











堅牢なデータベーススキーマを設計することは、ソフトウェア工学における基盤的なステップである。このアーキテクチャの設計図がエンティティ関係図(ERD)である。ERDはデータの構造を可視化し、異なる情報の塊が互いにどのように関係しているかを定義する。機能的な図はデータの整合性を保証するが、クリーンで保守可能な図は、システムが時間の経過とともに理解しやすく、適応しやすい状態を保つことを保証する。技術的負債はしばしばコードそのものに蓄積されるのではなく、陳腐化したり混乱を招くことになる文書や設計アーティファクトに蓄積される。このガイドは、時代に抗するERDを作成するための基本原則を概説する。
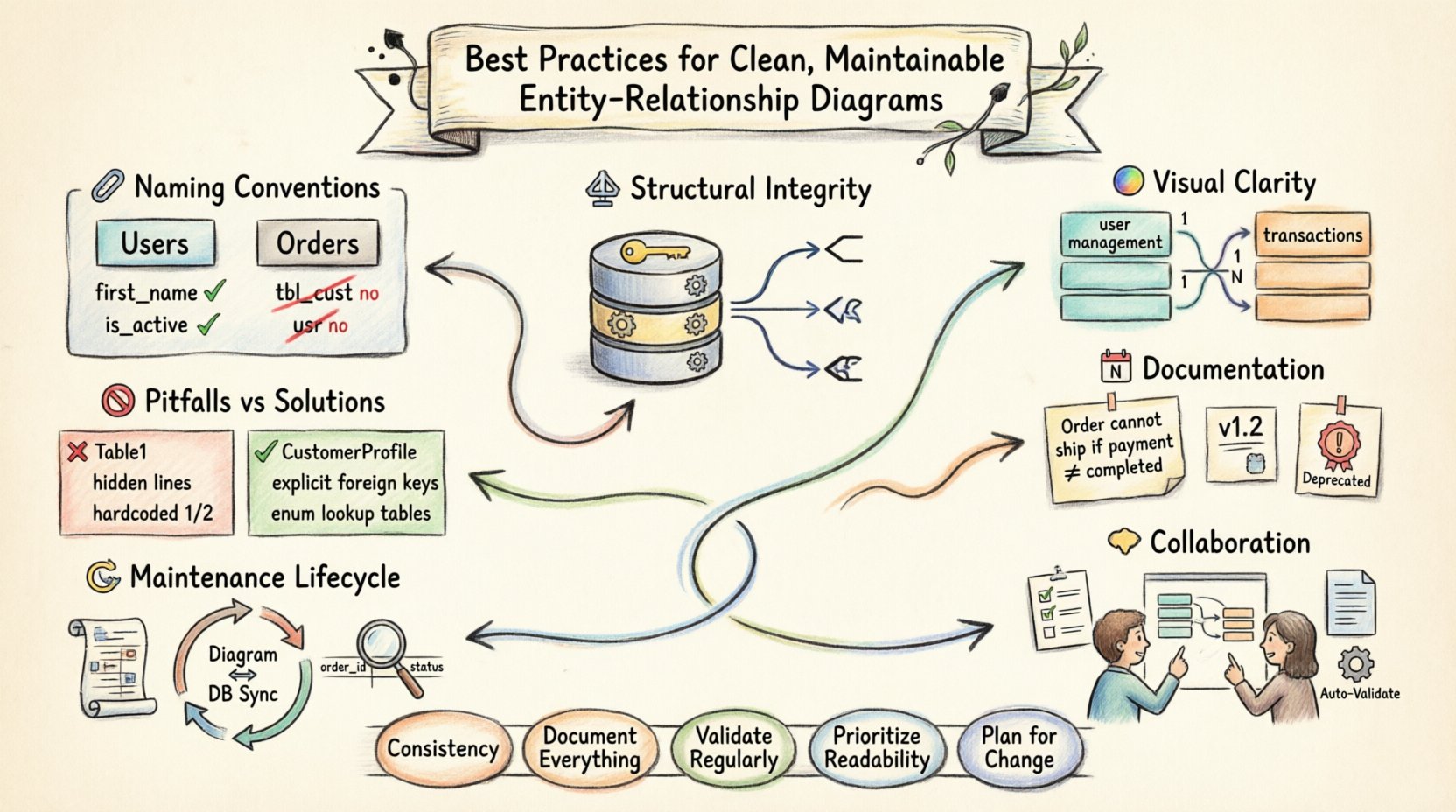
1. 名前付けの規則と基準 🏷️
エンティティまたは属性の名前は、スキーマを確認する開発者にとって最初の接触点である。一貫性のない名前付けは摩擦を生み、オンボーディングを遅らせるだけでなく、開発中のエラーの可能性を高める。標準化された名前付け戦略は単なる美観の問題ではない。それはコミュニケーションのプロトコルなのである。
エンティティの名前付けルール
- 複数形化:エンティティは一般的に複数形で命名すべきである(例:
Users,Orders)。これはレコードの集合を表すためである。単数形の名前(例:User)はシングルトンインスタンスを示す可能性があり、これはリレーショナルテーブルではめったにない。 - キャメルケースかスネークケース:一つのスタイルを選択し、一貫して適用する。キャメルケース(例:
CustomerOrder)はオブジェクト指向の文脈で一般的である。一方、スネークケース(例:customer_order)はSQL環境で好まれることが多い。スタイルの混在は避けるべきである。 - 記述性:名前は含まれるデータを正確に説明しなければならない。
tbl_custやordといった省略形を避ける。省略形が必要な場合は用語集を定義する。CustomerをCust. - 予約語の回避: エンティティ名がデータベースの予約語と衝突しないようにしてください(例:
グループ,注文,キー)。衝突を避けられない場合は、名前を引用符で囲むか、接頭辞を付けるようにしてください。ただし、名前の変更が望ましいです。
属性名の命名規則
- 小文字標準: 属性名に小文字を使用することで、異なるデータベースエンジン間で大文字小文字を区別しない動作を保証します。
FirstNameはfirst_name. - 外部キーに接頭辞を付ける: 他のエンティティを参照する場合、外部キーは参照先エンティティの主キー名と一致するのが理想的です。多くの場合、ソースを示す接尾辞やターゲットを示す接頭辞を付けることになります。たとえば、
Usersテーブルにuser_idがある場合、Ordersテーブルはそれをuser_id. - 論理値の明確性: 論理値属性は、質問形式や明確なフラグとして名前を付けるべきです(例:
is_active,has_subscription)のように、一般的なフラグ(例:ステータスまたはフラグ.
2. 構造的整合性と正規化 ⚖️
見た目は良いが正規化の原則に違反する図は、データ異常を引き起こす。保守性には、構造が効率的なクエリをサポートし、冗長性を最小限に抑えることが求められる。
主キー
- 明示的な宣言: すべてのテーブルには明確に定義された主キーが必要である。ドキュメントなしでデータベースエンジンが暗黙的に主キーを生成することに頼ってはならない。
- 代替キー: 自然キー(メールアドレスや社会保障番号など)ではなく、代替キー(自動増分整数またはUUID)を使用することを検討する。自然キーは変更される可能性があり、データベース全体に連鎖的な更新を必要とし、リスクが高くコストがかかる。
- 複合キー: 論理的に必要である場合(例:多対多の結合テーブル)にのみ複合キーを使用する。主要なエンティティにはそれらを使用しないようにし、インデックス化や関係性の管理を複雑にしないようにする。
外部キーと参照整合性
- 関係を定義する: すべての外部キーは図上で明示的に定義しなければならない。命名規則によって関係が暗黙に示されるだけではいけない。
- 連鎖ルール: 削除および更新の動作を文書化する。親が削除されたときに子レコードも削除されるべきか?あるいはNULLにすべきか?これらのルール(CASCADE、SET NULL、RESTRICT)は設計文書に明示されなければならない。
- 循環依存を避ける: 関係性が循環依存を生じ、結合が不可能になるか、パフォーマンスが予測不能になることを防ぐ。
3. 視覚的明確性とレイアウト 🎨
ERDは視覚的なツールである。レイアウトが混乱していると、データモデルの理解が難しくなる。視覚的な階層構造が、読者がシステムのアーキテクチャを一目で理解するのを助ける。
グループ化と整理
- 機能別グループ化: 関連するエンティティをまとめて配置する。たとえば、すべてのユーザー管理テーブルを近くに配置し、すべての取引関連テーブルを別々のクラスタとして配置する。
- 論理的分離: 読み取り専用データと書き込みが頻繁なデータを分離する。システムにレポート用テーブルがある場合は、運用用テーブルと視覚的に区別する。
- 方向性の流れ: 図を配置する際にデータの流れを示すようにする。通常、これは主要な参照データを上部または左側に配置し、取引データやログデータを下部または右側に配置することを意味する。
接続線
- 直交ルーティング:可能な限り対角線ではなく直角の線を使用する。対角線は頻繁に交差し、視覚的なノイズを生じる。
- 交差を最小限に抑える:関係線の交差回数を減らすために、エンティティの位置を調整する。交差する線は関係の経路を隠してしまう。
- 基数表記:標準的な表記法(クロウズフット、チェン、またはUML)を一貫して使用する。「1」と「多」の端が明確にマークされていることを確認する。線の太さや色だけに頼って基数を示してはならない。
4. ドキュメント化とメタデータ 📝
図自体だけでは不十分である。メタデータが、設計意思決定の背後にある「なぜ」を理解するために必要な文脈を提供する。
コメントと注釈
- ビジネスロジック:特定のビジネスルールを説明するノートを追加する。たとえば、「Orders」テーブルに注釈を付けることで、支払いステータスが「完了」でない限り注文を出荷できないことを説明できる。
注文テーブルには、支払いステータスが「完了」でない限り注文を出荷できないと説明する完了. - 制約:一意制約、チェック制約、デフォルト値を文書化する。これらは、スキーマの視覚的表示だけを見た場合、しばしば失われてしまう。
- 非推奨フラグ:エンティティまたは属性が非推奨だが、後方互換性のために保持されている場合、明確にマークする。隠さず、レガシーコードでまだ参照されている可能性があるためである。
バージョン管理
- 変更履歴:変更履歴を維持する。誰がスキーマを変更したのか?いつ?なぜ?これはプロダクションの問題をデバッグする上で不可欠である。
- バージョン番号:図にバージョン番号(例:v1.0、v1.1)を付与する。複数のデータベースマイグレーションが進行中の場合、混乱を防ぐためである。
5. コラボレーションとレビュー手順 🤝
データベース設計は稀に単独作業である。バックエンドエンジニア、データアナリスト、ビジネス関係者からの入力を必要とする。
同僚レビュー
- 独立した監査:設計を書いた開発者以外の開発者がレビューを行う。新しい目が論理的な穴や命名の不一致を発見する。
- ドメイン専門家の検証: モデルがビジネスドメインを正確に反映していることを確認する。データモデラーはテーブルを見ることができるが、ビジネスアナリストはそのテーブルが実際のワークフローを表しているかどうかを知っている。
ツールと標準
- 標準化されたテンプレート: 組織内の異なるプロジェクト間で一貫性を確保するために、すべての図にテンプレートを使用する。
- 自動検証: 図を実際のデータベーススキーマと照合するためのツールを使用する。図とコードの間にずれが生じることは、一般的なエラーの原因である。
6. メンテナンスライフサイクル 🔄
デプロイされた後、ERDは静的ではない。進化する。この進化を維持するには、規律が必要である。
スキーマのずれ管理
- 定期的に同期する: 定期的に本番データベースから図を再生成し、現実と一致していることを確認する。
- マイグレーションスクリプト: ERDのすべての変更にはマイグレーションスクリプトが対応しなければならない。図を更新せずにデータベースを手動で変更してはならない。
- 影響分析: 主キーを変更する前や列を削除する前には、どの下流のレポートやアプリケーションがその項目に依存しているかを分析する。
パフォーマンス上の考慮事項
- インデックス戦略: どの列がインデックス化されているか、そしてその理由を文書化する。これにより、将来の開発者がクエリ最適化の意思決定を理解しやすくなる。
- パーティショニング: テーブルが非常に大きくなる場合は、図にパーティショニング戦略を記載する。これはデータの照会や保守に影響を与える。
7. 一般的な落とし穴と反パターン 🚫
ベストプラクティスを守ることと同じくらい、ミスを避けることが重要である。以下は、一般的な誤りと推奨されるアプローチの比較である。
| 落とし穴 | 推奨されるアプローチ | 理由 |
|---|---|---|
| 一般的な名前 例: Table1, Data |
明確な名前 例えば、 CustomerProfile, ProductInventory |
明確な名前を付けることで、開発者は外部のドキュメントなしでデータの内容を理解できる。 |
| 隠された関係性 テーブル間に線が引かれていない |
明示的な外部キー 線が明確に描かれてラベル付けされている |
暗黙の関係性はデータの整合性の侵害や混乱を引き起こす。 |
| 過剰な正規化 あまりにも多くの小さなテーブル |
適切な正規化 3NFとパフォーマンスのニーズのバランス |
過度な結合はクエリのパフォーマンスを著しく低下させる。 |
| メタデータの欠落 説明や型がない |
豊富なメタデータ データ型、制約、コメントを含める |
メタデータは導入時および長期的な保守において不可欠である。 |
| ハードコードされた値 ステータスコードなど 1, 2図の中の |
列挙型 参照テーブルまたは明示的な列挙型を使用する |
凡例がないとハードコードされた整数は意味を持たず、変更されやすい。 |
長期的な持続可能性に関する結論
クリーンなERDを作成することは、プロジェクトの将来への投資です。開発者の認知負荷を軽減し、データ破損のリスクを最小限に抑え、システムが完全な再構築なしで進化できることを保証します。厳格な命名規則を遵守し、視覚的な明確性を保ち、メタデータを文書化することで、スケーラブルな成長を支える基盤を構築できます。今日の設計に費やす努力は、明日の保守の混乱を防ぎます。
ERDは動的な文書であることを忘れないでください。それが表すソースコードと同様の注意深さとバージョン管理が必要です。定期的なレビュー、基準への準拠、正確性へのコミットメントが、データアーキテクチャの強靭さとチームの生産性を維持します。
主なポイント ✅
- 一貫性が鍵です:プロジェクト全体を通して、一つの命名規則と一つの視覚スタイルに従ってください。
- すべてを文書化する:コードが自らを説明すると仮定しないでください。ビジネスロジックや制約についてコメントを追加してください。
- 定期的に検証する:図面が実際のデータベース状態と一致していることを確認し、ずれを防ぎましょう。
- 可読性を最優先する:図面が読みにくい場合、保守も難しくなります。接続を簡略化し、論理的にグループ化してください。
- 変化に備える:将来を見据えて設計してください。可能な限り擬似キーを使用し、ハードな依存関係を避けてください。