











成長を支えるテクノロジー・アーキテクチャを構築するには、部品を単に組み合わせるだけでは不十分です。需要を予測し、レジリエンスを確保し、圧力下でもパフォーマンスを維持する戦略的なアプローチが求められます。組織がスケーラビリティを追求する際、単にスピードを求めるのではなく、耐久性と適応性を求めるのです。このガイドでは、スケーラブルなインフラストラクチャのためのテクノロジー・アーキテクチャを計画するために必要な原則、フレームワーク、構造的要素について探求します。既存の手法、たとえばTOGAFフレームワークのようなものが、特定のベンダー製品に依存せずにこれらの意思決定を導く方法についても詳しく検討します。
スケーラビリティとは、リソースを追加することで負荷の増加に対応できるシステムの能力を指します。しかし、真のアーキテクチャ的スケーラビリティとは、成長が安定性を損なわないようにシステムを設計することを意味します。これには、非機能要件、データフロー、ハードウェアとソフトウェアのレイヤー間の相互作用について深い理解が必要です。基盤となる原則に注目することで、チームはビジネスニーズに合わせて自然に拡張できる環境を構築できます。
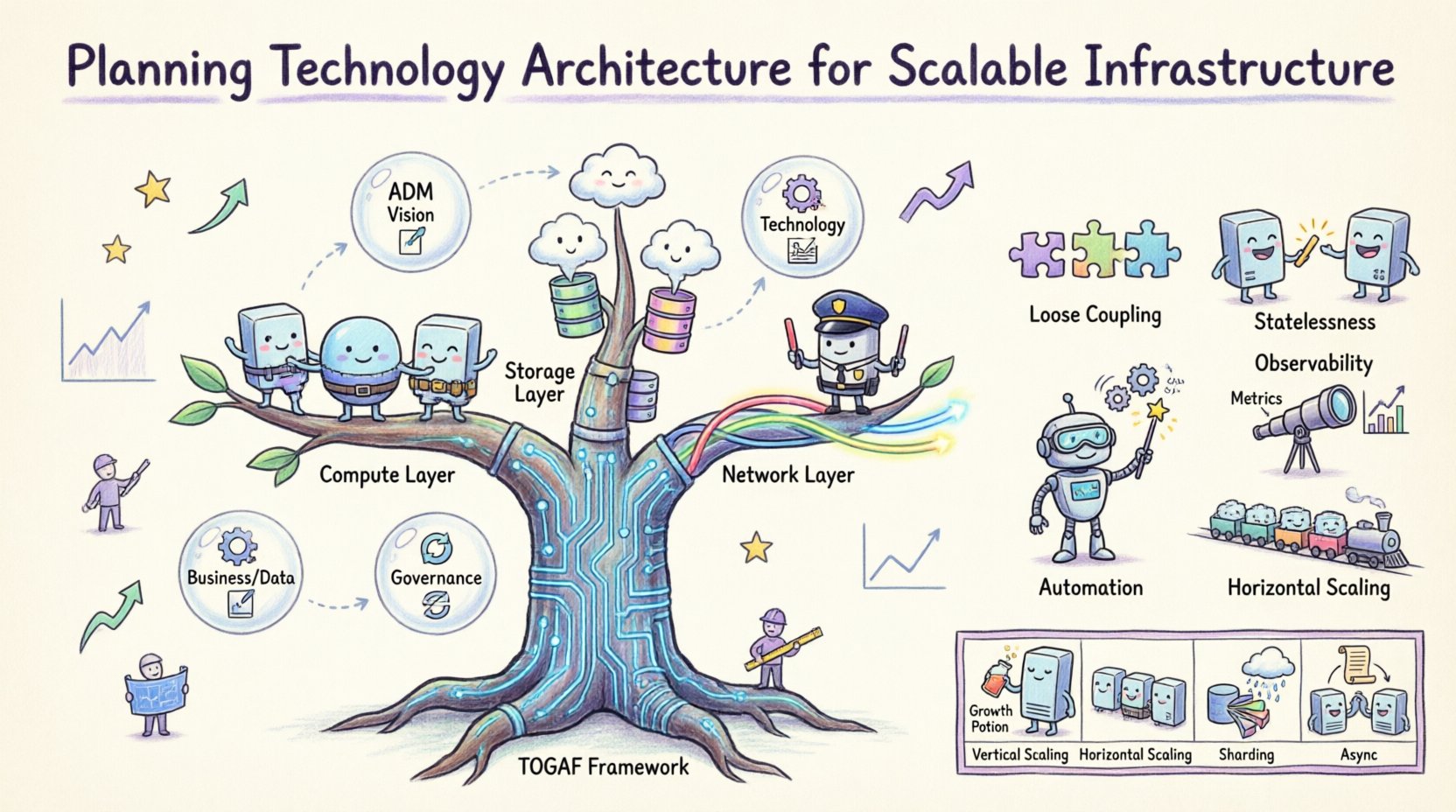
インフラストラクチャの文脈におけるTOGAFの理解 🧭
オープン・グループ・アーキテクチャ・フレームワーク(TOGAF)は、企業情報アーキテクチャの設計、計画、実装、統治に向けた構造的なアプローチを提供します。高レベルのビジネス戦略と関連づけられることが多くありますが、アーキテクチャ開発手法(ADM)の適用は、インフラストラクチャ計画において非常に効果的です。TOGAFは技術的決定がビジネス目標と整合することを保証し、通信や効率的なスケーリングができないスロットル化されたシステムの創出を防ぎます。
TOGAFをテクノロジー・アーキテクチャに適用する際、焦点はテクノロジー・アーキテクチャ段階に移ります。この段階では、優先順位の高いビジネスプロセスを支援するために必要なハードウェア、ソフトウェア、ネットワークの能力を定義します。論理的なビジネス要件と物理的な実装の間のギャップを埋めます。
- 整合性: インフラストラクチャが現在および将来のビジネス目標を支援することを保証する。
- 標準化: 共通の技術標準を強制することで、複雑性を低減する。
- 統合: 異なるシステムレイヤー間でのスムーズなデータ交換を促進する。
- 運用性: システムライフサイクル全体における運用および保守を簡素化する。
このようなフレームワークを使用することで、一時的な対応で新たなリソースを追加するような非計画的なスケーリングを防ぎます。代わりに、スケーリングが反応的な修正ではなく、計画的な進化であるという包括的な視点を促進します。
アーキテクチャ開発手法(ADM)サイクル ⏳
ADMサイクルはTOGAF手法の核です。反復的であるため、要件が変化する中でアーキテクトが設計を段階的に洗練できるようになります。インフラストラクチャ計画においては、特定の段階が重要な洞察を提供します。
段階A:アーキテクチャビジョン 🎯
この段階では、範囲と制約を定義することで舞台を整えます。インフラストラクチャ計画においては、予測される成長率、規制要件、パフォーマンスのベンチマークを理解することが含まれます。ステークホルダーは、組織内でのスケーラビリティの定義に合意します。現在の負荷の10倍を処理することを目標とするのか、それとも新たな地理的領域をサポートすることを目標とするのか。これらの問いが技術的ロードマップを形作ります。
段階BおよびC:ビジネスおよび情報システムアーキテクチャ 📊
サーバーやネットワークを設計する前に、それら上で実行されるデータとアプリケーションを理解する必要があります。段階Bではビジネスプロセスを特定します。段階Cではデータアーキテクチャとアプリケーションアーキテクチャを定義します。スケーラビリティは、データの構造化とアクセス方法に大きく依存します。データモデルが硬直的であれば、インフラストラクチャは効果的にスケーリングできません。この段階では、データ量とトランザクション速度に関する論理的要件が早期に文書化されることを保証します。
段階D:テクノロジー・アーキテクチャ 🖥️
これはインフラストラクチャ計画において極めて重要な段階です。段階Cの論理的要件を物理的仕様に変換します。プラットフォーム選定、ネットワークトポロジー、セキュリティアーキテクチャをカバーします。求められるスループットと可用性をサポートする図面(ブループリント)を作成することが目的です。主な検討事項には以下が含まれます:
- 計算リソース: 処理能力とメモリのバランスを決定する。
- ストレージ戦略: ローカルストレージと分散ストレージのどちらを採用するかを決定する。
- ネットワーク帯域幅: ノード間のデータ転送に十分な容量を確保する。
- レジリエンス: 単一障害ポイントを防ぐために冗長性を設計する。
フェーズEからH:機会、計画、ガバナンス、変更 🔄
これらのフェーズは実装と継続的な進化を管理する。スケーラビリティは一度きりの出来事ではなく、継続的なプロセスである。ガバナンスにより、インフラ構造への変更がパフォーマンスを低下させないことが保証される。変更管理により、アーキテクチャは完全な再構築なしに新しい技術や市場の変化に適応できる。
成長のための重要なアーキテクチャ原則 📈
スケーラビリティを達成するためには、特定の原則がすべての意思決定を導く必要がある。これらの原則はガバナンスの役割を果たし、拡張する際にもアーキテクチャが堅牢な状態を保つことを保証する。
- 緩い結合:コンポーネントは独立して動作すべきである。1つのサービスが障害を起こしたりスケーリングが必要になったとしても、他のコンポーネントに影響を与えてはならない。これにより、リソースのターゲット配分が可能になる。
- ステートレス:アプリケーションサーバーはユーザーのセッションデータをローカルに保存してはならない。これにより、どのサーバーでも任意のリクエストを処理でき、負荷分散が簡素化される。
- 自動化:手動でのスケーリングは遅く、エラーを引き起こしやすい。リソースのプロビジョニングや設定プロセスは自動化すべきである。
- 可観測性:システムは自らの健全性について明確な可視性を提供しなければならない。メトリクス、ログ、トレースは、障害を引き起こす前にボトルネックを特定するために不可欠である。
- 水平スケーリング:クラスタにノードを追加することは、単一ノードの性能を向上させるよりも、しばしば効果的かつコスト効率が良い。
これらの原則を遵守することで、技術的負債が減少し、急速な拡張を支える基盤が構築される。
インフラ構成要素の分解 💻
スケーラブルなインフラは、いくつかの相互依存するレイヤーで構成される。各レイヤーは、ボトルネックにならないように、負荷の増加に対応できるように設計されなければならない。
コンピュートレイヤー
コンピュートレイヤーはビジネスロジックが実行される場所である。スケーラビリティの観点では、弾性が焦点となる。リソースは需要に応じて動的にプロビジョニングされるべきである。これには、計算リソースをプールにまとめ、自動的に拡張または縮小できるようにする必要がある。重要な考慮事項は以下の通りである:
- プロセッサアーキテクチャ:特定のワークロードに最適化された命令セットを選択する。
- メモリ管理:スワッピングを伴わずに並行処理を処理できる十分なRAMを確保する。
- コンテナ化:軽量なパッケージングを使用してアプリケーションを隔離し、リソース制限を効率的に管理する。
ストレージレイヤー
データの増加は避けられない。ストレージアーキテクチャは、増加するデータ量を扱いながらも低遅延を維持しなければならない。大規模な環境では、集中型アレイよりも分散型ストレージシステムが好まれる。分散型ストレージは、より高い耐障害性と段階的な容量追加能力を提供する。
- データパーティショニング:複数のノードにデータを分割することで、読み取りと書き込みの負荷を分散する。
- レプリケーション:異なる場所にデータのコピーを作成して、可用性を確保し、アクセスを高速化する。
- キャッシング:頻繁にアクセスされるデータを高速なメモリ層に保存して、データベースの負荷を軽減する。
ネットワーク層
ネットワークは接続組織の役割を果たす。ネットワークが対応できなければ、全体のシステムが遅延する。スケーラブルなネットワーク設計は帯域幅、遅延、ルーティング効率に注力する。
- ロードバランシング:複数のサーバーに着信トラフィックを分散して、過負荷を防ぐ。
- コンテンツ配信:ユーザーに近い場所にコンテンツを配置して、遅延を低減する。
- 帯域幅管理:重要なトラフィックを優先して、必須サービスが応答性を保てるようにする。
表:スケーラビリティのパターンと利用事例
| パターン | 機能 | 最も適している用途 |
|---|---|---|
| 垂直スケーリング | 既存のノードにリソースを追加する | 高い単一ノード性能を必要とするデータベース |
| 水平スケーリング | プールにさらにノードを追加する | Webアプリケーションおよびマイクロサービス |
| シャーディング | データを複数のデータベースに分割する | 大量のトランザクションデータ |
| キャッシング | 高速アクセス用にデータのコピーを保存する | 読み取り中心のワークロード |
| 非同期処理 | 後続の実行のためにタスクをキューイングする | バックグラウンドジョブと通知 |
急成長環境におけるデータ管理 💾
データはスケーリングにおいてしばしば最大の制約要因となる。取引件数が増加するにつれて、データベースのパフォーマンスは急速に低下する可能性がある。データのスケーラビリティを計画するには、従来のリレーショナルモデルからより柔軟なアーキテクチャへと移行する必要がある。
リードレプリカ:プライマリデータベースのコピーを作成し、読み取り専用のクエリに使用する。これによりプライマリシステムの負荷が軽減され、ユーザーの応答時間が改善される。
データベースシャーディング: 大きなデータベースを、より小さく、高速で管理しやすい部分に分割する。これらの部分をシャードと呼ぶ。各シャードは独立したデータベースインスタンスである。これにより、単一の大規模サーバーのアップグレードではなく、シャードを追加することでシステムをスケールアウトできる。
イベント駆動型アーキテクチャ: システムが互いにデータをポーリングするのではなく、イベントに反応する。これによりコンポーネントが分離され、システムの各部分が特定のイベント負荷に基づいて独立してスケーリングできる。
データストレージを設計する際、アーキテクトはデータ保持ポリシーも考慮しなければならない。古いデータをコールドストレージにアーカイブすることで、アクティブなシステムは軽量かつ高速な状態を保てる。これにより、高性能リソースが現在の運用ニーズに専念できることが保証される。
ネットワークと接続性に関する考慮事項 🌐
スケーラブルなインフラは堅牢なネットワークに依存する。接続デバイスやサービスの数が増えるにつれて、ネットワークの複雑性が増す。設計は遅延、スループット、セキュリティを考慮しなければならない。
マイクロセグメンテーション: セキュリティ脅威の拡散を制限するためにネットワークをより小さなゾーンに分割する。これにより細かいトラフィック制御が可能となり、重要なサービスに優先順位を付けることができる。
マルチリージョン展開: インフラを複数の地理的場所に配置することで、異なる地域のユーザーに対する遅延を低減する。また、障害復旧機能も提供する。1つのリージョンがオフラインになった場合、トラフィックを他のリージョンにルーティングできる。
APIゲートウェイ: これらはすべてのクライアントリクエストの単一のエントリポイントとして機能する。認証、レート制限、ルーティングを処理する。これにより、バックエンドサービスが直接のトラフィックで圧倒されるのを防ぐ。
帯域幅最適化: データ転送を圧縮し、ペイロードサイズを最小限に抑えることで、ネットワークへの負荷を軽減する。最大のスループットを最小限のオーバーヘッドで確保するためには、効率的なプロトコルを使用すべきである。
ガバナンスとライフサイクル管理 🛡️
ガバナンスがなければ、スケーラビリティの取り組みは混乱に陥る可能性がある。ガバナンスはインフラへの変更が文書化され、レビューされ、承認されることを保証する。組織全体で一貫性を維持する。
- 変更管理: インフラへのすべての変更は追跡されなければならない。これにより構成のずれを防ぎ、本番環境が設計仕様と一致することを保証する。
- コスト管理: スケーラビリティはしばしばコストを増加させる。ガバナンスはリソースが効率的に利用されることを保証し、支出が予算制約と一致することを確保する。
- セキュリティコンプライアンス: セキュリティ制御はインフラと同時にスケーリングされなければならない。新しいノードが追加される際には、自動的にセキュリティポリシーを継承し、脆弱性を防がなければならない。
ライフサイクル管理は、リソースの作成から廃棄までの全過程を含む。自動化ツールがリソースのプロビジョニングおよび廃棄を担当すべきである。これにより人的ミスを減らし、使用されていないリソースが不要なコストを発生させないことを保証する。
リスクの評価と緩和戦略の策定 ⚠️
スケーリングは新たなリスクをもたらします。システムが複雑になるほど、障害の発生ポイントの可能性は高くなります。リスク管理に対して積極的なアプローチが不可欠です。
- 単一障害ポイント:システム全体を停止させる可能性のあるコンポーネントを特定する。すべての重要なコンポーネントに対して冗長性を設計する。
- 容量計画:現在の使用状況を予想される成長と定期的に比較する。需要が容量を超える前にリソースを追加できるようにする。
- 災害復旧:バックアップおよび復旧手順を定期的にテストする。危機発生時、サービスを迅速に復旧できる能力は不可欠である。
- ベンダー・ロックイン:1つのプロバイダーに依存すると柔軟性が制限される。可能な限りオープンな標準を使用することで、移行性と交渉力を確保する。
定期的なストレステストと負荷テストは、問題が深刻化する前に弱点を特定するのに役立つ。ピーク負荷をシミュレートすることで、チームはインフラが圧力下でも想定通りに動作することを検証できる。
将来の拡張への準備 🔮
技術の環境は急速に変化している。今日設計されたアーキテクチャは、明日の要件に適応できるようにしなければならない。これには、登場する技術や業界の動向を把握し続けることが含まれる。
- モジュール化:システムをモジュール構成として設計する。これにより、システムの一部を全体に影響を与えずにアップグレードまたは置き換え可能になる。
- 相互運用性:異なるシステムが標準プロトコルを使って通信できるようにする。これにより、新しいツールやサービスとの統合が容易になる。
- スケーラブルなセキュリティ:セキュリティ対策はインフラの進化に合わせて進化しなければならない。新たな脅威には新たな防御が必要であり、アーキテクチャはこれらの更新をスムーズにサポートしなければならない。
- 継続的改善:アーキテクチャを動的な文書として扱う。定期的なレビューにより、設計がビジネス目標と技術的現実に沿ったまま保たれる。
ドキュメント化と知識共有に投資することで、チームがアーキテクチャを理解できるようになる。人材の変更が生じても、組織的な知識は維持され、システムの整合性が保たれる。
アーキテクトのための最終的な考慮事項 🏁
スケーラブルなインフラのための技術アーキテクチャを計画することは、互いに競合する要件を調整する必要がある複雑な作業である。パフォーマンス、コスト、セキュリティ、柔軟性のすべてを考慮しなければならない。構造化された手法を活用し、検証された原則に従うことで、組織は時代に耐えるシステムを構築できる。
デプロイメントが終わるわけではない。スケーラビリティを維持するためには、継続的なモニタリングと最適化が必要である。ビジネスニーズが変化するにつれて、アーキテクチャもそれに合わせて進化しなければならない。これにより、技術が成長の促進要因となる一方で、制約にはならないことが保証される。
基本に注目する:クリーンな設計、自動化、可視性。これらの柱が、未来の課題に対応できる耐障害性の高いインフラを支える。慎重な計画と厳格な実行によって、スケーラブルなシステムはビジネス成功を後押しする現実となる。