











डेटाबेस आर्किटेक्चर एक दृष्टि से शुरू होता है। कोड की एक भी पंक्ति लिखे जाने से पहले, डेटा संरचनाओं को अवधारणात्मक रूप से विचार करना, व्यवस्थित करना और मान्यता देना आवश्यक है। एंटिटी-रिलेशनशिप डायग्राम (ERD) इस संरचना के लिए ब्लूप्रिंट के रूप में कार्य करता है, जो वास्तविक दुनिया की आवश्यकताओं को एक दृश्य मॉडल में बदलता है। हालांकि, एक डायग्राम अकेले डेटा को स्टोर नहीं करता है। तार्किक स्कीमा वह भौतिक कार्यान्वयन है जो जानकारी के भौतिक स्टोरेज, प्राप्ति और सुरक्षा के तरीके को नियंत्रित करता है।
अमूर्त ERD से भौतिक स्कीमा में संक्रमण करने के लिए सटीकता की आवश्यकता होती है। इसमें एंटिटी को टेबल में मैप करना, संबंधों को कीज़ में मैप करना और गुणों को कॉलम में मैप करना शामिल है। इस प्रक्रिया के द्वारा पूरी प्रणाली की अखंडता और प्रदर्शन निर्धारित होता है। इस अनुवाद के तात्पर्यों को समझने से यह सुनिश्चित होता है कि डेटाबेस भार के तहत भी मजबूत रहे और भविष्य की आवश्यकताओं के अनुकूल हो।
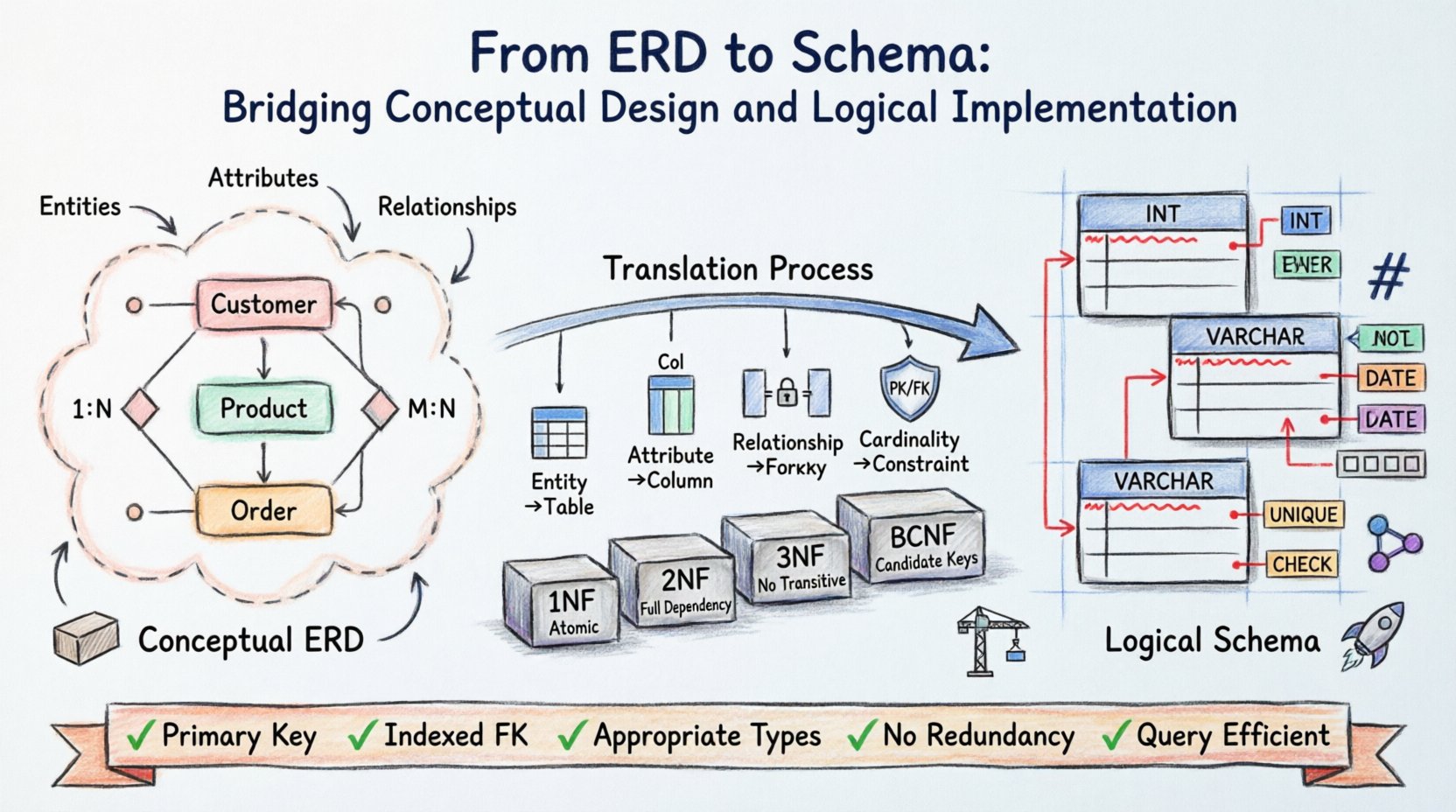
अवधारणात्मक आधार को समझना 🧱
एंटिटी-रिलेशनशिप डायग्राम अवधारणात्मक स्तर पर कार्य करता है। इसका ध्यान “क्या” पर होता है, न कि “कैसे” पर। इस चरण में, हितधारक और वास्तुकार क्षेत्र में रुचि के मुख्य वस्तुओं की पहचान करते हैं।
- एंटिटीज़: ये अलग-अलग वस्तुओं या अवधारणाओं का प्रतिनिधित्व करते हैं, जैसे एक ग्राहक, उत्पाद या आदेश।
- गुण: ये एक एंटिटी के गुणों को परिभाषित करते हैं, जैसे नाम, मूल्य या तारीख।
- संबंध: ये एंटिटीज़ के बीच बातचीत को वर्णित करते हैं, जैसे एक ग्राहक द्वारा आदेश देना।
इस चरण में तकनीकी सीमाएं द्वितीयक होती हैं। लक्ष्य स्पष्टता है। यदि अवधारणात्मक मॉडल अस्पष्ट है, तो परिणामस्वरूप स्कीमा दोषपूर्ण होगा। आम गलतियों में गुणों को एंटिटीज़ के साथ मिलाना या कार्डिनैलिटी को सही तरीके से परिभाषित न करना शामिल है।
कार्डिनैलिटी और भागीदारी
ERD डिज़ाइन के सबसे महत्वपूर्ण पहलुओं में से एक कार्डिनैलिटी को परिभाषित करना है। यह एंटिटीज़ के बीच मात्रात्मक संबंध को निर्धारित करता है।
- एक से एक (1:1): टेबल A में एक एकल रिकॉर्ड टेबल B में बिल्कुल एक रिकॉर्ड से संबंधित होता है।
- एक से बहुत (1:N): टेबल A में एक एकल रिकॉर्ड टेबल B में बहुत सारे रिकॉर्ड से संबंधित होता है।
- बहुत से बहुत (M:N): टेबल A में बहुत सारे रिकॉर्ड टेबल B में बहुत सारे रिकॉर्ड से संबंधित होते हैं।
भागीदारी की सीमाएं इस मॉडल को और बेहतर बनाती हैं। क्या संबंध अनिवार्य है या वैकल्पिक? यदि एक ग्राहक को आदेश देना है, तो भागीदारी अनिवार्य है। यदि वे आदेश के बिना भी अस्तित्व में रह सकते हैं, तो यह वैकल्पिक है। इन अंतरों को तार्किक स्कीमा में कॉलम की नलता के लिए सीधे प्रभावित करता है।
तार्किक स्कीमा: संरचनात्मक कार्यान्वयन 🏗️
तार्किक स्कीमा सिद्धांत और भौतिक स्टोरेज के बीच के अंतर को पार करता है। जबकि ERD प्लेटफॉर्म स्वतंत्र है, तार्किक स्कीमा डेटा को विशिष्ट स्टोरेज तकनीकों के लिए तैयार करता है। इस परत में डेटा प्रकार, सीमाएं और नॉर्मलाइजेशन के संबंध में विशिष्ट नियम शामिल होते हैं।
अवधारणात्मक मॉडल के विपरीत, तार्किक स्कीमा को डेटा अखंडता को स्पष्ट रूप से संबोधित करना आवश्यक है। इसे प्राथमिक कीज़, विदेशी कीज़ और अद्वितीय सीमाओं के माध्यम से प्राप्त किया जाता है। इन नियमों से अनाथ रिकॉर्ड से बचा जाता है और यह सुनिश्चित किया जाता है कि संबंध स्थिर रहें।
की अनुवाद नियम
ERD से स्कीमा में कीज़ के अनुवाद के लिए संबंधित सिद्धांत का सख्ती से पालन करना आवश्यक है।
- प्राथमिक कीज़: प्रत्येक एंटिटी को एक अद्वितीय पहचानकर्ता की आवश्यकता होती है। ERD में, इसे अक्सर नीचे लाइन के साथ चिह्नित किया जाता है। स्कीमा में, इसे प्राथमिक की सीमा बन जाता है।
- विदेशी कीज़: संबंधों को विदेशी कीज़ के माध्यम से कार्यान्वित किया जाता है। एक बहुत से बहुत संबंध के लिए आमतौर पर एक सहयोगी टेबल की आवश्यकता होती है जिसमें दो विदेशी कीज़ होती हैं ताकि कार्डिनैलिटी को हल किया जा सके।
- संयुक्त कुंजियाँ: यदि कोई एकता अद्वितीयता के लिए एकाधिक विशेषताओं पर निर्भर है, तो इन्हें तार्किक परिभाषा में जोड़ा जाना चाहिए।
एंटिटीज को टेबल में मैप करना 🔄
एक एंटिटी को टेबल में बदलने की प्रक्रिया सरल है, लेकिन विस्तार से ध्यान देने की आवश्यकता होती है। प्रत्येक एंटिटी को आमतौर पर एक टेबल में मैप किया जाता है। हालांकि, जटिल परिदृश्यों के लिए विभाजन या संयोजन की आवश्यकता हो सकती है।
विशेषीकरण और सामान्यीकरण का प्रबंधन
जब एंटिटीज सामान्य विशेषताओं को साझा करती हैं, तो उन्हें उपवर्ग के रूप में मॉडल किया जा सकता है। उदाहरण के लिए, एक वाहन एंटिटी के उपवर्ग जैसे कार और ट्रक.
एक योजना में इसके लागू करने के दो मुख्य तरीके हैं:
- एकल टेबल विरासत: सभी उपवर्गों को एक साथ एक टेबल में रखा जाता है, जिसमें एक विभेदक कॉलम होता है। इससे जॉइन कम होते हैं, लेकिन NULL मान बढ़ते हैं।
- वर्ग टेबल विरासत: प्रत्येक उपवर्ग को अपनी टेबल मिलती है, जो मुख्य वर्ग से विदेशी कुंजी द्वारा जुड़ी होती है। इससे अधिक सामान्यीकृत बनता है, लेकिन अधिक जटिल प्रश्नों की आवश्यकता होती है।
विशेषता मैपिंग
ईआरडी से विशेषताओं को कॉलम परिभाषाओं से मैप करना आवश्यक है। सभी विशेषताओं का सीधे अनुवाद नहीं होता है।
- सरल विशेषताएँ:सीधे कॉलम में मैप करें।
- संयुक्त विशेषताएँ: व्यक्तिगत कॉलम में तोड़ना होगा (उदाहरण के लिए, पता सड़क, शहर, जिप में विभाजित होता है)।
- बहुमूल्य विशेषताएँ: एक ही कॉलम में संग्रहीत नहीं किया जा सकता है। इन्हें विदेशी कुंजी द्वारा जुड़ी अलग टेबल की आवश्यकता होती है (उदाहरण के लिए, एक उपयोगकर्ता के फोन नंबर)।
- व्युत्पन्न विशेषताएँ: इन्हें अन्य डेटा से गणना की जाती है (उदाहरण के लिए, जन्म तिथि से उम्र)। इन्हें अतिरेक से बचने के लिए आमतौर पर योजना से बाहर रखा जाता है, जब तक कि प्रदर्शन अनुकूलन महत्वपूर्ण नहीं होता है।
नॉर्मलाइजेशन गहन अध्ययन 📊
नॉर्मलाइजेशन डेटा को व्यवस्थित करने की प्रक्रिया है जिससे अतिरेक कम होता है और अखंडता में सुधार होता है। ईआरडी से योजना में जाने पर, डिजाइनरों को यह सुनिश्चित करना होता है कि मॉडल विशिष्ट नॉर्मल रूपों का पालन करे।
पहला सामान्य रूप (1NF)
एक तालिका 1NF में होती है यदि इसमें परमाणु मान होते हैं। किसी भी कॉलम में सूची या मानों का सेट नहीं होना चाहिए। यदि किसी एकता के एक ही लक्षण के लिए कई मान हैं, तो एक नई तालिका बनानी चाहिए।
द्वितीय सामान्य रूप (2NF)
2NF के लिए तालिका को 1NF में होना चाहिए और आंशिक निर्भरता नहीं होनी चाहिए। सभी गैर-कुंजी विशेषताओं को पूर्ण मुख्य कुंजी पर निर्भर होना चाहिए, केवल इसके कुछ हिस्से पर नहीं। यह संयुक्त कुंजी वाली तालिकाओं के लिए महत्वपूर्ण है।
तृतीय सामान्य रूप (3NF)
3NF के लिए यह आवश्यक है कि कोई अंतरित निर्भरता न हो। गैर-कुंजी विशेषता किसी अन्य गैर-कुंजी विशेषता पर निर्भर नहीं होनी चाहिए। उदाहरण के लिए, यदिशहर पर निर्भर हैपिन कोड, औरपिन कोड पर निर्भर हैग्राहक आईडी, शहर को अलग तालिका में स्थानांतरित किया जाना चाहिए।
बॉयस-कॉड सामान्य रूप (BCNF)
BCNF, 3NF का कठोर रूप है। यह उन मामलों को संभालता है जहां एक तालिका में कई उम्मीदवार कुंजी हों और गैर-कुंजी विशेषता उन कुंजियों के उपसमुच्चय पर निर्भर हो।
| सामान्य रूप | आवश्यकता | फोकस |
|---|---|---|
| 1NF | परमाणु मान | दोहराए जाने वाले समूहों को हटाएं |
| 2NF | पूर्ण निर्भरता | आंशिक निर्भरताओं को हटाएं |
| 3NF | कोई अंतरित निर्भरता नहीं | अप्रत्यक्ष निर्भरताओं को हटाएं |
| BCNF | उम्मीदवार की निर्भरता | ओवरलैपिंग की को समाप्त करें |
डेटा प्रकार और सीमाएँ 🔒
स्टोरेज दक्षता और प्रश्न प्रदर्शन के लिए सही डेटा प्रकार चुनना महत्वपूर्ण है। ईआरडी लगभग कभी भी सटीक डेटा प्रकार नहीं निर्दिष्ट करता है, जिसे तार्किक डिजाइन चरण के लिए छोड़ दिया जाता है।
पूर्णांक बनाम संख्यात्मक
पूर्णांक पूर्ण संख्याओं को स्टोर करते हैं और गणना के लिए तेज होते हैं। संख्यात्मक या दशमलव प्रकार निर्णय बनाए रखने के लिए वित्तीय डेटा के लिए उपयोग किए जाते हैं। मुद्रा के लिए पूर्णांक का उपयोग करने से गोलाई त्रुटियाँ हो सकती हैं।
तारीख और समय
टाइमस्टैम्प यूटीसी और स्थानीय समय के बीच अंतर करना चाहिए। तारीखों को स्ट्रिंग के रूप में स्टोर करना एक सामान्य त्रुटि है जो कुशल वर्गीकरण और फ़िल्टरिंग को रोकती है। डेटाबेस इंजन द्वारा प्रदान किए गए मानक तारीख प्रकार का उपयोग करें।
सीमाएँ
सीमाएँ डेटाबेस स्तर पर व्यापार नियमों को लागू करती हैं।
- NOT NULL: सुनिश्चित करता है कि एक कॉलम में हमेशा कोई मान होता है।
- UNIQUE: कॉलम में दोहराए गए मानों को रोकता है।
- CHECK: एक विशिष्ट शर्त के खिलाफ डेटा की पुष्टि करता है (उदाहरण के लिए, उम्र > 0)।
- DEFAULT: यदि कोई मान प्रदान नहीं किया गया है, तो एक फॉलबैक मान प्रदान करता है।
आम त्रुटियाँ और सत्यापन ⚠️
एक मजबूत योजना के साथ भी, कार्यान्वयन के दौरान त्रुटियाँ हो सकती हैं। इन त्रुटियों को जल्दी से पहचानने से बाद में महत्वपूर्ण समय बचता है।
- अत्यधिक सामान्यीकरण: बहुत सारी टेबलें बनाने से प्रश्न धीमे और जटिल हो सकते हैं। पढ़ने पर अधिक निर्भर कार्यभार के लिए असामान्यीकरण आवश्यक हो सकता है।
- दुर्बल कीज़: प्राथमिक की के रूप में प्राकृतिक कीज़ (जैसे ईमेल पते) का उपयोग करना जोखिम भरा है। वे बदल सकते हैं और श्रृंखलाबद्ध समस्याएँ पैदा कर सकते हैं। सुरोगेट कीज़ (ऑटो-इनक्रीमेंट आईडी) अक्सर सुरक्षित होती हैं।
- अनुपस्थित सूचियाँ: विदेशी कीज़ को सूचीबद्ध किया जाना चाहिए। उनके बिना, टेबलों को जोड़ना प्रदर्शन की बाधा बन जाता है।
- चक्रीय निर्भरताएँ: यह सुनिश्चित करना कि टेबल संबंधों में लूप न बनाएं, संदर्भात्मक अखंडता बनाए रखने के लिए महत्वपूर्ण है।
सत्यापन चेकलिस्ट
स्कीमा को अंतिम रूप देने से पहले, इस सत्यापन सूची को चलाएं:
- क्या प्रत्येक तालिका में प्राथमिक कुंजी है?
- क्या सभी विदेशी कुंजियाँ सही तरीके से सूचीबद्ध हैं?
- क्या डेटा प्रकार अपेक्षित आयतन के लिए उपयुक्त हैं?
- क्या कोई अतिरिक्त कॉलम हैं जिन्हें हटाया जा सकता है?
- क्या स्कीमा आवश्यक प्रश्नों को कुशलतापूर्वक समर्थन करता है?
प्रदर्शन पर विचार 🚀
तार्किक स्कीमा केवल सही होने के बारे में नहीं है; यह गति के बारे में भी है। जैसे-जैसे डेटा बढ़ता है, संरचना को बढ़ी हुई लोड को संभालना चाहिए।
विभाजन
बड़ी तालिकाओं को छोटे, अधिक प्रबंधनीय टुकड़ों में बांटा जा सकता है। इसे क्षैतिज रूप से (पंक्तियों द्वारा) या ऊर्ध्वाधर रूप से (स्तंभों द्वारा) किया जा सकता है। विभाजन के कारण प्रश्न केवल संबंधित डेटा खंडों तक पहुंच सकते हैं।
संरचनात्मक पैटर्न
शार्डिंग जैसे डिज़ाइन पैटर्न डेटा को कई सर्वरों पर वितरित करते हैं। इसके लिए तार्किक डिज़ाइन चरण के दौरान सावधानीपूर्वक योजना बनाने की आवश्यकता होती है ताकि संबंधित डेटा को जहां संभव हो वहां एक साथ रखा जा सके।
सर्वोत्तम प्रथाओं का सारांश ✅
डेटाबेस स्कीमा बनाना एक आवर्ती प्रक्रिया है। इसमें सैद्धांतिक शुद्धता और व्यावहारिक सीमाओं के बीच संतुलन बनाए रखने की आवश्यकता होती है।
- सब कुछ दस्तावेज़ीकरण करें:ईआरडी तत्वों को स्कीमा परिभाषाओं से जोड़ने वाला स्पष्ट दस्तावेज़ीकरण बनाए रखें।
- संस्करण नियंत्रण:स्कीमा परिवर्तनों को कोड के रूप में लें। समय के साथ परिवर्तनों को ट्रैक करने के लिए माइग्रेशन स्क्रिप्ट का उपयोग करें।
- नियमित रूप से समीक्षा करें:जैसे-जैसे व्यवसाय की आवश्यकताएं बदलती हैं, वैसे ही स्कीमा को भी बदलना चाहिए। वर्तमान आवश्यकताओं के अनुरूप होने की गारंटी के लिए नियमित समीक्षा योजना बनाएं।
- सहयोग करें:विकासकर्ताओं, विश्लेषकों और हितधारकों को जल्दी से शामिल करें। अलग-अलग दृष्टिकोण किन्हीं किन्हीं किनारे के मामलों को उजागर करते हैं जिन्हें एकल डिज़ाइनर छोड़ सकता है।
एंटिटी-रिलेशनशिप डायग्राम से तार्किक स्कीमा तक संक्रमण डेटा इंजीनियरिंग की रीढ़ है। यह अमूल्य विचारों को एक कार्यात्मक प्रणाली में बदलता है। नॉर्मलाइजेशन नियमों का पालन करने, उपयुक्त डेटा प्रकार चुनने और प्रदर्शन की आवश्यकताओं की भविष्यवाणी करने से निर्मित डेटाबेस एप्लिकेशनों के लिए एक विश्वसनीय आधार बनेगा।
अंततः, स्कीमा की गुणवत्ता प्रणाली की लंबाई के निर्धारण करती है। एक अच्छी तरह से बनी डिज़ाइन तकनीकी दायित्व को कम करती है और भविष्य के विकास को सुगम बनाती है। स्पष्टता, अखंडता और विस्तार्यता पर ध्यान केंद्रित करके ऐसी प्रणालियाँ बनाएं जो समय के परीक्षण के लिए लंबे समय तक टिक सकें।