











データがどのようにつながっているかを理解することは、堅牢なシステムを構築する上で基本です。ドキュメントのないデータベーススキーマに遭遇した場合、エンティティ関係図(ERD)が信頼できる情報源となります。このガイドでは、これらの図を解釈するための構造的なアプローチを提供し、複雑なデータモデルを明確かつ正確に把握できるようにします。主要な記号、関係の種類、およびどのスキーマも効果的に解読するために必要な分析ステップについて説明します。
ERDを理解することが重要な理由 🧠
データベーススキーマはほとんどが自明ではない。丁寧にドキュメント化されたERDは、情報がどのように格納され、リンクされ、検証されるかを示す設計図となる。新しいサービスを統合する開発者、要件を収集するビジネスアナリスト、メンテナンスを行うデータベース管理者のいずれであっても、これらの図を読み解く能力は不可欠である。
- システム統合:外部キーの関係を把握することで、移行中にデータ整合性のエラーを防ぐことができる。
- パフォーマンスチューニング:結合パスを理解することで、クエリ実行を最適化できる。
- コミュニケーション:共有された視覚的言語が、技術チームとステークホルダーの間の溝を埋める。
- レガシーメンテナンス:古いシステムの解読は、既存の図を逆工程する作業に大きく依存する。
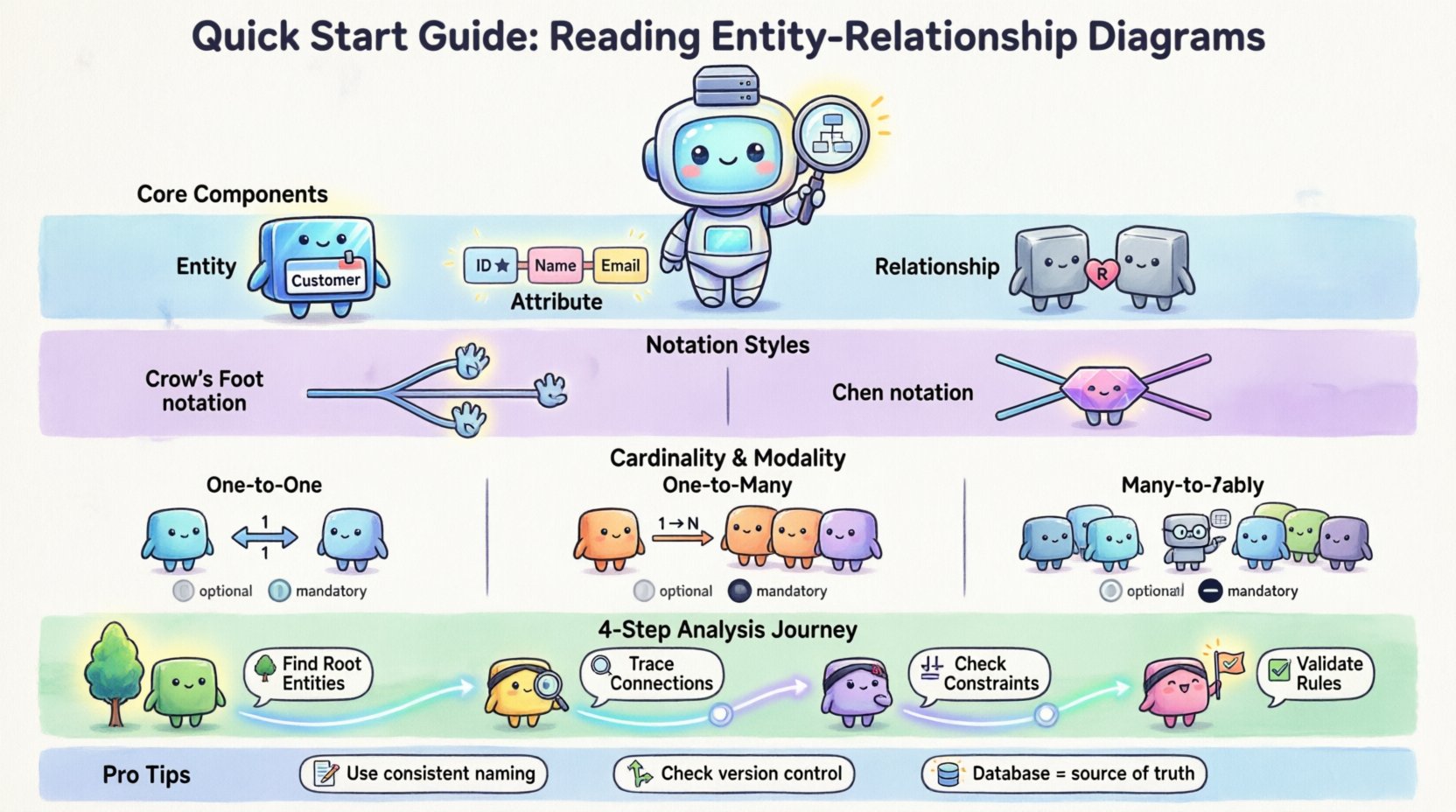
データベーススキーマの核心的な構成要素 🏗️
複雑な構造を分析する前に、構成要素を特定する必要がある。すべてのERDは3つの主要な要素から構成される。これらの要素を即座に認識できれば、図を扱いやすい部分に分割できる。
1. エンティティ 🏷️
エンティティは、システム内の明確なオブジェクトまたは概念を表す。関係型の文脈では、通常はテーブルに対応する。エンティティは一般的に長方形で描かれる。
- 例:顧客、製品、注文、従業員。
- 視覚的サイン:エンティティ名を含むボックス。
- キー識別子:各エンティティには、一意性を保証するための主キーが必要である。
2. 属性 📝
属性は、エンティティを記述する具体的なデータポイントを指す。これらはテーブル内の列を定義する。一部の表記法では属性をエンティティボックス内に配置するが、他の表記法では線で接続する。
- 主キー:通常は下線が引かれており、レコードを一意に識別する。
- 外部キー:別のエンティティの主キーにリンクする。
- データ型:文脈によって暗黙的に定義される(例:日付、整数、文字列)。
3. 関係 🔗
関係は、エンティティがどのように相互作用するかを定義します。レコード間の制約や依存関係を示します。図では、通常、エンティティを結ぶ線として表現されます。
- 方向:どのエンティティが接続を開始するかを示します。
- 制約:関係が必須かオプションかを示します。
- 基数:接続の数値制限を定義します(例:1対多)。
標準記法の解読 🔍
異なるチームやツールは、同じ概念を表現するためにさまざまなスタイルを使用します。最も一般的な2つのスタイルは、クロウズフット記法とチェン記法です。スタイルを認識することで、線の意味を正しく解釈できます。
記法スタイルの比較
| 特徴 | クロウズフット記法 | チェン記法 |
|---|---|---|
| エンティティ | 長方形 | 長方形 |
| 関係 | 記号付きの線で接続 | 線を結ぶダイアモンド |
| 基数 | 特定の終端を持つ線(例:クロウズフット) | 線に配置された数字 |
| 複雑さ | コンパクトで、現代のツールで人気 | 明確で、学術的な文脈でよく使用 |
図を確認する際は、凡例を確認するか、線のスタイルをチェックしてください。ダイアモンド型の形状が見える場合は、チェン記法です。線の終端が三本の突起を持つ場合は、クロウズフット記法です。両者は同じ論理を伝えますが、異なる視覚的メタファーを使用しています。
基数とモダリティの理解 🔄
基数はERDにおいて最も重要な側面です。データ量に関するビジネスルールを決定します。これを誤解すると、不完全なデータベース設計やアプリケーションロジックのエラーが生じます。
一般的な基数の種類
- 一対一 (1:1):テーブルAのレコードは、テーブルBの正確に1つのレコードにリンクしています。
- 一対多 (1:N):テーブルAのレコードは、テーブルBの複数のレコードにリンクしています。
- 多対多 (M:N):テーブルAのレコードは、テーブルBの複数のレコードにリンクしており、その逆もまた同様です。通常、この関係には結合テーブルが必要です。
モダリティ(選択的)
モダリティは、関係が必須か選択的かを決定します。これは、エンティティを結ぶ線に垂直棒(|)または円(o)で示されることがよくあります。
| 記号 | 意味 | 例のシナリオ |
|---|---|---|
| 円(o) | 選択的 | ユーザーはおそらくプロフィール画像を持っているかもしれません。 |
| 棒(|) | 必須 |
ステップバイステップの分析プロセス 📝
複雑な図を分析する際は、圧倒されてしまうことがあります。すべての必要な詳細を逃さず、重要な制約を漏れなく把握するために、この体系的なワークフローに従ってください。
ステップ1:ルートエンティティを特定する 🌳
中心的なアクターから始めましょう。これらはシステムの主要な主題です。最も多くの接続を持つエンティティを探してください。
- 主要なビジネスオブジェクトを特定します。
- その主キーをメモしてください。
- データの真実の出所であるかどうかを確認してください。
ステップ2:接続をたどる 🔍
1つのエンティティから別のエンティティへと線を追ってください。飛び跳ねてはいけません。1つの経路を完全にたどり終えてから、次の経路に移ってください。
- 関係線のラベルを読みましょう。
- 両端の基数マーカーを確認してください。
- 外部キーが明示的に名前付けされているか確認してください。
ステップ3:属性制約を確認する ⚖️
エンティティボックスの中を確認し、特定のデータルールを探してください。
- 非キー列に一意制約がありますか?
- デフォルト値が指定されていますか?
- 複合キー(複数の列が1つのキーを形成する)がありますか?
ステップ4:整合性ルールを検証する ✅
図が論理的なビジネス要件と整合していることを確認してください。
- 子エンティティは存在のために親に依存していますか?
- 問題を引き起こす可能性のある循環依存関係がありますか?
- データ正規化レベルは適切ですか(例:3NF)?
一般的な関係パターン 🏛️
特定のパターンは、さまざまな業界で頻繁に出現します。これらのショートカットを認識することで、解釈時間を大幅に短縮できます。
1. ハイエラルキカルパターン
この構造は木に似ています。1つの親が多数の子に接続し、子はそれぞれ自分の子に接続します。これは組織図やカテゴリツリーでよく見られます。
- 構造: 親 → 子 → 孫。
- 実装:同じテーブル内の自己参照外部キー。
- 警告:深いネストはクエリのパフォーマンスに影響する可能性があります。
2. スターシステムパターン
データウェアハウスでよく使用されます。中央のファクトテーブルが複数のディメンションテーブルに接続します。
- 構造:1つの中心部、多数のスポーク。
- 用途:集計およびレポートのシナリオ。
- 利点: 分析用の複雑なクエリを簡素化します。
3. 結合テーブルパターン
多対多関係に必須です。2つのエンティティは中間テーブルなしでは直接リンクできません。
- 構造: テーブルA ↔ 結合テーブル ↔ テーブルB。
- 機能: 両側からの外部キーとリンクの特定属性を格納します。
- 例: 学生と授業(1人の学生が複数の授業を受講する;1つの授業に複数の学生が登録される)。
ドキュメント作成のベストプラクティス 📚
図は、それに付随するドキュメントの品質に匹敵するものです。既存のERDに遭遇した際は、これらの基準を満たしているか確認してください。
- 一貫した命名規則: エンティティには単数名詞を使用してください(例:User ではなく Users)。カラムにはcamelCaseまたはsnake_caseを一貫して使用してください。
- 明確な凡例: 標記法が標準でない場合は、記号が定義されていることを確認してください。
- バージョン管理: 図は変化します。バージョンが現在のデータベース状態と一致していることを確認してください。
- メタデータ: 図自体に作成者名と更新日を含めてください。
- 論理的 vs. 物理的: 概念設計(ビジネスルール)と物理設計(データ型、インデックス)を区別してください。
曖昧さのトラブルシューティング 🔧
すべての図が完璧というわけではありません。曖昧な記号や情報の欠落に遭遇するかもしれません。そのギャップをどう扱うかを以下に示します。
カーディナリティの欠落
線に終端マークがない場合は、関係性が不明であると仮定してください。推測しないでください。開発チームに確認するか、システムテーブルを介してデータベーススキーマを直接確認してください。
不整合な外部キー
図面が関係を示しているが、データベースに外部キー制約がない場合、図面は古くなっています。実装作業では、実際に存在するデータベース構造を優先してください。
孤立したエンティティ
接続がないエンティティは、非推奨または誤ってモデル化されている可能性があります。それらをあなたの概念モデルから削除する前に、まだ使用されているかどうかを調査してください。
高度な考慮事項 🚀
基本を理解できたら、データモデルの解釈に影響を与えるこれらの高度な要素を検討してください。
1. 継承とスーパー型
一部の図面では、三角形や特別な線を使って継承を示します。これは、あるエンティティが別のエンティティの特殊化されたバージョンであることを意味します(例:Vehicleは、CarおよびBike).
- 共有属性:親から継承される。
- 固有の属性:子に固有のもの。
- 実装:通常、タイプカラムを持つ単一のテーブル、または共有キーを持つ複数のテーブルで処理される。
2. 再帰的関係
エンティティは自分自身と関係を持つことができます。これは承認ワークフローまたは階層データでよく見られます。
- 例:従業員が他の従業員を監督する。
- 視覚的表現:同じボックスに戻る線。
3. 弱いエンティティ
これらのエンティティは親が存在しないと存在できません。その主キーには親からの外部キーが含まれます。
- 視覚的表現:通常、二重の長方形で描かれる。
- 意味: 親を削除すると、子は自動的に削除されます。
スキーマ解釈についてのまとめ 📄
エンティティ関係図を読むことは、練習を重ねるほど向上するスキルです。すべての線をたどり、すべての制約を確認するには忍耐が必要です。図をエンティティ、属性、関係に分解することで、複雑な視覚情報をデータの論理的理解に変換できます。
図は動的な文書であることを思い出してください。システムの変化に応じて図も進化すべきです。図とコードの間に不一致を見つけたときは、データベースを真実の出所とみなしてください。図は意図を理解するためのものとして活用し、実行にはスキーマに頼りましょう。
この基盤があれば、どんなデータベースアーキテクチャにも対応できるようになります。ボトルネックを特定し、データの流れを理解し、情報の格納および管理方法についてステークホルダーと効果的にコミュニケーションできます。線の背後にある論理に注目すれば、技術的な詳細は自然と理解できます。