











データベースアーキテクチャはビジョンから始まる。1行のコードが書かれる前にも、データ構造は概念化され、整理され、検証されなければならない。エンティティ関係図(ERD)はこの構造の設計図として機能し、現実世界の要件を視覚的なモデルに変換する。しかし、図だけではデータを保存できない。論理スキーマは、情報が物理的にどのように格納され、取得され、保護されるかを規定する実体的な実装である。
抽象的なERDから具体的なスキーマへ移行するには正確さが求められる。エンティティをテーブルにマッピングし、関係をキーに、属性をカラムに変換する作業が含まれる。このプロセスは、システム全体の整合性とパフォーマンスを決定する。この翻訳の細部を理解することで、データベースが負荷に耐え、将来のニーズに適応できるようになる。
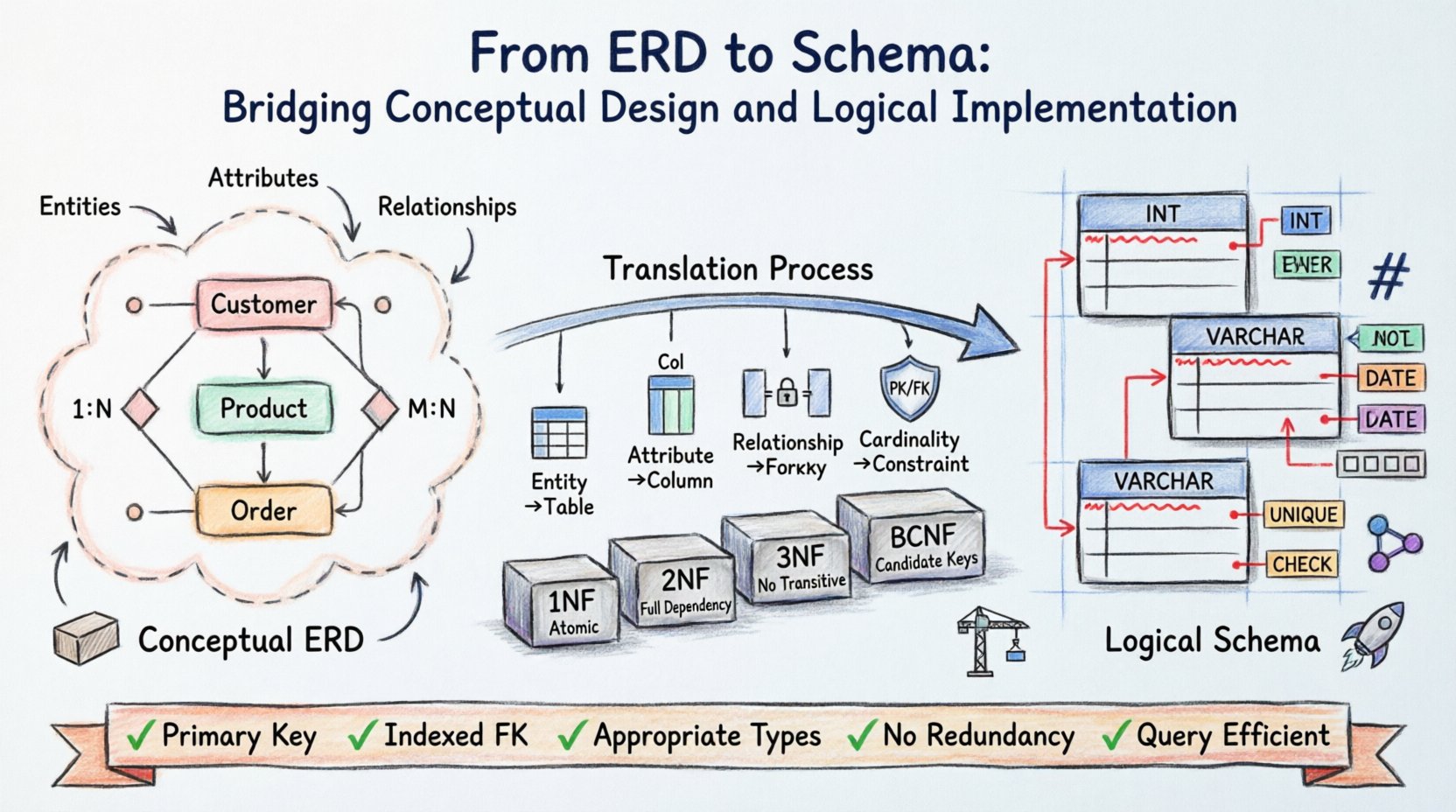
概念的基盤を理解する 🧱
エンティティ関係図(ERD)は概念レベルで動作する。それは「どのように」ではなく「何が」であるかに注目する。この段階では、関係者やアーキテクトが、ドメイン内の注目すべき核心的なオブジェクトを特定する。
- エンティティ: これらは、顧客、製品、注文など、明確に区別されるオブジェクトや概念を表す。
- 属性: これらはエンティティの性質を定義するもので、名前、価格、日付などである。
- 関係: これらはエンティティがどのように相互作用するかを説明するもので、顧客が注文を行うといった例がある。
この段階では、技術的制約は二次的なものである。目的は明確さである。概念モデルが曖昧であれば、結果として得られるスキーマも不完全になる。よくある誤りには、属性とエンティティを混同したり、基数を正しく定義しなかったりするものがある。
基数と参加制約
ERD設計において最も重要な要素の一つが、基数を定義することである。これにより、エンティティ間の数量的関係が決定される。
- 1対1(1:1): テーブルAの1レコードが、テーブルBの正確に1レコードと関連する。
- 1対多(1:N): テーブルAの1レコードが、テーブルBの複数のレコードと関連する。
- 多対多(M:N): テーブルAの複数のレコードが、テーブルBの複数のレコードと関連する。
参加制約はこのモデルをさらに精緻化する。関係は必須か任意か?顧客が注文を必ず行わなければならない場合、参加は必須である。注文がなくても存在できる場合、それは任意である。これらの違いは、論理スキーマにおけるカラムのnull許容性に直接影響する。
論理スキーマ:構造的実装 🏗️
論理スキーマは理論と物理的ストレージの間のギャップを埋める。ERDはプラットフォームに依存しないが、論理スキーマはデータを特定のストレージメカニズムに適応させる準備を行う。このレイヤーでは、データ型、制約、正規化に関する具体的なルールが導入される。
概念モデルとは異なり、論理スキーマはデータ整合性を明示的に扱わなければならない。これは主キー、外部キー、一意制約を通じて達成される。これらのルールにより、孤立レコードの発生を防ぎ、関係が一貫性を保つ。
キーの翻訳ルール
ERDからスキーマへのキーの翻訳には、関係理論への厳密な従従が求められる。
- 主キー: すべてのエンティティには一意の識別子が必要である。ERDでは、しばしば下線が引かれる。スキーマでは、これはPRIMARY KEY制約となる。
- 外部キー: 関係は外部キーによって実装される。多対多関係は、通常、基数を解決するために2つの外部キーを持つ関連テーブルを必要とする。
- 複合キー: エンティティが一意性のために複数の属性に依存する場合、それらは論理的定義で結合されなければならない。
エンティティをテーブルにマッピングする 🔄
エンティティをテーブルに変換するプロセスは簡単だが、細部に注意を払う必要がある。一般的に各エンティティは1つのテーブルに対応する。ただし、複雑なシナリオでは分割または統合が必要になる場合がある。
特殊化と一般化の処理
エンティティが共通の属性を共有する場合、サブクラスとしてモデル化できる。例えば、Vehicle エンティティには、Car および Truck.
スキーマ内でこれを実装するための主な戦略は2つある:
- シングルテーブル継承: すべてのサブクラスがディスクリミネータ列を持つ1つのテーブルに格納される。これにより結合が減るが、NULL値が増える。
- クラステーブル継承: 各サブクラスには親クラスと外部キーでリンクされた独自のテーブルが割り当てられる。これにより正規化度が高くなるが、より複雑なクエリが必要になる。
属性のマッピング
ERDからの属性はカラム定義にマッピングされなければならない。すべての属性が直接変換できるわけではない。
- 単純な属性: カラムに直接マッピングする。
- 複合属性: 個別のカラムに分解しなければならない(例:AddressはStreet、City、Zipに分割される)。
- 多値属性: 単一のカラムに格納できない。外部キーでリンクされた別テーブルが必要となる(例:ユーザーの電話番号)。
- 導出属性: これらは他のデータから計算される(例:生年月日から年齢を計算)。冗長性を避けるためにスキーマから省かれることが多いが、パフォーマンス最適化が重要な場合を除く。
正規化の詳細 📊
正規化は、冗長性を減らし、整合性を高めるためにデータを整理するプロセスである。ERDからスキーマへ移行する際、設計者はモデルが特定の正規形に従っていることを確認しなければならない。
第一正規形(1NF)
テーブルが1NFにあるのは、原子的な値を含んでいる場合である。どの列にもリストや値の集合を含めてはならない。あるエンティティが単一の属性に対して複数の値を持つ場合、新しいテーブルを作成しなければならない。
第二正規形(2NF)
2NFでは、テーブルが1NFにあり、部分的依存関係がないことを要求する。すべての非キー属性は、主キーの一部ではなく、完全な主キーに依存しなければならない。これは複合キーを持つテーブルにおいて特に重要である。
第三正規形(3NF)
3NFでは、推移的依存関係がないことを要求する。非キー属性は、他の非キー属性に依存してはならない。たとえば、もし都市は、郵便番号、そして郵便番号は、顧客ID, 都市都市は別々のテーブルに移動すべきである。
ボーイス・コッド正規形(BCNF)
BCNFは3NFのより厳格なバージョンである。テーブルに複数の候補キーがあり、非キー属性がそれらのキーの部分集合に依存する場合を処理する。
| 正規形 | 要件 | 焦点 |
|---|---|---|
| 1NF | 原子的値 | 繰り返しグループを排除する |
| 2NF | 完全依存 | 部分的依存を排除する |
| 3NF | 推移的依存なし | 間接的依存を排除する |
| BCNF | 候補キーの依存関係 | 重複するキーを排除する |
データ型と制約 🔒
適切なデータ型を選択することは、ストレージ効率とクエリパフォーマンスにとって不可欠です。ERDはほとんど正確なデータ型を指定せず、これを論理設計フェーズに任せることが多いです。
整数型 vs. 数値型
整数型は整数を格納し、計算において高速です。財務データの精度を保つために、数値型または小数型が使用されます。通貨に整数型を使用すると、四捨五入誤差が生じる可能性があります。
日付と時刻
タイムスタンプはUTCとローカル時刻を区別する必要があります。日付を文字列として格納することは一般的な誤りであり、効率的な並べ替えやフィルタリングを妨げます。データベースエンジンが提供する標準的な日付型を使用してください。
制約
制約はデータベースレベルでビジネスルールを強制します。
- NOT NULL:列に常に値が含まれることを保証します。
- UNIQUE:列内の重複値を防止します。
- CHECK:データが特定の条件(例:年齢 > 0)に合致しているか検証します。
- DEFAULT:値が提供されない場合のフォールバック値を提供します。
一般的な落とし穴と検証 ⚠️
しっかりとした計画があっても、実装中にエラーが発生する可能性があります。これらの落とし穴を早期に認識することで、後の時間の大幅な節約が可能です。
- 過剰正規化:あまりにも多くのテーブルを作成すると、クエリが遅くなり、複雑になります。読み込みが重いワークロードでは、非正規化が必要になる場合があります。
- 弱いキー:自然キー(メールアドレスなど)を主キーとして使用するのはリスクがあります。変更される可能性があり、連鎖的な問題を引き起こすことがあります。代替キー(自動増分ID)はしばしばより安全です。
- インデックスの欠落:外部キーはインデックス化すべきです。それがないと、テーブルの結合がパフォーマンスのボトルネックになります。
- 循環依存:関係性にループが生じないよう、テーブルが互いに循環的に依存しないようにすることが、参照整合性を維持するために重要です。
検証チェックリスト
スキーマを最終確定する前に、この検証リストを確認してください:
- すべてのテーブルに主キーがありますか?
- すべての外部キーが適切にインデックスされていますか?
- データ型は想定されるデータ量に適していますか?
- 削除できる重複する列はありますか?
- スキーマは必要なクエリを効率的にサポートしていますか?
パフォーマンスの考慮事項 🚀
論理スキーマは正しさだけでなく、速度にも関係します。データが増加するにつれて、構造は増加する負荷を処理できる必要があります。
パーティショニング
大きなテーブルは、より小さく管理しやすい部分に分割できます。これは行単位(水平)または列単位(垂直)で行うことができます。パーティショニングにより、クエリは関連するデータセグメントのみにアクセスできます。
アーキテクチャパターン
シャーディングのような設計パターンにより、データが複数のサーバーに分散されます。関連するデータが可能な限り一緒に残るようにするためには、論理設計段階で慎重な計画が必要です。
ベストプラクティスの要約 ✅
データベーススキーマの構築は反復的なプロセスです。理論的な純粋さと実用的な制約のバランスを取る必要があります。
- すべてを文書化する:ERDの要素とスキーマ定義を結びつける明確な文書を維持する。
- バージョン管理:スキーマの変更をコードとして扱う。変更履歴を追跡するためにマイグレーションスクリプトを使用する。
- 定期的に見直す:ビジネスニーズが変化するにつれて、スキーマも変化すべきです。現在の要件に合致していることを確認するために、定期的な監査をスケジュールする。
- 協働する:開発者、アナリスト、ステークホルダーを早期に参加させる。異なる視点が、単一のデザイナーが見逃す可能性のあるエッジケースを明らかにする。
エンティティ関係図から論理スキーマへの移行は、データエンジニアリングの基盤です。抽象的なアイデアを機能するシステムに変換します。正規化ルールを遵守し、適切なデータ型を選択し、パフォーマンスのニーズを予測することで、結果として得られるデータベースはアプリケーションの信頼できる基盤となります。
最終的に、スキーマの品質がシステムの持続可能性を決定します。適切に構造化された設計は、技術的負債を最小限に抑え、将来の成長を促進します。明確さ、整合性、スケーラビリティに注力して、時代を超えて通用するシステムを構築しましょう。