











データアーキテクチャの分野において、多対多関係ほど混乱を招く概念は少ない。エンティティ関係図(ERD)を設計する際、あるエンティティが別のエンティティの複数のインスタンスと関連し、その逆も成り立つ状況に直面すると、特定の構造的アプローチが必要となる。リレーショナルデータベース管理システムは、直接的な多対多関連をネイティブにサポートしていない。データの整合性を維持し、効率的なクエリを実現するためには中間構造を必要とする。このガイドでは、これらの関連を解決する権威的な手法を検討し、データモデルが堅牢でスケーラブルかつ正規化された状態を保つことを確実にする。
学術記録のシステム設計、在庫管理、ユーザー権限のいずれを対象としても、これらの基数を解決する原則は常に同じである。背後にあるメカニズムを理解することで、将来の異常を防ぎ、保守作業を簡素化できる。表面的な定義を超えて、プロフェッショナルなデータモデリングを定義する構造的要件、正規化ルール、実装戦略を検討する。
🔍 ERDにおける基数の理解
基数は、データベース内のエンティティ間の数的関係を定義する。あるエンティティのインスタンスが、別のエンティティの各インスタンスと関連できる数(または関連しなければならない数)を指定する。ERD表記では、通常、エンティティを結ぶ線で表現され、クロウズフット(カモメの足)が「複数」側を、直線または単一の印が「1つ」側を示す。
主な基数は以下の3つである:
- 1対1(1:1):エンティティAの1つのレコードが、エンティティBの1つのレコードと関連する。例:個人とそのパスポート。
- 1対多(1:M):エンティティAの1つのレコードが、エンティティBの複数のレコードと関連する。例:顧客が複数の注文を行う。
- 多対多(M:N):エンティティAの複数のレコードが、エンティティBの複数のレコードと関連する。例:学生が複数の授業に登録し、授業に複数の学生が含まれる。
1:1および1:M関係は物理的なデータベーススキーマ上で実装しやすいが、M:N関係は独自の課題を提示する。リレーショナル理論では、テーブルのセルには原子値(原子的な値)のみを含むべきであると定めている。テーブルAの1行が、理論上テーブルBの複数行を参照できるような直接的なリンクは、物理レイヤーにおいてこの原則に違反する。
🚫 直接的なM:M関係がリレーショナルモデルで失敗する理由
E.F. コッドによって確立されたリレーショナルモデルは、各列が特定の属性を表し、各行が一意のインスタンスを表す関係(テーブル)の概念に依存している。標準的なリレーショナルデータベースでは、直接的な多対多リンクが不可能な主な理由は以下の2つである:
- ネイティブなサポートの欠如:データベースエンジンは、外部キー列に複数の値を保持することを許可しない。外部キーは、別のテーブルの単一の主キーを指さなければならない。キーのリストを指すことはできない。
- 挿入および削除の異常:1つのセルに複数のIDを格納しようとする(例:「Student_ID: 101, 102, 103」)と、第1正規形(1NF)に違反する。これにより、特定の関係をクエリ、更新、削除する際に計算コストが高くなり、エラーが発生しやすくなる。
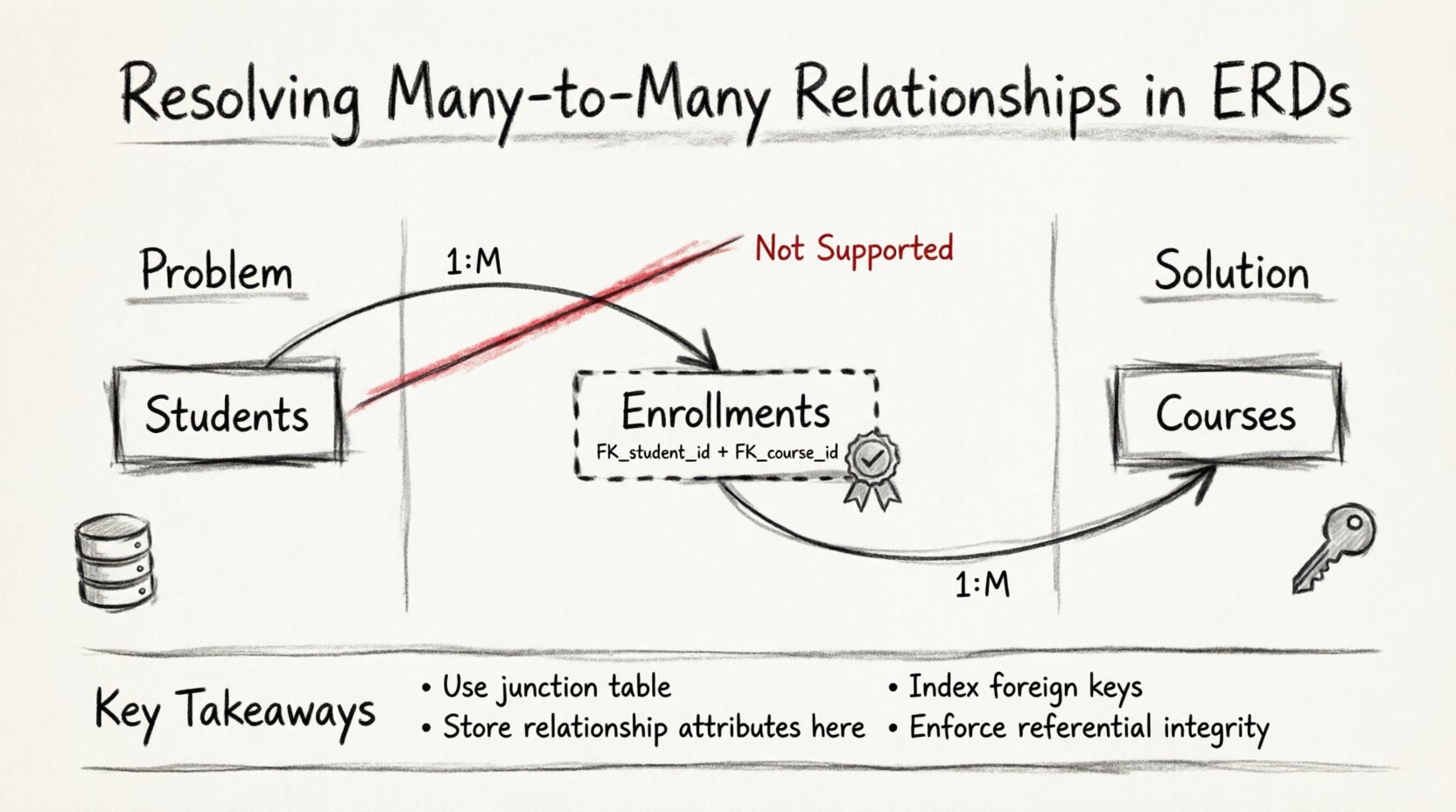
したがって、このデータを効率的に格納するためには、関係自体をエンティティとして扱わなければならない。この変換が、複雑さを解決する核心的な技術である。
🧱 技術1:関連エンティティ(ジョインテーブル)
多対多関係を解決する標準的な解決策は、関連エンティティ(一般的にジョインテーブルまたはブリッジテーブルとして知られる)の作成である。このテーブルは、2つの主要なエンティティの間に物理的に配置され、直接的な接続を2つの1対多関係に分割する。
ジョインテーブルを導入すると、元のM:N関係は以下の2つに分解される:
- エンティティAとジョインテーブルの間の1対多関係。
- エンティティBとジョインテーブルの間の1対多関係。
ジョインテーブルの構造:
- 外部キー:少なくとも2つの外部キー列を含む必要がある。1つはエンティティAの主キーを参照し、もう1つはエンティティBの主キーを参照する。
- 複合主キー:多くの場合、これらの2つの外部キーの組み合わせが、ジョインテーブルの主キーとして機能する。これにより、関係が本質的に多値である場合を除き、特定のエンティティペアが複数回リンクされることを防ぐ。
- サロゲートキー: 一部のケースでは、結合テーブルに一意の自動増分IDが追加されます。これは、関係が異なる属性を持つ複数のインスタンスを持つ場合に有用です(たとえば、学生が異なる年間に異なる成績で同じコースに複数回登録される場合など)。
例のシナリオ:
図書館システムを考えてみましょう。本は多くの利用者によって借りられます。利用者は多くの本.
- 解決なし:1つの本の行を複数の利用者の行に直接リンクすることはできません。
- 解決策あり:貸出記録テーブルを作成します。
- この貸出記録には
本IDと利用者ID.
この構造により、データベースは、どの利用者がいつどの本を持っているかを正確に追跡でき、本や利用者のデータを重複させることなく実現できます。
📝 技術2:関係に属性を扱う方法
ERDモデリングにおける重要な違いは、エンティティ間の関係が独自のデータを保持しているかどうかです。単純なリンクでは、接続があるか、ないかのどちらかです。しかし、多くの現実世界のシナリオでは、関係自体にプロパティがあります。
たとえば、プロジェクトと従業員 シナリオでは、従業員は複数のプロジェクトに従事でき、プロジェクトには複数の従業員が関与する。しかし、この関係には以下が含まれる可能性がある。
- 役割: この特定のプロジェクトにおいて、従業員は開発者、デザイナー、またはマネージャーですか?
- 割り当て時間(週): 週にこのプロジェクトに割り当てられている時間はどれくらいですか?
- 開始日: この割り当てはいつ開始されましたか?
関係を単なる2値フラグとして扱うと、この重要なデータを失うことになる。ジョインテーブルは、これらの属性を格納するのに最適な場所となる。
実装ルール:
- 関係の属性を親エンティティに格納してはならない。それらはプロジェクトだけのものでも、従業員だけのものでもない。
- すべての関係固有のデータをジョインテーブルに配置する。
- これらの属性を親エンティティに影響を与えずに更新できるように、ジョインテーブルに一意の識別子(複合または代替)を確保する。
このアプローチにより、データの正規化が保証される。もし、役割 列を 従業員 テーブルに追加した場合、従業員が異なるプロジェクトで複数の役割を持つと、重複が生じる。ジョインテーブルはこの変化を隔離する。
⚖️ 技術3:正規化とデータ整合性
M:N関係を解決することは、単にテーブルをリンクすることだけではない。データの異常を防ぐために正規化の原則に従うことが重要である。第三正規形(3NF)は、ほとんどのトランザクションシステムの標準的な目標である。
第三正規形(3NF)の要件:
- テーブルは第二正規形(2NF)にないといけない。
- すべての非キー属性は、主キーにのみ依存しなければならない。
ジョインテーブルを作成することで、関係データがジョインテーブルの複合キーに依存するようになり、個々のエンティティキーに依存しなくなる。これにより推移的依存が排除される。
参照整合性:
外部キー制約はジョインテーブルにおいて不可欠である。以下のルールを強制する。
- ある
書籍IDは貸出ログに存在しなければならない。書籍 テーブルに存在しなければならない。 - A
Patron_ID貸出ログ内のPatronsテーブルに存在しなければなりません。
これにより、孤立したレコードを防ぎます。カタログに存在しない本の貸出イベントを記録することはできません。データベースエンジンは、削除時のCASCADEまたはRESTRICTアクションによってこれを強制します。
📊 関係タイプの比較
関係タイプ間の違いを可視化することで、適切なモデリング戦略を選択するのに役立ちます。以下の表は、構造的要件と実装の複雑さを要約しています。
| 関係タイプ | 物理的実装 | 主キーの位置 | 複雑さ |
|---|---|---|---|
| 1対1 (1:1) | 1つのテーブルに外部キー | どちらかのテーブル | 低 |
| 1対多 (1:M) | 「多」側のテーブルに外部キー | 主テーブル | 中 |
| 多対多 (M:N) | 別々の結合テーブル | 結合テーブル(複合) | 高 |
ご覧の通り、M:N関係は最も大きな構造的オーバーヘッドを必要とします。しかし、これはデータ整合性のために不可欠です。クエリ中に追加の結合を行うコストは、不適切なスキーマ設計によるデータ不整合のコストよりも常に小さくなります。
🚀 パフォーマンスに関する考慮事項
結合テーブルを導入すると、クエリに間接性の層が加わります。データを取得する際には、2つのテーブルではなく3つのテーブルを結合する必要があります。高負荷のシステムでは、適切に管理されない場合、パフォーマンスに影響を与えることがあります。
- インデックス作成:結合テーブル内のすべての外部キーはインデックス化する必要があります。これにより、データベースエンジンは結合テーブル全体をスキャンせずに、特定のエンティティの行を迅速に検索できます。
- 複合インデックス:場合によっては、両方の外部キーの組み合わせにインデックスを作成する方が、個別のインデックスよりも効率的です。これにより、両方のエンティティを同時にフィルタリングするクエリをサポートできます。
- 読み取り vs. 書き込み:関係が動的である場合、結合テーブルは通常、書き込みが重いです。レポートを生成する際は読み取りが重くなります。インデックス戦略がアプリケーションの主な操作パターンをサポートしていることを確認してください。
⚠️ 一般的な落とし穴とその解決策
経験豊富なモデラーでさえ、基数を解決する際にミスを犯すことがあります。一般的な誤りに気づいておくことで、後のリファクタリングにかかる時間を大幅に節約できます。
1. 「1カラム」の誤り
複数のIDを、カンマ区切りの値(例:「1, 2, 3」)を使って1つのカラムに格納しようとする。これはデータベースの原則に違反し、文字列パース関数を使わなければクエリが不可能になります。関係の各インスタンスに対して常に別々の行を使用してください。
2. 冗長な属性
必要がないのに親エンティティの属性を結合テーブルにコピーすること。属性がエンティティに属する場合(例:生徒の名前)、それは生徒テーブルに属するべきであり、登録テーブルには属しません。リンク自体を説明するデータだけを記録してください。
3. NULL許容性の無視
必須であるべき外部キーをNULLを許容するように定義すること。関係が必須の場合(例:注文には顧客が必須)、外部キーはNULL値を許容してはいけません。これにより、データベースレベルでビジネスルールを強制できます。
4. 円形参照
不要に自分自身を参照する結合テーブルを作成すること。結合テーブルが関係に参加する2つの異なるエンティティのみをリンクしていることを確認してください。機能的な目的を持たないループを作成しないようにしましょう。
🎨 視覚的表現のベストプラクティス
ERDを文書化する際、明確さが最も重要です。視覚的表現は、図を読む誰にでも即座に解決された構造を伝えるべきです。
- 結合テーブルにラベルを付ける:テーブル名は説明的にしてください。「Table3」ではなく、「Student_Course_Enrollment」を使用してください。
- 基数を示す:結合テーブルと親エンティティをつなぐ線を明確にマークしてください。結合テーブル側にクロウズフットを使用して、親エンティティの視点から見た「多数」の関係を示してください。
- 属性を表示する:結合テーブルに属性(例:「成績」や「日付」)がある場合は、図に明示的にリストアップしてください。これにより、関係が単なるリンク以上のものであることが強調されます。
- 異なる線のスタイルを使用する:一部のモデリングツールでは、オプションの関係に破線、必須の関係に実線を使用できます。ここでの一貫性は理解を助けます。
🔄 再帰的関係とM:N
時折、1つのエンティティ内に多対多の関係が存在します。例えば、従業員 は複数の他のものを管理できます 従業員、そしてその従業員は他の人を管理できます。これは再帰的なM:N関係です。
解決方法は標準的なM:N関係と同様です。依然として中間テーブルを作成しますが、そのテーブル内の両方の外部キーは、同じエンティティの主キーを参照します。
- エンティティ: 従業員
- 中間テーブル: 従業員管理
- 外部キー1: マネージャーID(従業員を参照)
- 外部キー2: 従業員ID(従業員を参照)
この構造により、正規化ルールを違反せずに複雑な組織階層を実現できます。また、複数の管理レベルを横断するクエリを可能にします。
🛡️ データ制約とビジネスルール
技術的な制約だけでは不十分です。ビジネスルールも強制しなければなりません。中間テーブルは、これらのルールを適用する自然な場所です。
- 一意制約:特定の関係が意図しない限り、二度作成されないようにします。たとえば、学生は同じ学期に同じ授業セクションに二度登録してはいけません。Student_IDとCourse_IDの組み合わせに一意制約を設けることでこれを強制します。
- チェック制約:数値データを検証します。たとえば、プロジェクトの中間テーブルにある「割り当て時間」は0より大きく、40より小さくなければなりません。
- トリガー:複雑なシステムでは、要約テーブルを更新するためにトリガーが必要になる場合があります。中間テーブルが変更された場合、親エンティティ(例:「従業員ごとのプロジェクト数合計」)の要約テーブルが自動的に更新される必要があるかもしれません。
📈 モデルの進化
要件が変化するにつれてモデルは進化します。ビジネスルールが変更された場合、M:N関係が1:N関係に簡略化されることがあります。たとえば、学生が一度に一つの授業しか登録できないようにポリシーが変更された場合、中間テーブルを学生テーブルに統合できます。
しかし、中間テーブルから始める方が一般的に安全です。これにより最大限の柔軟性が確保されます。後で複数の登録を許可する要件に変更された場合、スキーマはすでに準備されています。一方、統合されたテーブルから始めると、後でリファクタリングが必要になります。
📝 主なポイントのまとめ
M:N関係を解決することは、データベース設計における基本的なスキルです。データの整合性を維持し、効率的なクエリをサポートするために中間構造を作成する必要があります。中間テーブルは標準的な解決策であり、複雑な関係を管理しやすい1:Nリンクに分割します。
- 常にM:Nを解決する:単一のカラムに複数の外部キーを格納しようとしないでください。
- 複合キーを使用する:外部キーの組み合わせは、通常、関係のユニーク識別子として機能します。
- 関係データを保存する:リンクに固有の属性を結合テーブルに配置する。
- 外部キーにインデックスを付ける:パフォーマンスは結合テーブルの行に対する高速な検索に依存する。
- 制約を適用する:無効なデータを防ぐために一意制約および外部キー参照を使用する。
これらの技術を遵守することで、データベーススキーマが変更に耐えうるようになり、複雑なデータ相互作用を処理できるようになります。設計段階での適切なモデル化に費やした努力は、システムのライフサイクル全体にわたり保守性とパフォーマンスの面で大きな利益をもたらします。