











डेटा आर्किटेक्चर के क्षेत्र में, बहु-से-बहु संबंध के अलावा ऐसी कोई अवधारणा नहीं है जो इतनी भ्रम उत्पन्न करे। एक एंटिटी-रिलेशनशिप डायग्राम (ईआरडी) डिज़ाइन करते समय, एक ऐसी स्थिति का सामना करना पड़ता है जहां एक एंटिटी दूसरी एंटिटी के कई उदाहरणों से जुड़ती है, और विपरीत भी। इसके लिए एक विशिष्ट संरचनात्मक दृष्टिकोण की आवश्यकता होती है। संबंधात्मक डेटाबेस प्रबंधन प्रणालियाँ बिना बुनियादी रूप से बहु-से-बहु संबंधों का समर्थन नहीं करती हैं। डेटा अखंडता बनाए रखने और प्रभावी खोज के लिए इन्हें एक मध्यवर्ती संरचना की आवश्यकता होती है। यह मार्गदर्शिका इन संबंधों को हल करने की विश्वसनीय विधियों का अध्ययन करती है, ताकि आपका डेटा मॉडल दृढ़, स्केलेबल और सामान्यीकृत बना रहे।
चाहे आप शैक्षणिक रिकॉर्ड, इन्वेंट्री प्रबंधन या उपयोगकर्ता अनुमतियों के लिए एक प्रणाली डिज़ाइन कर रहे हों, इन कार्डिनैलिटी को हल करने के सिद्धांत एक जैसे रहते हैं। नीचे की यांत्रिकी को समझने से भविष्य में असामान्यताओं को रोका जा सकता है और रखरखाव को सरल बनाया जा सकता है। हम सतही परिभाषाओं से आगे बढ़कर संरचनात्मक आवश्यकताओं, सामान्यीकरण नियमों और कार्यान्वयन रणनीतियों का अध्ययन करेंगे, जो पेशेवर डेटा मॉडलिंग को परिभाषित करते हैं।
🔍 ईआरडी में कार्डिनैलिटी को समझना
कार्डिनैलिटी डेटाबेस में एंटिटी के बीच संख्यात्मक संबंध को परिभाषित करती है। यह बताती है कि एक एंटिटी के प्रत्येक उदाहरण के साथ दूसरी एंटिटी के कितने उदाहरण जुड़ सकते हैं या जुड़ने चाहिए। ईआरडी नोटेशन में, इसे एंटिटी को जोड़ने वाली रेखाओं द्वारा आमतौर पर दर्शाया जाता है, जहां क्राउज़ फुट बहुत की ओर इशारा करते हैं और सीधी रेखाएं या एकल टिक एक की ओर इशारा करती हैं।
तीन मुख्य कार्डिनैलिटी हैं:
- एक-से-एक (1:1):एंटिटी ए में एक एकल रिकॉर्ड एंटिटी बी में एक एकल रिकॉर्ड से संबंधित होता है। उदाहरण: एक व्यक्ति और उनका पासपोर्ट।
- एक-से-बहुत (1:M):एंटिटी ए में एक एकल रिकॉर्ड एंटिटी बी में कई रिकॉर्ड से संबंधित होता है। उदाहरण: एक ग्राहक द्वारा कई आदेश देना।
- बहुत-से-बहुत (M:N):एंटिटी ए में कई रिकॉर्ड एंटिटी बी में कई रिकॉर्ड से संबंधित होते हैं। उदाहरण: छात्र बहुत से कोर्स में दाखिला लेते हैं, और कोर्स में कई छात्र होते हैं।
जबकि 1:1 और 1:M संबंध भौतिक डेटाबेस स्कीमा में लागू करने में सीधे हैं, लेकिन M:N संबंध एक विशिष्ट चुनौती प्रस्तुत करता है। संबंधात्मक सिद्धांत कहता है कि एक टेबल के सेल में केवल परमाणु मान होने चाहिए। दो टेबल के बीच सीधा संबंध जहां टेबल ए में एक ही पंक्ति टेबल बी में कई पंक्तियों को सिद्धांत रूप से संदर्भित कर सकती है, भौतिक स्तर पर इस सिद्धांत का उल्लंघन करता है।
🚫 संबंधात्मक मॉडल में सीधे M:M संबंधों के विफल होने के कारण
संबंधात्मक मॉडल, ई.एफ. कॉड द्वारा स्थापित, संबंधों (टेबल) की अवधारणा पर निर्भर करता है, जहां प्रत्येक कॉलम एक विशिष्ट गुणवत्ता का प्रतिनिधित्व करता है और प्रत्येक पंक्ति एक अद्वितीय उदाहरण का प्रतिनिधित्व करती है। एक मानक संबंधात्मक डेटाबेस में सीधे बहु-से-बहु संबंध के असंभव होने के दो मुख्य कारण हैं:
- मूल रूप से समर्थन की कमी:डेटाबेस इंजन एक विदेशी कुंजी कॉलम में कई मानों को संग्रहीत करने की अनुमति नहीं देते हैं। एक विदेशी कुंजी किसी अन्य टेबल में एक ही प्राथमिक कुंजी की ओर इशारा करना चाहिए। इसे कुंजी की सूची की ओर इशारा नहीं कर सकते।
- प्रविष्टि और डिलीट विचलन:यदि आप एक ही सेल में कई आईडी को संग्रहीत करने की कोशिश करते हैं (उदाहरण के लिए, “छात्र आईडी: 101, 102, 103”), तो आप पहले सामान्य रूप (1NF) के उल्लंघन का निर्माण करते हैं। इससे विशिष्ट संबंधों को खोजने, अपडेट करने और हटाने में गणनात्मक रूप से अधिक खर्चीला और त्रुटिपूर्ण हो जाता है।
परिणामस्वरूप, इस डेटा को प्रभावी ढंग से संग्रहीत करने के लिए, संबंध को एक एंटिटी के रूप में व्यवहार करना आवश्यक है। यह परिवर्तन जटिलता को हल करने की मूल तकनीक है।
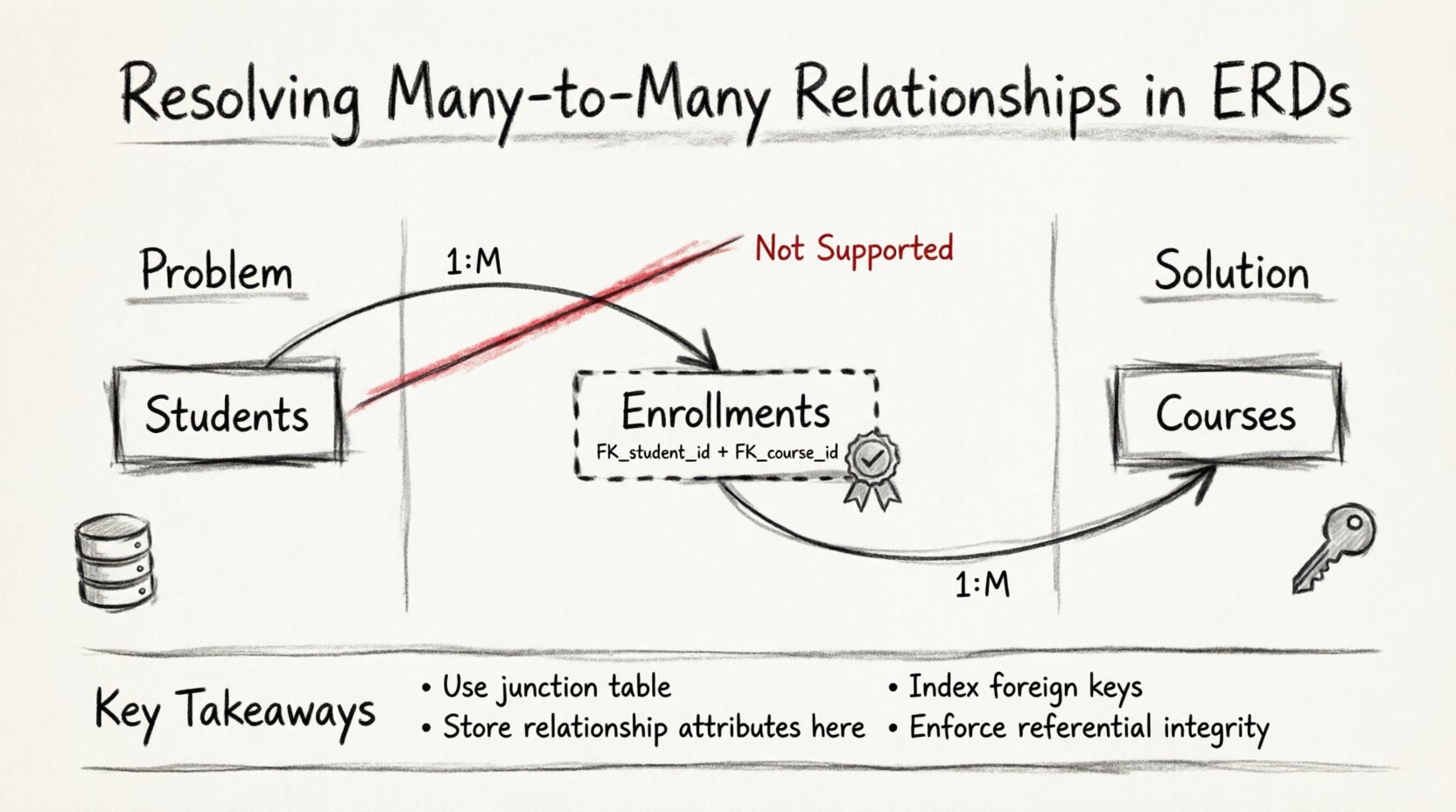
🧱 तकनीक 1: संबंधात्मक एंटिटी (जंक्शन टेबल)
बहु-से-बहु संबंध को हल करने का मानक समाधान एक संबंधात्मक एंटिटी के निर्माण करना है, जिसे आमतौर पर जंक्शन टेबल या ब्रिज टेबल के रूप में जाना जाता है। यह टेबल दो मुख्य एंटिटी के बीच भौतिक रूप से बैठती है और सीधे संबंध को दो एक-से-बहु संबंधों में तोड़ देती है।
जब आप एक जंक्शन टेबल का परिचय देते हैं, तो मूल M:N संबंध को निम्न में विघटित किया जाता है:
- एंटिटी ए और जंक्शन टेबल के बीच एक-से-बहु संबंध।
- एंटिटी बी और जंक्शन टेबल के बीच एक-से-बहु संबंध।
जंक्शन टेबल की संरचना:
- विदेशी कुंजियाँ:इसमें कम से कम दो विदेशी कुंजी कॉलम होने चाहिए। एक एंटिटी ए के प्राथमिक कुंजी को संदर्भित करता है, और दूसरा एंटिटी बी के प्राथमिक कुंजी को संदर्भित करता है।
- मिश्रित प्राथमिक कुंजी:अक्सर, इन दो विदेशी कुंजियों का संयोजन जंक्शन टेबल के लिए प्राथमिक कुंजी के रूप में कार्य करता है। इससे यह सुनिश्चित होता है कि एक विशिष्ट एंटिटी जोड़ी को एक से अधिक बार जोड़ा नहीं जा सकता, जब तक कि संबंध आंतरिक रूप से बहु-मूल्यवान न हो।
- सरोगेट कीज़: कुछ मामलों में, जंक्शन टेबल में एक अद्वितीय स्वतः बढ़ता हुआ ID जोड़ा जाता है। यह उपयोगी है यदि संबंध के कई उदाहरण हो सकते हैं जिनमें अलग-अलग विशेषताएं हों (उदाहरण के लिए, एक छात्र एक कोर्स में अलग-अलग वर्षों में अलग-अलग ग्रेड के साथ कई बार नामांकित हो सकता है)।
उदाहरण परिदृश्य:
एक पुस्तकालय प्रणाली को ध्यान में रखें। एक पुस्तक कई पाठकों द्वारा उधार ली जा सकती है। एक पाठक कई पुस्तकों.
- समाधान के बिना: आप एक पुस्तक की पंक्ति को सीधे बहुत सारी पाठक पंक्तियों से जोड़ नहीं सकते।
- समाधान के साथ: एक उधार लेने का लॉग टेबल बनाएं।
- का उधार लेने का लॉग में शामिल है
पुस्तक_आईडीऔरपाठक_आईडी.
इस संरचना के कारण डेटाबेस को किसी भी समय ठीक से ट्रैक करने में सक्षम होता है कि कौन सा पाठक किस पुस्तक के साथ है, बिना पुस्तक या पाठक डेटा की दोहराव के।
📝 तकनीक 2: संबंधों पर विशेषताओं का प्रबंधन
ईआरडी मॉडलिंग में एक महत्वपूर्ण अंतर यह है कि क्या संबंध में एक स्वयं के डेटा है। एक सरल लिंक में, संबंध मौजूद है या नहीं। हालांकि, बहुत सारे वास्तविक दुनिया के परिदृश्यों में, संबंध के खुद के गुण होते हैं।
उदाहरण के लिए, एक प्रोजेक्ट और कर्मचारी परिदृश्य, एक कर्मचारी एक से अधिक परियोजनाओं पर काम कर सकता है, और एक परियोजना में एक से अधिक कर्मचारी हो सकते हैं। लेकिन संबंध में शामिल हो सकते हैं:
- भूमिका:क्या कर्मचारी इस विशिष्ट परियोजना पर एक विकासकर्ता, डिज़ाइनर या प्रबंधक है?
- आवंटित घंटे:इस परियोजना के लिए हफ्ते में कितने घंटे आवंटित किए गए हैं?
- प्रारंभ तिथि:इस नियुक्ति का आरंभ कब हुआ था?
यदि आप संबंध को सिर्फ एक द्विआधारी फ्लैग के रूप में लेते हैं, तो आप इस महत्वपूर्ण डेटा को खो देते हैं। संयोजन तालिका इन विशेषताओं को संग्रहीत करने के लिए आदर्श स्थान बन जाती है।
कार्यान्वयन नियम:
- संबंध विशेषताओं को मूल एककों में संग्रहीत न करें। वे केवल परियोजना के लिए नहीं हैं, न ही कर्मचारी के लिए।
- सभी संबंध-विशिष्ट डेटा को संयोजन तालिका में रखें।
- सुनिश्चित करें कि संयोजन तालिका में एक अद्वितीय पहचानकर्ता (संयुक्त या स्थानापन्न) हो ताकि इन विशेषताओं के अपडेट करने की अनुमति मिले बिना मूल एककों को प्रभावित किए बिना।
इस दृष्टिकोण से डेटा सामान्यीकरण सुनिश्चित होता है। यदि आप भूमिका कॉलम को कर्मचारी तालिका में जोड़ते, तो यह अतिरेक उत्पन्न करेगा यदि कर्मचारी विभिन्न परियोजनाओं में एक से अधिक भूमिकाएं निभाता है। संयोजन तालिका इस भिन्नता को अलग करती है।
⚖️ तकनीक 3: सामान्यीकरण और डेटा अखंडता
M:N संबंधों को हल करना केवल तालिकाओं को जोड़ने के बारे में नहीं है; यह डेटा विचलनों को रोकने के लिए सामान्यीकरण सिद्धांतों का पालन करने के बारे में है। तृतीय सामान्य रूप (3NF) अधिकांश लेनदेन प्रणालियों के लिए मानक लक्ष्य है।
तृतीय सामान्य रूप (3NF) की आवश्यकताएं:
- तालिका को द्वितीय सामान्य रूप (2NF) में होना चाहिए।
- सभी गैर-कुंजी विशेषताओं को केवल मुख्य कुंजी पर निर्भर होना चाहिए।
संयोजन तालिका बनाकर, आप सुनिश्चित करते हैं कि संबंध डेटा संयोजन तालिका की संयुक्त कुंजी पर निर्भर होता है, न कि व्यक्तिगत एकक कुंजी पर। इससे स्थानांतरित निर्भरता को दूर किया जाता है।
संदर्भात्मक अखंडता:
संयोजन तालिका में विदेशी कुंजी सीमाएं आवश्यक हैं। वे निम्न नियमों को लागू करती हैं:
- एक
पुस्तक_आईडीउधार लेने के लॉग में उपस्थित होना चाहिए पुस्तकें तालिका में। - एक
प्रेक्षक_आईडीलेन-देन लॉग में मौजूद होना चाहिए प्रेक्षक तालिका में।
यह अनाथ रिकॉर्ड्स से बचाता है। आप किसी पुस्तक के लेन-देन की रिकॉर्डिंग नहीं कर सकते जो कैटलॉग में उपलब्ध नहीं है। डेटाबेस इंजन इसे हटाने पर कैस्केड या प्रतिबंधित कार्रवाई के माध्यम से लागू करते हैं।
📊 संबंध प्रकारों की तुलना
संबंध प्रकारों के बीच अंतरों को दृश्याकृत करना सही मॉडलिंग रणनीति चुनने में मदद करता है। नीचे दी गई तालिका संरचनात्मक आवश्यकताओं और कार्यान्वयन की जटिलता का सारांश प्रस्तुत करती है।
| संबंध प्रकार | भौतिक कार्यान्वयन | प्राथमिक कुंजी स्थान | जटिलता |
|---|---|---|---|
| एक से एक (1:1) | एक तालिका में विदेशी कुंजी | कोई भी तालिका | कम |
| एक से बहुत (1:M) | बहुत वाली तालिका में विदेशी कुंजी | प्राथमिक तालिका | मध्यम |
| बहुत से बहुत (M:N) | अलग जंक्शन तालिका | जंक्शन तालिका (संयुक्त) | उच्च |
जैसा कि दिखाया गया है, M:N संबंध को सबसे अधिक संरचनात्मक ओवरहेड की आवश्यकता होती है। हालांकि, यह ओवरहेड डेटा अखंडता के लिए आवश्यक है। एक प्रश्न के दौरान अतिरिक्त जॉइन की लागत अक्सर खराब रूप से मॉडल किए गए स्कीमा में डेटा असंगति की लागत से अधिक होती है।
🚀 प्रदर्शन पर विचार
एक जंक्शन टेबल को जोड़ने से आपके प्रश्नों में एक अतिरिक्त परत जोड़ी जाती है। डेटा प्राप्त करते समय, आपको दो टेबल के बजाय तीन टेबल को जोड़ना होगा। उच्च आयतन वाले सिस्टम में, यदि सही तरीके से प्रबंधित नहीं किया गया, तो यह प्रदर्शन पर प्रभाव डाल सकता है।
- इंडेक्सिंग:जंक्शन टेबल में प्रत्येक विदेशी कुंजी को इंडेक्स किया जाना चाहिए। इससे डेटाबेस इंजन को एक विशिष्ट एकाधिक इकाई के लिए पंक्तियों को पूरी जंक्शन टेबल को स्कैन किए बिना तेजी से खोजने में सक्षम बनाया जाता है।
- कॉम्पोजिट इंडेक्स: कुछ मामलों में, दोनों विदेशी कुंजियों के संयोजन पर इंडेक्स बनाना अलग-अलग इंडेक्स की तुलना में अधिक कुशल होता है। यह उन प्रश्नों का समर्थन करता है जो दोनों एकाधिक इकाइयों के साथ एक साथ फ़िल्टर करते हैं।
- पढ़ना बनाम लिखना: यदि संबंध गतिशील हैं, तो जंक्शन टेबल आमतौर पर लेखन-भारी होते हैं। रिपोर्ट बनाते समय ये पढ़ने-भारी होते हैं। सुनिश्चित करें कि आपकी इंडेक्सिंग रणनीति आपके एप्लिकेशन के प्रमुख ऑपरेशन पैटर्न का समर्थन करती है।
⚠️ सामान्य त्रुटियाँ और समाधान
यहाँ तक कि अनुभवी मॉडलर भी कार्डिनैलिटी को हल करते समय गलतियाँ करते हैं। सामान्य त्रुटियों के बारे में जागरूकता बाद में महत्वपूर्ण रिफैक्टरिंग समय बचा सकती है।
1. “एक कॉलम” की गलती
एक कॉलम में कमा-अलग किए गए मानों (जैसे “1, 2, 3”) का उपयोग करके एक साथ कई आईडी को संग्रहीत करने की कोशिश करना। यह डेटाबेस सिद्धांतों का उल्लंघन करता है और स्ट्रिंग पार्सिंग फंक्शन के बिना प्रश्न करना असंभव बना देता है। हमेशा प्रत्येक संबंध के लिए अलग पंक्ति का उपयोग करें।
2. अतिरिक्त विशेषताएँ
आवश्यकता के बिना मूल एकाधिक इकाइयों से विशेषताओं को जंक्शन टेबल में कॉपी करना। यदि एक विशेषता एकाधिक इकाई से संबंधित है (जैसे एक छात्र का नाम), तो वह छात्र टेबल में होना चाहिए, न कि एनरोलमेंट टेबल में। केवल उस लिंक का वर्णन करने वाले डेटा को ही रखें।
3. नलता को नजरअंदाज करना
जब विदेशी कुंजी को अनिवार्य होना चाहिए, तो उसे नल (NULL) के लिए अनुमति देना। यदि संबंध अनिवार्य है (जैसे एक ऑर्डर को एक ग्राहक की आवश्यकता है), तो विदेशी कुंजी को NULL मान की अनुमति नहीं होनी चाहिए। इससे व्यवसाय नियमों को डेटाबेस स्तर पर लागू किया जाता है।
4. चक्रीय संदर्भ
अनावश्यक रूप से खुद को संदर्भित करने वाली जंक्शन टेबल बनाना। सुनिश्चित करें कि जंक्शन टेबल केवल संबंध में शामिल दो अलग-अलग एकाधिक इकाइयों को जोड़ती है। ऐसे लूप बनाने से बचें जो कोई कार्यात्मक उद्देश्य नहीं रखते।
🎨 दृश्य प्रतिनिधित्व की शीर्ष विधियाँ
जब आप अपने ईआरडी का दस्तावेज़ीकरण करते हैं, तो स्पष्टता सर्वोच्च महत्व की होती है। दृश्य प्रतिनिधित्व को किसी भी आरेख पढ़ने वाले व्यक्ति को तुरंत संरचना के समाधान की जानकारी देनी चाहिए।
- जंक्शन टेबल को लेबल करें:टेबल का वर्णनात्मक नाम रखें। “Table3” के बजाय “Student_Course_Enrollment” का उपयोग करें।
- कार्डिनैलिटी को दर्शाएं:जंक्शन टेबल को मूल एकाधिक इकाइयों से जोड़ने वाली रेखाओं को स्पष्ट रूप से चिह्नित करें। मूल एकाधिक इकाइयों के दृष्टिकोण से “बहुत” संबंध को दर्शाने के लिए जंक्शन टेबल की ओर चिड़िया के पैर (क्राउज़ फुट) का उपयोग करें।
- विशेषताएँ दिखाएँ:यदि जंक्शन टेबल में विशेषताएँ (जैसे “ग्रेड” या “तारीख”) हैं, तो उन्हें आरेख में स्पष्ट रूप से सूचीबद्ध करें। इससे यह उजागर होता है कि संबंध केवल एक लिंक से अधिक है।
- अलग-अलग रेखा शैलियों का उपयोग करें: कुछ मॉडलिंग टूल वैकल्पिक संबंधों के लिए डैश्ड लाइन और अनिवार्य संबंधों के लिए सॉलिड लाइन की अनुमति देते हैं। यहाँ संगतता को समझने में मदद करती है।
🔄 पुनरावर्ती संबंध और एम:एन
कभी-कभी, एक ही एकाधिक इकाई के भीतर एक बहुत-से-बहुत संबंध होता है। उदाहरण के लिए, एक कर्मचारी कई अन्य को प्रबंधित कर सकते हैं कर्मचारी, और उन कर्मचारी अन्य को प्रबंधित कर सकते हैं। यह एक पुनरावृत्तिक M:N संबंध है।
निराकरण मानक M:N संबंध के समान रहता है। आप अभी भी एक संयोजन तालिका बनाते हैं, लेकिन उस तालिका में दोनों विदेशी कुंजियाँ एक ही संस्था की प्राथमिक कुंजी को संदर्भित करती हैं।
- संस्था: कर्मचारी
- संयोजन तालिका: कर्मचारी_प्रबंधन
- FK1: प्रबंधक_आईडी (कर्मचारी को संदर्भित करता है)
- FK2: अधीनस्थ_आईडी (कर्मचारी को संदर्भित करता है)
इस संरचना के कारण जटिल संगठनात्मक पदानुक्रमों को नियमितता नियमों के उल्लंघन किए बिना संभव बनता है। यह प्रश्नों को प्रबंधन की गहराई के कई स्तरों तक पहुँचने की अनुमति देता है।
🛡️ डेटा सीमाएँ और व्यापार नियम
तकनीकी सीमाएँ पर्याप्त नहीं हैं; व्यापार नियमों को लागू किया जाना चाहिए। एक संयोजन तालिका इन नियमों को लागू करने के लिए एक प्राकृतिक स्थान प्रदान करती है।
- एकल सीमाएँ: सुनिश्चित करें कि कोई विशिष्ट संबंध दो बार नहीं बनाया जा सकता है, जब तक इच्छा न हो। उदाहरण के लिए, एक छात्र को एक ही सेमेस्टर में एक ही कोर्स सेक्शन में दो बार नामांकित नहीं किया जाना चाहिए। स्टूडेंट_आईडी और कोर्स_आईडी के संयोजन पर एक एकल सीमा इसे लागू करती है।
- जाँच सीमाएँ: संख्यात्मक डेटा की पुष्टि करें। उदाहरण के लिए, प्रोजेक्ट संयोजन तालिका में “घंटे_आवंटित” शून्य से अधिक और 40 से कम होना चाहिए।
- ट्रिगर्स: जटिल प्रणालियों में, सारांश तालिकाओं को अपडेट करने के लिए ट्रिगर्स की आवश्यकता हो सकती है। यदि संयोजन तालिका में परिवर्तन होता है, तो मातृ संस्था में एक सारांश तालिका (उदाहरण के लिए, “कर्मचारी_प्रति_कुल_प्रोजेक्ट”) को स्वतः अपडेट करने की आवश्यकता हो सकती है।
📈 मॉडल का विकास
मॉडल आवश्यकताओं में परिवर्तन के साथ विकसित होते हैं। एक संबंध जो बहु-से-बहु के रूप में शुरू होता है, व्यापार नियम में परिवर्तन के कारण एक-से-बहु में सरल हो सकता है। उदाहरण के लिए, यदि नीति में परिवर्तन होता है जिसमें छात्र केवल एक समय में एक कोर्स में ही नामांकित हो सकता है, तो संयोजन तालिका को छात्र तालिका में वापस मिला लिया जा सकता है।
हालांकि, संयोजन तालिका से शुरुआत करना आमतौर पर सुरक्षित होता है। यह अधिकतम लचीलापन को स्थान देता है। यदि बाद में आवश्यकता परिवर्तन होती है और बहु-नामांकन की अनुमति दी जाती है, तो स्कीमा पहले से तैयार होता है। यदि आप मिलाए गए तालिका से शुरुआत करते हैं, तो बाद में रिफैक्टर करना होगा।
📝 मुख्य बातों का सारांश
बहु-से-बहु संबंधों को हल करना डेटाबेस डिजाइन में एक मूल कौशल है। इसके लिए मध्यवर्ती संरचना के निर्माण की आवश्यकता होती है ताकि डेटा अखंडता बनाए रखी जा सके और प्रभावी प्रश्नों का समर्थन किया जा सके। संयोजन तालिका मानक समाधान है, जो जटिल संबंधों को प्रबंधनीय एक-से-बहु संबंधों में तोड़ती है।
- हमेशा M:N को हल करें: कभी भी एक ही कॉलम में कई विदेशी कुंजियों को संग्रहीत करने की कोशिश न करें।
- मिश्रित कुंजियों का उपयोग करें: विदेशी कुंजियों का संयोजन अक्सर संबंध के लिए एकमात्र पहचानकर्ता के रूप में कार्य करता है।
- संबंध डेटा स्टोर करें:जंक्शन टेबल में लिंक के लिए विशिष्ट लक्षण रखें।
- विदेशी कुंजियों की इंडेक्सिंग करें: प्रदर्शन जंक्शन टेबल की पंक्तियों के त्वरित खोज पर निर्भर करता है।
- प्रतिबंधों को लागू करें: अमान्य डेटा को रोकने के लिए यूनिक प्रतिबंधों और विदेशी कुंजी संदर्भों का उपयोग करें।
इन तकनीकों का पालन करके, आप सुनिश्चित करते हैं कि आपकी डेटाबेस स्कीमा बदलाव के प्रति लचीली है और जटिल डेटा इंटरैक्शन को संभालने में सक्षम है। डिजाइन चरण के दौरान उचित मॉडलिंग में निवेश की गई मेहनत, पूरे प्रणाली के जीवनचक्र में रखरखाव और प्रदर्शन में लाभ के रूप में लौटती है।