

Concevoir un schéma de base de données robuste pour les plateformes de médias sociaux exige une compréhension approfondie de la manière dont les utilisateurs interagissent, partagent et consomment des informations. Contrairement aux systèmes transactionnels traditionnels, les réseaux sociaux impliquent des relations complexes plusieurs à plusieurs, des structures de données récursives et des exigences d’échelle massive. Le diagramme Entité-Relation (ERD) sert de plan directeur pour ces interactions, garantissant l’intégrité des données tout en soutenant une croissance rapide. Ce guide explore les stratégies essentielles pour modéliser efficacement les données des médias sociaux.
Comprendre le défi fondamental 🧩
Les applications de médias sociaux ne sont pas simplement des répertoires de contenu ; elles sont des réseaux dynamiques de relations. Un simple article de blog diffère considérablement d’un fil d’actualité de médias sociaux en raison de la couche d’engagement. Les likes, partages, commentaires et abonnements créent un réseau de connexions qui doit être modélisé avec précision. Une mauvaise modélisation entraîne des performances de requêtes lentes, des incohérences de données et des difficultés à implémenter des fonctionnalités telles que les fils d’actualité ou les suggestions d’amis.
- Volume :Les plateformes sociales génèrent des millions d’événements par seconde.
- Vitesse :Les données arrivent sous forme de flux en temps réel qui doivent être traitées immédiatement.
- Variété :Le contenu inclut du texte, des images, des vidéos, des métadonnées et des données de localisation.
- Relations :La valeur fondamentale réside dans les connexions entre les entités.
Lors de la construction d’un ERD, l’objectif principal est d’équilibrer la normalisation et les performances. Une sur-normalisation peut rendre les jointures trop coûteuses pour les lectures fréquentes. Une sur-dénormalisation peut entraîner une redondance des données et des problèmes d’intégrité. Les sections suivantes détaillent les entités et les relations spécifiques qui définissent ce domaine.
Définition des entités fondamentales 🔑
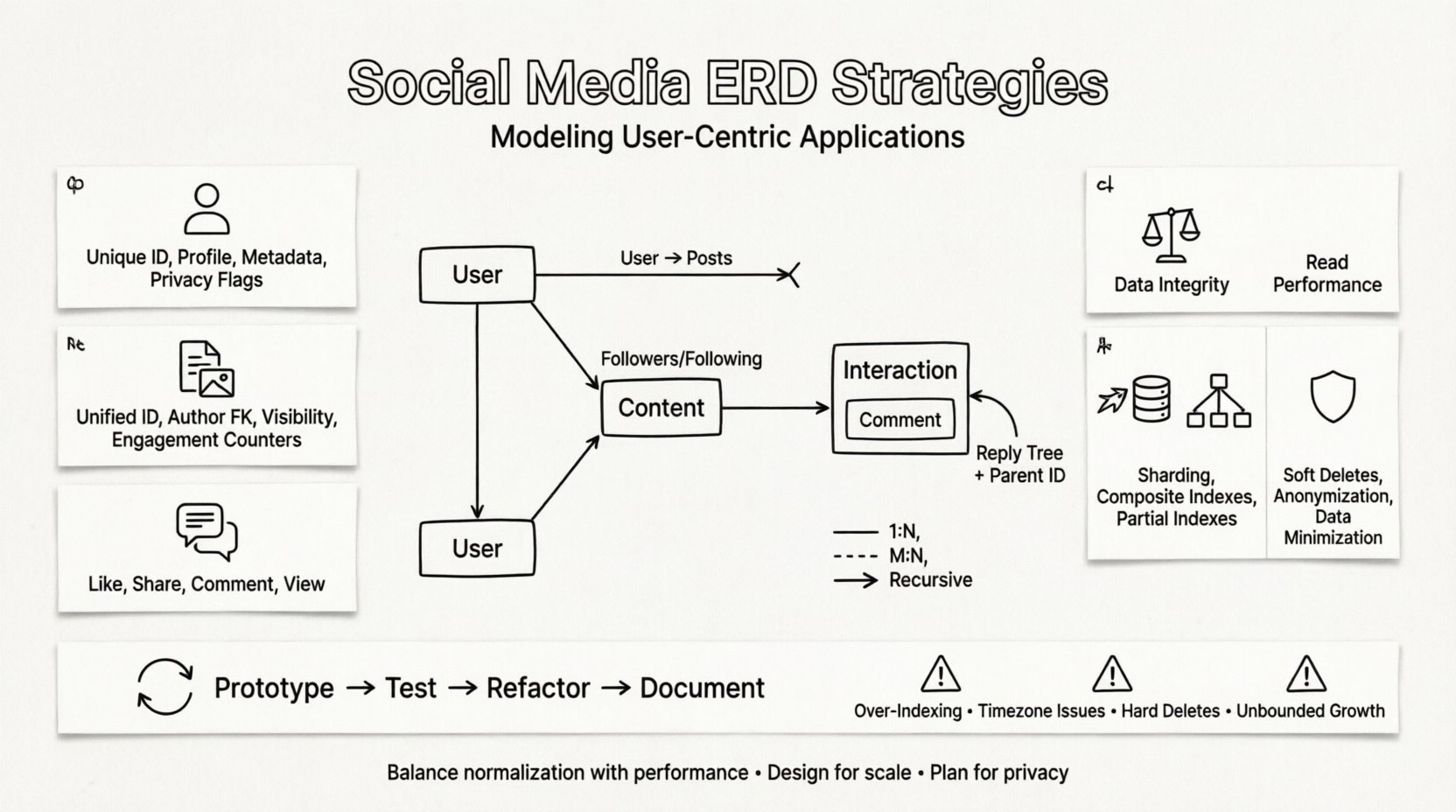
Chaque système de médias sociaux tourne autour de quelques entités fondamentales. Les identifier correctement est la première étape pour créer un schéma évolutif. Ces entités représentent les briques de base fondamentales de l’application.
1. L’entité Utilisateur 👤
L’utilisateur est le nœud central du réseau. Cette entité stocke les détails d’authentification, les informations de profil et les préférences. Elle doit être conçue pour gérer efficacement des millions d’enregistrements.
- Identifiant unique :Une clé surrogée est préférée aux clés naturelles pour des raisons de performance et d’anonymat.
- Données de profil :Nom, bio, avatar et statut de vérification.
- Métadonnées :Horodatages de la création du compte, de la dernière connexion et de la suppression.
- Drapeaux de confidentialité :Paramètres contrôlant la visibilité des données pour les autres utilisateurs.
2. L’entité Contenu 📝
Le contenu est le carburant des plateformes sociales. Il englobe les publications, les histoires, les images, les vidéos et les commentaires. Un schéma souple est nécessaire car les différents types de contenu ont des attributs différents.
- ID unifié :Un ID générique qui lie aux tables spécifiques de contenu.
- Référence de l’auteur : Une clé étrangère liée à l’entité Utilisateur.
- Portée de visibilité : Public, privé, réservé aux amis uniquement, ou groupes spécifiques.
- Compteurs d’engagement : Comptes mis en cache pour les likes et les commentaires afin de réduire la charge des requêtes.
3. L’entité d’interaction 💬
Les interactions représentent les actions que les utilisateurs effectuent sur le contenu ou d’autres utilisateurs. Il s’agit de transactions à fort volume qui dictent souvent les exigences de performance du système.
- J’aime : Un état binaire entre un utilisateur et du contenu.
- Partager : Une référence au contenu original avec un nouveau contexte.
- Commentaire : Une relation hiérarchique ou en fil de discussion avec le contenu.
- Vue : Souvent enregistré séparément en raison du volume élevé et de son moindre intérêt pour l’intégrité.
Modélisation des relations 🕸️
La véritable complexité des médias sociaux réside dans les relations entre les entités. Les techniques classiques de modélisation relationnelle peinent souvent à gérer la nature récursive des graphes sociaux. Une attention particulière doit être portée à la manière dont ces connexions sont stockées.
Relations un-à-plusieurs
Ce sont les relations les plus courantes et les plus simples. Par exemple, un utilisateur peut avoir de nombreux messages, mais un message appartient à un seul utilisateur. Cela est modélisé à l’aide d’une clé étrangère dans la table enfant.
- Exemple : Identifiant d’utilisateur dans la table Messages.
- Avantage : Récupération rapide de tous les messages pour un profil spécifique.
- Contrainte : Assure automatiquement l’intégrité référentielle.
Relations plusieurs-à-plusieurs
Les abonnés et les abonnements sont l’exemple classique. Un utilisateur suit de nombreux autres utilisateurs, et un utilisateur est suivi par de nombreux autres utilisateurs. Cela nécessite une table de jonction pour résoudre la relation.
- Table de jonction : Contient l’identifiant utilisateur A et l’identifiant utilisateur B.
- Horodatages : Lorsque l’action suivante s’est produite.
- Statut : En attente, accepté ou bloqué.
- Performances : L’indexation est essentielle sur les deux clés étrangères.
Relations récursives
Certaines relations impliquent le même type d’entité. Un commentaire peut avoir des réponses à des réponses. Cela crée une structure arborescente qui est difficile à interroger dans les modèles relationnels standards.
- ID du parent : Une clé étrangère pointant vers l’ID du commentaire.
- Profondeur : Limiter la profondeur de récursion empêche les boucles infinies.
- Chemins matérialisés : Stockage du chemin de l’arbre pour un parcours plus rapide.
| Type de relation | Exemple | Stratégie d’implémentation | Impact sur les performances |
|---|---|---|---|
| Un à plusieurs | Utilisateur – Publications | Clé étrangère dans l’enfant | Faible (indexation standard) |
| Plusieurs à plusieurs | Utilisateur – Suit | Table d’association | Moyen (surcharge de jointure) |
| Récursif | Commentaire – Réponse | Clé étrangère auto-référente | Élevé (requêtes complexes) |
| Associatif | Tag – Utilisateur | Clés composées | Moyen (recherche intensive) |
Normalisation vs. dénormalisation ⚖️
Dans les systèmes de médias sociaux, la performance de lecture dépasse souvent celle de l’écriture. Les utilisateurs s’attendent à ce que les flux se chargent instantanément, même lorsque des millions d’enregistrements sont impliqués. Cela exige un équilibre soigneux entre normalisation et dénormalisation.
Le cas pour la normalisation
La normalisation garantit l’intégrité des données et réduit la redondance. Elle est essentielle pour les données principales qui ne changent pas fréquemment.
- Consistance des données : Les mises à jour ont lieu à un seul endroit.
- Efficacité du stockage : Moins de stockage de données redondantes.
- Maintenabilité : Plus facile d’appliquer les règles métier.
Le cas pour la dénormalisation
La dénormalisation consiste à dupliquer des données afin de réduire le nombre de jointures nécessaires lors des lectures. C’est courant dans les flux sociaux.
- Vitesse de lecture : Moins de jointures signifient une exécution de requête plus rapide.
- Mise en cache : Comptages agrégés (par exemple, nombre total de likes) stockés directement.
- Surcharge d’écriture : Les mises à jour doivent être propagées à toutes les copies.
Approche hybride
Une stratégie pratique consiste à normaliser le schéma principal tout en dénormalisant les métriques fréquemment lues. Par exemple, stocker le nom d’utilisateur dans la table des publications aux côtés de l’ID utilisateur. Cela évite une jointure lors de l’affichage de la publication, au prix d’une logique de synchronisation occasionnelle.
Stratégies d’évolutivité pour les modèles ERD 🚀
À mesure que la base d’utilisateurs grandit, le schéma doit évoluer pour gérer la charge accrue. Le dimensionnement vertical a des limites ; le dimensionnement horizontal nécessite des considérations spécifiques au schéma.
Partitionnement
Le partitionnement divise les grandes tables en morceaux plus petits et gérables. Dans les médias sociaux, les données sont souvent partitionnées par ID utilisateur ou par date.
- Partitionnement horizontal : Répartition des utilisateurs sur des shards différents en fonction de plages d’ID.
- Partitionnement vertical : Déplacement des colonnes peu fréquemment accessibles vers une table séparée.
- Partitionnement par date :Archivage des anciens messages dans des tables de stockage froid.
Stratégies d’indexation
Les index sont essentiels pour les performances des requêtes, mais ils ralentissent les écritures. Une approche stratégique de l’indexation est nécessaire.
- Index composés :Couverture des modèles de requêtes courants (par exemple, ID utilisateur + horodatage).
- Index partiels :Indexation uniquement des lignes pertinentes (par exemple, messages actifs).
- Index de recherche :Utilisation de moteurs de recherche full-text pour la découverte de contenu.
Considérations sur la vie privée et la conformité 🛡️
La modélisation des données moderne doit tenir compte des réglementations sur la vie privée telles que le RGPD et le CCPA. La conception du schéma influence la facilité avec laquelle les données peuvent être anonymisées ou supprimées.
Droit à l’oubli
Les utilisateurs peuvent demander la suppression de leurs données. Le schéma ER doit permettre les suppressions en cascade ou les suppressions douces sans rompre l’intégrité référentielle.
- Suppressions douces :Ajout d’un indicateur « is_deleted » au lieu de supprimer les lignes.
- Données orphelines :Gestion des données qui font référence à un utilisateur supprimé.
- Anonymisation :Remplacement des identifiants personnels par des hachages.
Minimisation des données
Stockez uniquement les données strictement nécessaires. La collecte excessive de métadonnées augmente les coûts de stockage et les risques liés à la vie privée.
- Politiques de rétention :Suppression automatique des journaux après une période définie.
- Permissions granulaires :Contrôles d’accès au niveau des lignes.
- Chiffrement :Champ sensibles chiffrés au repos.
Gestion des métadonnées et des journaux 📉
Au-delà des entités principales, les systèmes génèrent de vastes quantités de métadonnées. Cela inclut les analyses, les journaux d’erreurs et les traces d’audit. Ces éléments ne doivent pas encombrer le schéma transactionnel principal.
Séparation des préoccupations
Gardez la base de données transactionnelle propre. Transférez les journaux lourds et les analyses vers des systèmes distincts.
- Flux d’événements :Utilisez des files de messages pour la journalisation asynchrone.
- Tables d’analyse :Tables distinctes pour les tendances historiques.
- Données chronologiques :Stockage spécifique pour les métriques au fil du temps.
Processus itératif de conception 🔄
Les diagrammes entité-relations sont rarement parfaits dès le premier brouillon. Les exigences des réseaux sociaux évoluent rapidement avec l’introduction de nouvelles fonctionnalités. Le processus de conception doit être itératif.
- Prototype :Concevez un schéma minimal viable pour la fonctionnalité principale.
- Test :Effectuez des tests de charge avec des volumes de données réalistes.
- Refactorisation :Ajustez les relations en fonction des goulets d’étranglement de performance.
- Documentation :Maintenez des diagrammes à jour pour les développeurs futurs.
Péchés courants à éviter ⚠️
Même les architectes expérimentés commettent des erreurs lors de la modélisation des données sociales. Reconnaître ces schémas aide à prévenir les problèmes futurs.
- Sur-indexation :Trop d’index ralentissent considérablement les opérations d’écriture.
- Ignorer les fuseaux horaires :Le stockage des horodatages sans contexte de fuseau horaire entraîne de la confusion.
- Valeurs codées en dur :Évitez d’incorporer la logique métier dans le schéma (par exemple, des valeurs d’état spécifiques).
- Oublier les suppressions douces :Les suppressions rigides peuvent rompre les contraintes de clés étrangères à travers le réseau.
- Croissance illimitée :Le fait de ne pas archiver les anciennes données entraîne un gonflement des tables.
Considérations finales pour la croissance future 🔮
Construire une plateforme de médias sociaux est une entreprise à long terme. Le modèle de données doit être suffisamment souple pour s’adapter aux changements sans nécessiter une refonte complète. Concentrez-vous sur la clarté, la scalabilité et la maintenabilité. Des revues régulières du schéma par rapport aux schémas d’utilisation réels garantissent que le système reste robuste à mesure qu’il évolue.
- Gestion des versions :Prévoyez des migrations de schéma qui supportent la compatibilité descendante.
- Surveillance :Surveillez les performances des requêtes pour identifier précocement les faiblesses du schéma.
- Retours de la communauté :Écoutez comment les données sont réellement utilisées par l’équipe d’ingénierie.
En suivant ces stratégies, les développeurs peuvent créer une base solide pour des applications centrées sur l’utilisateur. L’ERD n’est pas seulement un schéma ; c’est l’intégrité structurelle de toute la plateforme. Une planification soigneuse aujourd’hui évite des dettes techniques importantes plus tard.