











データベースモデルは、いかなる堅牢なアプリケーションの基盤を成す。エンティティ、関係、属性が進化する際、基盤となるスキーマはデータ整合性を損なうことなく適応しなければならない。このガイドでは、バージョン管理を通じてエンティティ関係図(ERD)の変更を管理するという分野について探求する。一貫性を維持し、履歴を追跡し、チーム間で効果的に協働する方法を検討する。
現代の開発サイクルはスピードを要求するが、データの安定性を速度のためには犠牲にしてはならない。データベーススキーマは単なるテーブルの集まりではない。それはアプリケーションと永続的ストレージとの間の契約である。適切なガバナンスなしにこの契約を変更するとリスクが生じる。データベースモデルをコードとして扱うことで、チームはデータインフラに確立されたエンジニアリング手法を適用できる。
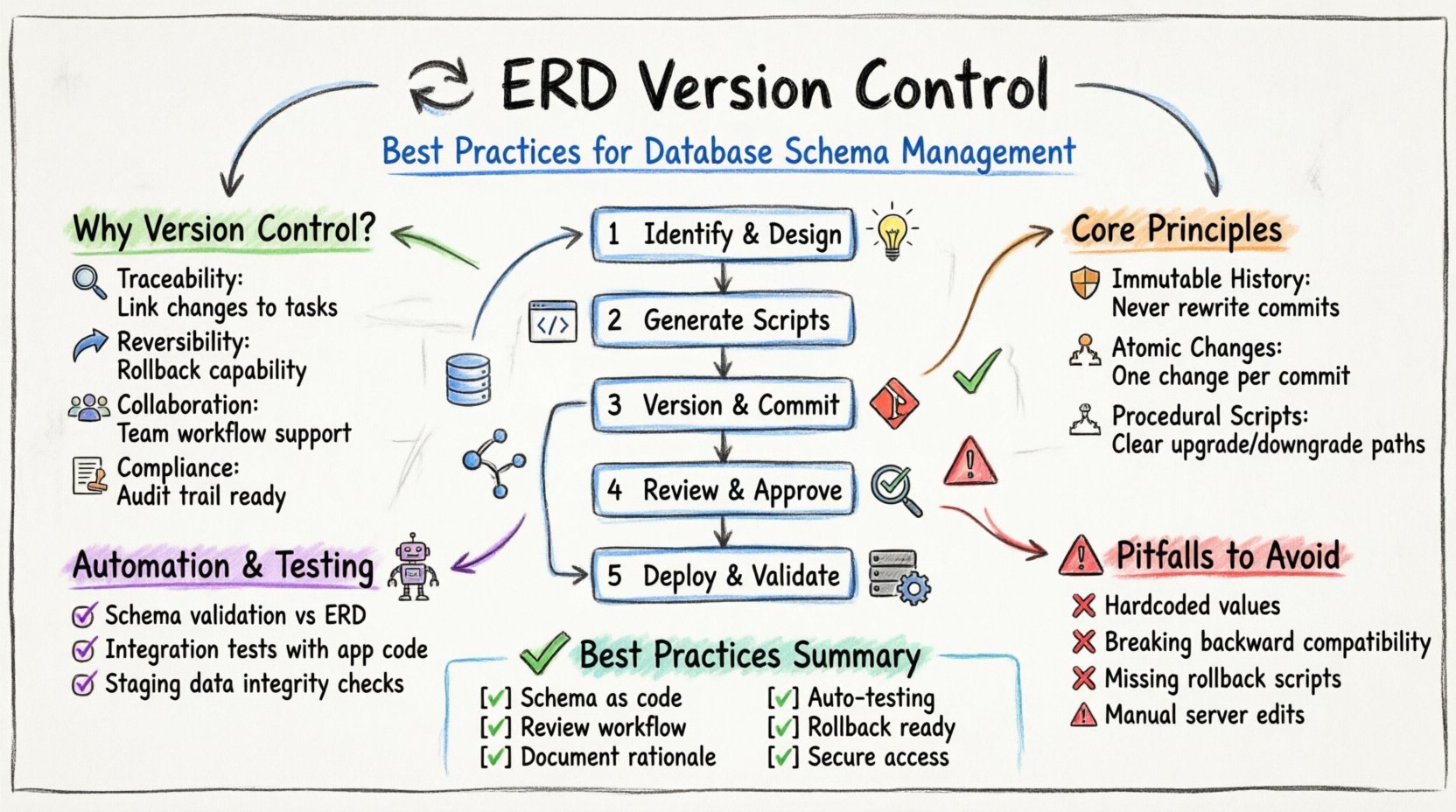
なぜデータベーススキーマのバージョン管理が重要なのか 🤔
アプリケーションコードと比べて、データベースモデルのバージョン管理はしばしば軽視される。開発者はアプリケーションロジックをリポジトリで管理する一方で、データベースの変更を臨時のスクリプトとして扱うことが多い。この乖離は技術的負債と運用上の脆弱性を生み出す。スキーマの進化に対する構造的なアプローチにより、すべての変更が文書化され、レビューされ、元に戻せることが保証される。
欠落したマイグレーションスクリプトの影響を検討してみよう。本番環境では、予期せぬスキーマ変更が全体のデプロイパイプラインを停止する可能性がある。変更履歴がなければ、デバッグは推測のゲームになる。このカラムは先週存在していたのか?インデックスは意図的に削除されたのか?バージョン管理はこれらの問いに明確な答えを提供する。
- トレーサビリティ: すべての変更は、特定のリクエストまたはタスクに関連付けられている。
- ロールバック可能性: 変更によって問題が発生した場合、システムは以前の状態に戻すことができる。
- 協働性: 複数の開発者が、互いの変更を上書きすることなく、モデルの異なる部分に同時に作業できる。
- コンプライアンス: オーディットログは、データ取り扱いやアクセスに関する規制要件を満たす。
モデル安定性の核心原則 🛡️
効果的なバージョン管理は、ガイドラインとなる一連の原則に依存する。これらのルールは、変更がどのように提案され、実装され、マージされるかを規定する。これらの基準を遵守することで、衝突を最小限に抑え、信頼性を最大化できる。
1. 変更不可能な履歴
スキーマバージョンがリポジトリにコミットされた後は、決して変更してはならない。誤りが発見された場合でも、正しい対応は前の状態を修正する新しいバージョンを作成することである。履歴を書き換えると、意思決定のタイムラインが曖昧になり、変更の監査が難しくなる。
2. 原子的な変更
変更は小さな論理単位で行うべきである。1つのコミットは、1つの特定の要件にのみ対応すべきである。関係のない変更を1つのパッケージにまとめるのは、問題の特定を困難にする。デプロイが失敗した場合、どの変更が問題を引き起こしたかを正確に把握できれば、解決が迅速になる。
3. 宣言的 vs. 手順的
スキーマ状態を表現するには、主に2つの哲学がある。1つは望ましい最終状態(宣言的)に注目するものであり、もう1つはその状態に到達するためのステップ(手順的)に注目するものである。両方とも利点があるが、手順的マイグレーションスクリプトは、本番環境ではしばしば好まれる。なぜなら、アップグレードとダウングレードの明確なパスを提供するからである。
スキーマ変更のライフサイクル 🔄
ERDの変更を管理するには、構造化されたワークフローが必要である。このプロセスは、モデリングツール内の図から、ライブデータベース内の検証済み状態へと概念を移行する。このライフサイクルに従うことで、ステップの漏れがなくなる。
ステップ1:識別と設計
プロセスは変更の必要性を特定することから始まる。これは、機能用の新しいテーブル、既存テーブルの分割、関係の変更などである可能性がある。設計はERDモデリングツールに記録すべきである。この段階では、物理的実装の詳細よりも論理的一貫性に注目する。
- エンティティとその属性を明確に定義する。
- 主キーと外部キーを設定する。
- データ整合性のための制約を確認する。
- 変更の理由を文書化する。
ステップ2:スクリプト生成
論理モデルが承認されると、実行可能なスクリプトに変換する必要があります。これには、データベースオブジェクトを作成、変更、または削除するSQL文を生成することが含まれます。可能な限り、これらのスクリプトが再実行可能(idempotent)であることを確認することが重要です。これは、エラーを引き起こさずに複数回実行できるという意味です。
ステップ3:バージョン管理とコミット
スクリプトはバージョン管理システムに追加されます。各スクリプトには一意の識別子(通常はタイムスタンプまたは連番)を付けるべきです。コミットメッセージは、関連するタスクや問題番号を参照しながら変更内容を詳細に記述する必要があります。これにより、コードとデータの間に明確なリンクが作られます。
ステップ4:レビューと承認
マージの前に、変更内容は同僚によるレビューが必要です。このステップは、自動化ツールが見逃す可能性のある論理的な誤りを発見するために不可欠です。レビュアーは命名規則、制約の定義、および潜在的なパフォーマンスへの影響を確認する必要があります。正式な承認プロセスにより、不正な変更がメインブランチに到達するのを防ぐことができます。
ステップ5:デプロイと検証
最終ステップは、変更を対象環境に適用することです。これは通常、自動化パイプラインを通じて行われます。デプロイ後の検証により、スキーマが期待される状態と一致していることを確認できます。これには、カラム数の確認のためのクエリ実行や、データ整合性制約のチェックが含まれる場合があります。
並行開発および衝突の対処 ⚔️
複数の開発者がいるチームでは、スキーマの変更がしばしば同時に発生します。同じテーブルや関係性を2人が同時に変更すると、衝突が生じます。このような衝突を解決するには、体系的なアプローチが必要です。
衝突の解決は、テキストをマージすることだけではなく、データ構造をマージすることです。2つのERDをマージすることは、2つのソースコードファイルをマージするよりも複雑です。結合されたモデルが論理的に整合していることを確認する必要があります。
- 連携:開発者は変更を行う前に、共有するエンティティについて調整するべきです。
- ブランチ戦略:変更を隔離するために機能ブランチを使用する。本番環境に移行する前に、これらのブランチを共有された統合ブランチにマージする。
- 手動マージ:自動化ツールはスキーマの衝突に対してしばしば苦戦します。差異を調整するために、人間の介入が頻繁に必要です。
- 衝突の解決:衝突が発生した場合、チームはどの変更バージョンを優先するかを決定しなければなりません。この決定は文書化されるべきです。
代表的な衝突シナリオ
| シナリオ | 説明 | 解決戦略 |
|---|---|---|
| カラム名の変更 | 2人の開発者が、同じカラムを異なる名前に変更した。 | 標準的な命名規則に合意し、合意した名前に戻す。 |
| テーブルの削除 | 1人の開発者が、別の開発者が変更中のテーブルを削除した。 | 削除の前にすべての依存関係を削除することを確認する。テーブルが必要な場合は、削除をロールバックする。 |
| データ移行 | スクリプトは、互いに矛盾する方向にデータを移動させる。 | すべての変換を正しく処理する単一のスクリプトに論理を統合する。 |
| 制約の追加 | 2人の開発者が同じカラムに制約を追加する。 | 互換性がある場合は制約をマージし、そうでない場合は単一の制約定義に統合する。 |
検証とテストの自動化 🤖
手動テストは誤りを起こしやすい。自動化により、スキーマの変更がデプロイされる前に品質基準を満たしていることを保証する。継続的インテグレーションパイプラインとの統合により、すべてのコミットに対して即時フィードバックが得られる。
スキーマ検証
自動化ツールは、生成されたSQLをERDモデルと照合できる。これにより、物理的実装が論理設計と一致していることを保証する。不一致が発生するとビルドパイプラインで失敗が発生し、開発者に即座に通知される。
統合テスト
スキーマの変更はアプリケーションコードに対してテストされるべきである。カラムが削除された場合、そのカラムをまだ参照しているアプリケーションはコンパイルまたは実行に失敗すべきである。この連携により、破壊的変更が見逃されるのを防ぐ。
データ整合性の確認
本番環境に類似したデータ量を持つステージングデータベースでマイグレーションを実行することで、パフォーマンス上の問題を特定できる。長時間実行されるクエリやロック競合は、ライブユーザーに影響を与える前に発見できる。このステップは大規模なデータベース環境において不可欠である。
ドキュメント作成と監査ログ 📜
締切が近づくと、ドキュメントが最初に無視されがちである。しかし、データベースモデルにおいては、ドキュメントは一種の保険である。それは「何をしたか」の背後にある「なぜ」を説明する。
すべての変更には説明文が付随すべきである。この説明文は、バージョン管理システム内のスクリプトと共に保存されるべきである。以下の質問に答えるべきである:
- なぜこの変更が必要なのか?
- どのデータが影響を受けるのか?
- 他のシステムとの依存関係は存在するか?
- 想定されるダウンタイムはどのくらいか?
監査ログは、誰がいつ変更を行ったかを記録する。これはセキュリティおよびコンプライアンスにとって不可欠である。データ漏洩が発生した場合やクエリのパフォーマンスが低下した場合、スキーマ変更の原因を把握できることで、トラブルシューティングが容易になる。
避けたい一般的な落とし穴 🚫
堅固なプロセスがあっても、ミスは起こる。一般的な落とし穴を認識することで、チームはそれらを回避できる。
値のハードコード
マイグレーションスクリプトに環境固有の値を埋め込まない。開発環境では動作するスクリプトが、パスや認証情報がハードコードされているために本番環境で失敗する可能性がある。これらの違いは、構成管理を使用して処理する。
後方互換性の無視
破壊的変更は可能な限り避けるべきである。カラムを削除する場合、アプリケーションが依然として動作することを確認する。一般的な戦略として、新しいカラムを追加し、データを移行した上で、次のリリースで古いカラムを非推奨にする方法がある。
ロールバック計画の欠如
すべてのマイグレーションスクリプトには、対応するロールバックスクリプトが必要である。デプロイが失敗した場合、変更を素早く元に戻すことができる必要がある。ロールバック計画がなければ、失敗したデプロイによりデータベースが一貫性のない状態に陥る可能性がある。
手動でのスクリプト編集
サーバー上でデータベーススクリプトを直接編集してはいけません。常にバージョン管理システムで変更を行い、デプロイしてください。直接の編集は再起動時に失われ、変更の記録が残らないためです。
ベストプラクティスの要約 🏁
健全なデータベースモデルを維持するには、規律が求められます。コードを書くだけでは不十分です。データ層は同じ厳密さで扱われるべきです。以下の表は、ERDの変更を管理するための主なポイントをまとめています。
| 分野 | ベストプラクティス |
|---|---|
| バージョン管理 | スキーマをリポジトリ内のコードとして扱う。 |
| ワークフロー | 明確なレビューおよび承認プロセスを使用する。 |
| テスト | 検証および統合テストを自動化する。 |
| コミュニケーション | すべての変更の理由を文書化する。 |
| 復旧 | 常にロールバックスクリプトを維持する。 |
| セキュリティ | 本番データベースへの直接アクセスを制限する。 |
これらの実践を導入することで、チームはリスクを低減し、データインフラに対する信頼を高めることができます。目標は、上層で実行されるアプリケーションコードと同等に、データベースを信頼性と予測可能性の高いものにすることです。