











डेटाबेस डिजाइन की जटिल संरचना में, इंजीनियर्स को आमतौर पर आत्म-संदर्भित एंटिटी के बराबर कोई अवधारणा चुनौती नहीं देती है। इसे रिकर्सिव रिलेशनशिप के रूप में भी जाना जाता है, जो एक टेबल को खुद से जोड़ने की अनुमति देता है, जिससे एक समतल स्कीमा के भीतर जैरार्की और जटिल संरचनाओं का मॉडलिंग संभव होता है। इसे सही तरीके से लागू करने की समझ डेटा अखंडता और क्वेरी प्रदर्शन को बनाए रखने के लिए निर्णायक है।
एंटिटी रिलेशनशिप डायग्राम (ERD) डिजाइन करते समय, अधिकांश संबंध दो अलग-अलग एंटिटीज को जोड़ते हैं। हालांकि, वास्तविक दुनिया के डेटा के कई मामलों में एक ही एंटिटी को अपने ही प्रकार से जोड़ने की आवश्यकता होती है। एक मैनेजर कर्मचारियों को नियंत्रित करता है, एक श्रेणी उपश्रेणियों को समावेश करती है, और एक उत्पाद एक किट का हिस्सा हो सकता है। इन परिस्थितियों में रिकर्सिव रिलेशनशिप की आवश्यकता होती है।
यह गाइड स्वयं-संदर्भित एंटिटीज को हैंडल करने के यांत्रिकी, डिजाइन पैटर्न और सर्वोत्तम प्रथाओं का अध्ययन करता है। हम इन संबंधों को विशिष्ट सॉफ्टवेयर टूल्स पर निर्भर बिना कैसे संरचित करना है, उन सार्वभौमिक डेटाबेस सिद्धांतों पर ध्यान केंद्रित करेंगे।
🧐 स्वयं-संदर्भित एंटिटी क्या है?
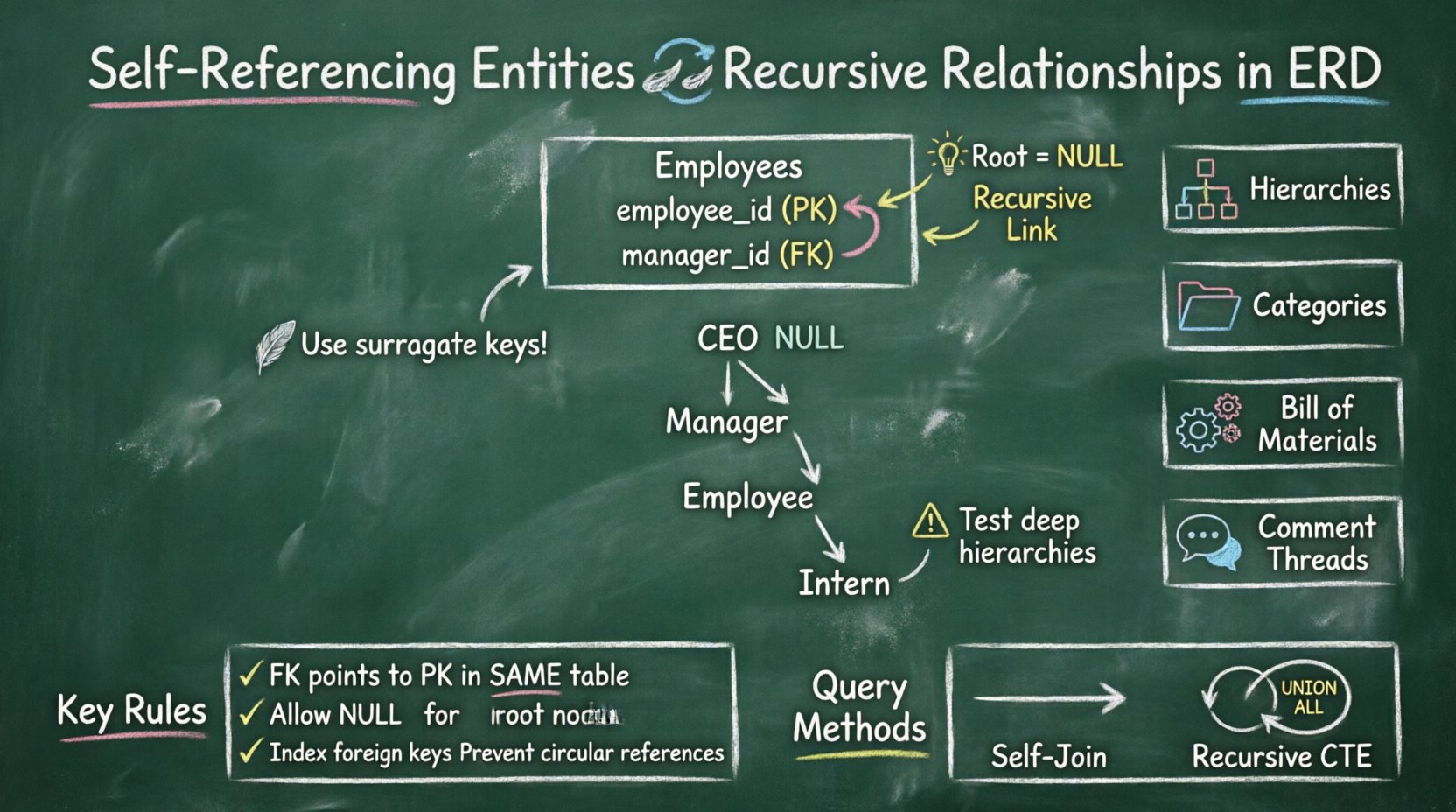
एक स्वयं-संदर्भित एंटिटी तब होती है जब एक टेबल में एक विदेशी कुंजी उसी टेबल की प्राथमिक कुंजी की ओर इशारा करती है। इससे एक लूप बनता है जहां एक ही टेबल के डेटा पंक्तियां उसी टेबल की अन्य पंक्तियों को संदर्भित कर सकती हैं। यह जैरार्की डेटा संरचनाओं के मॉडलिंग के लिए एक मूलभूत तकनीक है।
मुख्य विशेषताएं:
- एकल टेबल: संबंध पूरी तरह से एक ही टेबल संरचना के भीतर मौजूद होता है।
- माता-पिता-बच्चा संबंध: एक पंक्ति माता-पिता के रूप में कार्य करती है, जबकि दूसरी पंक्ति बच्चे के रूप में कार्य करती है।
- नल हैंडलिंग: जैरार्की के रूट में आमतौर पर विदेशी कुंजी कॉलम में नल मान होता है।
- चक्रीय तर्क: डेटा प्राप्त करते समय अनंत लूप से बचने के लिए सावधानी बरतने की आवश्यकता होती है।
🏗️ रिकर्सिव संबंधों के मुख्य घटक
इस संबंध को प्रभावी ढंग से लागू करने के लिए विशिष्ट डेटाबेस घटकों को समन्वयित करना आवश्यक है। स्कीमा डिजाइन प्राथमिक कुंजी और विदेशी कुंजी के बीच बातचीत पर बहुत अधिक निर्भर करता है।
🔑 प्राथमिक कुंजी
टेबल की प्रत्येक पंक्ति को एक अद्वितीय पहचानकर्ता की आवश्यकता होती है। यह एक आधार बिंदु है। जब कोई पंक्ति दूसरी पंक्ति को संदर्भित करती है, तो वह माता-पिता पंक्ति के अद्वितीय पहचानकर्ता को संग्रहीत करके ऐसा करती है।
- इसे स्थिर होना चाहिए। प्राथमिक कुंजी बदलना एक जटिल संचालन है।
- त्वरित खोज प्रदर्शन के लिए इसकी इंडेक्सिंग की जानी चाहिए।
- आमतौर पर, यह एक स्वतः-बढ़ता पूर्णांक या UUID होता है।
🔗 विदेशी कुंजी
विदेशी कुंजी कॉलम प्राथमिक कुंजी के साथ एक ही टेबल में स्थित होता है। यह माता-पिता पंक्ति के प्राथमिक कुंजी के मान को संग्रहीत करता है। यह कॉलम संबंध की दिशा को परिभाषित करता है।
- नल योग्य: जैरार्की में, शीर्ष स्तर की वस्तु (रूट) का कोई माता-पिता नहीं होता है। इसलिए, इस कॉलम में नल मान की अनुमति होनी चाहिए।
- प्रतिबंध: एक विदेशी कुंजी प्रतिबंध सुनिश्चित करता है कि संग्रहीत मान उसी टेबल में मौजूद एक मौजूदा प्राथमिक कुंजी से मेल खाता है।
- इंडेक्सिंग: हालांकि यह हमेशा अनिवार्य नहीं है, विदेशी कुंजी कॉलम को इंडेक्स करने से जैरार्की के माध्यम से जाने वाले प्रश्नों की गति में महत्वपूर्ण वृद्धि होती है।
📐 एक एंटिटी रिलेशनशिप डायग्राम में दृश्याकरण
एक स्व-संदर्भित एंटिटी का प्रतिनिधित्व करने के लिए एरडी बनाते समय, नोटेशन पहली नजर में भ्रमित कर सकता है। मानक एरडी टूल्स जोड़ाव को दर्शाने के लिए विशिष्ट रेखाओं का उपयोग करते हैं।
दृश्य नोटेशन नियम:
- एंटिटी बॉक्स एक बार बनाया जाता है।
- एक संबंध रेखा प्राथमिक कुंजी को उसी बॉक्स के बाहरी कुंजी से जोड़ती है।
- रेखा अक्सर एंटिटी में वापस लौटती है, जिससे दृश्य वृत्त बनता है।
- कार्डिनैलिटी संकेतक (1:1, 1:M) रेखा पर रखे जाते हैं ताकि यह दर्शाया जा सके कि एक माता-पिता के कितने बच्चे हो सकते हैं।
उदाहरण: संगठनात्मक संरचना
| अवधारणा | विवरण | एरडी नोटेशन |
|---|---|---|
| कर्मचारी | मॉडल की जा रही एंटिटी | लेबल वाला बॉक्स “कर्मचारी” |
| प्रबंधक | वह भूमिका जो उसी तालिका को संदर्भित करती है | प्रबंधक आईडी से कर्मचारी आईडी तक रेखा |
| रिपोर्टिंग लाइन | पुनरावर्ती संबंध | लूपिंग तीर |
| रूट नोड | सीईओ या शीर्ष स्तर का बॉस | प्रबंधक आईडी में नॉल मान |
🌳 पुनरावर्ती डेटा के लिए सामान्य उपयोग केस
पुनरावर्ती संबंध सिर्फ सैद्धांतिक नहीं हैं; वे डेटा मॉडलिंग में भावी समस्याओं को हल करते हैं। यहां उन स्थितियों की सूची है जहां इस पैटर्न का उपयोग किया जाता है।
1️⃣ संगठनात्मक पदानुक्रम
हर कंपनी की एक संरचना होती है। कर्मचारी प्रबंधकों को रिपोर्ट करते हैं, जो निदेशकों को रिपोर्ट करते हैं, जो वीपी को रिपोर्ट करते हैं। यह श्रृंखला एक पारंपरिक ट्री संरचना है।
- डेटा मॉडल: एक तालिका जिसका नाम “कर्मचारी” है।
- स्तंभ:
कर्मचारी_आईडी,नाम,प्रबंधक_आईडी. - तर्क: द
प्रबंधक_आईडीकॉलम संदर्भित करता हैकर्मचारी_आईडी. - लाभ: एक नए कर्मचारी को जोड़ने के लिए केवल एक पंक्ति डालने की आवश्यकता होती है। प्रत्येक विभाग के लिए नई टेबल बनाने की आवश्यकता नहीं है।
2️⃣ श्रेणी वृक्ष
ई-कॉमर्स प्लेटफॉर्म अक्सर उत्पादों को नेस्टेड श्रेणियों में व्यवस्थित करते हैं। इलेक्ट्रॉनिक्स > कंप्यूटर > लैपटॉप।
- डेटा मॉडल: एक टेबल जिसका नाम “श्रेणियाँ” है।
- कॉलम:
श्रेणी_आईडी,नाम,माता_आईडी. - तर्क: एक श्रेणी का माता हो सकता है, या यह एक रूट श्रेणी हो सकती है (माता_आईडी खाली है)।
- लाभ: स्कीमा बदले बिना जितनी भी उपश्रेणियाँ चाहे उतनी जोड़ने की लचीलापन।
3️⃣ सामग्री का बिल (BOM)
निर्माण के लिए अक्सर जटिल भागों की सूची की आवश्यकता होती है। एक कार इंजनों से बनती है, जिन्हें पिस्टन से बनाया जाता है। कभी-कभी एक पिस्टन एक अलग इंजन प्रकार का हिस्सा होता है।
- डेटा मॉडल: एक तालिका जिसका नाम “भाग” है।
- स्तंभ:
भाग_आईडी,विवरण,संयोजन_आईडी. - तर्क: एक भाग स्वयं एक संयोजन हो सकता है, जिसमें अन्य भाग होते हैं।
- लाभ: बहु-स्तरीय निर्माण संरचनाओं की अनुमति देता है।
4️⃣ टिप्पणी धाराएँ
फोरम और ब्लॉग उपयोगकर्ताओं को टिप्पणियों के उत्तर देने की अनुमति देते हैं। एक टिप्पणी के एक मूल टिप्पणी हो सकती है जिसके उत्तर दिए जा रहे हैं, या यह एक स्वतंत्र टिप्पणी हो सकती है।
- डेटा मॉडल: एक तालिका जिसका नाम “टिप्पणियाँ” है।
- स्तंभ:
टिप्पणी_आईडी,उपयोगकर्ता_आईडी,सामग्री,मूल_टिप्पणी_आईडी. - तर्क: एक उत्तर मूल टिप्पणी आईडी के लिंक करता है।
- लाभ: चर्चाओं के अनंत नेस्टिंग का समर्थन करता है।
⚙️ कार्यान्वयन पर विचार
स्कीमा डिज़ाइन करना केवल पहला चरण है। विभिन्न परिस्थितियों में डेटा के सही तरीके से व्यवहार करने की गारंटी देने के लिए सावधानीपूर्वक योजना बनाने की आवश्यकता होती है।
🛑 चक्रीय संदर्भों को रोकना
रिकर्सिव संबंधों में एक महत्वपूर्ण जोखिम चक्कर बनाने का है। उदाहरण के लिए, कर्मचारी A कर्मचारी B के अधीन है, और कर्मचारी B कर्मचारी A के अधीन है। इससे अनंत लूप बनता है।
- एप्लिकेशन तर्क: जब डेटा में निर्माण या अपडेट कर रहे हों, तो एप्लिकेशन को जरूरत से अधिक गहराई वाले विभाजन की जांच करनी चाहिए ताकि कोई चक्कर न बने।
- डेटाबेस सीमाएँ: जबकि मानक SQL सीमाएँ आसानी से चक्करों को रोक नहीं सकतीं (क्योंकि वे वर्तमान स्थिति की जांच करती हैं, न कि परिणामी स्थिति की), कुछ प्रणालियों में लेखन से पहले मार्ग की पुष्टि करने के लिए ट्रिगर का उपयोग किया जा सकता है।
- रूट पहचान: सुनिश्चित करें कि प्रत्येक वैध वृक्ष में बिल्कुल एक मूल नोड हो (जहां विदेशी कुंजी खाली हो)।
📉 खाली मानों का प्रबंधन
हिरार्की का मूल बिंदु शुरुआती बिंदु है। एक मानक रिकर्सिव संबंध में, मूल पंक्ति में विदेशी कुंजी कॉलम में खाली मान होता है।
- प्रश्न पूछना: सभी मूल नोड्स खोजने के लिए, उन पंक्तियों के लिए प्रश्न पूछें जहां विदेशी कुंजी NULL है।
- डिफ़ॉल्ट मान: यदि यह माता-पिता को इंगित करता है, तो विदेशी कुंजी के लिए डिफ़ॉल्ट मान सेट न करें। 0 या -1 का डिफ़ॉल्ट मान भ्रमित कर सकता है और डेटा अखंडता के मुद्दे पैदा कर सकता है।
- अखंडता: सुनिश्चित करें कि डेटाबेस इंजन विदेशी कुंजी कॉलम के लिए NULL की अनुमति देता है। NOT NULL सीमा वृक्ष मॉडल को तोड़ देगी।
📈 प्रदर्शन और सूचीकरण
जैसे-जैसे डेटा बढ़ता है, रिकर्सिव संरचनाओं को प्रश्न पूछना धीमा हो सकता है। किसी विशिष्ट नोड के सभी वंशजों को खोजने के लिए एक सरल प्रश्न में बहुत सारे जॉइन या रिकर्सिव प्रश्नों की आवश्यकता हो सकती है।
अनुकूलन रणनीतियाँ:
- विदेशी कुंजियों की सूची बनाएँ: माता-पिता के संदर्भ को धारण करने वाले कॉलम पर एक सूची बनाएँ। इससे बच्चों को खोजने में तेजी आती है।
- सामग्रीकृत मार्ग: कुछ प्रणालियाँ हिरार्की के पूर्ण मार्ग को अलग कॉलम में संग्रहीत करती हैं (उदाहरण के लिए, “/1/5/12/20”)। इससे तेजी से स्ट्रिंग-आधारित फ़िल्टरिंग संभव होती है, हालांकि इसके लिए हर इन्सर्ट के बाद अपडेट करने की आवश्यकता होती है।
- नेस्टेड सेट्स: गहराई का प्रतिनिधित्व करने के लिए बाएं और दाएं संख्याओं का उपयोग करने वाला एक विकल्प एल्गोरिदम। यह प्राप्त करने के लिए तेज है, लेकिन इन्सर्ट करने के लिए धीमा है।
- प्रश्न की गहराई: अपने प्रश्नों में रिकर्सन की गहराई को सीमित करें। यदि सीमा न लगाई जाए, तो अनंत लूप डेटाबेस इंजन को क्रैश कर सकते हैं।
🔍 पुनरावृत्ति डेटा का प्रश्न
हायरार्किकल डेटा को प्राप्त करना फ्लैट डेटा को प्राप्त करने से अधिक जटिल है। सामान्य JOINs एक स्तर के लिए काम करते हैं, लेकिन बहुस्तरीय डेटा के लिए विशेष तर्क की आवश्यकता होती है।
🔄 सेल्फ-जॉइन
सबसे आम तरीका तालिका को खुद से जोड़ने में शामिल है। आप तालिका को एक बार पिता के रूप में और एक बार बच्चे के रूप में एलियास करते हैं।
- एक स्तर:तालिका को खुद से एक बार जोड़ें ताकि तुरंत पिता प्राप्त हो सके।
- बहुस्तरीय:बहुस्तरीय जॉइन की आवश्यकता होती है, जो जल्दी ही अव्यवस्थित हो जाती है।
- नुकसान: आवश्यक जॉइन की संख्या हायरार्की की गहराई के बराबर होती है।
🔁 पुनरावृत्ति सामान्य तालिका अभिव्यक्तियाँ (CTEs)
आधुनिक डेटाबेस इंजन पुनरावृत्ति CTEs का समर्थन करते हैं। इससे एक प्रश्न को खुद पर UNION ALL चलाने की अनुमति मिलती है जब तक कि कोई अधिक पंक्तियाँ नहीं मिलती हैं।
- एंकर सदस्य: पुनरावृत्ति का आरंभ बिंदु (आमतौर पर रूट नोड)।
- पुनरावृत्ति सदस्य: प्रश्न का वह हिस्सा जो परिणाम को तालिका में वापस जोड़ता है ताकि अगला स्तर प्राप्त किया जा सके।
- समाप्ति: प्रश्न तब रुक जाता है जब कोई अधिक मेल वाली पंक्तियाँ नहीं मिलती हैं।
- लाभ: किसी भी गहराई की हायरार्की को जाने बिना संभालता है।
🛡️ डेटा अखंडता और सीमाएँ
सेल्फ-रेफरेंसिंग तालिका की अखंडता बनाए रखना महत्वपूर्ण है। यदि कोई पिता हटा दिया जाता है, तो बच्चों के साथ क्या होता है?
🗑️ डिलीट कैस्केडिंग
जब कोई पिता पंक्ति हटा दी जाती है, तो डेटाबेस को निर्णय लेना होता है कि बच्चों की पंक्तियों को कैसे संभाला जाए।
- RESTRICT: यदि बच्चे मौजूद हैं तो पिता के हटाने को रोकता है। यह डेटा को सुरक्षित रखता है लेकिन आवश्यक सफाई को रोक सकता है।
- CASCADE: जब पिता को हटाया जाता है तो सभी बच्चों की पंक्तियाँ हटा दी जाती हैं। गहरी हायरार्की में यह खतरनाक है क्योंकि यह डेटा के बड़े हिस्से को गलती से मिटा सकता है।
- SET NULL: बच्चों के विदेशी कुंजी को NULL कर देता है, जिससे वे नए रूट नोड बन जाते हैं। डेटा संरचना को बनाए रखने के लिए यह आमतौर पर सबसे सुरक्षित विकल्प होता है।
- डिफ़ॉल्ट सेट करें: विदेशी कुंजी को डिफ़ॉल्ट मान (उदाहरण के लिए, एक विशिष्ट अनाथ श्रेणी) पर सेट करता है।
🔒 अपडेट सीमाएँ
एक माता रोड के मुख्य कुंजी को बदलना जोखिम भरा है। यदि आप प्रबंधक के ID को बदलते हैं, तो आपको उनके रेफ़रेंस करने वाले प्रत्येक कर्मचारी रिकॉर्ड में उस ID को अपडेट करना होगा।
- एप्लिकेशन लेयर: सभी संदर्भों को एक साथ अपडेट करने की गारंटी के लिए अपडेट को लेनदेन के रूप में संभालें।
- डेटाबेस ट्रिगर्स: ID बदलाव के प्रसार को स्वचालित कर सकते हैं, हालांकि इससे जटिलता बढ़ जाती है।
- सर्वोत्तम प्रथा: जब भी संभव हो, रिकर्सिव संरचनाओं में मुख्य कुंजी के अपडेट को बचें। प्राकृतिक कुंजियों (जैसे कर्मचारी कोड) के बजाय सुरोगेट कुंजियों (स्वतः बढ़ते पूर्णांक) का उपयोग करें।
🚧 सामान्य समस्याओं का निवारण
सावधानी से डिज़ाइन करने के बावजूद, विकास और रखरखाव के दौरान समस्याएँ उत्पन्न हो सकती हैं।
❓ मैं पेड़ की गहराई कैसे ज्ञात करूँ?
किसी विशिष्ट पंक्ति के स्तर को निर्धारित करने के लिए, आपको पंक्ति से रूट तक ऊपर जाना होगा। छलांगों की संख्या गिनें।
- क्वेरी दृष्टिकोण: ऊपर जाते समय पंक्तियों को गिनने वाली एक पुनरावर्ती क्वेरी का उपयोग करें।
- एप्लिकेशन दृष्टिकोण: सम्मिलन के दौरान गहराई को एक कॉलम में स्टोर करें। इससे क्वेरी समय बचता है, लेकिन रखरखाव की आवश्यकता होती है।
❓ मैं अनाथ नोड्स को कैसे संभालूँ?
अनाथ नोड्स वे पंक्तियाँ हैं जहाँ विदेशी कुंजी किसी अस्तित्वहीन माता पर इशारा करती है। यह आमतौर पर बग या हाथ से डेटा दर्ज करने की गलती के कारण होता है।
- सत्यापन: ऐसी पंक्तियों को खोजने के लिए नियमित रूप से अखंडता जांच चलाएं जहाँ विदेशी कुंजी किसी भी मुख्य कुंजी से मेल नहीं खाती है।
- पुनर्स्थापना: एक नीति तय करें: उन्हें रूट श्रेणी में ले जाएँ, उन्हें हटा दें, या उन्हें समीक्षा के लिए चिह्नित करें।
❓ समय के साथ प्रदर्शन में गिरावट
जैसे पेड़ बढ़ता है, पूरे पेड़ को स्कैन करने वाली क्वेरी धीमी हो जाती हैं।
- कैशिंग: एप्लिकेशन मेमोरी में अक्सर एक्सेस किए जाने वाले हियरार्की संरचनाओं को कैश करें।
- आर्काइविंग: हियरार्की के ऐतिहासिक या निष्क्रिय हिस्सों को आर्काइव टेबल में स्थानांतरित करें।
- विभाजन: यदि डेटा विशाल है, तो तालिका को मूल श्रेणी द्वारा विभाजित करें।
📝 बेस्ट प्रैक्टिसेज का सारांश
स्व-संदर्भित एंटिटी के एक विश्वसनीय अनुप्रयोग सुनिश्चित करने के लिए, इन दिशानिर्देशों का पालन करें।
- सरोगेट की का उपयोग करें:प्राथमिक कुंजी के लिए व्यापारिक कुंजियों की तुलना में स्वतः बढ़ते पूर्णांक को प्राथमिकता दें।
- NULL की अनुमति दें: सुनिश्चित करें कि विदेशी कुंजी कॉलम मूल नोड्स के लिए NULL मानों की अनुमति देता है।
- विदेशी कुंजियों पर इंडेक्स बनाएं: हमेशा उस कॉलम पर इंडेक्स बनाएं जो माता-पिता संदर्भ रखता है।
- चक्रों की पुष्टि करें: चक्रीय संदर्भों (A -> B -> A) को रोकने के लिए जांच कार्यान्वित करें।
- पुनरावृत्ति की सीमा निर्धारित करें: स्टैक ओवरफ्लो को रोकने के लिए प्रश्नों में पुनरावृत्ति की गहराई को सीमित करें।
- स्कीमा का दस्तावेजीकरण करें: अपने ईआरडी दस्तावेजीकरण में स्पष्ट रूप से उन कॉलम्स को चिह्नित करें जो स्व-संदर्भित हैं।
- हटाने के लिए योजना बनाएं: माता-पिता के हटाए जाने पर कैस्केडिंग हटाने या NULL सेट करने के लिए स्पष्ट नियम निर्धारित करें।
- गहन हायरार्की का परीक्षण करें: प्रदर्शन को बनाए रखने के लिए अपने प्रश्नों का परीक्षण कम से कम 10 स्तरों की गहराई के साथ करें।
🔮 भविष्य के विचार
डेटाबेस तकनीक लगातार विकसित हो रही है। जबकि स्व-संदर्भित एंटिटी की अवधारणा स्थिर रहती है, इसके प्रबंधन के उपकरणों में सुधार हो रहा है।
- ग्राफ डेटाबेस: कुछ आधुनिक प्रणालियाँ संबंधों को प्रथम श्रेणी के नागरिकों के रूप में मानती हैं। वे SQL की जटिलता के बिना निर्मित रूप से पुनरावृत्ति रास्तों का प्रबंधन करती हैं।
- JSON समर्थन: नए डेटाबेस इंजन JSON कॉलम में हायरार्किकल डेटा संग्रहीत करने की अनुमति देते हैं, जो गहराई से नेस्टेड संरचनाओं के लिए स्कीमा डिजाइन को सरल बना सकते हैं।
- ORM में सुधार: ऑब्जेक्ट-रिलेशनल मैपर्स पुनरावृत्ति संबंधों को स्वचालित रूप से संभालने में बेहतर हो रहे हैं, जिससे बॉलरप्लेट कोड कम हो रहा है।
इन उन्नतियों के बावजूद, पुनरावृत्ति संबंध की मूल तर्कविज्ञान वही रहता है। डेटा संरचनाओं के साथ काम करने वाले किसी भी तकनीकी पेशेवर के लिए प्राथमिक कुंजियों, विदेशी कुंजियों और तालिका संबंधों के आधारभूत तकनीकी तत्वों को समझना आवश्यक है।
इन सिद्धांतों का पालन करके आप ऐसे प्रणालियाँ बना सकते हैं जो जटिल हायरार्की को संभालने के लिए पर्याप्त लचीली होंगी, जबकि प्रदर्शन और रखरखाव में बनी रहेंगी। स्व-संदर्भित एंटिटी आपके डेटा मॉडलिंग आर्सेनल में एक शक्तिशाली उपकरण है, बशर्ते इसका निपुणता और सावधानी से उपयोग किया जाए।