










टिकाऊ डेटाबेस स्कीमा डिज़ाइन करने के लिए सिर्फ टेबल और कॉलम की सूची बनाने से ज़्यादा चाहिए। इसके लिए यह समझना आवश्यक है कि एकता कैसे एक दूसरे से संबंधित हैं। एंटिटी-रिलेशनशिप डायग्राम (ERD) में सबसे शक्तिशाली लेकिन जटिल अवधारणाओं में से एक विरासत है। इस तंत्र के द्वारा हम वास्तविक दुनिया के पदानुक्रमों को मॉडल कर सकते हैं, जहां वस्तुएं सामान्य विशेषताओं को साझा करती हैं लेकिन साथ ही अनूठे गुण भी रखती हैं। डेटाबेस डिज़ाइन के संदर्भ में, इसका अर्थ होता है सुपरटाइप्स और सबटाइप्स। 🧩
जब हम विरासत का मॉडलिंग करते हैं, तो हम मूल रूप से “है-एक” संबंध को पकड़ रहे होते हैं। उदाहरण के लिए, एक वाहन एक प्रकार का है उत्पाद, और एक कार एक प्रकार का है वाहन। इस पदानुक्रम के कारण हम उच्च स्तर पर विशेषताओं का पुनर्उपयोग कर सकते हैं, जबकि निचले स्तर पर विशिष्ट व्यवहार या डेटा को परिभाषित कर सकते हैं। एक संबंधात्मक डेटाबेस में इसके कार्यान्वयन को समझना डेटा अखंडता और प्रश्न प्रदर्शन के लिए निर्णायक है। 🗄️
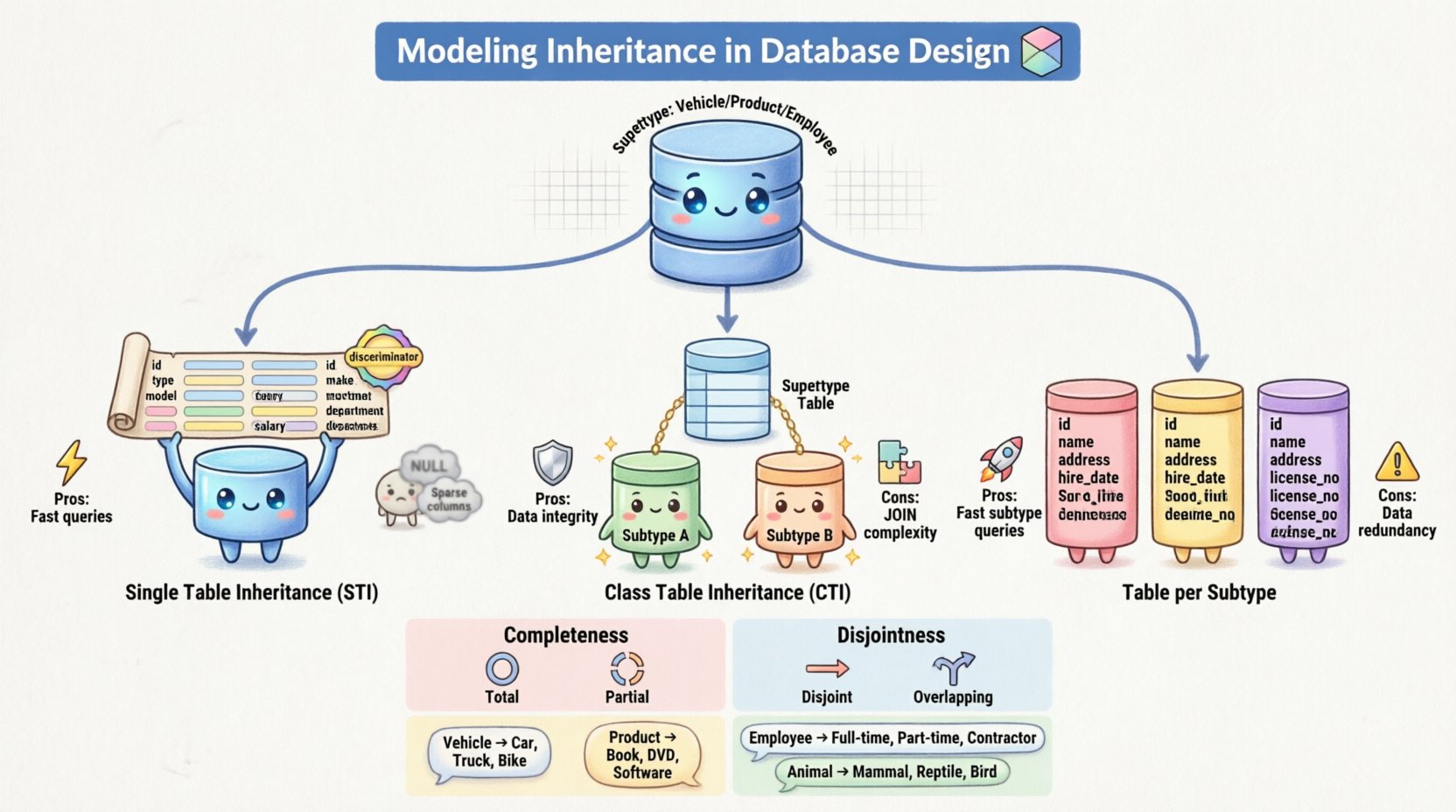
🔑 मूल अवधारणाएं: सुपरटाइप्स और सबटाइप्स
कार्यान्वयन में डुबकी लगाने से पहले, हमें शब्दावली को स्पष्ट रूप से परिभाषित करना होगा। डेटाबेस मॉडलिंग में विरासत केवल कोड के बारे में नहीं है; यह डेटा के संरचनात्मक प्रतिनिधित्व के बारे में है।
- सुपरटाइप: यह मुख्य एंटिटी है। इसमें सभी संबंधित एंटिटी की सामान्य विशेषताएं होती हैं। यह सामान्य श्रेणी का प्रतिनिधित्व करता है। उदाहरण के लिए, कर्मचारी एक सुपरटाइप के रूप में हो सकता है।
- सबटाइप: ये बच्चे की एंटिटी हैं। इन्हें सुपरटाइप से विशेषताएं विरासत में मिलती हैं, लेकिन इन्हें अपनी अनूठी विशेषताएं भी हो सकती हैं। उदाहरणों में शामिल हैं प्रबंधक या विकासकर्ता.
- एंटिटी श्रेणी: सुपरटाइप को कभी-कभी एंटिटी श्रेणी कहा जाता है, जो सबटाइप्स को एक साथ ग्रुप करता है।
- डिस्क्रिमिनेटर: सुपरटाइप के भीतर एक विशिष्ट विशेषता जो निर्धारित करती है कि एक उदाहरण किस सबटाइप में स्थित है। इसका अक्सर भौतिक कार्यान्वयन में उपयोग किया जाता है।
सुपरटाइप और सबटाइप के बीच संबंध कठोर होता है। प्रत्येक सबटाइप के उदाहरण को सुपरटाइप का भी उदाहरण होना चाहिए। हालांकि, सुपरटाइप के प्रत्येक उदाहरण को एक विशिष्ट सबटाइप का उदाहरण होने की आवश्यकता नहीं है। यह अंतर डेटा मॉडलिंग की सटीकता के लिए महत्वपूर्ण है। ✅
📊 कार्यान्वयन रणनीतियां
तार्किक ERD मॉडल को भौतिक डेटाबेस स्कीमा में बदलने के लिए विशिष्ट मैपिंग रणनीतियों की आवश्यकता होती है। संबंधात्मक प्रणालियों में विरासत के प्रतिनिधित्व के लिए तीन मुख्य दृष्टिकोणों का उपयोग किया जाता है। प्रत्येक के भंडारण, पुनर्प्राप्ति गति और डेटा अखंडता के संबंध में व्यापार लाभ-हानि होते हैं। 🛠️
1. एकल तालिका विरासत (STI)
इस दृष्टिकोण में, सुपरटाइप और सभी सबटाइप के सभी लक्षण एकल तालिका में संयोजित किए जाते हैं। तालिका में पूरे विरासत पदानुक्रम में परिभाषित प्रत्येक लक्षण के लिए कॉलम होते हैं। विभिन्न सबटाइपों से संबंधित पंक्तियों को अलग करने के लिए एक विभेदक कॉलम जोड़ा जाता है।
- लाभ: डेटा पढ़ने के लिए बहुत कुशल। एक सरल
SELECTजटिल जॉइन्स के बिना सभी जानकारी प्राप्त करता है। - नुकसान: तालिका बहुत चौड़ी हो सकती है जिसमें कई
NULLवे लक्षण जो विशिष्ट सबटाइपों के लिए लागू नहीं होते हैं। यदि सबटाइप-विशिष्ट प्रतिबंधों में परिवर्तन होता है तो अपडेट करना कठिन हो सकता है।
2. वर्ग तालिका विरासत (CTI)
यहाँ, सुपरटाइप और प्रत्येक सबटाइप को अलग-अलग तालिकाओं में मैप किया जाता है। सुपरटाइप तालिका में सामान्य लक्षण और प्राथमिक कुंजी होती है। प्रत्येक सबटाइप तालिका में अद्वितीय लक्षण होते हैं और एक विदेशी कुंजी होती है जो सुपरटाइप की प्राथमिक कुंजी से जुड़ती है।
- लाभ: बहुत अधिक नॉर्मलाइज्ड। कोई भी
NULLअनुपयुक्त लक्षणों के लिए। सख्ती से संदर्भी अखंडता लागू करता है। - नुकसान: डेटा प्राप्त करने के लिए बहुत सारे
JOINसंचालन की आवश्यकता होती है, जो बड़े डेटासेट्स पर प्रदर्शन को प्रभावित कर सकती है। इसके अलावा यहINSERTसंचालन को जटिल बना देता है क्योंकि डेटा को कई तालिकाओं में लिखना होता है।
3. प्रत्येक सबटाइप के लिए तालिका (कॉन्क्रीट तालिका विरासत)
इस रणनीति में प्रत्येक सबटाइप के लिए एक तालिका बनाई जाती है, जिसमें सुपरटाइप भी शामिल है। हालांकि, प्रत्येक सबटाइप तालिका में सुपरटाइप के लक्षणों की प्रतिलिपि होती है। केंद्रीय सुपरटाइप तालिका के लिए कोई सीधा संबंध नहीं है।
- लाभ: एक विशिष्ट सबटाइप को प्रश्न करना बहुत तेज है क्योंकि सभी डेटा एक ही स्थान पर है। यह
NULLSTI की समस्या से बचता है। - नुकसान: डेटा अतिरेक। यदि सुपरटाइप में एक सामान्य लक्षण में परिवर्तन होता है, तो इसे प्रत्येक सबटाइप तालिका में अपडेट करना होगा। इससे डेटा असंगति का जोखिम बढ़ जाता है।
⚖️ विरासत पर प्रतिबंध
सभी विरासत संबंध एक जैसे नहीं होते हैं। हमें उन प्रतिबंधों को परिभाषित करना होगा जो उदाहरणों और उनके प्रकारों के बीच संबंधों को नियंत्रित करते हैं। इन प्रतिबंधों के कारण डेटा तार्किक और संगत बना रहता है। 📝
पूर्णता प्रतिबंध
यह प्रतिबंध निर्धारित करता है कि क्या प्रत्येक सुपरटाइप उदाहरण को कम से कम एक उपटाइप में सदस्यता होनी चाहिए।
- पूर्ण: सुपरटाइप का प्रत्येक उदाहरण कम से कम एक उपटाइप का सदस्य होना चाहिए। कोई भी “सामान्य” उदाहरण नहीं है। उदाहरण के लिए, प्रत्येक जानवर को या तो एक स्तनधारी या एक पक्षी.
- आंशिक: सुपरटाइप का एक उदाहरण जरूरी नहीं है कि किसी भी उपटाइप में सदस्यता रखे। यह एक सामान्य एकांत के रूप में अस्तित्व में हो सकता है। यह तब आम होता है जब वर्गीकरण के बजाय वर्गीकरण के लिए श्रेणी का उपयोग किया जाता है।
असंयुक्तता प्रतिबंध
यह प्रतिबंध निर्धारित करता है कि क्या एक उदाहरण एक साथ एक से अधिक उपटाइप में सदस्यता रख सकता है।
- असंयुक्त: एक उदाहरण केवल एक उपटाइप में सदस्यता रख सकता है। इस मॉडल में यह नहीं हो सकता कि वह एक प्रबंधक और एक विकासकर्ता एक ही समय में इस मॉडल में।
- ओवरलैप: एक उदाहरण एक से अधिक उपटाइप में सदस्यता रख सकता है। इससे जटिल भूमिकाओं की अनुमति मिलती है जहां एक कर्मचारी कई पदों या वर्गीकरणों को धारण कर सकता है।
इन प्रतिबंधों को मिलाने से चार अलग-अलग मॉडलिंग परिदृश्य प्राप्त होते हैं। स्कीमा बनाने से पहले यह समझना महत्वपूर्ण है कि कौन सा परिदृश्य आपकी व्यावसायिक तर्क के अनुरूप है। 🧠
| प्रतिबंध प्रकार | परिभाषा | उदाहरण परिदृश्य |
|---|---|---|
| असंयुक्त + पूर्ण | केवल एक उपप्रकार, कोई सामान्य उदाहरण नहीं | आदेश स्थिति: अपेक्षित, भेजा गया, डिलीवर किया गया |
| असंयुक्त + आ частिक | केवल एक उपप्रकार, वैकल्पिक उपप्रकार | ग्राहक: वीआईपी या नियमित (कुछ न तो वीआईपी हैं न ही नियमित) |
| अतिव्याप्ति + पूर्ण | एक से अधिक उपप्रकार अनुमति है, एक के साथ संबंधित होना चाहिए | उपयोगकर्ता भूमिका: प्रशासक और संपादक (कम से कम एक के लिए आवश्यक है) |
| अतिव्याप्ति + आ भाग | एक से अधिक उपप्रकार अनुमति है, वैकल्पिक | उत्पाद: बिक्री योग्य, प्रचारात्मक (दोनों या कोई भी नहीं हो सकता है) |
🔍 प्रश्न पूछना और डेटा प्राप्त करना
मैपिंग रणनीति का चयन आपके प्रश्न लिखने के तरीके को महत्वपूर्ण रूप से प्रभावित करता है। एक सामान्यीकृत वातावरण में, आपको एक एकांत के पूर्ण चित्र को प्राप्त करने के लिए आरोही क्रम में यात्रा करने की आवश्यकता होती है। 🔎
- उपप्रकार डेटा प्राप्त करना: यदि आप किसी उपप्रकार के विशिष्ट लक्षणों तक पहुंच की आवश्यकता है, तो आपको उपप्रकार तालिका को जोड़ना होगा। यह क्लास टेबल विरासत में मानक है।
- उपप्रकार डेटा प्राप्त करना: यदि आप सामान्य लक्षणों की आवश्यकता है, तो आप सीधे उपप्रकार तालिका को प्रश्न कर सकते हैं।
- बहुआकृति प्रश्न: जब किसी उपप्रकार के बिना सभी उदाहरणों के लिए प्रश्न कर रहे हैं, तो एक तालिका दृष्टिकोण सबसे तेज है। हालांकि, यदि एक से अधिक तालिकाओं का उपयोग कर रहे हैं, तो आपको
यूनियनसंचालन या जटिल जॉइन का उपयोग करना होगा।
प्रदर्शन के प्रभावों को ध्यान में रखें। एक लेख को प्राप्त करने के लिए पांच तालिकाओं को जोड़ने वाला प्रश्न एक अनियमित तालिका पर प्रश्न से धीमा हो सकता है। हालांकि, अनियमित तालिका सामान्यीकरण नियमों के उल्लंघन कर सकती है, जिससे अपडेट विचलन हो सकते हैं। इन कारकों के बीच संतुलन बनाना स्कीमा डिजाइन का मुख्य हिस्सा है। ⚖️
🛠️ रखरखाव और विकास
स्कीमा स्थिर नहीं होते हैं। व्यापार आवश्यकताएं बदलती हैं, और इसी तरह डेटाबेस संरचना भी बदलनी चाहिए। विरासत मॉडलिंग लचीलापन प्रदान करती है, लेकिन रखरखाव के दौरान इसमें जटिलता भी लाती है। 🔄
नए उपप्रकार जोड़ना
नए उपप्रकार को जोड़ना आमतौर पर सरल होता है। आप एक नई तालिका बनाते हैं (CTI में) या डिस्क्रिमिनेटर कॉलम में एक नया मान जोड़ते हैं (STI में)। हालांकि, आपको यह सुनिश्चित करना होगा कि मौजूदा प्रश्न और एप्लिकेशन तर्क नए प्रकार को स्वीकार करें। कोड को अपडेट न करने के कारण रनटाइम त्रुटियां हो सकती हैं।
उपप्रकार लक्षणों को संशोधित करना
यदि आप उपप्रकार में एक लक्षण जोड़ते हैं, तो यदि CTI या प्रत्येक उपप्रकार के लिए तालिका का उपयोग कर रहे हैं, तो इसे हर उपप्रकार तालिका में प्रतिबिंबित करना होगा। STI में, आप इसे एक बार एकल तालिका में जोड़ते हैं। इससे सामान्य परिवर्तनों के लिए STI को रखरखाव करना आसान होता है, लेकिन विशिष्ट परिवर्तनों के लिए कठिन होता है।
डेटा स्थानांतरण
विरासत मॉडल को पुनर्गठित करना एक महत्वपूर्ण कार्य है। एकल तालिका से नॉर्मलाइज्ड संरचना में जाने के लिए बहुत सारी तालिकाओं में डेटा को स्थानांतरित करने की आवश्यकता होती है। इस प्रक्रिया को डेटा के नुकसान या क्षति से बचने के लिए सावधानी से प्रबंधित किया जाना चाहिए। 🚧
📈 नॉर्मलाइजेशन और विरासत
विरासत मॉडलिंग डेटाबेस नॉर्मलाइजेशन से निकटता से जुड़ी होती है। नॉर्मलाइजेशन का लक्ष्य अतिरिक्तता को कम करना और डेटा अखंडता में सुधार करना है। यदि सही तरीके से नहीं संभाला गया, तो विरासत इन लक्ष्यों से कभी-कभी टकरा सकती है।
- पहला सामान्य रूप (1NF): विरासत मॉडल आम तौर पर 1NF को संतुष्ट करते हैं, क्योंकि विशेषताएं परमाणु होती हैं।
- दूसरा सामान्य रूप (2NF): STI में, यदि डिस्क्रिमिनेटर कुंजी का हिस्सा नहीं है, तो एक तालिका में वे विशेषताएं हो सकती हैं जो प्राथमिक कुंजी पर पूरी तरह निर्भर नहीं होती हैं। इसके लिए सावधानी से कुंजी डिजाइन की आवश्यकता होती है।
- तीसरा सामान्य रूप (3NF): CTI में, उपप्रकार तालिकाओं में विशेषताओं के अलगाव के कारण आमतौर पर 3NF प्राप्त करने में मदद मिलती है, क्योंकि इससे स्थानांतरित निर्भरताएं हट जाती हैं।
जब सुपरटाइप डिजाइन कर रहे हों, तो यह सुनिश्चित करें कि सामान्य विशेषताएं वास्तव में सामान्य हों। यदि कोई विशेषता केवल एक उपप्रकार द्वारा उपयोग की जाती है, तो उसे सुपरटाइप में नहीं होना चाहिए। इससे बचा जाता है कि सुपरटाइप एक “देवता तालिका” बन जाए जिसे प्रश्न करना मुश्किल हो। 👁️
🎯 स्कीमा डिजाइन के लिए सर्वोत्तम प्रथाएं
अपने विरासत मॉडल को रखरखाव योग्य और कार्यक्षम बनाए रखने के लिए, इन दिशानिर्देशों का पालन करें।
- गहराई सीमित करें: गहरे पदानुक्रमों से बचें। आमतौर पर विरासत के तीन स्तर ही अधिकतम सिफारिश किए गए हैं। इससे आगे जाने पर प्रश्नों और रखरखाव की जटिलता लाभ से अधिक हो जाती है।
- स्पष्ट नामकरण का उपयोग करें: नाम पदानुक्रम को दर्शाने चाहिए।वाहन, कार, ट्रक स्पष्ट है।एंटिटी1, एंटिटी2 स्पष्ट नहीं है।
- वृद्धि के लिए योजना बनाएं: भविष्य के उपप्रकारों की अपेक्षा करें। यदि आप बहुत सारे नए उपप्रकारों की उम्मीद कर रहे हैं, तो एकल तालिका असंभाव्य हो सकती है। यदि आप कम उपप्रकारों की उम्मीद कर रहे हैं, तो CTI बेहतर हो सकती है।
- प्रतिबंधों को दस्तावेज़ीकृत करें: स्पष्ट रूप से असंगतता और पूर्णता के प्रतिबंधों को दस्तावेज़ीकृत करें। भविष्य के विकासकर्ताओं को यह जानने की आवश्यकता होगी कि क्या कोई उदाहरण एक से अधिक उपप्रकारों में सदस्यता रख सकता है।
- インデックス戦略: यदि CTI का उपयोग कर रहे हैं, तो उपप्रकार तालिकाओं में विदेशी कुंजी कॉलम को इंडेक्स करें ताकि जॉइन को तेज किया जा सके। यदि STI का उपयोग कर रहे हैं, तो फ़िल्टरिंग के लिए डिस्क्रिमिनेटर कॉलम को इंडेक्स करें।
🧪 वास्तविक दुनिया के परिदृश्य
आइए देखें कि इसका वास्तविक डेटा मॉडलिंग चुनौतियों पर कैसे अनुप्रयोग होता है।
परिदृश्य 1: मानव संसाधन
एक एचआर प्रणाली में, आपके पास है व्यक्ति एक सुपरटाइप के रूप में। उपप्रकारों में शामिल हैं कर्मचारी, ठेकेदार, और अंतर्निर्मित। प्रत्येक उपप्रकार के पास अद्वितीय डेटा है: कर्मचारी के पास एक वेतन आईडी है, ठेकेदार के पास बिलिंग दर है। एक व्यक्ति तालिका नाम और पता रखती है। यह क्लास टेबल इनहेरिटेंस मॉडल के साथ बहुत अच्छी तरह से फिट बैठता है।
परिदृश्य 2: स्टॉक प्रबंधन
एक उत्पाद कैटलॉग को ध्यान में रखें। उत्पाद सुपरटाइप है। उपप्रकार हैं इलेक्ट्रॉनिक्स, फर्नीचर, और कपड़े. इलेक्ट्रॉनिक्स के साथ है गारंटी अवधि. कपड़े के साथ है आकार और रंग. यदि आप गारंटी वाले सभी उत्पादों के लिए प्रश्न करते हैं, तो आपको इलेक्ट्रॉनिक्स तालिका को जोड़ना होगा। इससे प्रश्न प्रदर्शन व्यापार की ओर ध्यान आकर्षित करता है। 🔍
परिदृश्य 3: वित्तीय लेनदेन
बैंकिंग प्रणाली में, खाता सुपरटाइप है। उपप्रकार हैं बचत, जांच, और ऋण. एक बचत खाता ब्याज दर के साथ है। एक ऋण खाता एक तारीख के साथ है। इस परिदृश्य में आमतौर पर एकल तालिका दृष्टिकोण से लाभ मिलता है ताकि सभी खाता प्रकारों के बीच बैलेंस की गणना सरल बनाई जा सके।
🚀 प्रदर्शन पर विचार
प्रदर्शन अक्सर मैपिंग रणनीति चुनते समय निर्णायक कारक होता है। बड़े डेटासेट दृष्टिकोणों के बीच अंतरों को बढ़ाते हैं।
- लेखन प्रदर्शन: STI सबसे तेज है क्योंकि यह एकल है
INSERTबयान। CTI कई के आवश्यकता हैINSERTकथन, जो लेनदेन अतिरिक्त लागत बढ़ाते हैं। - पढ़ने का प्रदर्शन: यदि आप निरंतर विशिष्ट उपप्रकारों के लिए प्रश्न पूछते हैं, तो CTI, STI से तेज है क्योंकि आप केवल संबंधित स्तंभों को पढ़ते हैं। यदि आप सभी उदाहरणों के लिए प्रश्न पूछते हैं, तो STI तेज है।
- भंडारण: STI अधिक भंडारण का उपयोग करता है क्योंकि
NULLभराव। CTI डुप्लिकेट प्राथमिक कुंजियों और विदेशी कुंजियों के कारण अधिक भंडारण का उपयोग करता है, लेकिन NULL भराव की कमी के कारण कम।NULLभराव।
आपके एप्लिकेशन का प्रोफाइलिंग करना आवश्यक है। सैद्धांतिक प्रदर्शन हमेशा वास्तविक दुनिया के उपयोग के पैटर्न से मेल नहीं खाता है। अपने चयन की पुष्टि करने का एकमात्र तरीका वास्तविक डेटा आयतन के साथ परीक्षण करना है। 📊
🛡️ डेटा अखंडता और मान्यता
विरासत मॉडल में डेटा अखंडता बनाए रखने के लिए सख्त मान्यता नियमों की आवश्यकता होती है। आपको सुनिश्चित करना होगा कि उपप्रकार तालिका में दर्ज किया गया डेटा सुपरटाइप की सीमाओं के अनुरूप हो।
- विदेशी कुंजी सीमाएँ: सुनिश्चित करें कि उपप्रकार की पंक्तियाँ हमेशा मान्य सुपरटाइप पंक्तियों से जुड़ी रहें। इससे अनाथ डेटा की रोकथाम होती है।
- चेक सीमाएँ: व्यावसायिक नियमों को लागू करने के लिए चेक सीमाओं का उपयोग करें। उदाहरण के लिए, सुनिश्चित करें कि ब्याज दर में एक बचत उपप्रकार कभी भी ऋणात्मक नहीं होता है।
- ट्रिगर्स: कुछ जटिल परिदृश्यों में, अपडेट के दौरान तालिकाओं के बीच संगतता बनाए रखने के लिए डेटाबेस ट्रिगर्स की आवश्यकता हो सकती है।
स्वचालित परीक्षण में विरासत के परिदृश्यों को शामिल करना चाहिए। सुनिश्चित करें कि एक नए उपप्रकार उदाहरण को बनाने से सुपरटाइप के रूप में सही तरीके से अपडेट होता है। सुनिश्चित करें कि यदि यह इच्छित व्यवहार है, तो सुपरटाइप उदाहरण को हटाने से उपप्रकारों में सही तरीके से कैस्केड होता है। 🧪
📝 अंतिम विचार
विरासत के मॉडलिंग में लचीलापन और जटिलता के बीच संतुलन बनाए रखना होता है। इसके लिए एकमात्र “सही” तरीका नहीं है। सबसे अच्छा चयन आपके विशिष्ट डेटा पहुंच पैटर्न, व्यावसायिक नियमों और प्रदर्शन की आवश्यकताओं पर निर्भर करता है।
- क्षेत्र की स्पष्ट समझ से शुरुआत करें। तालिकाओं के बारे में चिंता करने से पहले संस्थाओं को मैप करें।
- अपनी सबसे अधिक आम प्रश्नों के अनुरूप एक मैपिंग रणनीति चुनें।
- अपने निर्णयों को दस्तावेज़ीकृत करें। भविष्य के रखरखाव के लिए इस दस्तावेज़ीकरण पर निर्भर रहना होगा।
- स्कीमा की नियमित रूप से समीक्षा करें। जैसे व्यवसाय विकसित होता है, मॉडल में बदलाव की आवश्यकता हो सकती है।
सुपरटाइप्स और सबटाइप्स को ध्यान से डिज़ाइन करके, आप एक डेटाबेस बनाते हैं जो टिकाऊ, स्केलेबल और समझने में आसान है। इस आधार ने उन एप्लिकेशन्स का समर्थन किया है जो इस पर निर्भर हैं, जिससे लंबे समय तक स्थिरता और दक्षता सुनिश्चित होती है। 🏗️