










डेटाबेस डिज़ाइन किसी भी विश्वसनीय सॉफ्टवेयर एप्लिकेशन की रीढ़ है। जब आप जटिल डेटा को हैंडल करने वाले सिस्टम का निर्माण करते हैं, तो एक स्केलेबल आर्किटेक्चर और एक नाजुक बिखरे हुए बिंदु के बीच अंतर अक्सर आपके जानकारी के संरचना के तरीके पर निर्भर करता है। इस संरचना के केंद्र में तीन मूलभूत स्तंभ हैं: प्रतिनिधित्व, गुण और संबंध। इन अवधारणाओं को समझना डेवलपर के लिए वैकल्पिक नहीं है; यह रखरखाव योग्य, कुशल और तार्किक डेटा मॉडल बनाने के लिए आवश्यक है।
एक प्रतिनिधित्व संबंध आरेख (ERD) इन संरचनाओं के लिए ब्लूप्रिंट के रूप में कार्य करता है। यह डेटा कैसे जुड़ता है, कैसे संग्रहीत किया जाता है और आपके सिस्टम में कैसे प्रवाहित होता है, इसका दृश्यीकरण करता है। इन मूल घटकों को स्पष्ट रूप से समझे बिना, यहां तक कि सबसे उन्नत एप्लिकेशन लॉजिक भी प्रदर्शन में कठिनाई महसूस करेगा। यह गाइड प्रत्येक तत्व को सटीकता के साथ तोड़ता है, ताकि आप आत्मविश्वास और स्पष्टता के साथ डेटा मॉडल डिज़ाइन कर सकें।
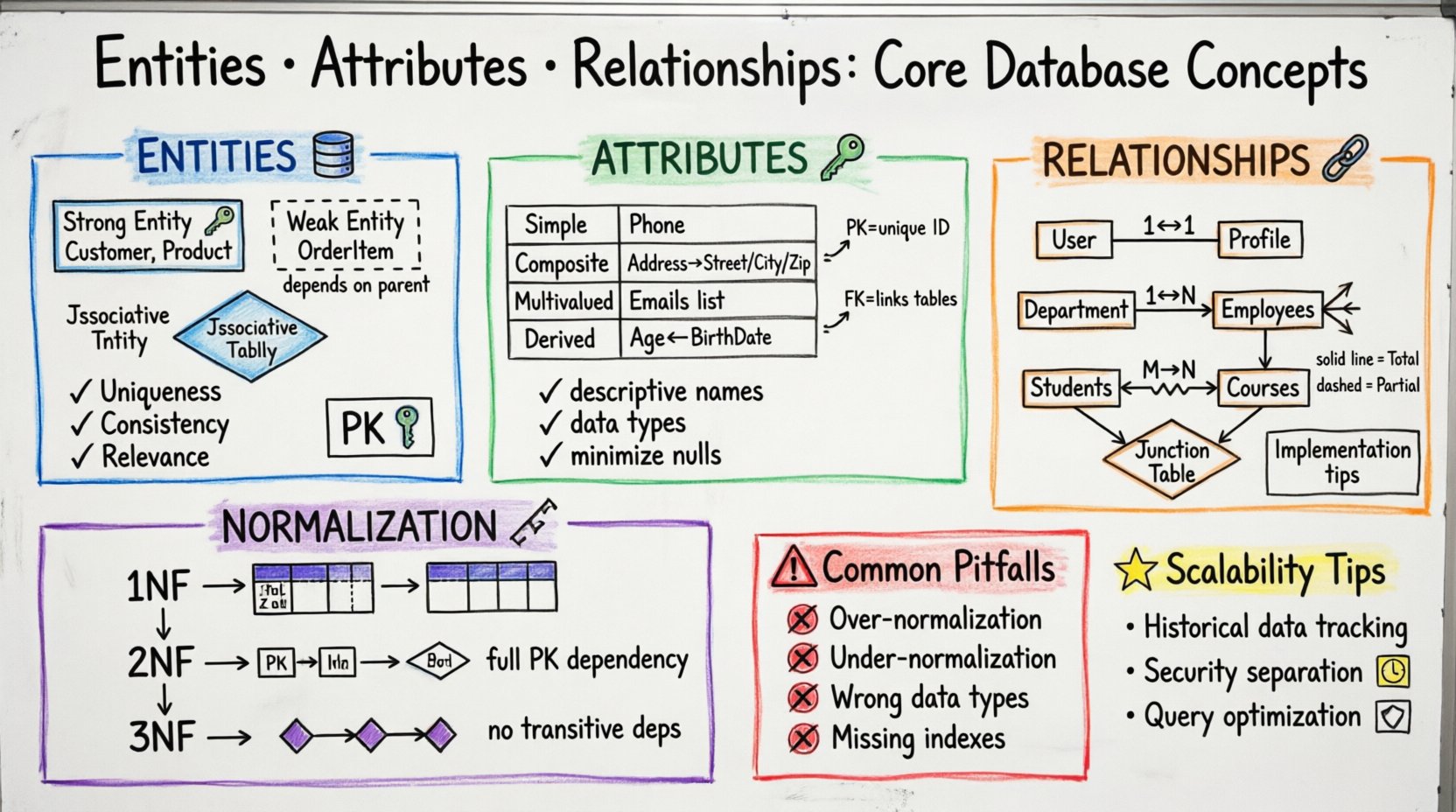
प्रतिनिधित्व को समझना: डेटा की नींव 🧱
डेटाबेस डिज़ाइन के संदर्भ में, एक प्रतिनिधित्व एक विशिष्ट वस्तु या अवधारणा का प्रतिनिधित्व करता है जिसके बारे में आपको जानकारी संग्रहीत करने की आवश्यकता होती है। यह आपके डेटा मॉडल में एक संज्ञा है। इसे वास्तविक दुनिया या आपके व्यवसाय क्षेत्र में मौजूद चीजों की एक श्रेणी या वर्ग के रूप में सोचें। प्रत्येक प्रतिनिधित्व को सिस्टम के संदर्भ में अद्वितीय और पहचानने योग्य होना चाहिए।
प्रतिनिधित्व के प्रकार
प्रतिनिधित्व सभी एक जैसे नहीं बनाए जाते हैं। आपके सामने आने वाले प्रतिनिधित्व के प्रकार को पहचानना डेटा के संग्रह और प्राप्त करने के नियमों को परिभाषित करने में मदद करता है।
- मजबूत प्रतिनिधित्व: ये स्वतंत्र रूप से मौजूद होते हैं। उनके अपने प्राथमिक कुंजी होती है और उनके अस्तित्व के लिए अन्य प्रतिनिधित्वों पर निर्भर नहीं होते हैं। उदाहरण के लिए, एक ग्राहक या एक उत्पाद अपने आप में मौजूद हो सकते हैं।
- दुर्बल प्रतिनिधित्व: इनका अस्तित्व मजबूत प्रतिनिधित्व पर निर्भर होता है। उन्हें मातृ प्रतिनिधित्व के बिना अद्वितीय रूप से पहचाना नहीं जा सकता है। एक प्रमुख उदाहरण है एक आदेश आइटम एक आदेश। आदेश के संदर्भ के बिना, इस विशिष्ट स्कीमा में आइटम का कोई अर्थ नहीं है।
- संबंधात्मक प्रतिनिधित्व: जंक्शन टेबल के रूप में भी जाने जाते हैं, ये बहु-से-बहु संबंधों को हल करते हैं। वे दो अन्य प्रतिनिधित्वों के बीच सेतु बनाते हैं ताकि उनके बीच बहुगुणा संबंध संभव हो।
प्रतिनिधित्व की पहचान करना
जब आप एक मॉडल डिज़ाइन कर रहे हों, तो आपको खुद से पूछना चाहिए कि कौन सी वास्तविक दुनिया की वस्तुओं को ट्रैक करने की आवश्यकता है। अपने व्यवसाय आवश्यकताओं में संज्ञाओं को ढूंढें। यदि एक व्यवसाय नियम निर्धारित करता है कि आपको किसी चीज़ के स्थिति, इतिहास या गुणों को ट्रैक करने की आवश्यकता है, तो वह चीज़ एक प्रतिनिधित्व होने की संभावना है।
निम्नलिखित विशेषताओं को ध्यान में रखें जो एक वैध प्रतिनिधित्व को परिभाषित करती हैं:
- अद्वितीयता: प्रत्येक उदाहरण को प्रत्येक अन्य उदाहरण से अलग किया जा सकना चाहिए।
- स्थिरता: प्रतिनिधित्व की परिभाषा को पूरे सिस्टम में स्थिर रहना चाहिए।
- प्रासंगिकता: प्रतिनिधित्व को व्यवसाय तर्क में कोई उद्देश्य प्रदान करना चाहिए। उन डेटा के लिए प्रतिनिधित्व बनाने से बचें जिनका दुर्लभ रूप से प्रश्न पूछा जाता है या उपयोग किया जाता है।
विशेषताएँ: प्राणी गुणों को परिभाषित करना 🔑
जब आप प्राणियों को पहचान लेते हैं, तो उनका वर्णन करने की आवश्यकता होती है। विशेषताएँ एक प्राणी को वर्णित करने वाली विशेषताएँ, गुण या विवरण हैं। यदि एक प्राणी एक तालिका है, तो एक विशेषता एक स्तंभ है। एक साथ, वे आपके द्वारा प्रबंधित डेटा की पूरी तस्वीर बनाते हैं।
प्राथमिक कुंजियाँ और विदेशी कुंजियाँ
सभी विशेषताएँ समान नहीं होती हैं। कुछ डेटा की अखंडता और जोड़ने में एक महत्वपूर्ण भूमिका निभाती हैं।
- प्राथमिक कुंजी (PK): एक प्राणी के भीतर एक रिकॉर्ड के लिए एक अद्वितीय पहचानकर्ता। यह सुनिश्चित करता है कि कोई भी दो पंक्तियाँ समान नहीं हैं। एक प्राथमिक कुंजी एकल स्तंभ (जैसे आईडी नंबर) या बहुत से स्तंभों से बनी मिश्रित कुंजी हो सकती है।
- विदेशी कुंजी (FK): एक विशेषता जो दूसरे प्राणी की प्राथमिक कुंजी से जुड़ती है। इससे तालिकाओं के बीच संबंध स्थापित होता है। यह संदर्भात्मक अखंडता को बल देता है, जिससे सुनिश्चित होता है कि एक तालिका में एक रिकॉर्ड दूसरी तालिका में अस्तित्वहीन रिकॉर्ड को संदर्भित नहीं कर सकता।
विशेषता वर्गीकरण
विशेषताएँ उनके भंडारण और निर्माण के तरीके में भिन्न होती हैं। इन अंतरों को समझना भंडारण और प्रश्न प्रदर्शन को अनुकूलित करने में मदद करता है।
| प्रकार | विवरण | उदाहरण |
|---|---|---|
| सरल | आगे विभाजित नहीं किया जा सकता। यह परमाणु है। | फ़ोन नंबर |
| मिश्रित | उप-भागों में विभाजित किया जा सकता है। | पता (सड़क, शहर, ज़िप) |
| बहुमूल्य | एकल प्राणी उदाहरण के लिए कई मान धारण कर सकता है। | ईमेल पते |
| व्युत्पन्न | अन्य विशेषताओं से गणना की गई। | आयु (जन्म तिथि से व्युत्पन्न) |
विशेषताओं के लिए सर्वोत्तम प्रथाएँ
जब आप विशेषताओं को परिभाषित करते हैं, तो डेटा गुणवत्ता सुनिश्चित करने के लिए निम्नलिखित दिशानिर्देशों को ध्यान में रखें:
- वर्णनात्मक नामों का उपयोग करें: सामान्य नामों जैसे
col1याडेटा. सामग्री को समझाने वाले नामों का उपयोग करें, जैसे किग्राहक ईमेलयाआदेश तिथि. - डेटा प्रकार परिभाषित करें: सटीक रहें। गिनती के लिए पूर्णांक का उपयोग करें, समय संबंधी डेटा के लिए तारीखें, और पाठ के लिए स्ट्रिंग। इससे डेटा दर्ज करने और प्राप्त करने के दौरान त्रुटियों से बचा जा सकता है।
- नल मानों को कम करें: जहां संभव हो, प्रतिबंधों को लागू करें ताकि विशेषताओं को खाली न छोड़ा जाए। नल मान प्रश्नों को जटिल बना सकते हैं और अप्रत्याशित परिणामों की ओर जाते हैं।
- डेटा को सामान्यीकृत करें: सुनिश्चित करें कि विशेषताएं केवल मुख्य कुंजी पर निर्भर करें। उस डेटा को संग्रहीत करने से बचें जो निर्यात किया जा सकता है या दूसरे एकांकी में स्थानांतरित किया जा सकता है।
संबंध: बिंदुओं को जोड़ना 🔗
एकांकी अक्सर अलगाव में नहीं होते। संबंध यह निर्धारित करते हैं कि एकांकी एक-दूसरे के साथ कैसे बातचीत करते हैं। वे यह निर्धारित करते हैं कि डेटा कैसे जुड़ा जाता है, प्रश्न कैसे जुड़ते हैं, और डेटाबेस के माध्यम से अखंडता कैसे बनाए रखी जाती है। अच्छी तरह से डिज़ाइन किए गए संबंध संरचना डेटा अतिरेक को रोकती है और यह सुनिश्चित करती है कि अपडेट सही तरीके से प्रसारित होते हैं।
कार्डिनैलिटी
कार्डिनैलिटी एकांकी के बीच संख्यात्मक संबंध को परिभाषित करती है। यह प्रश्न का उत्तर देती है: “एकांकी A के कितने उदाहरण एकांकी B के कितने उदाहरण से संबंधित हैं?”
- एक से एक (1:1): एकांकी A का एक उदाहरण एकांकी B के ठीक एक उदाहरण से संबंधित होता है। यह दुर्लभ है लेकिन उदाहरण के रूप में एक उपयोगकर्ता के एक प्रोफ़ाइल होने जैसे परिदृश्य में होता है।
- एक से बहुत (1:N): एकांकी A का एक उदाहरण एकांकी B के कई उदाहरणों से संबंधित होता है। उदाहरण के लिए, एक विभाग में बहुत सारे हैं कर्मचारी.
- बहुत से बहुत (M:N): एकांकी A के कई उदाहरण एकांकी B के कई उदाहरणों से संबंधित होते हैं। उदाहरण के लिए, एक छात्र बहुत से में दाखिला ले सकता है पाठ्यक्रम, और एक पाठ्यक्रम में कई हो सकते हैं छात्र.
भागीदारी प्रतिबंध
कार्डिनैलिटी आपको मात्रा बताती है, लेकिन भागीदारी प्रतिबंध आपको बताते हैं कि संबंध अनिवार्य है या नहीं।
- पूर्ण भागीदारी: किसी भी एकता का प्रत्येक उदाहरण संबंध में भाग लेना चाहिए। उदाहरण के लिए, प्रत्येक आदेश के पास एक होना चाहिए ग्राहक.
- आंशिक भागीदारी: एक उदाहरण संबंध में भाग ले सकता है या नहीं भी ले सकता है। उदाहरण के लिए, एक ग्राहक के पास एक हो सकता है या नहीं भी हो सकता है आदेश एक निर्धारित समय पर।
कार्यान्वयन रणनीतियाँ
विभिन्न कार्डिनैलिटी के डेटा मॉडल के भीतर विभिन्न कार्यान्वयन रणनीतियों की आवश्यकता होती है।
| संबंध प्रकार | कार्यान्वयन विधि | उदाहरण परिदृश्य |
|---|---|---|
| 1:1 | तालिकाओं को मिलाएँ या एक तरफ एफके जोड़ें। | उपयोगकर्ता प्रोफ़ाइल उपयोगकर्ता खाते से जुड़ी है। |
| 1:एन | बहुत सारे पक्ष की तालिका में एफके जोड़ें। | कर्मचारी तालिका में एक विभाग_आईडी है। |
| एम:एन | दो एफके के साथ एक जंक्शन टेबल बनाएं। | छात्रों और कोर्सेज़ को जोड़ने वाली एनरोलमेंट टेबल। |
नॉर्मलाइज़ेशन: स्थिरता के लिए संरचना 📐
जबकि एंटिटीज़, एट्रिब्यूट्स और संबंध संरचना बनाते हैं, नॉर्मलाइज़ेशन उस संरचना को दोहराव को कम करने और अखंडता को बेहतर बनाने के लिए व्यवस्थित करता है। नॉर्मलाइज़ेशन एक चरणों की श्रृंखला है जिसका उद्देश्य यह सुनिश्चित करना है कि डेटा निर्भरता समझ में आए।
पहला सामान्य रूप (1NF)
1NF में, प्रत्येक कॉलम में परमाणु मान होने चाहिए। आप एक ही सेल में मानों की सूची स्टोर नहीं कर सकते। प्रत्येक पंक्ति अद्वितीय होनी चाहिए, जिसे आमतौर पर प्राथमिक कुंजी द्वारा बल दिया जाता है। इससे दोहराए गए समूहों को खत्म कर दिया जाता है।
दूसरा सामान्य रूप (2NF)
जब 1NF प्राप्त हो जाता है, तो 2NF सुनिश्चित करता है कि सभी गैर-कुंजी विशेषताएं प्राथमिक कुंजी पर पूरी तरह निर्भर हों। यदि आपके पास एक संयुक्त कुंजी है, तो प्रत्येक विशेषता पूरी कुंजी पर निर्भर होनी चाहिए, केवल इसके कुछ हिस्से पर नहीं।
तीसरा सामान्य रूप (3NF)
3NF से अनुक्रमिक निर्भरताएं हटा दी जाती हैं। गैर-कुंजी विशेषताओं को अन्य गैर-कुंजी विशेषताओं पर निर्भर नहीं होना चाहिए। उदाहरण के लिए, यदि शहर पर निर्भर है पिन कोड पर निर्भर है पिन कोड पर निर्भर है ग्राहक आईडी तो शहर पर निर्भर है ग्राहक आईडी अनुक्रमिक रूप से। इसे ठीक करने के लिए, शहर अलग एक एंटिटी में ले जाएं या सुनिश्चित करें कि यह कुंजी से सीधे जुड़ा हो।
डिज़ाइन में सामान्य गलतियां ⚠️
यहां तक कि अनुभवी डेवलपर्स भी डेटा मॉडल डिज़ाइन करते समय गलतियां करते हैं। सामान्य गलतियों के बारे में जागरूक रहने से विकास चरण में महत्वपूर्ण समय बचाया जा सकता है।
- अत्यधिक नॉर्मलाइज़ेशन:डेटा को बहुत अधिक छोटी एंटिटीज़ में बांटने से क्वेरीज़ को जटिल और धीमा बना सकता है। कभी-कभी, पढ़ने वाले कार्यभार के लिए अनॉर्मलाइज़ेशन स्वीकार्य होता है।
- अपर्याप्त नॉर्मलाइज़ेशन: एक ही डेटा को कई स्थानों पर स्टोर करने से असंगति आती है। यदि एक ग्राहक का पता बदलता है, तो आपको हर रिकॉर्ड में इसे अपडेट करना होगा। इससे त्रुटियों का जोखिम बढ़ जाता है।
- डेटा प्रकारों के बारे में बेफिक्री: संख्याओं या तारीखों के लिए स्ट्रिंग्स का उपयोग करने से सॉर्टिंग समस्याएं और सत्यापन त्रुटियां होती हैं। हमेशा एट्रिब्यूट प्रकार को वास्तविक डेटा के अनुरूप रखें।
- हार्डकोडेड मान: यदि स्टेटस कोड का कोई विशिष्ट अर्थ है, तो उन्हें स्ट्रिंग के रूप में स्टोर करने से बचें। स्थिति या देश जैसे मानों के लिए रेफरेंस टेबल का उपयोग करके संगतता बनाए रखें।
- अनुपस्थित सूचकांक: विदेशी कुंजियां और अक्सर पूछे जाने वाले लक्षणों को सूचीबद्ध करना चाहिए ताकि खोज गति में सुधार हो। सूचकांक के बिना, जॉइन ऑपरेशन बॉटलनेक बन सकते हैं।
स्केलेबिलिटी के लिए उन्नत विचार 🚀
जैसे-जैसे एप्लिकेशन बढ़ते हैं, डेटा मॉडल को विकसित करना आवश्यक होता है। प्रारंभिक डिज़ाइन निर्णय यह निर्धारित करते हैं कि सिस्टम को कितनी आसानी से स्केल किया जा सकता है। यहां लंबे समय तक स्थिरता के लिए विचार दिए गए हैं।
ऐतिहासिक डेटा का प्रबंधन
व्यापार नियम समय के साथ बदलते हैं। वे लक्षण जो कभी अनिवार्य थे, वे अब वैकल्पिक हो सकते हैं। संबंध बदल सकते हैं। बार-बार स्कीमा बदलने के बजाय, इतिहास के लिए कॉलम जोड़ने या समय संबंधित टेबल का उपयोग करके बदलावों को ट्रैक करने के बारे में सोचें। इससे आप बिना वर्तमान कार्यक्षमता को नुकसान पहुंचाए बदलावों का ऑडिट कर सकते हैं।
सुरक्षा और पहुंच नियंत्रण
एंटिटीज अक्सर संवेदनशील जानकारी रखती हैं। अपने संबंधों को पहुंच नियंत्रण के समर्थन के लिए डिज़ाइन करें। उदाहरण के लिए, उपयोगकर्ता डेटा को लॉग्स डेटा से अलग करने से अनुमतियों के प्रबंधन में मदद मिलती है। सुनिश्चित करें कि विदेशी कुंजियां अनधिकृत उपयोगकर्ताओं को संवेदनशील डेटा न दिखाएं।
प्रश्न प्रदर्शन
आपके संबंधों के संरचना का प्रश्न प्रदर्शन पर सीधा प्रभाव पड़ता है। गहन रूप से नेस्टेड संबंधों के लिए बहुत सारे जॉइन की आवश्यकता होती है, जो डेटा प्राप्त करने की गति को धीमा कर सकते हैं। अपने सबसे अधिक आवृत्ति वाले प्रश्नों का विश्लेषण करें और अपनी एंटिटीज को इस तरह संरचित करें कि आवश्यक जॉइन की संख्या को न्यूनतम किया जा सके। कभी-कभी, विशिष्ट लक्षणों को रीड-अनुकूलित भंडार में डेनॉर्मलाइज़ करना सही चयन होता है।
निष्कर्ष 🏁
एंटिटीज, लक्षणों और संबंधों की मूल अवधारणाओं को समझना एक यात्रा है जो आपके करियर के दौरान जारी रहती है। इन तत्वों को केवल सैद्धांतिक रचनाएं नहीं माना जाना चाहिए; ये व्यावहारिक उपकरण हैं जिनका उपयोग आप लंबे समय तक चलने वाले प्रणालियों के निर्माण के लिए करते हैं। स्पष्टता, अखंडता और दक्षता पर ध्यान केंद्रित करके, आप ऐसे डेटा मॉडल बनाते हैं जो आपके एप्लिकेशन को वर्षों तक समर्थन देते हैं।
आधार से शुरुआत करें। अपनी एंटिटीज को स्पष्ट रूप से परिभाषित करें। उन्हें सटीक रूप से वर्णित करने वाले लक्षण निर्धारित करें। वास्तविक दुनिया के बातचीत को दर्शाने वाले संबंधों को मैप करें। जैसे आप इन डिज़ाइनों को बेहतर बनाते हैं, आप पाएंगे कि आपके एप्लिकेशन की तर्क अधिक स्पष्ट और अधिक विश्वसनीय हो जाती है। याद रखें कि एक अच्छा डिज़ाइन वह होता है जो समझने में आसान हो और बदलने में भी आसान हो। अपने विकास कार्य के दौरान इन सिद्धांतों को ध्यान में रखें।
सही ERD डिज़ाइन में समय निवेश करने से कम बग, तेज़ विकास चक्र और अधिक रखरखाव योग्य कोडबेस के लाभ मिलते हैं। चाहे आप एक छोटे उपयोगिता या बड़े पैमाने पर एंटरप्राइज सिस्टम का निर्माण कर रहे हों, एंटिटीज, लक्षणों और संबंधों के नियम एक जैसे रहते हैं। मूल सिद्धांतों पर टिके रहें, और आपकी डेटा आर्किटेक्चर समय के परीक्षण को सहन करेगी।