











堅牢なデータベースインフラを構築するには、開発のすべての段階で正確さが求められます。エンティティ関係図(ERD)はこの構造の設計図として機能します。ERDは、データエンティティがどのように相互作用するか、情報がどのように流れ、システムライフサイクル全体で整合性がどのように維持されるかを定義します。ERDの徹底的なレビューを省略すると、高コストな再設計やデータ破損、パフォーマンスのボトルネックが将来にわたって発生する可能性があります。このガイドは、実装を確定する前にスキーマを検証するための詳細で実行可能なチェックリストを提供します。
データベースアーキテクトおよび開発者は、スキーマ設計に対して鋭い目で臨む必要があります。本番環境で構造上の誤りを修正するコストは、設計段階で修正する際の努力と比べてはるかに高くなります。構造的なレビュー手順に従うことで、チームは結果として得られるデータベースがビジネスロジックをサポートし、正規化の原則に従い、スケーラブルであることを保証できます。
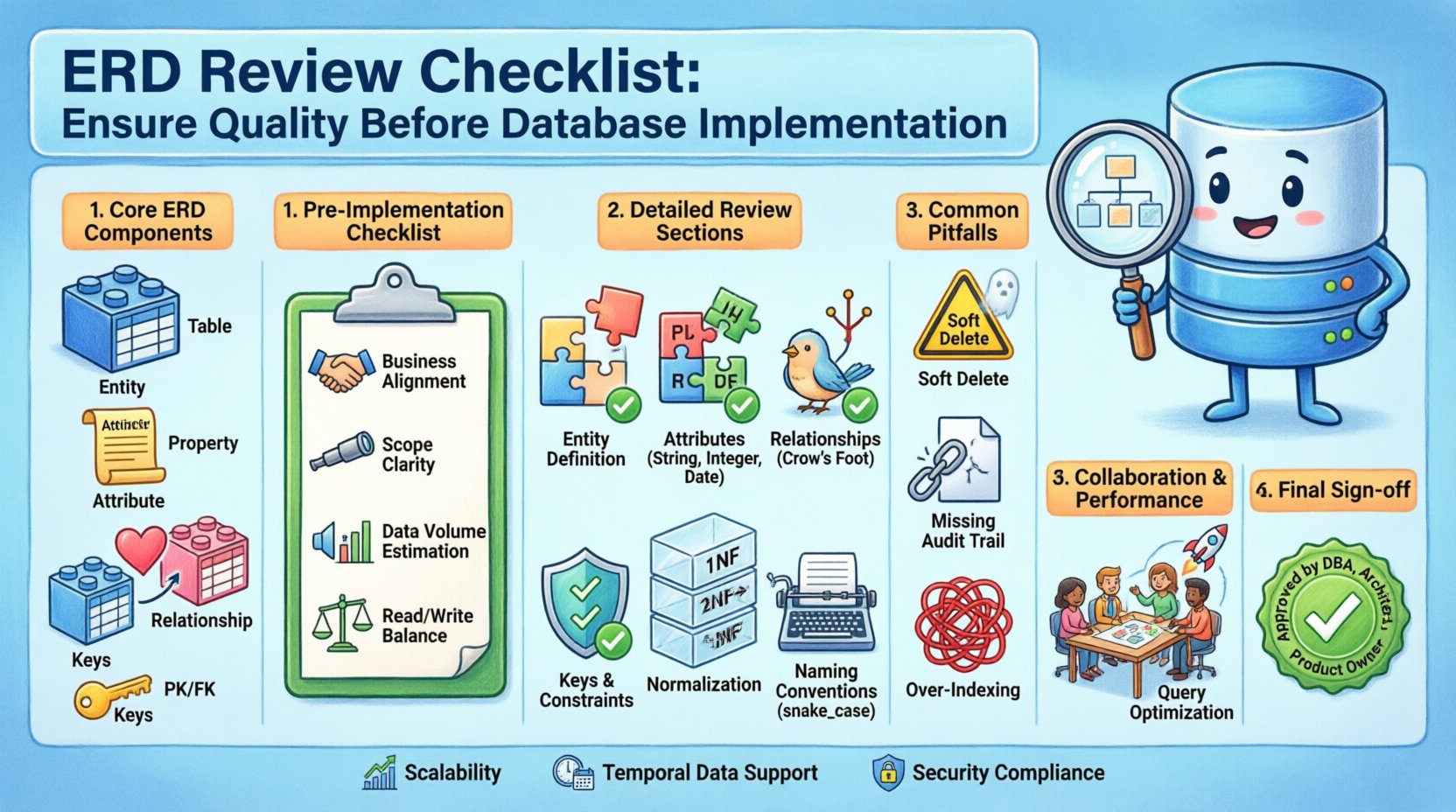
ERDのコアコンポーネントを理解する 🔍
チェックリストに取り組む前に、標準的なエンティティ関係図(ERD)を構成する基本的な構成要素を理解することが不可欠です。これらのコンポーネントが、あなたのデータモデルの語彙を形成します。
- エンティティ: これらは、データが格納される対象となる現実世界のオブジェクトや概念を表します。リレーショナルな文脈では、エンティティは通常、テーブルに対応します。
- 属性: これらはエンティティの性質や特徴を記述します。テーブル内の列に対応します。
- 関係: これらはエンティティ間の関連を定義します。1つのテーブルのデータが、別のテーブルのデータとどのように関連しているかを示します。
- カーディナリティとキー: カーディナリティはエンティティ間の数的関係(例:1対1、多対多)を定義します。キーは一意の識別と接続性を保証します。
高品質なERDは、これらの要素を明確に表現しなければなりません。図面内の曖昧さは、コード内の曖昧さに直結し、実装エラーを引き起こします。
実装前の検証ステップ ✅
特定のチェックリスト項目を適用する前に、データベース全体の文脈がビジネス要件と整合している必要があります。この段階で、モデルが目的に適していることを確認します。
- ビジネス要件の整合性: すべてのエンティティおよび関係が、特定のビジネスルールまたはユーザー・ストーリーに対応していることを確認してください。
- 範囲の定義: データの境界を確認してください。単一のアプリケーション、マイクロサービス、または企業全体を対象としたデータウェアハウスのために設計しているのでしょうか?
- データ量の推定: レコードの予想される量を検討してください。これは、インデックス作成やパーティショニング戦略の決定に影響を与えます。
- 読み書き比率: ワークロードの特性を理解してください。読み込みが重いアプリケーションでは正規化の解除が必要な場合がありますが、書き込みが重いシステムは厳格な整合性を優先します。
詳細なERDレビュー確認リスト 📝
このセクションでは、検証が必要な具体的な技術的属性を分解します。設計レビューの場で、このリストを検証ツールとしてご利用ください。
1. エンティティおよびテーブル定義
図面上のすべてのエンティティは、明確に区別され、適切に定義されている必要があります。よくある誤りは、統合すべき重複するエンティティを作成すること、または単一の概念を複数のテーブルに無駄に分割することです。
- 明確性: 各テーブルが一意の概念を表していることを確認してください。目的が異なるにもかかわらず、明確な区別がないまま類似したデータを格納するテーブルを避けてください。
- 粒度: テーブルの粒度が細かくなりすぎていないか確認してください。過度な分割は複雑な結合を引き起こし、パフォーマンスの低下を招く可能性があります。
- 命名規則: 一貫性を確認してください。テーブルは単数名を使用すべきです(例:
CustomerではなくCustomers)はオブジェクト指向マッピングパターンと整合させるために使用すべきです。 - メタデータ: すべてのテーブルに作成日時および更新日時を含めるように確認してください。これにより監査およびデータの履歴追跡が可能になります。
2. 属性とデータ型
属性は格納されるデータの性質を定義します。適切なデータ型を選択することは、ストレージ効率とクエリパフォーマンスにおいて重要です。
- 主なデータ型: 整数、文字列、論理値が正しく使用されているか確認してください。日付や数値に文字列を使用しないようにしてください。
- 長さ制約: 文字列フィールドの最大長を定義してください。これによりストレージの肥大化を防ぎ、入力検証時の一貫性が保たれます。
- Null許容性: フィールドがNullを許容するかどうかを明確に定義してください。ビジネスロジックが許容しない限り、ほとんどのフィールドはNullを許容してはなりません。
- デフォルト値: デフォルト値が必要かどうかを確認してください。たとえば、ステータスフィールドは初期挿入を必要とせず、デフォルトで「active」になるようにする場合があります。
- 列挙値: 適切な場合、列挙リストを使用して値を制限してください。これにより、ソースでの無効なデータ入力を防ぐことができます。
3. 関係性と基数
関係性はデータモデルを統合する基盤です。ここでの誤りは、孤立レコードやデータの重複を引き起こします。
| 関係性の種類 | 説明 | 実装上の注意点 |
|---|---|---|
| 1対1(1:1) | Table Aの1レコードが、Table Bの正確に1レコードにリンクします。 | 通常、Aの主キーをBの外部キーとして配置することで実装されます。 |
| 1対多 (1:N) | Table A の1つのレコードが、Table B の複数のレコードにリンクしています。 | A の主キーを B に外部キーとして配置する。 |
| 多対多 (M:N) | A のレコードは B の複数にリンクでき、その逆もまた同様である。 | 2つの主キーをリンクする中間テーブルが必要である。 |
- 基数の検証:関係の方向が正しいことを確認するために、クロウズフット記法または同等の記法を確認する。
- オプショナリティ:必須関係と任意関係を区別する。外部キー制約は、関連レコードが存在しなければならないかどうかを反映すべきである。
- 再帰的関係: 自己参照テーブル(例:同じテーブル内の
従業員テーブルがマネージャーID にリンクするもの)を確認する。 - 循環依存:関係がデータの読み込みやクエリを複雑にする循環ループを作らないように確認する。
4. キーと制約
キーは一意性と接続のメカニズムである。適切なキーがなければ、データの整合性は崩壊する。
- 主キー:すべてのテーブルには主キーが必要である。一意で、決してnullであってはならない。
- 代替キー:自然なビジネスキーではなく、システム生成のID(代替キー)を使用することを検討する。これにより、ビジネスロジックの変更がデータベース構造に影響を与えるのを回避できる。
- 外部キー:すべての外部キーが親テーブルの有効な主キーを参照していることを確認する。
- 一意制約:主キーではないが、一意でなければならないフィールド(例:メールアドレス、口座番号)を特定する。
- チェック制約: データ型だけで強制できない論理ルールを検索する(例:
開始日は以下より前に設定する必要がある終了日).
5. 正規化
正規化は重複を減らし、データの整合性を向上させます。過剰な正規化はパフォーマンスに悪影響を及ぼす可能性がありますが、正規化不足は異常を引き起こします。
- 第一正規形 (1NF):原子的な値を確保する。1つのセル内に繰り返しグループや配列を含めない。
- 第二正規形 (2NF):すべての非キー属性が主キーに完全に依存していることを確認する。部分的な依存ではない。
- 第三正規形 (3NF):推移的依存関係がないことを確認する。非キー属性は主キーにのみ依存し、他の非キー属性に依存してはならない。
- 非正規化戦略:パフォーマンスが懸念される場合は、非正規化を適用した場所と理由を文書化する。これは無意識の誤りではなく、意図的な決定であるべきである。
6. 名前付け規則
一貫した名前付けは開発者の認知負荷を軽減し、エラーの発生確率を低下させる。
- テーブル名:単数名詞を使用する(例:
注文、複数形の注文). - カラム名:一貫性を持たせるためにsnake_caseを使用する(例:
作成日時). - 予約語を避ける:カラム名がSQLキーワードと衝突しないことを確認する(例:
ユーザー,注文,グループ). - 明確さ:名前は説明的であるべきです。業界標準のものでない限り、省略語を避けてください。
避けるべき一般的な落とし穴 ⚠️
経験豊富なデザイナーでさえ、重要な詳細を見落とすことがあります。一般的な罠に注意することで、クリーンなスキーマを維持するのに役立ちます。
- ソフトデリートを無視する:データを永続的に削除する必要があるか、論理的に非アクティブとしてマークするかを決定してください。
is_deletedフラグは物理的な削除よりも安全な場合が多いです。 - 監査ログの欠如:誰がいつデータを変更したかを追跡する仕組みがあることを確認してください。これはコンプライアンスにとって不可欠です。
- 過剰なインデックス化:あまりにも多くのインデックスを追加すると、書き込み操作が遅くなります。インデックスの配置を正当化するために、クエリパターンを確認してください。
- ハードコードされた値:国コードのような特定の値を文字列として保存するのは避けましょう。参照テーブルにマッピングできる場合は特にそうです。
- 暗黙の仮定:ビジネスロジックで必須である場合、フィールドがオプションであると仮定してはいけません。仮定を明確に文書化してください。
協働とドキュメント化 🤝
ERDは単なる技術的成果物ではなく、コミュニケーションツールです。データベース管理者だけでなく、ステークホルダーにも理解されるべきです。
- ステークホルダーのレビュー:ビジネスアナリストに図をレビューしてもらい、プロセスに対する彼らのメンタルモデルと一致しているか確認してください。
- バージョン管理:ERDをコードとして扱いましょう。変更を時間の経過とともに追跡できるように、バージョン管理に保存してください。
- ドキュメント化:図の傍らにデータ辞書を含めましょう。各フィールドの意味と許容範囲を定義してください。
- 変更管理:スキーマを変更するためのプロセスを確立してください。変更は、即座に適用するのではなく、レビューと承認を経て行うべきです。
パフォーマンスに関する考慮事項 🚀
ERDは論理的であるが、物理的なパフォーマンス目標をサポートしなければならない。特定の設計選択は直接的なパフォーマンスへの影響を持つ。
- 結合の複雑さ:一般的なクエリに必要な結合の数を最小限に抑える。複雑な結合はクエリ最適化子に負担をかける可能性がある。
- パーティショニング対応性:データセットが大幅に増加すると予想される場合は、テーブル設計時にパーティショニングを考慮する。
- 検索性:頻繁に検索されるフィールドはインデックス化されていることを確認する。テキストが多めのフィールドについては全文検索の要件も検討する。
- 並行処理:ロック戦略を評価する。高並行処理環境では、特定の分離レベルやテーブル設計が必要になる場合がある。
最終承認基準 🏁
実装に進む前に、ERDは特定の受入基準を満たしている必要がある。これにより、設計から開発へのスムーズな移行が保証される。
- 完全性:範囲で要求されるすべてのエンティティと関係が存在している。
- 一貫性:命名規則とデータ型が一貫して適用されている。
- 整合性:主キーおよび外部キー制約が正しく定義されている。
- 明確性:図はエンジニアリングチームにとって読みやすく、理解しやすいものである。
- 承認:主要なステークホルダーが設計に署名して承認している。
このチェックリストを遵守することで、データベースの基盤がしっかりしたものになる。技術的負債を削減し、開発サイクルをスムーズに進める。よくレビューされたERDは、耐障害性のあるデータアーキテクチャへの第一歩である。
将来のスケーラビリティを考慮したERDのレビュー
現在の状況に合わせた設計では不十分である。データモデルは完全な再構築なしに成長に対応できるようにしなければならない。
- 水平スケーリング:シャーディングが関係性に与える影響を検討する。シャード間の外部キーは複雑であり、しばしば避けられる。
- 垂直スケーリング:データ型がより大きな値を扱えることを確認する。たとえば、
BIGINT~の代わりにINTカウンター用。 - 機能フラグ: ソフトな機能フラグをサポートするテーブルを設計する。これにより、スキーマの変更なしに新しい機能を切り替えられる。
- 後方互換性: スキーマの移行を計画する。カラムの追加は既存のクエリを破壊してはならない。
時系列データのような特別なケースの取り扱い
時間はデータモデリングにおける重要な次元である。履歴の適切な扱いは、しばしば見過ごされる。
- 有効日: 時間とともに変化するエンティティの場合、履歴を追跡するために開始日と終了日を含める。
- タイムゾーン: エリア間の曖昧さを避けるために、タイムスタンプをUTCで保存する。
- スナップショット: 歴史的スナップショットが必要かどうかを決定する。これにより、別々の履歴テーブルが必要になる可能性がある。
- 時系列テーブル: 一部のシステムはネイティブな時系列テーブルをサポートしている。アーキテクチャ上の制約に合致するか評価する。
スキーマにおけるセキュリティとコンプライアンス
データセキュリティはテーブルレベルから始まる。構造はプライバシーおよび保護要件をサポートしなければならない。
- PIIの取り扱い: 個人を特定できる情報(PII)のフィールドを特定する。これらは暗号化またはマスキングが必要である。
- アクセス制御: スキーマで定義されたデータの機密性に基づいて、ロールと権限を設計する。
- 静的暗号化: データベースエンジンが機密フィールドの暗号化をサポートしていることを確認する。
- 保持ポリシー: 法的要件に基づいて、データを削除できる時期を示すフィールドを定義する。
これらのチェックを厳密に適用することで、データベースは負債ではなく信頼できる資産となる。ERDレビュー段階に費やした努力は、保守性とパフォーマンスの面で大きな成果をもたらす。