











ソフトウェア開発およびデータ管理の世界では、堅牢なデータベース構造を設計する能力は基盤となるスキルです。エンティティ関係図(ERD)は、データがどのように整理され、保存され、取得されるかの設計図として機能します。採用担当者や技術系リクルーターにとって、あなたのポートフォリオに丁寧に作成されたERDが含まれていることは、データの整合性、関係性、システムアーキテクチャに対する理解を即座に示す証拠となります。 🗂️
このガイドでは、初心者から上級者まで幅広いレベルの具体的なプロジェクトアイデアを紹介します。各スキーマの設計の論理を説明することで、流行語や営業的な表現に頼らず、深い技術的実力を示すポートフォリオの構築を支援します。この記事の最後まで読むことで、求職活動で目立つERDを作成するための明確なロードマップが得られます。
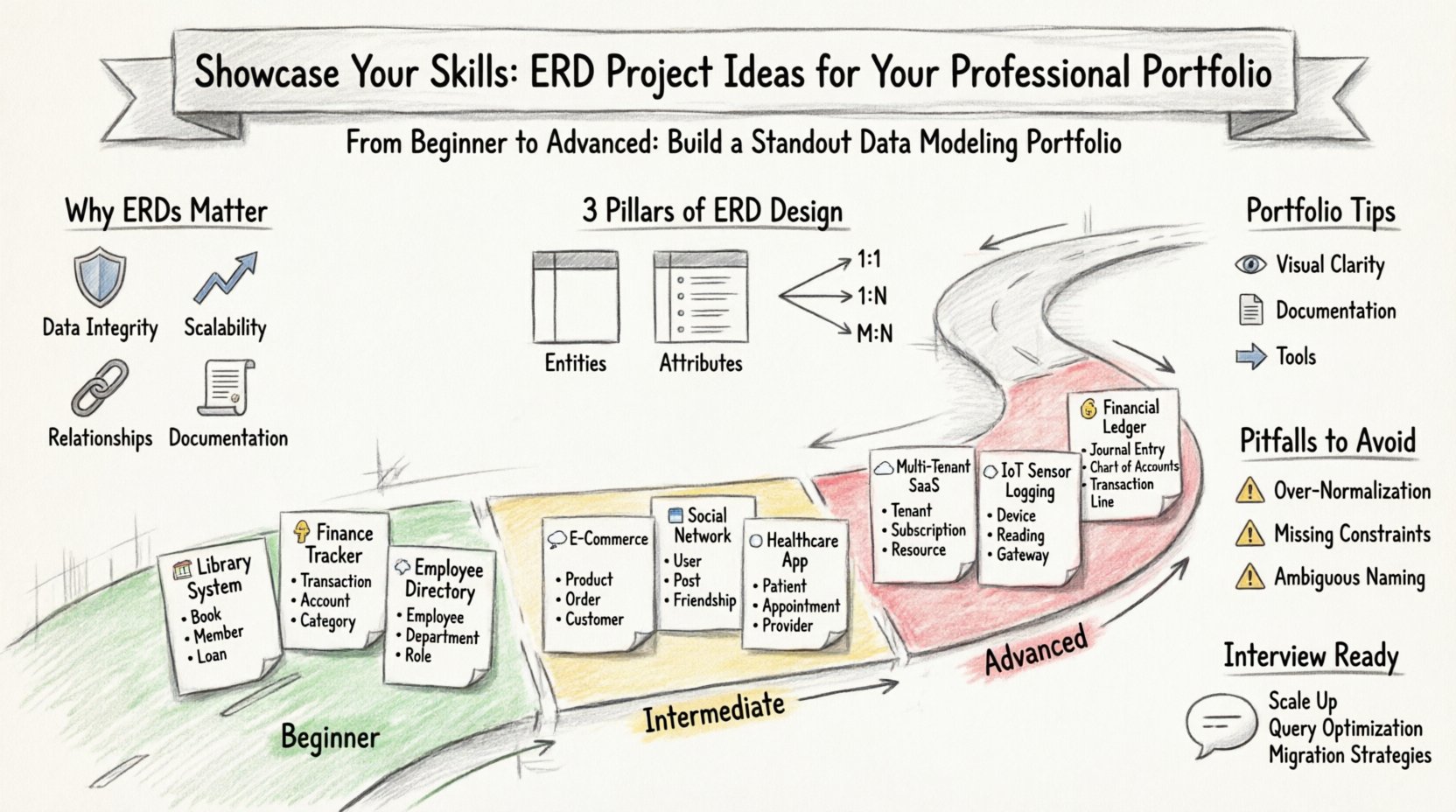
なぜERDはあなたのポートフォリオで重要なのか 📊
コードスニペットは、構文を書けることを示しますが、ERDはあなたが考えられる能力を示します。プロジェクトを潜在的な雇用主に提出する際、彼らはデータの複雑さをどう扱うかを知りたがります。強力なERDは以下の点を示します:
- データ整合性: 正規化を通じて異常を防ぐ方法を理解しています。
- スケーラビリティ: ユーザーの需要に応じて拡張できるスキーマを設計できます。
- 関係性: 外部キーと結合操作のニュアンスを理解しています。
- ドキュメント化: ステークホルダーに複雑な構造を伝えることができます。
リクルーターはしばしば設計の背後にある「なぜ」に注目します。ここでは多対多の関係を選んだのはなぜですか?このテーブルは第三正規形を違反していますか?これらの質問に備えておくことは、図自体と同等に重要です。
強力なERD設計の基盤 🧩
具体的なプロジェクトアイデアに取り組む前に、ERDを効果的にするための核心的な要素を確認することが不可欠です。すべての図は3つの柱、すなわちエンティティ、属性、関係性に依存しています。
1. エンティティとテーブル
エンティティは、データを保存する必要がある現実世界のオブジェクトや概念を表します。データベースでは、これはテーブルに相当します。良いエンティティ名は単数形で、明確な説明を含むべきです。たとえば、”顧客“ではなく”顧客たち、そして”請求書“ではなく”請求書記録.
2. 属性とカラム
属性はエンティティの性質を定義します。各属性には明確なデータ型を設定する必要があります。複雑なオブジェクトを1つのフィールドに保存しないようにしましょう。たとえば、”住所という1つのフィールドではなく、以下のように分解することを検討してください通り, 市, 州、および郵便番号検索および並べ替えを容易にするために。
3. 関係性と基数
関係性はエンティティがどのように相互作用するかを定義します。基数を理解することは非常に重要です:
- 1対1 (1:1):Table A の1レコードが Table B の1レコードにのみ関連します。例:個人とそのパスポート。
- 1対多 (1:N):Table A の1レコードが Table B の複数のレコードに関連します。例:1人の著者が多くの本を執筆する。
- 多対多 (M:N):Table A の複数のレコードが Table B の複数のレコードに関連します。例:学生と授業。通常、中間テーブルが必要です。
初心者向けプロジェクト 🟢
初心者の方は、明確さと基本的な正規化に注目してください。これらのプロジェクトは、過剰な設計をせずにシンプルなビジネスルールをモデル化できることを示すべきです。
1. 図書館管理システム 📚
在庫管理、貸出、ユーザー管理をカバーする古典的なプロジェクトです。1対多および多対多の関係を示すのに非常に適しています。
- 主要なエンティティ:
- 書籍: ISBN、タイトル、出版年、ジャンル、在庫数
- 著者: 著者ID、名前、略歴
- 会員: 会員ID、名前、メールアドレス、入会日、ステータス
- 貸出: 貸出ID、書籍ID、会員ID、貸出日、返却期限、返却日
- 設計ロジック:
- A 書籍は複数の著者(M:N)、結合テーブルが必要です。
- A 会員は複数の書籍(1:N、貸出テーブル経由)。
- 使用する返却日をnull可能として、未返却の貸出を示す。
2. 個人財務トラッカー 💰
財務データには正確性が求められます。このプロジェクトは、データ型(小数 vs 整数)と履歴追跡の重要性を強調しています。
- 主要なエンティティ:
- 口座: 口座ID、口座名、残高、種別(普通預金/貯蓄預金)
- 取引: 取引ID、口座ID、金額、日付、カテゴリ、種別(貸方/借方)
- カテゴリ: カテゴリID、名前、親カテゴリID
- 設計ロジック:
- 使用する小数通貨には小数型を使用して、浮動小数点エラーを回避する。
- 実装する自己参照関係カテゴリテーブルに階層的な予算管理(例:食料 > 食材)用の自己参照関係を実装する。
- すべての取引が正確に1つの口座に紐づいていることを確認する。
3. 従業員ディレクトリ 👥
シンプルだが、階層構造のデータ構造や自己参照関係を示すのに効果的である。
- 主要なエンティティ:
- 従業員: 従業員ID、名前、役割、採用日、マネージャーID
- 部署: 部署ID、部署名、予算
- 設計論理:
- このマネージャーID従業員テーブル内のマネージャーIDは、従業員テーブル自身を指す外部キーである。これにより再帰的関係が作成される。
- 各従業員は1つの部署.
- 以下のような休暇申請テーブルを追加して取引履歴を表示する。
中級レベルのプロジェクト 🟡
この段階では、複雑なビジネスルール、同時実行性、より複雑な正規化要件を扱う必要がある。これらのプロジェクトは、現実世界の複雑さに対処できる能力を示している。
4. インターネット通販プラットフォーム 🛒
オンラインで製品を販売するには在庫管理、注文、支払い、レビューが必要である。これはバックエンド職にとって高価値のプロジェクトである。
- 主要なエンティティ:
- 製品: 製品ID、名前、説明、基本価格、SKU
- 注文: 注文ID、顧客ID、注文日、ステータス、配送先
- 注文項目: 注文項目ID、注文ID、製品ID、数量、購入時の価格
- 顧客: 顧客ID、メールアドレス、パスワードハッシュ、請求先住所
- レビュー: レビューID、製品ID、顧客ID、評価、コメント
- 設計論理:
- 重要な決定:以下の情報を保存する購入時の価格 に注文アイテム。製品の価格が後で変更された場合でも、過去の注文記録は正確なまま維持されるべきである。
- 以下の関係を使用する多対多 関係を顧客 と製品 注文/注文アイテム構造を介して実現する。
- 廃止された製品に対しては、データベースから削除するのではなく、ソフト削除フラグを実装する。
5. ソーシャルネットワーキングアプリ 📱
ソーシャルグラフは伝統的に複雑である。このプロジェクトは、関係性やコンテンツフィードをモデル化する能力を示している。
- 主要エンティティ:
- ユーザー: ユーザーID、ユーザー名、プロフィール画像、自己紹介
- 投稿: 投稿ID、ユーザーID、コンテンツ、タイムスタンプ
- フォロー: フォロワーID、フォローアップ相手ID、フォロー日
- コメント: コメントID、投稿ID、ユーザーID、コンテンツ
- 設計論理:
- The 以下に示す テーブルは、多対多関係の結合テーブルです。
- 以下のブロック テーブルを追加して、ユーザー制限を管理します。
- 以下の項目にインデックスを使用して、タイムスタンプフィード取得クエリの最適化を行います。
- 参照整合性を確保して、既存の投稿やコメントがあるユーザーの削除を防ぎます。
6. 医療予約システム 🏥
医療データは厳格なプライバシー保護とスケジューリング論理を必要とします。これにより、制約の取り扱いが強調されます。
- 主要なエンティティ:
- 患者: 患者ID、氏名、生年月日、保険証番号
- 医師: 医師ID、氏名、専門分野
- 予約: 予約ID、患者ID、医師ID、開始時刻、終了時刻、理由
- 医療記録: 記録ID、患者ID、医師ID、診断、メモ
- 設計論理:
- 時間枠:同じ医師の予約が重複しないように、開始時刻 および 終了時刻 同じ医師の予約が重複しないようにします。
- 履歴: 患者は時間の経過とともに、同じ医師から複数の記録を持つことができます。
- プライバシー: 敏感なフィールドは、アプリケーション層で論理的に分離するか、暗号化する必要があります。
上級者向けプロジェクト 🔴
上級職のポジションでは、スケーラビリティ、マルチテナント、監査トレースの理解を示す必要があります。これらのスキーマは高負荷環境を想定して設計されています。
7. マルチテナントSaaSアーキテクチャ ☁️
ソフトウェアとしてのサービス(SaaS)プラットフォームは、単一のインスタンスで多数の組織をサポートします。このような設計には、慎重な分離戦略が必要です。
- 主要なエンティティ:
- テナント: テナントID、名前、サブスクリプションプラン
- ユーザー: ユーザーID、テナントID、メールアドレス、役割
- データレコード: レコードID、テナントID、ユーザーID、ペイロード、作成日時
- 設計ロジック:
- テナントの分離: すべてのテーブルには テナントID 外部キーがあり、データの分離を保証する必要があります。
- グローバル vs. ローカル: スキーマを共有する(安価だが分離が難しい)か、テナントごとに別々のスキーマを使用する(高価だが安全)かを決定します。
- パフォーマンス: クエリが常に テナントID WHERE句に含めるようにし、テナント間のデータ漏洩を回避します。
8. IoTセンサーのデータ記録 📡
インターネット・オブ・シングスは膨大な量の時系列データを生成します。このプロジェクトは、ストレージ効率と時系列クエリに焦点を当てています。
- 主要なエンティティ:
- デバイス: デバイスID、デバイスタイプ、場所、設置日
- 読み取り値: 読み取りID、デバイスID、センサータイプ、値、タイムスタンプ
- アラート: アラートID、デバイスID、しきい値、発動時刻、解決時刻
- 設計論理:
- パーティショニング: その 読み取り テーブルは成長を管理するために、時間(例:月単位)でパーティショニングされるべきである。
- 圧縮: 値を効率的に保存し、センサデータに最適化された特定のデータ型を使用する可能性がある。
- 保持: アクティブなデータベースのパフォーマンスを維持するために、古い読み取りデータのアーカイブ方針を定義する。
9. 金融取引台帳 💸
金融システムは絶対的な正確性を要求する。二重簿記の原則はスキーマに反映されなければならない。
- 主要なエンティティ:
- 口座: 口座ID、口座タイプ、残高
- 取引: 取引ID、日付、説明
- 仕訳: 仕訳ID、取引ID、口座ID、借方金額、貸方金額
- 設計論理:
- 原子性: すべての取引には、少なくとも1つの借方と貸方の仕訳があり、その合計がゼロになる必要がある。
- 不変性: レジャーエントリを決して更新しない。エラーが発生した場合は、逆仕訳を作成する。
- 同時実行: 残高を更新する際のレースコンディションを防ぐために、ロックメカニズムを使用する。
ポートフォリオを効果的に提示する 📝
図を作成することは、戦いの半分に過ぎない。どのように提示するかが、レビュアーがあなたの意図を理解できるかどうかを決める。影響を最大化するために、これらのガイドラインに従ってください。
1. ドキュメント作成の基準 📄
文脈のない図は混乱を招きます。各プロジェクトにREADMEファイルまたは説明セクションを含め、以下の内容を記載してください:
- ビジネス的文脈:このデータベースが解決しようとしている問題は何ですか?
- 前提条件:どのようなルールを正しいと仮定しましたか?(例:「ユーザーは1つのアクティブなサブスクリプションしか持てない。」)
- 正規化:なぜ3rd Normal Form(3NF)で停止したのか、またはパフォーマンス向上のための逸脱をした理由を簡潔に説明してください。
2. 視覚的明確さ 👁️
ERDが読みやすいことを確認してください。不要な線の交差を避けてください。一貫した命名規則(例:カラムにはcamelCase、テーブルにはPascalCase)を使用してください。可能であれば、高レベルのビューと詳細なビューの両方を提供してください。
3. ツールとフォーマット
図をPNGやSVGなどの標準フォーマットでエクスポートしてください。レビュー者が開けないプロプライエタリなファイル形式に頼らないでください。ズームインした際にもテキストが読みやすいように、十分な解像度を確保してください。
避けるべき一般的な落とし穴 ⚠️
経験豊富なデザイナーでもミスを犯します。提出前にこのチェックリストに基づいて自分の作業を確認し、ミスを発見してください。
| 落とし穴 | 影響 | 解決策 |
|---|---|---|
| 過剰な正規化 | 結合が多すぎるとクエリの実行が遅くなる。 | 読み込みが重い操作のために、特定のフィールドを非正規化する。 |
| 制約の欠如 | データ整合性のリスク(例:負の年齢)。 | CHECK制約とNOT NULLフラグを追加する。 |
| 曖昧な命名 | 開発中に混乱が生じる。 | 説明的な名前を使用する(例:created_at vs date1). |
| ハードコードされた値 | スキーマが硬直化し、変更が難しくなる。 | ステータスコードやカテゴリには照合テーブルを使用する。 |
| タイムゾーンを無視する | 地域間で誤ったタイムスタンプが発生する。 | UTCで保存し、アプリケーション層で変換する。 |
面接準備 🗣️
これらのプロジェクトをポートフォリオに掲載したら、自分の選択を説明できる準備を整えておこう。面接官はしばしば「もしも~だったら?」というシナリオを尋ね、柔軟な対応力を試す。
- スケーリングアップ:「このテーブルが1億行にまで成長した場合、どうなるか?」インデックス戦略、パーティショニング、シャーディングについて準備して議論できるようにしよう。
- クエリ最適化:「支出額の上位10人のユーザーをどう見つけますか?」フィルタリングとソートのアプローチを説明してください。
- 変更:「この構造を変更する必要がある新しい機能を追加するにはどうしますか?」マイグレーション戦略と後方互換性について議論しよう。
構文だけでなく、設計の背後にある論理に注目することで、上級者レベルの思考を示すことができる。雇用者はトレードオフを判断し、技術的決定を正当化する能力を重視する。これらのプロジェクトアイデアを基盤として活用しつつ、自分の興味に合わせてカスタマイズしてもよい。フィンテック、ヘルスケア、ソーシャルメディアのいずれに関心があっても、データモデリングの基本原則は一貫している。丁寧にポートフォリオを構築し、考えの根拠を記録し、図面が自分の専門性を語るよう心がけよう。