










データベース開発者の技術面接に臨むには、SQLの構文を知っているだけでは不十分です。データがどのように構造化され、関連付けられ、維持されているかを深く理解していることを示す必要があります。エンティティ関係図(ERD)は、データモデリングの基盤です。これは、データベースアーキテクチャの視覚的設計図として機能します。
面接官はERDに関する質問を通じて、ビジネス要件を技術的構造に変換する能力を評価します。あなたが基数、正規化、データ整合性を理解しているかどうかを確認したいのです。このガイドでは、必須の概念とあなたが直面する可能性のある一般的なシナリオを丁寧に解説します。
🔍 ERDの核心的な構成要素を理解する
複雑なシナリオに取り組む前に、基本的な構成要素を確実に理解しておく必要があります。ERDは単なる図面ではなく、ルールや制約の表現です。
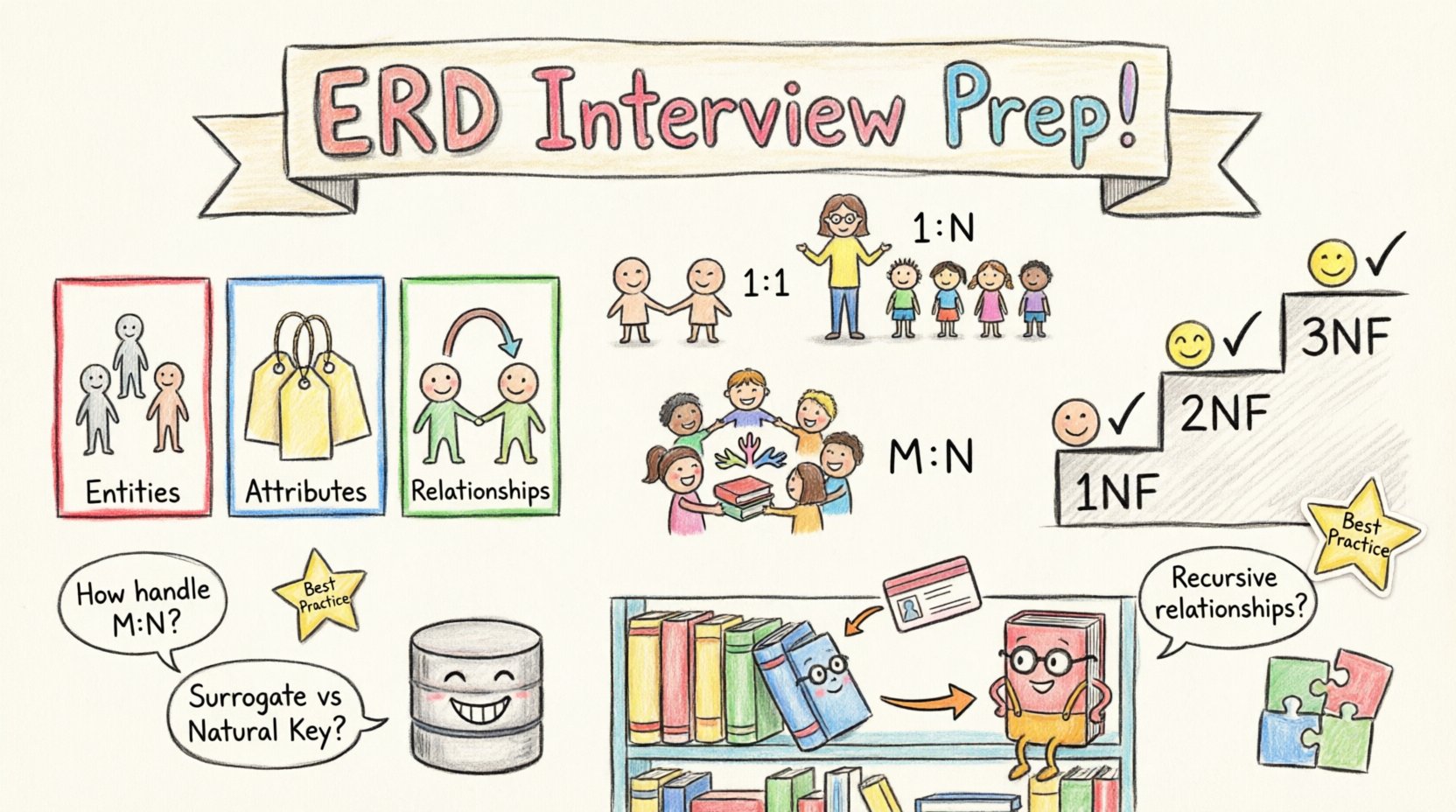
- エンティティ: これらは、顧客、注文、製品など、現実世界のオブジェクトや概念を表します。データベースでは、これらはテーブルに対応します。
- 属性: これらはエンティティを記述する性質です。顧客エンティティの場合、属性には名前、メールアドレス、電話番号などが含まれます。これらは列に対応します。
- 関係: これらはエンティティどうしの相互作用を定義します。たとえば、顧客が注文を出すという状況です。この相互作用が、2つのテーブル間の接続を定義します。
これらの図を描く際には、明確さが最も重要です。標準的な表記法を使用することで、他の開発者があなたの設計を混乱せずに読み取れるようにします。
📊 基数と参加:関係の核心
基数は、あるエンティティのインスタンスが、別のエンティティのインスタンスと関係を持つことができる数や、必須の数を定義します。これは面接で最も厳しく検証される部分です。
説明できるようにしておくべき基数の主な種類は4つあります:
- 1対1(1:1): エンティティAの1つのインスタンスが、エンティティBのちょうど1つのインスタンスに関連します。例:1人の人物は1つのパスポートを持ちます。
- 1対多(1:N): エンティティAの1つのインスタンスが、エンティティBの複数のインスタンスに関連します。例:1つの部署に複数の従業員が所属します。
- 多対1(N:1): 1対多の逆。エンティティAの複数のインスタンスが、エンティティBの1つのインスタンスに関連します。
- 多対多(M:N): エンティティAの複数のインスタンスが、エンティティBの複数のインスタンスに関連します。例:学生は複数の授業に登録し、授業には複数の学生がいます。
面接官は、ビジネスシナリオの中でこれらの関係を特定するよう求められることがよくあります。関係が特定の方法で設計された理由を説明できる必要があります。
基数リファレンス表
| 関係の種類 | 表記法 | データベース実装 | 例のシナリオ |
|---|---|---|---|
| 1対1 | 1:1 | 1つのテーブル内の外部キー | ユーザーとプロフィール |
| 1対多 | 1:N | 『多』側のテーブル内の外部キー | 著者と本 |
| 多対多 | M:N | 2つの外部キーを持つ結合テーブル | 生徒と授業 |
🧩 正規化とERD設計
正規化とは、データの重複を減らし、整合性を高めるためにデータを整理するプロセスです。しばしば別々に教えられますが、正規化はERDの描き方に対して直接的な影響を与えます。
面接では、整理されていない要件のセットを正規化するよう求められることがあります。以下がその対処法です:
- 第1正規形(1NF):すべての列が原子的な値を含むことを確認する。繰り返しグループは存在してはならない。各行は一意でなければならない。
- 第2正規形(2NF):1NFの要件を満たし、すべての非キー属性が主キーに完全に依存していることを確認する。部分的依存を削除する。
- 第3正規形(3NF):2NFの要件を満たし、推移的依存を削除する。非キー属性は他の非キー属性に依存してはならない。
従業員名、部門名、部門マネージャーが含まれる単一のテーブルがある状況を考えてみましょう。部門マネージャーが変更された場合、その部門のすべての行を更新しなければなりません。これは3NFに違反しています。適切なERDでは、部門エンティティを従業員エンティティから分離するべきです。
❓ 一般的な面接質問と詳細な回答
特定の質問を練習することで、プレッシャーの中でも自分の考えを明確に伝える力が身につきます。以下に頻出する質問と、強力な回答の背後にある論理を示します。
Q1:多対多の関係はどのように扱いますか?
回答の戦略:結合テーブルの必要性を説明する。
- 説明:データベースシステムは通常、多対多の関係を直接サポートしていません。
- 解決策:私は関連するエンティティを導入します。これはしばしば結合テーブルまたはブリッジテーブルと呼ばれます。
- 実装: この新しいテーブルには、関連する両方のエンティティの主キーを参照する外部キーが含まれます。これにより、M:N関係が2つの1対多の関係に分割されます。
- 利点: 関係自体に追加の属性を格納できるようになり、たとえば関係内の「入社日」や「役割」などを保存できます。
Q2:自然キーではなくサロゲートキーを選ぶのはどのような場合ですか?
回答の戦略: 安定性、パフォーマンス、柔軟性について議論する。
- 自然キー: これらはビジネスで定義された識別子(例:社会保障番号、メールアドレス)です。変更されるか、利用できなくなることがあります。
- サロゲートキー: これらはシステムによって生成されるもの(例:自動増分整数またはUUID)です。
- 推奨: 多くのエンタープライズシステムでは、主キーとしてサロゲートキーを好む。ビジネスデータが変更されても安定性が保証される。また、整数は長い文字列よりも処理が速いため、結合のパフォーマンスを最適化する。
Q3:再帰的関係はどのように扱いますか?
回答の戦略: ハイエラルキカルデータ構造を説明する。
- 定義: エンティティが自分自身と関係を持つときに、再帰的関係が発生する。
- 例: 従業員が他の従業員を管理できるEmployeeエンティティ。
- 実装: テーブルには自己参照の外部キー列が含まれる(例:ManagerIDがEmployeeIDを指す)。
- 考慮点: ルートノード(最上位の管理者)に対してnull値があることを認識し、データベースの制約がこれを許可していることを確認する。
Q4:弱いエンティティと強いエンティティの違いは何ですか?
回答の戦略: 依存関係と識別について焦点を当てる。
- 強いエンティティ: 他のテーブルに依存せずに独自に識別できる主キーを持つ。
- 弱いエンティティ: 自分自身の主キーを持たず、識別には親エンティティからの外部キーに依存する。
- 例: 注文内の「明細項目」は「注文」が存在しないと成立しない。明細項目の主キーは、通常注文IDと項目順序番号の複合キーである。
⚙️ 複雑なモデルにおける高度な考慮事項
上級の役割では、基本的な図を越えた思考が求められる。パフォーマンスや保守性を考慮しなければならない。
- 連鎖削除:親レコードが削除されたときに何が起こるかを決定する。子レコードは自動的に削除されるべきか、デフォルトに移動されるべきか、またはブロックされるべきか?これはERDにおける慎重な設計を要する。
- 論理削除:レコードを物理的に削除するのではなく、「削除日時」のタイムスタンプを追加する。これにより履歴と関係性が保持される。
- アーキテクチャパターン:レポート作成にスターシステムを使用する場合と、トランザクション処理に正規化スキーマを使用する場合を理解する。ERDはワークロードに応じて変化する。
📝 ERDを描くためのベストプラクティス
手で描いていなくても、概念モデルは論理的でなければならない。設計がプロフェッショナルかつ保守可能になるように、これらのガイドラインに従う。
- 一貫した命名規則:エンティティには単数名詞を使用する(例:「Customer」、複数形の「Customers」は使用しない)。属性には明確で説明的な名前を付ける。
- 明確な記法:クロウズフット記法やチェン記法などの標準記法に従う。同じ図内で記法を混在させない。
- インデックス戦略: 図に常に描かれるわけではないが、定義された関係に基づいて、どの列にインデックスを設定するかを把握しておく必要がある。
- ドキュメント化: 線やボックスだけでは表現できない複雑な論理やビジネスルールを説明するために、注記を追加する。
🛠️ ツールと概念
モデリングに使用するツールについて尋ねられることはよくある。しかし、常に概念に注目すべきである。
- 概念モデル: 技術的な詳細を含まず、ビジネスルールを捉えた高レベルの図。
- 論理モデル: データ型、キー、関係性を含むが、特定のデータベースソフトウェアに依存しない。
- 物理モデル: 特定の制約やストレージパラメータを含む、最終的な実装スキーマ。
面接官は、物理的実装よりも論理モデルを説明できる候補者を評価する。データ構造を把握していれば、どのシステムにも適応できる。
🧠 シナリオベースの問題解決
開放的な設計に関する質問に備えてください。曖昧な要件が提示され、その上で解決策の図を描くように求められるかもしれません。
シナリオ:図書館システムの設計
- エンティティ: 書籍、著者、会員、貸出。
- 関係:
- 著者が書籍を執筆する(1対多)。
- 会員が書籍を貸し出す(多対多、貸出エンティティによって解決)。
- 書籍は複数の著者を持つ(多対多、BookAuthor結合エンティティによって解決)。
- 属性: 貸出日、返却日、罰金を追跡する。
回答する際は、面接官に自分の思考プロセスを説明してください。明確化する質問をしましょう。例えば、「過去の貸出データを追跡する必要があるのか、現在の貸出のみか?」といった質問です。これにより、構文ではなく要件について考えていることが示されます。
🔒 データの整合性と制約
ルールを強制しないERDは無意味です。データ品質を確保する方法について説明してください。
- 主キー: 一意性を確保する。
- 外部キー: テーブル間の参照整合性を確保する。
- チェック制約: 特定の値を検証する(例:年齢は0より大きい必要がある)。
- 一意制約: 特定の列(例:メールアドレス)に重複がないことを確保する。
🏁 準備についての最終的な考察
データベースの面接準備とは、メンタルモデルを構築することにあります。ソーシャルメディアプラットフォーム、ECサイト、在庫管理など日常的なシステムの図を描く練習をしましょう。
- 基本を復習する: 正規化ルールと関係の種類を再確認する。
- シナリオの練習: 業務要件を取得し、それをテーブルに変換する。
- 自分の考えを説明する: デザインを提示する際は、各選択の理由を説明してください。「なぜ」が「何をしたか」よりも重要であることが多いです。
これらの核心原則に注目し、明確なコミュニケーションを実践することで、次の面接で成功するために必要な権威と自信を示すことができるでしょう。準備に成功することを祈っています!🌟