère. Une contrainte NOT NULL rompra le modèle hiérarchique.
📈 Performances et indexation
À mesure que les données augmentent, les requêtes sur les structures récursives peuvent devenir lentes. Une requête simple pour trouver tous les descendants d’un nœud spécifique peut nécessiter de nombreuses jointures ou des requêtes récursives.
Stratégies d’optimisation :
- Indexer les clés étrangères : Créez un index sur la colonne qui contient la référence au parent. Cela accélère la recherche des enfants.
- Chemins matérialisés : Certains systèmes stockent le chemin complet de la hiérarchie dans une colonne séparée (par exemple, “/1/5/12/20”). Cela permet un filtrage plus rapide basé sur les chaînes de caractères, bien qu’il nécessite des mises à jour à chaque insertion.
- Ensembles imbriqués : Un algorithme alternatif qui utilise des nombres gauche et droit pour représenter la profondeur. Cela est plus rapide pour la récupération, mais plus lent pour l’insertion.
- Profondeur des requêtes : Limitez la profondeur de récursion dans vos requêtes. Les boucles infinies peuvent faire planter le moteur de base de données si elles ne sont pas limitées.
🔍 Requête de données récursives
Récupérer des données hiérarchiques est plus complexe que récupérer des données plates. Les JOIN standards fonctionnent pour un seul niveau, mais plusieurs niveaux exigent une logique spécialisée.
🔄 Auto-jointures
La méthode la plus courante consiste à joindre la table à elle-même. Vous alias la table une fois comme parent et une fois comme enfant.
- Un seul niveau :Joignez la table à elle-même une fois pour obtenir le parent immédiat.
- Plusieurs niveaux :Exige plusieurs jointures, ce qui devient rapidement difficile à gérer.
- Inconvénient :Le nombre de jointures nécessaires est égal à la profondeur de la hiérarchie.
🔁 Expressions de table commune récursives (CTE)
Les moteurs de bases de données modernes prennent en charge les CTE récursives. Cela permet à une requête de s’exécuter avec un UNION ALL contre elle-même jusqu’à ce qu’aucune ligne supplémentaire ne soit trouvée.
- Membre d’ancrage :Le point de départ de la récursion (généralement le nœud racine).
- Membre récursif :La partie de la requête qui joint le résultat à la table pour trouver le niveau suivant.
- Terminaison :La requête s’arrête lorsque plus aucune ligne correspondante n’est trouvée.
- Avantage :Gère toute profondeur de hiérarchie sans avoir besoin de la connaître à l’avance.
🛡️ Intégrité des données et contraintes
Maintenir l’intégrité d’une table auto-référencée est essentiel. Si un parent est supprimé, que deviennent les enfants ?
🗑️ Suppression en cascade
Lorsqu’une ligne parente est supprimée, la base de données doit décider comment traiter les lignes enfants.
- RESTREINDRE :Empêche la suppression du parent s’il existe des enfants. Cela préserve les données, mais peut bloquer un nettoyage nécessaire.
- CASCADE :Supprime toutes les lignes enfants lorsque le parent est supprimé. Cela est dangereux dans les hiérarchies profondes car cela peut effacer accidentellement de grandes parties des données.
- METTRE À NULL :Définit la clé étrangère des enfants à NULL, les rendant ainsi de nouveaux nœuds racines. C’est souvent l’option la plus sûre pour préserver la structure des données.
- DEFINIR PAR DÉFAUT : Définit la clé étrangère sur une valeur par défaut (par exemple, une catégorie orpheline spécifique).
🔒 Contraintes de mise à jour
Modifier la clé primaire d’une ligne parente est risqué. Si vous modifiez l’ID d’un manager, vous devez mettre à jour cet ID dans chaque enregistrement d’employé qui fait référence à lui.
- Couche application : Gérer la mise à jour de manière transactionnelle pour garantir que toutes les références soient mises à jour ensemble.
- Déclencheurs de base de données : Peut automatiser la propagation des modifications d’ID, bien que cela ajoute de la complexité.
- Meilleure pratique : Évitez de mettre à jour les clés primaires dans les structures récursives dès que possible. Utilisez des clés de substitution (entiers auto-incrémentés) plutôt que des clés naturelles (comme les codes d’employés).
🚧 Dépannage des problèmes courants
Même avec une conception soignée, des problèmes peuvent survenir pendant le développement et la maintenance.
❓ Comment puis-je trouver la profondeur d’un arbre ?
Pour déterminer le niveau d’une ligne spécifique, vous devez remonter depuis la ligne jusqu’à la racine. Comptez le nombre de sauts.
- Approche de requête : Utilisez une requête récursive qui compte les lignes au fur et à mesure de la remontée.
- Approche application : Stockez la profondeur dans une colonne lors de l’insertion. Cela économise du temps de requête, mais nécessite une maintenance.
❓ Comment gérer les nœuds orphelins ?
Les nœuds orphelins sont des lignes où la clé étrangère pointe vers un parent inexistant. Cela se produit généralement à cause de bogues ou d’erreurs de saisie manuelle.
- Validation : Exécutez des vérifications d’intégrité périodiques pour trouver les lignes où la clé étrangère ne correspond à aucune clé primaire.
- Récupération : Décidez d’une politique : les déplacer vers une catégorie racine, les supprimer ou les signaler pour revue.
❓ Détérioration des performances au fil du temps
Au fur et à mesure que l’arbre grandit, les requêtes qui analysent tout l’arbre deviennent plus lentes.
- Mise en mémoire tampon : Mettez en mémoire tampon les structures hiérarchiques fréquemment consultées dans la mémoire de l’application.
- Archivage : Déplacez les parties historiques ou inactives de la hiérarchie vers des tables d’archivage.
- Partitionnement : Si les données sont massives, partitionnez la table par catégorie racine.
📝 Résumé des meilleures pratiques
Pour garantir une implémentation solide des entités auto-référentielles, suivez ces directives.
- Utilisez des clés surrogées :Préférez les entiers auto-incrémentés aux clés métiers pour la clé primaire.
- Autoriser les valeurs NULL : Assurez-vous que la colonne de clé étrangère autorise les valeurs NULL pour les nœuds racines.
- Indexer les clés étrangères : Indexez toujours la colonne qui contient la référence au parent.
- Valider les cycles : Implémentez des vérifications pour empêcher les références circulaires (A -> B -> A).
- Limitez la récursion : Limitez la profondeur de récursion dans les requêtes pour éviter les débordements de pile.
- Documentez le schéma : Indiquez clairement quelles colonnes sont auto-référentielles dans votre documentation ERD.
- Prévoyez la suppression : Définissez des règles claires pour les suppressions en cascade ou le passage à NULL lors de la suppression du parent.
- Testez les hiérarchies profondes : Testez vos requêtes avec au moins 10 niveaux de profondeur pour garantir que les performances sont maintenues.
🔮 Considérations futures
La technologie des bases de données évolue continuellement. Bien que le concept d’une entité auto-référentielle reste constant, les outils pour la gérer s’améliorent.
- Bases de données graphes : Certains systèmes modernes traitent les relations comme des entités de premier plan. Ils gèrent les chemins récursifs nativement, sans la complexité du SQL.
- Prise en charge du JSON : Les moteurs de base de données plus récents permettent de stocker des données hiérarchiques dans des colonnes JSON, ce qui peut simplifier la conception du schéma pour des structures profondément imbriquées.
- Améliorations des ORM : Les mappages objet-relationnel (ORM) deviennent de plus en plus efficaces pour gérer automatiquement les relations récursives, réduisant ainsi le code boilerplate.
Malgré ces avancées, la logique fondamentale de la relation récursive reste la même. Comprendre les mécanismes sous-jacents des clés primaires, des clés étrangères et des relations entre tables est essentiel pour tout professionnel technique travaillant avec des structures de données.
En suivant ces principes, vous pouvez construire des systèmes suffisamment flexibles pour gérer des hiérarchies complexes tout en restant performants et maintenables. L’entité auto-référentielle est un outil puissant dans votre arsenal de modélisation de données, à condition de l’utiliser avec précision et soin.