



堅牢なデータモデルを設計するには、エンティティや関係をマッピングするだけでは不十分です。データが時間とともにどのように変化するかを理解することが求められます。従来のエンティティ関係図(ERD)では、記録の状態を単一の時点でのみ捉えることがよくあります。給与の現在の値、ユーザーのアクティブなステータス、製品の最新価格などを保存します。しかし、ビジネスインテリジェンスや規制遵守の観点から、現在正しい情報だけでなく、過去にどのような状態であったかを知ることが求められることがあります。
ここに時系列データモデリングの導入が求められます。静的なスキーマを動的な履歴追跡システムに変換します。ERDに時間次元を直接組み込むことで、変更がすべて文書化され、監査可能でクエリ可能になり、変更がいつ行われたかという文脈を失うことなく、変更履歴を保持できます。このガイドでは、時系列対応データベースシステムを構築するために必要な構造的技術について探求します。
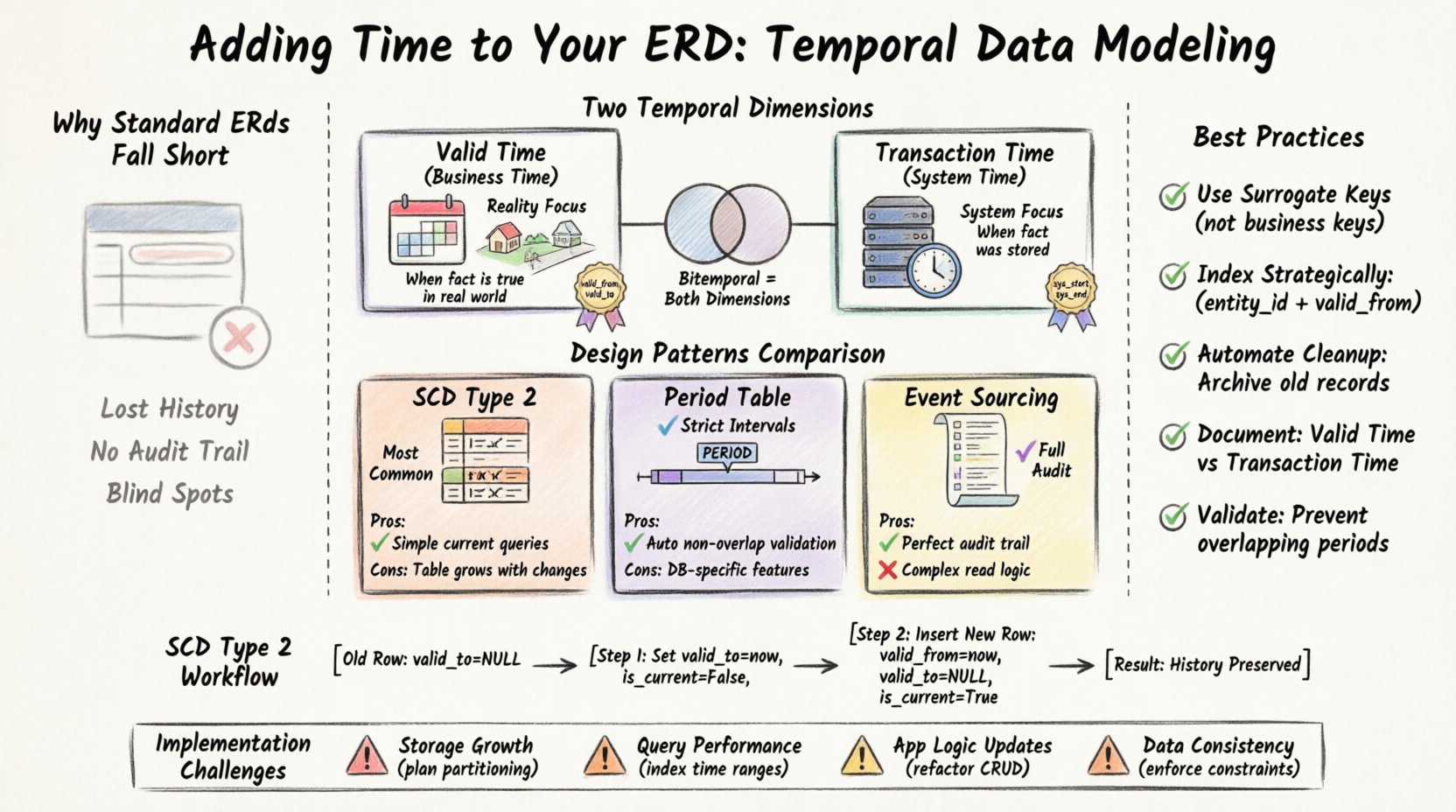
なぜ標準的なERDでは履歴管理に不十分なのか 📉
従来のERDは現在の状態に注目します。レコードが更新されると、古い値は通常上書きされます。これはシンプルな運用システムでは問題ありませんが、分析的なニーズには大きな盲点をもたらします。過去5年間の顧客の請求履歴を再構築する必要がある状況を考えてみましょう。標準的なテーブルでは、現在の住所や現在のサブスクリプションレベルしか表示されないかもしれません。
時系列モデリングがなければ、以下の課題に直面します:
- 文脈の喪失:現実世界で価格変更が実際に効力を持った時期と、システムに登録された時期の区別がつかない。
- 監査の複雑さ:別々の監査ログテーブルを構築するには、手動でトリガーを実装する必要があり、すべての書き込み操作にオーバーヘッドが発生する。
- クエリの難しさ:タイムラインを再構築するには、維持・最適化が難しい複雑な結合や自己結合が必要になることが多い。
- データ整合性:明確な時間制約がなければ、バッチ更新中に歴史データを誤って上書きしてしまうリスクが高くなる。
時間情報をスキーマに直接埋め込むことで、履歴追跡の責任をアプリケーションロジックからデータ構造自体に移すことができる。
時系列次元の理解 ⏳
時間を効果的にモデリングするには、データベース内での時間の異なる存在形態を区別する必要があります。考慮すべき主な2つの次元は、有効時間(Valid Time)と取引時間(Transaction Time)です。この違いを理解することは、適切なモデリング手法を選択するために不可欠です。
1. 有効時間(ビジネス時間)
有効時間とは、事実が現実世界で真実である期間を表します。これはデータベースシステムとは無関係です。たとえば、ある社員の部署が1月1日に営業部門からエンジニアリング部門に変更された場合、エンジニアリング部門への配置の有効時間はその日から始まります。HRマネージャーがシステムに登録した時期とは無関係です。
- 焦点:現実。
- 使用例:歴史的レポート作成、コンプライアンス監査、過去の状態の再構築。
- 属性:通常は、
valid_fromおよびvalid_toタイムスタンプで実装される。
2. 取引時間(システム時間)
トランザクション時間は、事実がデータベースに格納された時刻を追跡します。これはシステムによって完全に管理されます。ユーザーが今日レコードを編集した場合、トランザクション時間はその特定の瞬間を記録します。レコードが削除された場合、トランザクション時間はシステムがそのレコードがアクティブセットから見えなくなった時刻を把握できるようにします。
- 焦点:システム操作。
- 使用例:データ問題のデバッグ、特定の瞬間におけるシステム状態の理解、ロールバック機能。
- 属性:通常、データベースエンジンによって自動的に管理され、
sys_startおよびsys_end.
3. バイテンポラルデータ
有効時間とトランザクション時間の両方を必要とする場合、あなたはバイテンポラルテーブルを構築していることになります。これは時系列モデリングの最も包括的な形態です。例えば、「2023年1月1日の世界の実際の状態に関して、2023年3月1日にシステムが真実だと信じていたことは何だったか?」といった質問が可能になります。
時系列対応スキーマの設計パターン 🛠️
ERD内での時系列データの実装には、いくつかのアーキテクチャパターンがあります。選択は、クエリパターンとストレージ制約に依存します。
ゆっくり変化する次元(SCD)タイプ2パターン
これはデータウェアハウスにおける履歴追跡で最も一般的な手法です。行を更新するのではなく、新しいバージョン識別子をもつ新しい行を挿入します。古い行は非アクティブとしてマークされます。
- 主な追加項目:
surrogate_key(新しいバージョンにリンクするため)およびis_activeフラグ。 - 利点:フィルタを使用して現在のレコードを検索するシンプルなクエリ。
- 欠点: テーブルは変更に伴って線形に増大する。行の削除には、すべての以前のバージョンを更新するか、フラグを設定する必要がある。
期間テーブルパターン
このアプローチでは、時間は2つの別々の列ではなく、期間型として格納されます。これは現代のデータベースエンジンでしばしばネイティブにサポートされています。期間が重複しないことを強制します。
- 主な追加項目: A
期間データ型の制約。 - 利点:重複しない時間範囲の自動的な適用。
- 欠点:特定のデータベース機能を必要とするが、すべてのシステムで利用可能とは限らない。
イベントソーシングパターン
現在の状態を保存するのではなく、イベントのシーケンスを保存する。状態はこれらのイベントを再実行することで再構築される。非常に詳細ではあるが、読み取りには計算コストがかかることがある。
- 主な追加:追加のみ可能なログテーブル。
- 利点:完全な監査証跡;データは決して削除されない。
- 欠点:読み取りロジックが複雑になる;状態の再構築は即時ではない。
SCD Type 2アプローチの詳細 🔄
大多数の企業向けアプリケーションにおいて、SCD Type 2は複雑さと有用性の最適なバランスを提供する。これがERD構造にどのように対応するかを見てみよう。
以下のような状況を想像してみよう:顧客エンティティ。標準モデルでは、顧客IDごとに1行となる。時間に基づいて区別される時間的モデルでは、同じ顧客IDに対して複数の行が存在する。
必須属性:
顧客ID:自然なビジネスキー。バージョンID:各レコードインスタンスの固有識別子。有効開始日時:このレコードが有効になった日時。有効終了日時:このレコードが有効でなくなった日時。現在のレコードの場合、多くの場合NULLに設定される。現在有効フラグ:最新の状態を素早く識別するためのブール値フラグ。
顧客の住所が変更された場合、既存の行を更新しないでください。代わりに、次の手順を実行します:
- 次のフィールドを更新します:
valid_to古い住所行の値を現在のタイムスタンプに更新します。 - 次のフィールドを設定します:
is_current古い行の値を False に設定します。 - 新しい住所を含む新しい行を挿入します。
- 次のフィールドを設定します:
valid_from現在のタイムスタンプに設定します。 - 次のフィールドを設定します:
valid_toNULL に設定します。 - 次のフィールドを設定します:
is_currentTrue に設定します。
期間テーブルと有効時間 🗓️
SCD Type 2 は柔軟ですが、期間テーブルは時間の定義をより厳密にします。このモデルでは、時間間隔が単一の属性となります。これにより、valid_fromがvalid_to.
以下に、期間テーブルのスキーマ構造を示します:
| 列名 | 型 | 説明 |
|---|---|---|
entity_id |
UUID | エンティティの主キー |
データ値 |
VARCHAR | 追跡対象の属性 |
時間期間 |
PERIOD(TIMESTAMP) | 有効期間の開始と終了 |
システムバージョン |
INT | 行のシーケンス番号 |
この構造により、データベースエンジンが挿入前に時間間隔を検証することが保証されます。同じエンティティに対して既存の期間と重複するレコードを挿入しようとすると、明示的に許可されない限り、操作は失敗します。
トランザクション時間の取り扱い 📝
有効時間は、何が真であったかを教えてくれます。トランザクション時間は、いつそれを知ったかを教えてくれます。場合によっては、その事実が現実世界で後に誤りであると証明されたとしても、データベースがその事実を真であると信じていたことを知る必要があります。
例えば、ユーザーが誤った住所を入力する場合があります。システムはその情報をトランザクション時間とともに記録します。その後、ユーザーがそれを修正します。有効時間のみを追跡すると、初期の誤りの記録を失います。トランザクション時間を追跡すれば、データ入力のシステム履歴を保持できます。
トランザクション時間を実装するには、通常、これらのカラムをユーザーインターフェースから非表示にする必要があります。これらのカラムはデータベースエンジンによって管理されます。現在の状態を照会する際、システムは自動的にトランザクション時間が期限切れになったレコード(つまり、レコードが削除されたもの)を除外します。
バイテンポラルモデリングの説明 ⚖️
バイテンポラルモデリングは、有効時間とトランザクション時間を組み合わせます。これは規制遵守およびフォレンジックデータ分析のゴールドスタンダードです。
スキーマへの影響:
- 4つの時間関連のカラムが必要です:
有効開始,有効終了,トランザクション開始,トランザクション終了. - インデックス戦略は、両方の次元を考慮する必要があります。
- クエリはより複雑になり、しばしば範囲結合を必要とします。
クエリ例の論理:
特定の時点でのレコードの状態を調べるには、トランザクション時間を基準にフィルタリングします。特定の時点での世界の状態を調べるには、有効時間を基準にフィルタリングします。特定の時点でのシステムが認識していた世界の状態を調べるには、両方を基準にフィルタリングします。
この粒度の細かさは、データの出所がデータそのものと同じくらい重要となる金融、医療、法務などの業界において不可欠です。
実装上の課題 ⚠️
ERDに時間を追加すると、注意深く管理しなければならない複雑性が生じます。
1. ストレージの肥大化
すべての変更が新しい行を作成します。数年経過すると、時間的属性を持たないテーブルと比べて、テーブルのサイズは著しく大きくなります。ストレージ要件の増加を予測する必要があります。時間範囲(例:月単位または年単位)でパーティショニングするという手法は、クエリを高速に保ち、メンテナンスを容易にするための一般的な戦略です。
2. クエリのパフォーマンス
時間範囲でフィルタリングする場合は、適切にインデックスが設定されていれば一般的に高速です。しかし、歴史的状態を再構成するには複数のテーブルを結合する必要があることが多くあります。数百万行を含む履歴テーブルをスキャンするクエリの場合、もともとミリ秒で終わっていたものが数秒かかるようになることがあります。
3. アプリケーションロジックの変更
1つのエンティティに対して1行しか存在しないと仮定している既存のアプリケーションコードは破綻します。すべてのCRUD操作を時間属性を扱えるように再設計する必要があります。挿入操作は条件付きのロジック更新に変わります。
4. データの一貫性
以下を保証すること:有効開始日時は常に有効終了日時データベースの制約が必要です。これらの制約がなければ、歴史的レポートを破綻させる無効な期間を作成するリスクがあります。
保守のためのベストプラクティス 🧹
時間的モデルを健全に保つためには、以下のガイドラインに従ってください。
- サロゲートキーを使用する:履歴テーブルには、ビジネスキーではなく内部IDを常に使用する。これにより、ビジネスキーが変更されても参照整合性が保たれます。
- 戦略的にインデックスを設定する: (
エンティティID,有効開始日時) に複合インデックスを作成する。これにより、現在のレコードや歴史的スナップショットの検索が高速化される。 - クリーンアップを自動化する:アーカイブポリシーを実装する。レコードが10年以上経過した場合は、アクティブテーブルを軽く保つために、冷蔵ストレージテーブルに移動する。
- タイムラインを文書化する:データ辞書内で、有効時間とトランザクション時間の違いを明確に記録する。開発者は、自分のユースケースにどのタイムスタンプが適用されるかを把握する必要がある。
- 重複を検証する: 同じエンティティの有効期間が重複しないように、データベースの制約を使用する。
時系列戦略の比較
適切なモデルを選択するには、あなたの具体的なニーズに応じて判断する必要がある。以下の表は、それぞれのトレードオフを要約している。
| 戦略 | 複雑さ | ストレージコスト | クエリ速度 | 最適な使用ケース |
|---|---|---|---|---|
| SCDタイプ2 | 中程度 | 中程度 | 高 | 一般的なビジネス履歴追跡 |
| 期間テーブル | 高 | 中程度 | 高 | 厳格な規制遵守 |
| バイテンポラル | 非常に高い | 高 | 中程度 | 法医学的分析、システム監査 |
| イベントソーシング | 高 | 非常に高い | 低(読み取り) | 状態の再構築、リアルタイムフィード |
データアーキテクトの最終的な検討事項
エンティティ関係図に時間を組み込むことは、データのライフサイクルに影響を与える意思決定である。これは単なる技術的な調整ではなく、情報の捉え方そのものを変えるものである。
時間を意識して設計するとき、データは静的ではないことを認識します。データは流れ、変化し、時を経て古くなります。これらの機能をスキーマの基盤に組み込むことで、過去の分析が必要になるリスクからシステムを未来に備えて守ることができます。
まず、システム内のどの属性が本当に履歴を必要としているかを特定しましょう。すべてのカラムにタイムスタンプが必要なわけではありません。財務残高や人員配置、製品価格といった高価値のデータポイントに注目してください。不要なオーバーヘッドを避けるために、時間的パターンを選択的に適用しましょう。
システムが成熟するにつれて、初期の設計を見直す必要があることに気づくかもしれません。時間的データモデルは反復的なものです。クエリのパフォーマンスとストレージの増加を監視し、履歴データの量が増えるに従って、パーティショニングやインデックス戦略を調整しましょう。
結局のところ、時間認識型のERDは、過去を尊重しながら現在を支える唯一の真実の情報源を提供します。何かが「なぜ」起こったかという疑問が生じたとき、その答えはすでにデータベースに記録されており、取得を待っている状態です。