











एक डेटाबेस सिस्टम बनाना एक ऊंची इमारत के आधार को बनाने जैसा है। यदि ब्लूप्रिंट खराब है, तो संरचना दबाव के तहत अंततः फट जाएगी। एक एंटिटी रिलेशनशिप डायग्राम (ERD) वही ब्लूप्रिंट है। यह निर्धारित करता है कि डेटा अपने एप्लिकेशन के भीतर कैसे जुड़ता है, प्रवाहित होता है और कैसे स्थायी रहता है। जैसे-जैसे आपके उपयोगकर्ता आधार बढ़ता है और डेटा का आकार फूलता है, एक स्थिर डिजाइन अक्सर एक बॉटलनेक बन जाता है। लंबे समय तक चलने के लिए, आपको शुरुआत से ही स्केलेबल ERD डिजाइन सिद्धांतों को अपनाना होगा। यह गाइड ऐसे तकनीकी रणनीतियों का अध्ययन करता है जिनकी आवश्यकता ऐसे सिस्टम बनाने के लिए होती है जो टिके रहें।
डेटा मॉडलिंग के मूल सिद्धांतों को समझना 🧱
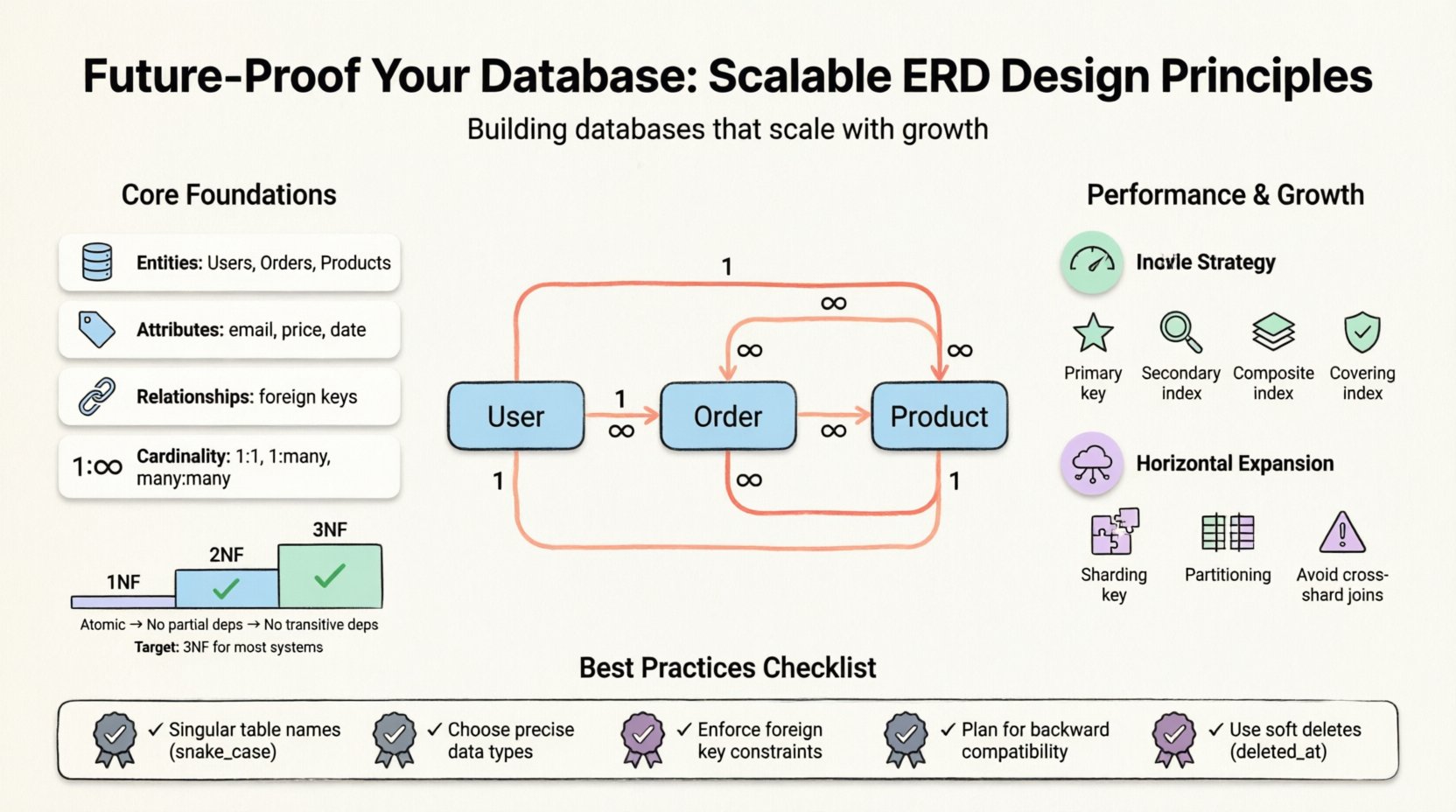
विशिष्ट रणनीतियों में उतरने से पहले, यह समझना आवश्यक है कि ERD क्या प्रतिनिधित्व करता है। यह डेटाबेस की तार्किक संरचना को दृश्यमान बनाता है। यह एंटिटीज (तालिकाएं), एट्रिब्यूट्स (कॉलम), और रिलेशनशिप (कीज) को मैप करता है। एक अच्छी तरह से बनाए गए मॉडल में डेटा अखंडता और प्रदर्शन के बीच संतुलन होता है। हालांकि, “सर्वोत्तम प्रथा” कार्यभार पर निर्भर करती है। एक रीड-हेवी एप्लिकेशन को लेखन-हेवी ट्रांजैक्शनल सिस्टम की तुलना में अलग अनुकूलन की आवश्यकता होती है।
मुख्य घटक शामिल हैं:
- एंटिटीज: मुख्य वस्तुएं, जैसे उपयोगकर्ता, आदेश या उत्पाद।
- एट्रिब्यूट्स: एक एंटिटी को परिभाषित करने वाले गुण, जैसे ईमेल पते या कीमतें।
- रिलेशनशिप: एंटिटीज कैसे बातचीत करती हैं, ज्यादातर विदेशी कीज द्वारा परिभाषित।
- कार्डिनैलिटी: एंटिटीज के बीच संख्यात्मक संबंध (एक-एक, एक-बहुत, बहुत-बहुत)।
नॉर्मलाइजेशन: अतिरेक और गति के बीच संतुलन ⚖️
नॉर्मलाइजेशन डेटा को व्यवस्थित करने की प्रक्रिया है जिससे अतिरेक को कम किया जाता है और अखंडता में सुधार होता है। जबकि इसे अक्सर एक कठोर नियम के रूप में लिया जाता है, यह एक व्यापार-बदलाव है। उच्च नॉर्मलाइजेशन विचलनों को कम करता है लेकिन जॉइन्स के माध्यम से क्वेरी की जटिलता बढ़ा सकता है। कम नॉर्मलाइजेशन (डेनॉर्मलाइजेशन) पढ़ने की गति बढ़ाता है लेकिन डेटा असंगति के जोखिम को बढ़ाता है।
नॉर्मलाइजेशन के स्तर
मानक रूपों को समझने से आपको यह तय करने में मदद मिलती है कि कहाँ रुकना है। प्रत्येक रूप विशिष्ट डेटा विचलनों को संबोधित करता है।
- पहला सामान्य रूप (1NF): परमाणुता सुनिश्चित करता है। प्रत्येक कॉलम में अविभाज्य मान होने चाहिए। एक ही सेल में दोहराए जाने वाले समूह या ऐरे नहीं होने चाहिए।
- दूसरा सामान्य रूप (2NF): 1NF पर आधारित है। सभी गैर-की विशेषताओं को पूर्ण मुख्य की पर निर्भर होना चाहिए, केवल इसके कुछ हिस्से पर नहीं। इससे आंशिक निर्भरता को दूर किया जाता है।
- तीसरा सामान्य रूप (3NF): 2NF पर आधारित है। गैर-की विशेषताओं को अन्य गैर-की विशेषताओं पर निर्भर नहीं होना चाहिए। इससे स्थानांतरित निर्भरता को हटाया जाता है।
- बॉयस-कॉड सामान्य रूप (BCNF): 3NF का कठोर रूप। यह उन मामलों को संभालता है जहां निर्धारक उम्मीदवार कीज नहीं हैं।
अधिकांश स्केलेबल सिस्टम के लिए, 3NF तक पहुंचना मानक लक्ष्य है। आगे बढ़ने पर अक्सर लाभ कम होता है जबकि रखरखाव के लिए अतिरिक्त लागत बढ़ती है। हालांकि, एनालिटिक्स-हेवी सिस्टम के लिए, डेनॉर्मलाइजेशन में नियंत्रित वापसी आम है।
नॉर्मलाइजेशन व्यापार-बदलाव तालिका
| नॉर्मलाइजेशन स्तर | प्राथमिक लाभ | प्राथमिक नुकसान |
|---|---|---|
| 1NF | परमाणु डेटा भंडारण | कोई नहीं |
| 2NF | आंशिक निर्भरता को समाप्त करता है | अधिक जॉइन की आवश्यकता होती है |
| 3NF | स्थानांतरित निर्भरता को समाप्त करता है | जॉइन की जटिलता में वृद्धि |
| अनियमित | तेजी से पढ़ने वाले प्रश्न | डेटा अतिरेक और अपडेट विचलन |
वृद्धि और लचीलापन के लिए स्कीमा डिजाइन 📈
वर्तमान के लिए डिजाइन करना पर्याप्त नहीं है। आपको भविष्य के स्कीमा विकास की अपेक्षा करनी चाहिए। जब व्यावसायिक तर्क में परिवर्तन आता है, तो कठोर संरचनाएं टूट जाती हैं। लचीला डिजाइन एक पूर्ण सिस्टम माइग्रेशन के बिना विस्तार की अनुमति देता है।
1. नामकरण प्रणाली और मानक
रखरखाव के लिए सुसंगतता बहुत महत्वपूर्ण है। अव्यवस्थित नामकरण प्रणाली भ्रम और त्रुटियों का कारण बनती है। टीम के पूरे विस्तार में एक मानक स्थापित करें और उसका कड़ाई से पालन करें।
- एकल नाम का उपयोग करें:तालिकाएं एकल एकता का प्रतिनिधित्व करनी चाहिए (उदाहरण के लिए,
उपयोगकर्ता, नहींउपयोगकर्ता). - सुसंगत विभाजक:तालिका नामों और कॉलम के लिए snake_case का उपयोग करें ताकि विभिन्न ऑपरेटिंग प्रणालियों और उपकरणों के बीच संगतता सुनिश्चित हो।
- विशिष्टता के लिए पूर्वपद:जैसे पूर्वपद का उपयोग करें
fk_विदेशी कुंजियों के लिए याidx_सूचकांकों के लिए उनके उद्देश्य को स्पष्ट करने के लिए। - आरक्षित शब्दों से बचें: कभी भी जैसे कीवर्ड्स का उपयोग न करें
क्रम,समूह, याचयन करेंकॉलम के नाम के रूप में।
2. डेटा प्रकार और शुद्धता
सही डेटा प्रकार का चयन स्टोरेज स्पेस और प्रश्न गति को प्रभावित करता है। अत्यधिक सामान्य प्रकार स्थान की बर्बादी करते हैं और प्रसंस्करण को धीमा कर देते हैं।
- पूर्णांक: उपयोग करें
टीनीएंटफ्लैग्स (0-1) या छोटी गिनती के लिए। उपयोग करेंबिगएंटकेवल तब जब आप विशाल पैमाने की उम्मीद करते हैं। - स्ट्रिंग्स: बचें
टेक्स्टछोटे मानों के लिए। उपयोग करेंवर्चारविशिष्ट लंबाई के साथ स्थान बचाने और इंडेक्सिंग की अनुमति देने के लिए। - तारीखें: उपयोग करें
टाइमस्टैम्पविशिष्ट क्षणों के लिए औरदिनांककेवल कैलेंडर तारीखों के लिए। हमेशा यूटीसी में स्टोर करें ताकि समय क्षेत्र की भ्रम में न पड़ें। - दशमलव: वित्तीय डेटा के लिए, दशमलव त्रुटियों से बचने के लिए फ्लोटिंग-पॉइंट संख्याओं के बजाय फिक्स्ड-पॉइंट दशमलव का उपयोग करें।
संबंध और कार्डिनैलिटी प्रबंधन 🔗
किसी एकता के अन्य एकताओं से संबंध निर्धारित करता है आपके डेटा की अखंडता। गलत प्रबंधन के कारण संबंध अनाथ रिकॉर्ड और डेटा हानि के कारण होते हैं।
1. विदेशी कुंजी प्रतिबंध
विदेशी कुंजियाँ संदर्भात्मक अखंडता को बनाए रखती हैं। वे सुनिश्चित करती हैं कि एक तालिका में कोई रिकॉर्ड दूसरी तालिका में अस्तित्वहीन रिकॉर्ड को संदर्भित नहीं कर सकता है। कुछ विकासकर्ता प्रदर्शन के लिए इन्हें अक्षम कर देते हैं, लेकिन आधुनिक डेटाबेस इंजन इन्हें कुशलतापूर्वक संभालते हैं। एप्लिकेशन स्तर के जांच पर निर्भर रहना त्रुटिपूर्ण होता है।
2. बहु-से-बहु संबंधों का प्रबंधन
एक बहु-से-बहु संबंध (उदाहरण के लिए, छात्र और कोर्स) को दो तालिकाओं में सीधे प्रतिनिधित्व नहीं किया जा सकता है। इसके लिए एक जंक्शन तालिका (संबंधात्मक एकता) की आवश्यकता होती है।
- दोनों संबंधित तालिकाओं की प्राथमिक कुंजियों को समावेश करने वाली एक नई तालिका बनाएं।
- दोनों विदेशी कुंजियों के संयोजन से बनी एक संयुक्त प्राथमिक कुंजी जोड़ें।
- इस तालिका का उपयोग संबंध के लिए विशिष्ट अतिरिक्त लक्षणों को संग्रहीत करने के लिए करें, जैसे कि पंजीकरण तिथियाँ।
3. वैकल्पिक बनाम अनिवार्य संबंध
स्पष्ट रूप से निर्धारित करें कि क्या संबंध आवश्यक है। एक NULLविदेशी कुंजी कॉलम में मान एक वैकल्पिक संबंध को इंगित करता है। इस निर्णय का एप्लिकेशन स्तर पर वैधता नियंत्रण तर्क पर प्रभाव पड़ता है।
पढ़ने के प्रदर्शन के लिए इंडेक्सिंग रणनीतियाँ 🏎️
इंडेक्स डेटा प्राप्त करने की गति बढ़ाने के मुख्य तरीके हैं। हालांकि, वे मुफ्त नहीं हैं। प्रत्येक इंडेक्स डिस्क स्थान का उपयोग करता है और लेखन ऑपरेशन (इन्सर्ट, अपडेट, डिलीट) को धीमा करता है।
1. प्राथमिक इंडेक्स
प्रत्येक तालिका को एक प्राथमिक कुंजी की आवश्यकता होती है। यह अक्सर क्लस्टर्ड होता है, जिसका अर्थ है कि भौतिक डेटा कुंजी के क्रम में संग्रहीत होता है। एक स्थिर कुंजी चुनें जिसे कभी अपडेट नहीं किया जाता है। प्रदर्शन के लिए सुरक्षित कुंजियाँ (स्वचालित रूप से बढ़ने वाली पूर्णांक) प्राकृतिक कुंजियों (जैसे ईमेल) की तुलना में अक्सर बेहतर होती हैं।
2. द्वितीयक इंडेक्स
गैर-प्राथमिक कॉलम पर फ़िल्टर या क्रमबद्ध करने वाले प्रश्नों को अनुकूलित करने के लिए द्वितीयक इंडेक्स का उपयोग करें। सामान्य परिदृश्य इस प्रकार हैं:
- ईमेल पते द्वारा खोज करना।
- स्थिति या श्रेणी द्वारा फ़िल्टर करना।
- तिथि द्वारा परिणामों को क्रमबद्ध करना।
3. संयुक्त इंडेक्स
जब कई कॉलमों द्वारा प्रश्न पूछा जाता है, तो एक संयुक्त इंडेक्स अलग-अलग एकल कॉलम इंडेक्स की तुलना में अधिक कुशल हो सकता है। इंडेक्स में कॉलम के क्रम का महत्व होता है। सबसे अधिक चयनात्मक कॉलम को पहले रखें।
4. कवरिंग इंडेक्स
एक कवरिंग इंडेक्स में एक प्रश्न को संतुष्ट करने के लिए आवश्यक सभी कॉलम शामिल होते हैं। इससे डेटाबेस को मुख्य तालिका तक पहुँचे बिना सीधे इंडेक्स से डेटा प्राप्त करने की अनुमति मिलती है, जिससे I/O काफी कम हो जाता है।
क्षैतिज स्केलिंग के लिए डिज़ाइन करना 🌐
ऊर्ध्वाधर स्केलिंग (एकल सर्वर में अधिक शक्ति जोड़ना) की सीमाएँ हैं। अंततः, आपको डेटा को कई नोड्स के बीच वितरित करना होगा। ईआरडी डिज़ाइन को इस वास्तविकता को ध्यान में रखना चाहिए।
1. शार्डिंग कुंजियाँ
शार्डिंग में डेटा को कई डेटाबेस में विभाजित करना शामिल है। शार्डिंग कुंजी का चयन महत्वपूर्ण है। इसका उपयोग प्रश्नों में अक्सर किया जाना चाहिए ताकि डेटा स्थिति सुनिश्चित हो। यदि आप “उपयोगकर्ता_आईडी, आप उस उपयोगकर्ता के सभी डेटा को एक ही नोड पर आसानी से प्रश्न कर सकते हैं।
- अच्छे शार्डिंग कीज़: उच्च कार्डिनैलिटी, प्रश्नों में अक्सर उपयोग की जाती है।
- खराब शार्डिंग कीज़: कम कार्डिनैलिटी (उदाहरण के लिए,
देश_कोड) या दुर्लभ रूप से उपयोग की जाती है।
2. क्रॉस-शार्ड जॉइन से बचें
अलग-अलग शार्ड्स के बीच जॉइन करना महंगा और जटिल होता है। इनकी आवश्यकता को कम करने के लिए अपने स्कीमा को डिज़ाइन करें। यदि आप दो एंटिटीज़ से डेटा चाहते हैं जो अलग-अलग शार्ड्स पर हो सकती हैं, तो डेटा को डेनॉर्मलाइज़ करने के बारे में सोचें। जॉइन से बचने के लिए आवश्यक विदेशी कुंजी डेटा को सीधे टेबल में स्टोर करें।
3. पार्टीशनिंग
पार्टीशनिंग एक बड़ी टेबल को छोटे, प्रबंधनीय टुकड़ों में बांटती है। इसे रेंज (तारीखें), सूची (श्रेणियां) या हैश द्वारा किया जा सकता है। इससे रखरखाव और प्रश्न प्रदर्शन में सुधार होता है, बिना एप्लिकेशन लॉजिक को बहुत बदले।
स्कीमा विकास और माइग्रेशन 🔄
आवश्यकताएं बदलती हैं। नए फीचर्स के लिए नए कॉलम की आवश्यकता होती है। पुराने फीचर्स को अप्रचलित कर दिया जाता है। एक मजबूत ERD बदलाव को स्वीकार करता है बिना मौजूदा कार्यक्षमता को तोड़े।
1. पीछे की ओर संगतता
जब नए फीचर्स जोड़ते हैं, तो सुनिश्चित करें कि पुराने क्लाइंट्स अभी भी काम कर सकें। पहले नए कॉलम को nullable बनाएं। उन्हें धीरे-धीरे भरें। कॉलम को तुरंत हटाएं नहीं; उन्हें अप्रचलित चिह्नित करें और माइग्रेशन विंडो के लिए रखें।
2. डेटा मॉडल का संस्करण बनाना
स्कीमा संस्करणों का अनुसरण करें। यह आपको तब बदलाव को वापस लाने की अनुमति देता है यदि माइग्रेशन के कारण महत्वपूर्ण विफलताएं हों। ऐसे माइग्रेशन स्क्रिप्ट्स का उपयोग करें जो आइडेम्पोटेंट हों, जिसका अर्थ है कि उन्हें बार-बार चलाया जा सकता है बिना त्रुटियों के।
3. डेटा माइग्रेशन का प्रबंधन
बड़े आकार के डेटा को हटाने के लिए सावधानी से योजना बनाने की आवश्यकता होती है। बड़े लॉक उत्पादन ट्रैफिक को रोक सकते हैं। निम्न ट्रैफिक विंडो के दौरान माइग्रेशन करें या जहां संभव हो ब्लू-ग्रीन डेप्लॉयमेंट रणनीतियों का उपयोग करें।
बचने के लिए सामान्य गलतियां ⚠️
यहां तक कि अनुभवी वास्तुकार भी गलतियां करते हैं। सामान्य त्रुटियों के बारे में जागरूकता आपको उनसे बचने में मदद करती है।
- अतिरिक्त डिज़ाइन:आपके पास अभी नहीं है उस स्केल के लिए डिज़ाइन करना। यदि आप शुरुआत कर रहे हैं, तो इसे सरल रखें। जटिलता लागत और जोखिम बढ़ाती है।
- सॉफ्ट डिलीट को नजरअंदाज करना: कभी भी संवेदनशील रिकॉर्ड्स को तुरंत स्थायी रूप से हटाएं नहीं। एक का उपयोग करें
हटाया_गया_समयसमयचिह्न के बजाय। इससे ऑडिट ट्रेल्स को बनाए रखा जाता है और पुनर्स्थापना की अनुमति मिलती है। - नाम संघर्ष: एक ही नाम का उपयोग टेबल और कॉलम के लिए करने से अस्पष्टता उत्पन्न होती है। एकल टेबल नियम का पालन करें।
- अनुपस्थित सीमाएँ: व्यावसायिक नियमों को लागू करने के लिए केवल एप्लिकेशन लॉजिक पर निर्भर रहने से डेटा क्षति होती है। डेटाबेस स्तर पर सीमाओं को लागू करें।
- सुरक्षा को नजरअंदाज करना: डिज़ाइन में पहुँच नियंत्रण के लिए क्षेत्रों को शामिल करना चाहिए। सुनिश्चित करें कि स्कीमा डिज़ाइन चरण में भूमिका-आधारित पहुँच का समर्थन किया जाता है।
दीर्घायु के लिए अंतिम विचार 🏁
एक स्केलेबल डेटाबेस बनाना एक निरंतर प्रक्रिया है। इसमें मॉनिटरिंग, विश्लेषण और समायोजन की आवश्यकता होती है। कोई डिज़ाइन लॉन्च के समय पूर्ण नहीं होता है। लक्ष्य एक ऐसी नींव बनाना है जिसे आसानी से संशोधित किया जा सके।
अपने प्रश्नों का नियमित रूप से ऑडिट करें। धीमे संचालन की पहचान करें और नीचे के स्कीमा को अनुकूलित करें। यह जानने के लिए प्रोफाइलिंग उपकरणों का उपयोग करें कि आपके डेटा को कैसे प्राप्त किया जाता है। इस फीडबैक लूप सुनिश्चित करता है कि आपकी आर्किटेक्चर आपके डेटा के बढ़ने के साथ भी कार्यक्षम बनी रहे।
याद रखें कि तकनीक विकसित होती है। नए स्टोरेज इंजन और प्रश्न भाषाएँ उभरती हैं। एक लचीला स्कीमा इन बदलावों के प्रति एक कठोर स्कीमा की तुलना में बेहतर ढंग से अनुकूलित होता है। मूल संबंधों और डेटा अखंडता पर ध्यान केंद्रित करें। ये विषय उन उपकरणों के बदलने के बावजूद भी स्थिर रहते हैं।
इन सिद्धांतों का पालन करके आप ऐसी प्रणालियाँ बनाते हैं जो लचीली होती हैं। वे वृद्धि को आसानी से संभालती हैं और भार के तहत प्रदर्शन बनाए रखती हैं। यही आपके डेटाबेस इंफ्रास्ट्रक्चर को भविष्य के लिए सुरक्षित बनाने का आधार है।