




マルチテナント環境のデータベースアーキテクチャを設計するには、データの分離、スケーラビリティ、保守の負荷について慎重に検討する必要があります。エンティティ関係図(ERD)はこれらの意思決定のための設計図であり、テナント間でデータがどのように構造化されるかを規定します。適切なアプローチを選択することは、パフォーマンス、セキュリティ、システムの将来の進化能力に影響を与えます。このガイドでは、主なアーキテクチャパターン、それらのERDへの影響、各戦略におけるトレードオフについて探求します。
🔍 データモデリングにおけるマルチテナントの理解
マルチテナント化により、1つのソフトウェアインスタンスが複数の顧客(しばしばテナントと呼ばれる)を対象にサービスを提供できます。データベース設計の文脈では、テナントのデータを分離しつつ効率性を維持する方法を決定することが核心的な課題です。ERDは、これらの分離境界を明確に反映しなければなりません。
- テナント: システムを利用している個別の顧客または組織。
- 共有システム: アプリケーションロジックおよび、場合によっては基盤となるインフラ構造。
- データ分離: 1つのテナントが他のテナントのデータにアクセスできないようにすること。
設計上の選択は、主に分離境界がどこにあるかという点に集中します。それはデータベースレベル、スキーマレベル、あるいは行レベルに存在するのでしょうか?それぞれの選択は、特定のERD構造を必要とします。
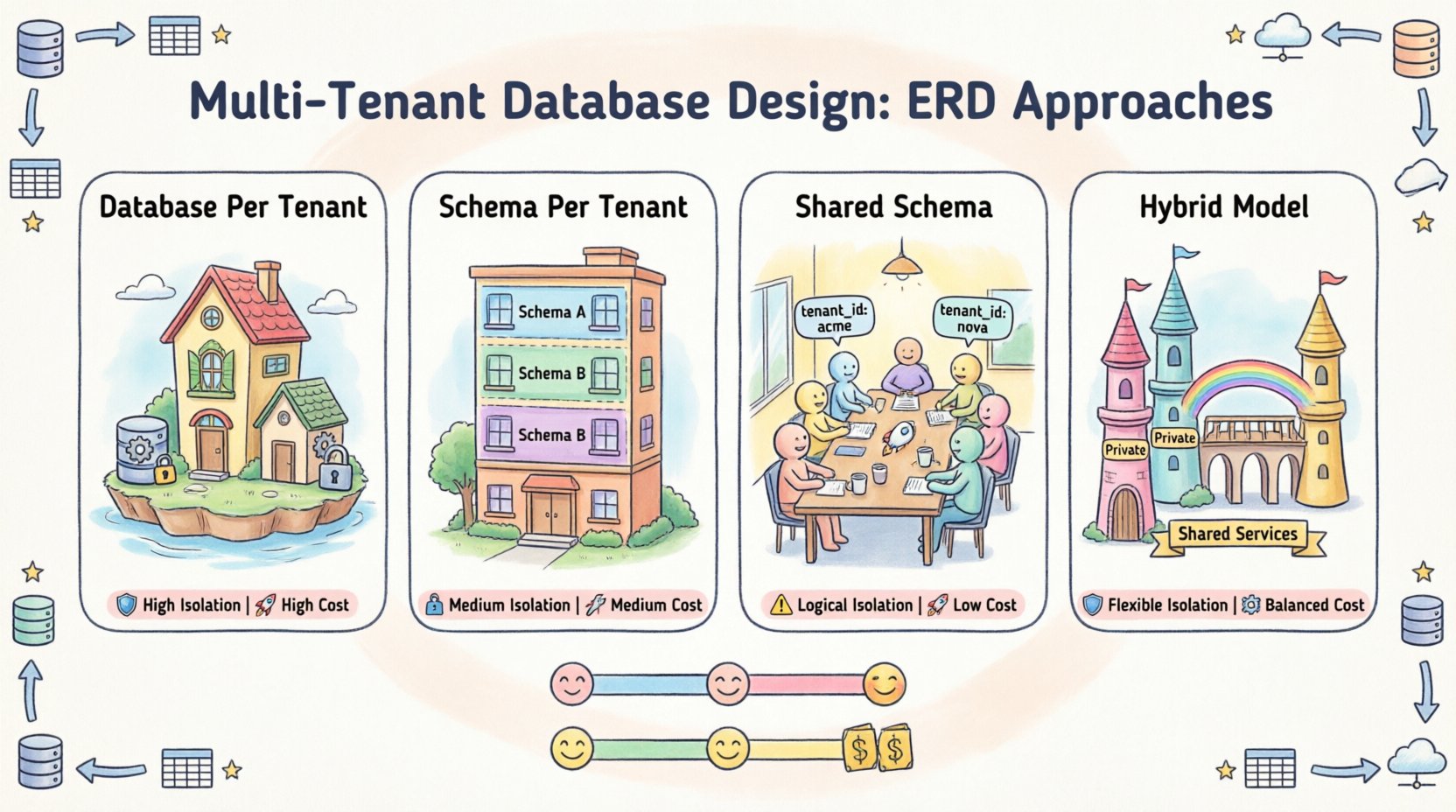
🏗️ 戦略1:テナントごとのデータベース
このモデルでは、各テナントに専用のデータベースインスタンスが割り当てられます。これにより、最も高いレベルの分離とセキュリティが実現されます。ERDの観点から見ると、すべてのデータベースでスキーマは同一ですが、物理的な分離は完全です。
📊 ERD構造
単一テナント用データベースのERD図は、標準的な単一テナント設計と同一です。tenant_id列は必要ありません。なぜなら、データベースの境界そのものがフィルタとして機能するからです。
- テーブル構造: テーブルには、特定のテナントに関連するデータのみが含まれます。
- 外部キー: テナントの意識を持たずに、標準的な参照整合性が適用されます。
- インデックス: そのテナントの特定のデータ量に最適化されています。
✅ 優位性
- 完全な分離: 1つのデータベースでセキュリティ侵害が発生しても、他のデータベースには影響しません。
- カスタマイズ性: スキーマの変更を特定のテナントに適用でき、他のテナントには影響を与えません。
- パフォーマンス: 同じ接続プールやディスクI/Oにおいて、他のテナントとの競合がありません。
❌ デメリット
- コスト:複数のインスタンスによる高いインフラコスト。
- 保守:スキーマの更新は、すべてのデータベースインスタンスにデプロイする必要がある。
- 複雑さ:接続の管理とオーケストレーションがスケールアップするにつれて難しくなる。
🏗️ 戦略2:テナントごとのスキーマ
このアプローチは前二者の間にある。各テナントは同じデータベースサーバー内に専用のスキーマを割り当てる。これにより、複数のデータベース接続を管理するオーバーヘッドを軽減しつつ、論理的な分離を維持できる。
📊 ERD構造
ERDはシングルテナントモデルと一貫性を保つが、ネームスペースが変更される。テーブルはパブリックネームスペースではなく、特定のスキーマネームスペース内に存在する。
- テーブル名:標準的な命名規則(例:
users,orders). - スキーマ名:一意の識別子(例:
schema_tenant_a,schema_tenant_b). - 接続性:アプリケーションはアクティブなテナント用の特定のスキーマに接続する。
✅ メリット
- 分離性:共有スキーマモデルよりも強固な分離性。
- 管理:別々のデータベースインスタンスよりも管理が容易。
- バックアップ:個別のスキーマを独立して復元またはバックアップできます。
❌ デメリット
- リソース使用量:完全に共有されたモデルよりも多くのリソースを消費します。
- クエリの複雑さ:複数のテナントにまたがるデータを集計するには、動的なスキーマ切り替えが必要です。
- スキーマのずれ:多数のテナントにわたってスキーマを同期させるのは手間がかかります。
🏗️ 戦略3:共有データベース、共有スキーマ
これはSaaSアプリケーションで最も一般的なアプローチです。すべてのテナントが同じデータベースと同じテーブルを共有します。データの分離は、一意の識別子カラムを通じて論理的に実現されます。
📊 ERD構造
ERDには明示的にtenant_idテナント固有のデータを格納するすべてのテーブルに含まれるカラムです。このカラムがパーティションキーとして機能します。
- コアテーブル:
users,orders,productsすべてにtenant_id. - 共有テーブル: 例えば
rolesまたはpermissionsはすべてのテナント間で共有される可能性があります。 - 制約:外部キーは、テナントコンテキスト内で参照整合性が維持されるようにスコープを設定する必要がある場合があります。
✅ 優位性
- コスト効率:最低限のインフラコスト。
- 保守性:スキーマの変更はすべてのテナントに即座に適用される。
- 分析:システム全体のレポート作成に必要なデータを集約しやすくなる。
❌ 劣位性
- 複雑なクエリ:すべてのクエリは、
tenant_id. - パフォーマンス:1つのテナントが過剰なリソースを消費した場合、高い競合リスクが生じる。
- セキュリティ:論理エラーのリスクが高くなり、データ漏洩につながる可能性がある。
🏗️ 戦略4:ハイブリッドモデル
ハイブリッドアプローチは、上記の戦略の要素を組み合わせたものである。たとえば、標準データには共有スキーマを、プレミアム層や特定の高価値テナントには専用スキーマを用いる。
📊 ERD構造
ERDはより複雑になり、共有テーブルとテナント固有のテーブルを区別する必要がある。
- グローバルテーブル:設定情報や共有メタデータを格納する。
- テナントテーブル:tenant_idを含むユーザー情報を格納する、または別々のスキーマに格納する。
tenant_idまたは別々のスキーマに格納する。 - リンク:結合操作は、データのスコープを考慮しなければならない。
🛡️ データの分離とセキュリティ上の考慮事項
選択した戦略にかかわらず、データの分離は極めて重要である。ERDは、誤ったデータアクセスを防ぐ仕組みをサポートしなければならない。
🔒 行レベルのセキュリティ
共有スキーマモデルでは、行レベルのセキュリティ(RLS)ポリシーを定義できる。データベースエンジンは、tenant_idが認証されたコンテキストと一致する行へのアクセスを制限する。
- 実装:ポリシーは、すべての
SELECT,UPDATE、およびDELETE操作に対してチェックを強制する。 - 利点:アプリケーションレベルのバグがデータ漏洩を引き起こすのを防ぐ。
- ERDへの影響:すべての関連テーブルに明示的な
tenant_id列を追加する必要がある。
🔒 外部キー制約
共有モデルでは、テナント間で参照整合性を保つのは難しい場合がある。外部キーは、関係が明示的にグローバルである場合を除き、複数のテナントにまたがるテーブルを指すべきではない。
- 自己参照: テーブルが自分自身を参照する場合(例:
parent_id)、両側のtenant_idが一致している必要がある。 - グローバル参照: 例えば
カテゴリグローバルになる可能性があり、すべてのテナントが参照できるようになります。
⚡ パフォーマンスとスケーリング戦略
テナント数が増えるにつれて、パフォーマンスが重要な課題になります。ERDの設計は、システムのスケーラビリティに直接影響します。
📈 インデックス戦略
インデックスはクエリパフォーマンスにとって不可欠です。共有スキーマでは、tenant_id列は、主複合キーの一部であるか、強くインデックス化されるべきです。
- 複合インデックス:
(tenant_id, created_at)テナントと時刻による効率的なフィルタリングを可能にします。 - 部分インデックス:特定の条件に対してのみインデックスを作成でき、インデックスのサイズを削減できます。
- 避けるべきこと:テナントフィルタリングに役立たない列のインデックス化。
📦 パーティショニング
テーブルパーティショニングは、大規模なデータセットを管理するのに役立ちます。データはtenant_idtenant_id に基づいて、またはテナント内の時間範囲に基づいて分割できます。
- 範囲パーティショニング:日付範囲に基づいてデータを分割します。
- リストパーティショニング:特定のテナントIDに基づいてデータを分割します。
- 管理:パーティションを分離またはアーカイブすることで、パフォーマンスを向上させることができます。
🔧 メンテナンスとスキーマの進化
ソフトウェアは進化します。テーブルを追加したり、列を変更したり、型を変更したりする必要があります。選択したアーキテクチャが、これらの変更に必要な作業量を決定します。
🔄 スキーマの更新
- 共有スキーマ:単一のマイグレーションスクリプトで、すべてのテナントのスキーマを更新できます。これが最も簡単な方法です。
- テナントごとのデータベース: マイグレーションスクリプトは、すべてのデータベースインスタンスに対して実行されなければなりません。自動化が必須です。
- テナントごとのスキーマ: テナントごとのデータベースと似ていますが、同じインスタンス内で管理されます。
📝 後方互換性
ERDを変更する際は、ダウンタイムを避けるために後方互換性を確保してください。
- 列の追加: まず可変長列を使用し、データを埋め込んだ後、非可変長に変更します。
- 列の削除: 変更を破壊しないように、列を削除する前に名前を変更してください。
- バージョン管理: テナントが更新をオプトアウトできる場合、スキーマ自体をバージョン管理することを検討してください。
📋 アーキテクチャアプローチの比較
| 機能 | テナントごとのデータベース | テナントごとのスキーマ | 共有スキーマ |
|---|---|---|---|
| 隔離性 | 高 | 中 | 低 |
| コスト | 高 | 中 | 低 |
| 保守性 | 複雑 | 中 | 簡単 |
| クエリパフォーマンス | 高 (フィルタリングなし) | 中 | 可変 (フィルタリングが必要) |
| ERDの複雑さ | 単純 (各データベースごと) | 単純 (各スキーマごと) | 複雑 (tenant_idが必要) |
| スケーラビリティ | 水平 | 垂直 | 垂直/水平 |
✅ ベストプラクティスチェックリスト
マルチテナントシステムのERDを最終確定する前に、以下の基準を満たしていることを確認してください。
- テナントの範囲を定義する:どのデータがテナント固有のもので、どのデータがグローバルなものかを明確に識別する。
- 命名規則を統一する:すべてのテーブルで、
tenant_idカラムに対して一貫した命名規則を使用する。 - 制約を強制する:可能な限り、データベースの制約を使用して、テナント間のデータアクセスを防止する。
- 離脱を想定する:テナントのオンボーディングおよびオフボーディング(データ削除またはアーカイブ)を想定して設計する。
- 隔離性のテスト:定期的にテストを行い、1つのテナントが他のテナントのデータを照会できないことを確認する。
- 関係を文書化する:ERDの文書化において、外部キーの関係を明確に記録する。
- パフォーマンスを監視する:テナント固有のボトルネックを示す可能性のある遅いクエリに対してアラートを設定する。
🧩 ハイドゥケースの対処
現実のシナリオでは、標準的なERDがすぐにカバーできない複雑さがしばしば導入される。
🔄 テナントの統合
時折、2つのテナントが1つに統合される。共有スキーマでは、これにより1つのテナントから別のテナントへ行を移動する必要がある。tenant_idへ移動する。テナントごとのデータベースモデルでは、これにより2つの完全なデータベースを統合することになる。
- データ一貫性:統合中にデータが失われないことを確認する。
- 重複除去:統合によって生じる可能性のある重複レコードを処理する。
📉 テナントの離脱
テナントが離脱する。データを削除するかアーカイブするかの判断は、ERDに影響を与える。
- ソフト削除: に
is_deletedフラグを追加して、コンプライアンスのためにデータを保持する。 - ハード削除:行を完全に削除する。孤立したレコードを避けるために、カスケード削除が正しく設定されていることを確認する。
- アーカイブ:古いテナントデータをコールドストレージテーブルに移動しつつ、スキーマを維持する。
🔗 アプリケーションロジックとの統合
ERDは孤立した存在ではない。アプリケーション層とシームレスに統合されなければならない。
- ミドルウェア: アプリケーションレベルのミドルウェアを使用して、
tenant_idをすべてのクエリに自動的に挿入する。 - ORMの設定:オブジェクトリレーショナルマッピングツールを設定して、テナントスコープを処理する。
- API設計:データを返す前に、APIエンドポイントがテナントコンテキストを検証することを確認する。
🎯 デザインに関する最終的な考察
マルチテナント環境における適切なデータベース設計を選定することは、隔離性と効率性のバランスを取ることである。ERDは、これらの境界を定義する契約の役割を果たす。唯一の完璧な解決策は存在しない。選択は、セキュリティ、コスト、スケーラビリティに関する具体的な要件に依存する。各戦略の影響を理解することで、アーキテクトは堅牢でスケーラブルかつ安全なシステムを構築できる。
明確なデータモデリングの実践に注力することで、テナント数の増加に伴ってシステムが維持可能であることが保証される。実際の使用状況に基づいてERDを定期的に見直すことで、ボトルネックやセキュリティ上の穴を、重大な問題になる前に発見できる。
結局のところ、目標はデータの整合性を損なうことなくビジネスを支援する設計を実現することである。ERD段階での慎重な計画が、後の高コストな再設計を防ぐ。