











सोशल मीडिया प्लेटफॉर्म के लिए एक बलिया डेटाबेस स्कीमा डिज़ाइन करने के लिए उपयोगकर्ताओं के बीच बातचीत, साझाकरण और जानकारी के उपयोग के तरीके को गहन रूप से समझने की आवश्यकता होती है। पारंपरिक लेनदेन प्रणालियों के विपरीत, सोशल नेटवर्क में जटिल बहु-से-बहु संबंध, पुनरावर्ती डेटा संरचनाएँ और विशाल स्केल की आवश्यकताएँ शामिल होती हैं। एंटिटी-रिलेशनशिप डायग्राम (ईआरडी) इन बातचीत के लिए ब्लूप्रिंट के रूप में कार्य करता है, जिससे डेटा अखंडता सुनिश्चित होती है और तेजी से विकास का समर्थन होता है। यह गाइड सोशल मीडिया डेटा के प्रभावी मॉडलिंग के लिए महत्वपूर्ण रणनीतियों का अध्ययन करता है।
मूल समस्या को समझना 🧩
सोशल मीडिया एप्लिकेशन केवल सामग्री के भंडार के रूप में नहीं हैं; वे संबंधों के गतिशील नेटवर्क हैं। एक साधारण ब्लॉग पोस्ट सोशल मीडिया फीड से बहुत अलग होता है क्योंकि इसमें एंगेजमेंट परत होती है। लाइक, शेयर, कमेंट और फॉलो करने से एक जाल बनता है जिसे सही तरीके से मॉडल करने की आवश्यकता होती है। खराब मॉडलिंग के कारण कम गति वाले क्वेरी प्रदर्शन, डेटा असंगति और न्यूज़ फीड या दोस्त सुझाव जैसी विशेषताओं को लागू करने में कठिनाई होती है।
- आयतन:सोशल प्लेटफॉर्म प्रति सेकंड मिलियनों घटनाओं का उत्पादन करते हैं।
- वेग:डेटा वास्तविक समय में स्ट्रीम के रूप में आता है जिसे तुरंत प्रसंस्कृत किया जाना चाहिए।
- विविधता:सामग्री में पाठ, छवियाँ, वीडियो, मेटाडेटा और स्थान डेटा शामिल हैं।
- संबंध: मूल मूल्य संबंधों में संबंधित एंटिटी के बीच है।
ईआरडी बनाते समय, मुख्य लक्ष्य नॉर्मलाइजेशन और प्रदर्शन के बीच संतुलन बनाए रखना है। अत्यधिक नॉर्मलाइजेशन के कारण उच्च आवृत्ति वाले पढ़ने के लिए जॉइन बहुत महंगे हो सकते हैं। अत्यधिक डेनॉर्मलाइजेशन के कारण डेटा अतिरिक्तता और संगति की समस्याएँ उत्पन्न हो सकती हैं। निम्नलिखित खंड इस क्षेत्र को परिभाषित करने वाली विशिष्ट एंटिटी और संबंधों का विवरण प्रदान करते हैं।
मूल एंटिटी को परिभाषित करना 🔑
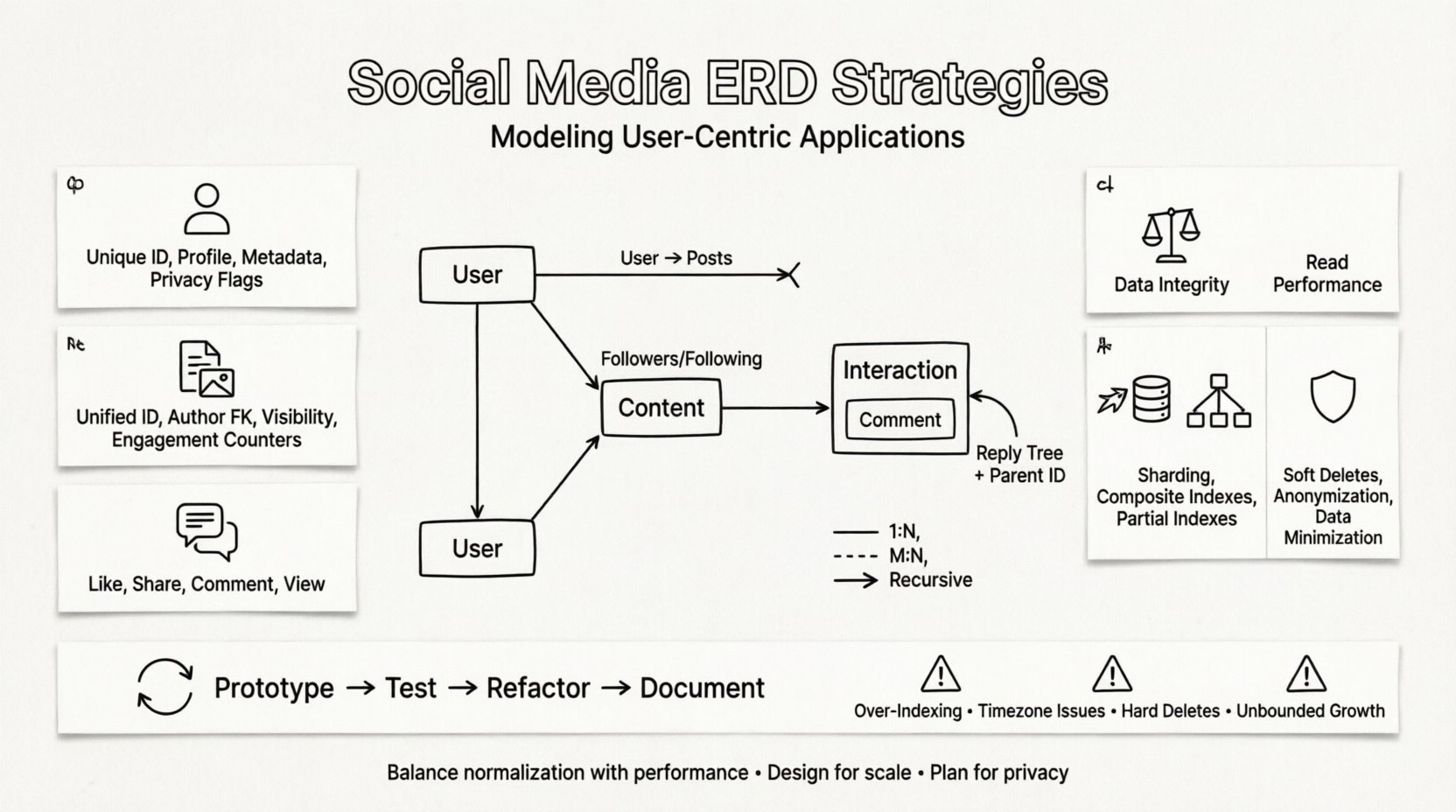
प्रत्येक सोशल मीडिया प्रणाली कुछ मूलभूत एंटिटी के चारों ओर घूमती है। इन्हें सही तरीके से पहचानना एक स्केलेबल स्कीमा बनाने का पहला चरण है। ये एंटिटी एप्लिकेशन के मूल निर्माण ब्लॉक का प्रतिनिधित्व करती हैं।
1. उपयोगकर्ता एंटिटी 👤
उपयोगकर्ता नेटवर्क में केंद्रीय नोड है। इस एंटिटी में प्रमाणीकरण विवरण, प्रोफाइल जानकारी और पसंदीदा विवरण स्टोर किए जाते हैं। इसे लाखों रिकॉर्ड को कुशलतापूर्वक संभालने के लिए डिज़ाइन किया जाना चाहिए।
- एकल पहचानकर्ता: प्रदर्शन और गोपनीयता के लिए प्राकृतिक की के बजाय सरोगेट की को प्राथमिकता दी जाती है।
- प्रोफाइल डेटा: नाम, बायो, एवाटार और सत्यापन स्थिति।
- मेटाडेटा: खाता बनाने, अंतिम लॉगिन और हटाए जाने के लिए समयचिह्न।
- गोपनीयता झंडियाँ: अन्य उपयोगकर्ताओं के लिए डेटा की दृश्यता को नियंत्रित करने वाली सेटिंग्स।
2. सामग्री एंटिटी 📝
सामग्री सोशल प्लेटफॉर्म का ईंधन है। इसमें पोस्ट, कहानियाँ, छवियाँ, वीडियो और कमेंट शामिल हैं। एक लचीला स्कीमा आवश्यक है क्योंकि विभिन्न प्रकार की सामग्री के अलग-अलग लक्षण होते हैं।
- एकीकृत आईडी: विशिष्ट सामग्री टेबल से जुड़ने वाली सामान्य आईडी।
- लेखक संदर्भ: उपयोगकर्ता संस्था से जुड़ने वाला विदेशी कुंजी।
- दृश्यता सीमा: सार्वजनिक, निजी, मित्रों तक सीमित, या विशिष्ट समूह।
- एंगेजमेंट गिनतियाँ: प्रश्न लोड को कम करने के लिए पसंद और टिप्पणियों की कैश की गई गिनती।
3. इंटरैक्शन एंटिटी 💬
इंटरैक्शन सामग्री या अन्य उपयोगकर्ताओं पर उपयोगकर्ताओं द्वारा की गई क्रियाओं का प्रतिनिधित्व करते हैं। ये उच्च आयतन वाले लेनदेन हैं जो अक्सर प्रणाली की प्रदर्शन आवश्यकताओं को निर्धारित करते हैं।
- पसंद: उपयोगकर्ता और सामग्री के बीच एक द्विआधारी अवस्था।
- साझा करें: एक नए संदर्भ के साथ मूल सामग्री का संदर्भ।
- टिप्पणी: सामग्री के साथ एक पदानुक्रमिक या धागाबंद संबंध।
- दृश्य: उच्च आयतन और अखंडता के लिए कम महत्व के कारण अक्सर अलग से लॉग किया जाता है।
संबंधों का मॉडलिंग 🕸️
सोशल मीडिया की वास्तविक जटिलता संस्थाओं के बीच संबंधों में निहित है। मानक संबंधात्मक मॉडलिंग तकनीकें अक्सर सोशल ग्राफ की पुनरावृत्ति प्रकृति के साथ कठिनाई में पड़ती हैं। इन जुड़ावों को कैसे संग्रहीत किया जाता है, इस पर विशेष ध्यान देने की आवश्यकता होती है।
एक से बहुत के संबंध
ये सबसे आम और सीधे-सादे हैं। उदाहरण के लिए, एक उपयोगकर्ता के बहुत सारे पोस्ट हो सकते हैं, लेकिन एक पोस्ट केवल एक उपयोगकर्ता के संबंध में होता है। इसे बच्चे की तालिका में विदेशी कुंजी के उपयोग से मॉडल किया जाता है।
- उदाहरण: पोस्ट तालिका में उपयोगकर्ता ID।
- लाभ: एक विशिष्ट प्रोफाइल के लिए सभी पोस्ट का त्वरित प्राप्त करना।
- प्रतिबंध: संदर्भात्मक अखंडता को स्वचालित रूप से लागू करता है।
बहुत से से बहुत के संबंध
फॉलोअर्स और फॉलोइंग का उदाहरण प्राचीन है। एक उपयोगकर्ता बहुत से अन्य लोगों को फॉलो करता है, और एक उपयोगकर्ता बहुत से अन्य लोगों द्वारा फॉलो किया जाता है। इस संबंध को हल करने के लिए एक संयोजन तालिका की आवश्यकता होती है।
- संयोजन तालिका: उपयोगकर्ता ID A और उपयोगकर्ता ID B को समावेश करती है।
- समय-सारणी: जब अनुसरण क्रिया हुई।
- स्थिति: रुके हुए, स्वीकृत या अवरुद्ध।
- प्रदर्शन: दोनों विदेशी कुंजियों पर इंडेक्सिंग महत्वपूर्ण है।
पुनरावृत्ति संबंध
कुछ संबंध एक ही संस्था प्रकार को शामिल करते हैं। एक टिप्पणी में उत्तरों के उत्तर हो सकते हैं। इससे एक वृक्ष संरचना बनती है जिसे मानक संबंधात्मक मॉडल में प्रश्न करना कठिन होता है।
- माता-पिता का ID: टिप्पणी ID की ओर इशारा करने वाला विदेशी कुंजी।
- गहराई: पुनरावृत्ति की गहराई सीमित करने से अनंत लूप से बचा जा सकता है।
- सामग्रीकृत मार्ग: तेजी से अनुसरण के लिए वृक्ष के मार्ग को संग्रहीत करना।
| संबंध प्रकार | उदाहरण | कार्यान्वयन रणनीति | प्रदर्शन प्रभाव |
|---|---|---|---|
| एक से बहुत | उपयोगकर्ता – पोस्ट | बच्चे में विदेशी कुंजी | कम (मानक इंडेक्सिंग) |
| बहुत से बहुत | उपयोगकर्ता – अनुसरण करता है | संयोजन तालिका | मध्यम (जॉइन ओवरहेड) |
| पुनरावृत्ति | टिप्पणी – उत्तर | स्वयं-संदर्भित विदेशी कुंजी | उच्च (जटिल प्रश्न) |
| संयोजक | टैग – उपयोगकर्ता | मिश्रित कुंजियाँ | मध्यम (खोज भारी) |
सामान्यीकरण बनाम असामान्यीकरण ⚖️
सोशल मीडिया प्रणालियों में, पढ़ने के प्रदर्शन को लिखने के प्रदर्शन से अक्सर अधिक महत्व दिया जाता है। उपयोगकर्ता चाहते हैं कि फीड तुरंत लोड हो, भले ही मिलियनों रिकॉर्ड शामिल हों। इसके लिए सामान्यीकरण और असामान्यीकरण के बीच सावधानीपूर्वक संतुलन आवश्यक है।
सामान्यीकरण के लिए तर्क
सामान्यीकरण डेटा अखंडता सुनिश्चित करता है और अतिरिक्तता को कम करता है। यह मूल डेटा के लिए आवश्यक है जो अक्सर नहीं बदलता है।
- डेटा सुसंगतता: अपडेट एक ही स्थान पर होते हैं।
- स्टोरेज दक्षता: कम दोहराए गए डेटा स्टोरेज।
- रखरखाव: व्यापार नियमों को लागू करना आसान होता है।
असामान्यीकरण के लिए तर्क
असामान्यीकरण पढ़ने के दौरान आवश्यक जॉइन्स की संख्या को कम करने के लिए डेटा की प्रतिलिपि बनाने में शामिल होता है। यह सोशल फीड में सामान्य है।
- पढ़ने की गति: कम जॉइन्स का मतलब है तेज़ क्वेरी निष्पादन।
- कैशिंग: संयुक्त गिनती (उदाहरण के लिए, कुल लाइक) सीधे स्टोर की जाती है।
- लेखन ओवरहेड: अपडेट को सभी प्रतियों तक पहुँचाना होता है।
हाइब्रिड दृष्टिकोण
एक व्यावहारिक रणनीति में मुख्य स्कीमा को सामान्यीकृत करने के साथ-साथ अक्सर पढ़े जाने वाले मापदंडों को असामान्यीकृत करना शामिल होता है। उदाहरण के लिए, पोस्ट तालिका में उपयोगकर्ता ID के साथ-साथ उपयोगकर्ता नाम भी स्टोर करें। इससे पोस्ट प्रदर्शित करते समय जॉइन से बचा जा सकता है, हालांकि अवसर पर सिंक्रनाइज़ेशन तर्क की आवश्यकता होती है।
ईआरडी के लिए स्केलेबिलिटी रणनीतियाँ 🚀
जैसे-जैसे उपयोगकर्ता आधार बढ़ता है, स्कीमा को बढ़ी हुई लोड को संभालने के लिए विकसित होना चाहिए। ऊर्ध्वाधर स्केलिंग की सीमाएँ हैं; क्षैतिज स्केलिंग के लिए विशिष्ट स्कीमा विचारों की आवश्यकता होती है।
पार्टीशनिंग
पार्टीशनिंग बड़ी तालिकाओं को छोटे, प्रबंधनीय टुकड़ों में बाँटती है। सोशल मीडिया में, डेटा अक्सर उपयोगकर्ता आईडी या तारीख के आधार पर पार्टीशन किया जाता है।
- क्षैतिज पार्टीशनिंग: आईडी रेंज के आधार पर उपयोगकर्ताओं को अलग-अलग शर्ड में बाँटना।
- उर्ध्वाधर पार्टीशनिंग: कम उपयोग किए जाने वाले कॉलम को अलग टेबल में स्थानांतरित करना।
- तारीख विभाजन:पुराने पोस्ट को कोल्ड स्टोरेज टेबल में आर्काइव करना।
इंडेक्सिंग रणनीतियाँ
इंडेक्स किसी प्रश्न के प्रदर्शन के लिए बहुत महत्वपूर्ण हैं, लेकिन लेखन को धीमा कर देते हैं। इंडेक्सिंग के लिए एक रणनीतिक दृष्टिकोण की आवश्यकता होती है।
- संयुक्त इंडेक्स:सामान्य प्रश्न पैटर्न को कवर करना (उदाहरण के लिए, उपयोगकर्ता ID + समय चिह्न)।
- आंशिक इंडेक्स:केवल संबंधित पंक्तियों को इंडेक्स करना (उदाहरण के लिए, सक्रिय पोस्ट)।
- खोज इंडेक्स:सामग्री खोज के लिए पूर्ण-पाठ खोज इंजन का उपयोग करना।
गोपनीयता और सुसंगतता के मामले 🛡️
आधुनिक डेटा मॉडलिंग में ग्रेडी और सीसीपीए जैसे गोपनीयता नियमों को ध्यान में रखना आवश्यक है। स्कीमा डिजाइन डेटा को अनामित करने या हटाने की आसानी को प्रभावित करता है।
भूलने का अधिकार
उपयोगकर्ता अपने डेटा के हटाए जाने की अनुरोध कर सकते हैं। ईआरडी को रेफरेंशियल इंटीग्रिटी को नष्ट किए बिना कैस्केडिंग हटाने या सॉफ्ट हटाने का समर्थन करना चाहिए।
- सॉफ्ट हटाना:पंक्तियों को हटाने के बजाय “is_deleted” फ्लैग जोड़ना।
- अनाथ डेटा:एक हटाए गए उपयोगकर्ता को संदर्भित करने वाले डेटा का प्रबंधन करना।
- अनामीकरण:व्यक्तिगत पहचानकर्ताओं को हैश के साथ प्रतिस्थापित करना।
डेटा न्यूनीकरण
केवल तब डेटा स्टोर करें जब वह बिल्कुल आवश्यक हो। अत्यधिक मेटाडेटा संग्रह स्टोरेज लागत और गोपनीयता जोखिम बढ़ाता है।
- संरक्षण नीतियाँ:एक निर्धारित अवधि के बाद लॉग्स को स्वचालित रूप से हटाना।
- विस्तृत अनुमतियाँ:पंक्ति स्तर पर पहुंच नियंत्रण।
- एन्क्रिप्शन:संवेदनशील क्षेत्रों को आराम के समय एन्क्रिप्ट किया गया है।
मेटाडेटा और लॉग्स का प्रबंधन 📉
मुख्य एंटिटी के बाहर, प्रणालियाँ विशाल मात्रा में मेटाडेटा उत्पन्न करती हैं। इसमें विश्लेषण, त्रुटि लॉग और ऑडिट ट्रेल शामिल हैं। इन्हें मुख्य लेनदेन योजना में भारी नहीं होने देना चाहिए।
चिंता के विभाजन
लेनदेन डेटाबेस को साफ रखें। भारी लॉगिंग और विश्लेषण को अलग प्रणालियों पर लोड करें।
- घटना प्रवाह:असिंक्रोनस लॉगिंग के लिए संदेश भंडार का उपयोग करें।
- विश्लेषण तालिकाएँ:ऐतिहासिक प्रवृत्तियों के लिए अलग तालिकाएँ।
- समय-श्रृंखला डेटा:समय के साथ मापदंडों के लिए विशिष्ट भंडारण।
पुनरावृत्त डिज़ाइन प्रक्रिया 🔄
पहली ड्राफ्ट में ईआरडी दुर्लभ रूप से पूर्ण होते हैं। सोशल मीडिया की आवश्यकताएँ नए फीचर्स के लिए तेजी से बदलती हैं। डिज़ाइन प्रक्रिया को पुनरावृत्त होना चाहिए।
- प्रोटोटाइप:मुख्य फीचर के लिए एक न्यूनतम लागू योजना बनाएं।
- परीक्षण:वास्तविक डेटा आयतन के साथ लोड परीक्षण करें।
- पुनर्गठन:प्रदर्शन की सीमाओं के आधार पर संबंधों को समायोजित करें।
- दस्तावेज़ीकरण:भविष्य के डेवलपर्स के लिए अद्यतन आरेख बनाए रखें।
बचने के लिए सामान्य गलतियाँ ⚠️
यहां तक कि अनुभवी वास्तुकार सोशल डेटा के मॉडलिंग में गलतियां करते हैं। इन पैटर्न को पहचानने से भविष्य की समस्याओं को रोकने में मदद मिलती है।
- अत्यधिक सूचकांकन:बहुत सारे सूचकांक लेखन संचालन को महत्वपूर्ण रूप से धीमा कर देते हैं।
- समय क्षेत्रों के बिना ध्यान देना:समय क्षेत्र के बिना समय टैग स्टोर करने से भ्रम उत्पन्न होता है।
- कड़े मान:योजना में व्यापार तर्क को एम्बेड न करें (उदाहरण के लिए, विशिष्ट स्थिति मान)।
- सॉफ्ट डिलीट को नजरअंदाज करना:हार्ड डिलीट नेटवर्क के आसपास विदेशी की सीमाओं को तोड़ सकते हैं।
- असीमित वृद्धि: पुराने डेटा को आर्काइव न करने से टेबल ब्लाउट होता है।
भविष्य के विकास के लिए अंतिम विचार 🔮
सोशल मीडिया प्लेटफॉर्म बनाना एक लंबे समय तक का प्रयास है। डेटा मॉडल को बिना पूरी तरह से फिर से लिखे बदलावों को स्वीकार करने के लिए पर्याप्त लचीला होना चाहिए। स्पष्टता, स्केलेबिलिटी और रखरखाव पर ध्यान केंद्रित करें। वास्तविक दुनिया के उपयोग के पैटर्न के खिलाफ स्कीमा की नियमित समीक्षा सुनिश्चित करती है कि प्रणाली बढ़ते हुए भी दृढ़ बनी रहे।
- संस्करण निर्धारण:पीछे की ओर संगतता के समर्थन करने वाले स्कीमा माइग्रेशन की योजना बनाएं।
- निगरानी:स्कीमा की कमजोरियों को जल्दी से पहचानने के लिए प्रश्न प्रदर्शन का अनुसरण करें।
- समुदाय की प्रतिक्रिया:इंजीनियरिंग टीम द्वारा डेटा का वास्तविक उपयोग कैसे किया जाता है, इस पर ध्यान दें।
इन रणनीतियों का पालन करके विकासकर्ता उपयोगकर्ता-केंद्रित एप्लिकेशन के लिए एक ठोस आधार बना सकते हैं। ईआरडी केवल एक आरेख नहीं है; यह पूरे प्लेटफॉर्म की संरचनात्मक अखंडता है। अब ध्यान से योजना बनाने से बाद में महत्वपूर्ण तकनीकी देनदारी को रोका जा सकता है।