











データベース設計の複雑なアーキテクチャにおいて、自己参照エンティティほどエンジニアに挑戦をもたらす概念は少ない。再帰的関係とも呼ばれるこのパターンは、テーブルが自分自身とリンクできるようにし、フラットなスキーマ内に階層構造や複雑な構造をモデル化することを可能にする。これを正しく実装する方法を理解することは、データ整合性とクエリパフォーマンスを維持するために不可欠である。
エンティティ関係図(ERD)を設計する際、ほとんどの関係は2つの異なるエンティティを結びつける。しかし、現実世界のデータは、単一のエンティティが自分自身の種類と関係を持つことを要求することが多い。マネージャーが従業員を管理し、カテゴリがサブカテゴリを含み、製品がキットの一部となる。このような状況では、再帰的関係が必要となる。
このガイドでは、自己参照エンティティを扱うためのメカニズム、設計パターン、およびベストプラクティスを検討する。特定のソフトウェアツールに依存せずに、これらの関係をどのように構造化するかを、普遍的なデータベース原則に焦点を当てて検討する。
🧐 自己参照エンティティとは何か?
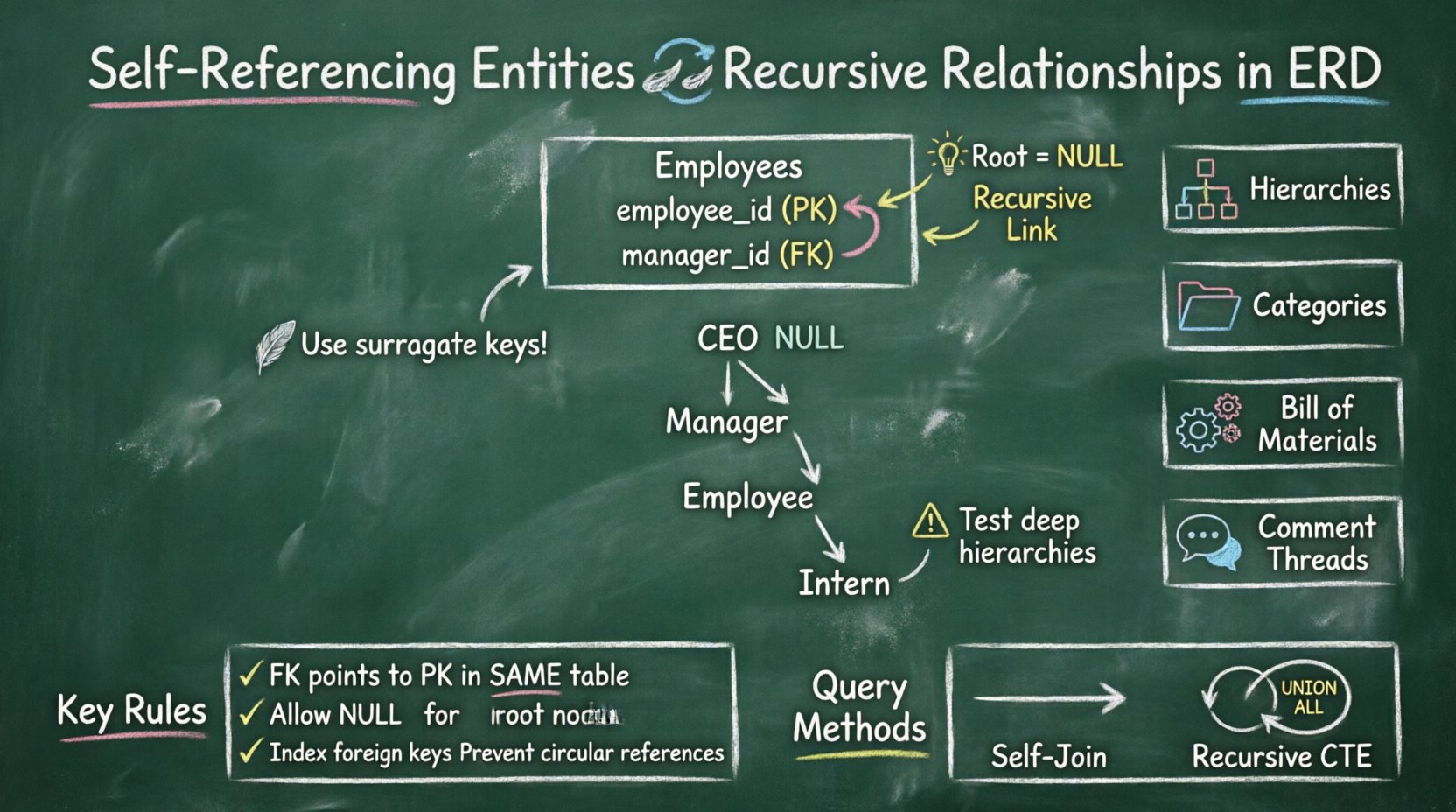
自己参照エンティティとは、テーブル内の外部キーが、同じテーブルの主キーを指すときに発生する。これにより、単一のテーブル内のデータ行が、その同じテーブル内の他の行を参照できるループが作られる。これは階層構造のデータをモデル化するための基本的な手法である。
主な特徴:
- 単一テーブル: 関係は完全に1つのテーブル構造内に存在する。
- 親子リンク: 1行が親となり、別の行が子となる。
- NULLの扱い: 階層の根(ルート)は、通常、外部キー列にNULL値を持つ。
- 循環論理: データ取得中に無限ループを防ぐために注意が必要である。
🏗️ 再帰的関係の核心構成要素
この関係を効果的に実装するためには、特定のデータベース構成要素が整合されている必要がある。スキーマ設計は、主キーと外部キーの相互作用に大きく依存する。
🔑 主キー
テーブル内のすべての行には一意の識別子が必要である。これがアンカーとなる。行が他の行を参照する際は、親行の一意の識別子を格納することで実現する。
- 安定性が求められる。主キーを変更することは複雑な操作である。
- 高速な検索パフォーマンスを得るために、インデックスを付けるべきである。
- 一般的には、自動増分の整数またはUUIDである。
🔗 外部キー
外部キー列は、主キーと同じテーブル内に存在する。この列は親行の主キーの値を保持する。この列が関係の方向を定義する。
- NULL許容: 階層において、最上位の項目(ルート)には親が存在しない。したがって、この列はNULL値を許容しなければならない。
- 制約: 外部キー制約により、格納された値が同じテーブル内の既存の主キーと一致することを保証する。
- インデックス: 必須ではないが、外部キー列にインデックスを付けることで、階層をたどるクエリの実行速度が著しく向上する。
📐 エンティティ関係図における可視化
自己参照エンティティを表現するためにERDを描く際、表記法は一見して混乱しやすい。標準的なERDツールは、接続を示すために特定の線を使用する。
視覚的表記ルール:
- エンティティボックスは一度だけ描かれる。
- 関係線は、同じボックス内の主キーを外部キーに接続する。
- この線はしばしばエンティティに戻り、視覚的な円を形成する。
- 基数マーカー(1:1、1:M)は、親が何人の子を持てるかを示すために線に配置される。
例:組織構造
| 概念 | 説明 | ERD表記 |
|---|---|---|
| 従業員 | モデル化されるエンティティ | 「従業員」とラベル付けされたボックス |
| マネージャー | 同じテーブルを参照する役割 | マネージャーIDから従業員IDへの線 |
| 報告ライン | 再帰的関係 | ループする矢印 |
| ルートノード | CEOまたは最上位の上司 | マネージャーIDにNULL値 |
🌳 再帰的データの一般的な利用ケース
再帰的関係は理論的なものではなく、データモデリングにおける実際の問題を解決する。このパターンが適用される最も一般的なシナリオを以下に示す。
1️⃣ 組織階層
すべての会社には構造がある。従業員はマネージャーに報告し、マネージャーはディレクターに報告し、ディレクターはVPに報告する。この連鎖は古典的なツリー構造である。
- データモデル: 「Employees」という名前の1つのテーブル。
- カラム:
従業員ID,名前,マネージャーID. - 論理: その
マネージャーID列は参照します従業員ID. - 利点: 新しい従業員を登録するには、1行だけを挿入すればよい。各部署ごとに新しいテーブルを作成する必要はない。
2️⃣ カテゴリツリー
ECプラットフォームでは、製品をネストされたカテゴリに分類することが多い。電子機器 > コンピュータ > ラップトップ。
- データモデル: 「Categories」という名前の1つのテーブル。
- 列:
カテゴリID,名前,親ID. - 論理: カテゴリには親を持つこともでき、ルートカテゴリ(parent_id が null)になることもできる。
- 利点: スキーマを変更せずに、必要なだけサブカテゴリを追加できる柔軟性。
3️⃣ 材料表(BOM)
製造にはしばしば複雑な部品リストが必要です。車はエンジンで構成されており、エンジンはピストンで構成されています。ときにはピストンが別のエンジンタイプの一部となることもあります。
- データモデル: 「Parts」という名前の1つのテーブル。
- 列:
part_id,説明,assembly_id. - ロジック: 部品は、他の部品を含む自体がアセンブリであることもできます。
- 利点: 複数レベルの製造構造を可能にします。
4️⃣ コメントスレッド
フォーラムやブログでは、ユーザーがコメントに返信できます。コメントには、返信している親コメントが存在する場合と、独立したコメントとして存在する場合があります。
- データモデル: 「Comments」という名前の1つのテーブル。
- 列:
comment_id,user_id,コンテンツ,parent_comment_id. - ロジック: 返信は元のコメントIDにリンクします。
- 利点: 議論の無限のネストをサポートしています。
⚙️ 実装上の考慮事項
スキーマの設計は最初のステップにすぎません。さまざまな状況下でデータが正しく動作することを保証するには、慎重な計画が必要です。
🛑 循環参照の防止
再帰的関係における重大なリスクは、循環を作ることです。たとえば、従業員Aが従業員Bを管理し、従業員Bが従業員Aを管理している場合、無限ループが発生します。
- アプリケーションロジック:データを挿入または更新する際、アプリケーションは階層の深さを確認し、循環が形成されないことを保証する必要があります。
- データベース制約:標準的なSQL制約では循環を簡単に防げません(現在の状態しかチェックできないため、結果としての状態は確認できないため)。ただし、一部のシステムでは、書き込み前にパスを検証するためにトリガーを使用できます。
- ルートノードの識別: 有効なツリーには、正確に1つのルートノード(外部キーがnullのノード)があることを確認してください。
📉 null値の扱い
階層のルートは出発点です。標準的な再帰的関係では、ルート行の外部キー列にnull値があります。
- クエリ処理: すべてのルートノードを見つけるには、外部キーがNULLの行を検索します。
- デフォルト値: 親を示すようなデフォルト値を外部キーに設定しないでください。0や-1などのデフォルト値は誤解を招き、データ整合性の問題を引き起こす可能性があります。
- 整合性: 外部キー列にnullを許容するようにデータベースエンジンを設定してください。NOT NULL制約を設けると、階層モデルが破綻します。
📈 パフォーマンスとインデックス
データが増えるにつれて、再帰構造のクエリは遅くなる可能性があります。特定のノードのすべての子孫を検索する単純なクエリでも、多くの結合や再帰クエリが必要になることがあります。
最適化戦略:
- 外部キーのインデックス作成: 親参照を保持する列にインデックスを作成します。これにより、子ノードの検索が高速化されます。
- 物化パス: 一部のシステムでは、階層の完全なパスを別々の列に保存します(例:”/1/5/12/20″)。これにより、文字列ベースのフィルタリングが高速化されますが、挿入ごとに更新が必要になります。
- ネストセット: 深さを表すために左と右の数値を使用する代替アルゴリズムです。検索には高速ですが、挿入には遅くなります。
- クエリの深さ: クエリ内の再帰の深さを制限してください。上限がなければ、無限ループがデータベースエンジンをクラッシュさせる可能性があります。
🔍 再帰的データの照会
階層データを取得することは、平坦なデータを取得するよりも複雑です。標準的なJOINは1レベルにのみ対応しますが、複数のレベルでは特別な論理が必要です。
🔄 自己結合
最も一般的な方法は、テーブルを自分自身と結合することです。テーブルを親として1回、子として1回別名を付ける必要があります。
- 1レベル:テーブルを自分自身と1回結合して、直近の親を取得します。
- 複数レベル:複数の結合が必要となり、すぐに扱いにくくなります。
- 欠点:必要な結合の数は、階層の深さに等しくなります。
🔁 再帰的共通テーブル式(CTE)
現代のデータベースエンジンは再帰的CTEをサポートしています。これにより、結合結果が見つからなくなるまで、クエリが自分自身とUNION ALLを実行できます。
- アンカー項目:再帰の出発点(通常はルートノード)。
- 再帰的項目:結果をテーブルに戻して次のレベルを見つけるために結合するクエリの部分。
- 終了条件:一致する行が見つからなくなると、クエリは停止します。
- 利点:事前に深さを知らなくても、任意の深さの階層を処理できます。
🛡️ データ整合性と制約
自己参照テーブルの整合性を維持することは非常に重要です。親が削除された場合、子はどうなるのでしょうか?
🗑️ 削除の伝播
親行が削除されたとき、データベースは子行をどう扱うかを決定しなければなりません。
- RESTRICT:子が存在する場合、親の削除を禁止します。データは保護されますが、必要なクリーンアップを妨げる可能性があります。
- CASCADE:親が削除されると、すべての子行が削除されます。深い階層では、誤って大量のデータを消去してしまう危険性があるため危険です。
- SET NULL:子の外部キーをNULLに設定し、新しいルートノードとして扱います。データ構造を保持するには、これがしばしば最も安全な選択です。
- デフォルトを設定:外部キーをデフォルト値(例:特定の孤立したカテゴリ)に設定します。
🔒 更新制約
親行の主キーを変更するのは危険です。マネージャーのIDを変更する場合、そのマネージャーを参照するすべての従業員レコードのIDも更新する必要があります。
- アプリケーション層:すべての参照が同時に更新されるように、更新をトランザクションで処理します。
- データベーストリガー:IDの変更の伝播を自動化できますが、これにより複雑性が増します。
- ベストプラクティス:再帰構造の主キーを更新する場合は、可能な限り避けてください。従業員コードのような自然キーではなく、サロゲートキー(自動増分整数)を使用してください。
🚧 一般的な問題のトラブルシューティング
慎重な設計をしても、開発や保守中に問題が発生する可能性があります。
❓ 木の深さをどうやって調べますか?
特定の行のレベルを調べるには、その行からルートまで上方向にたどる必要があります。移動回数を数えます。
- クエリアプローチ:上方向に移動する際に行数をカウントする再帰クエリを使用します。
- アプリケーションアプローチ:挿入時に深さをカラムに保存します。これによりクエリ時間は短縮されますが、メンテナンスが必要になります。
❓ 孤立ノードはどう処理しますか?
孤立ノードとは、外部キーが存在しない親を指している行のことです。これは通常、バグや手動でのデータ入力ミスによって発生します。
- 検証:定期的な整合性チェックを実行し、外部キーがどの主キーとも一致しない行を特定します。
- 回復:方針を決定します:ルートカテゴリに移動する、削除する、またはレビュー用にフラグを立てる。
❓ 時間が経つにつれてパフォーマンスが低下する
木が大きくなるにつれて、木全体をスキャンするクエリは遅くなるようになります。
- キャッシュ:頻繁にアクセスされる階層構造をアプリケーションメモリにキャッシュします。
- アーカイブ:階層の歴史的または非アクティブな部分をアーカイブテーブルに移動します。
- パーティショニング: データが非常に大きい場合は、ルートカテゴリごとにテーブルをパーティション分割してください。
📝 ベストプラクティスの要約
自己参照エンティティの堅牢な実装を確保するため、以下のガイドラインに従ってください。
- 代替キーを使用する: 主キーには、ビジネスキーよりも自動増分整数を優先してください。
- NULLを許可する: ルートノードに対して、外部キー列がNULL値を許可していることを確認してください。
- 外部キーにインデックスを設定する: 親参照を保持する列には、常にインデックスを設定してください。
- ループの検証: 円形参照(A → B → A)を防ぐためのチェックを実装してください。
- 再帰の深さ制限: クエリ内の再帰の深さを制限して、スタックオーバーフローを防いでください。
- スキーマを文書化する: ERDドキュメント内で、どの列が自己参照しているかを明確にマークしてください。
- 削除の計画: 親ノードの削除時に、連鎖削除のルールまたはNULL設定のルールを明確に定義してください。
- 深い階層のテスト: パフォーマンスが維持されることを確認するため、少なくとも10段階の深さでクエリをテストしてください。
🔮 今後の検討事項
データベース技術は継続的に進化しています。自己参照エンティティの概念は変わらないものの、それを管理するためのツールは改善されています。
- グラフデータベース: 一部の現代的なシステムでは、関係性を第一級の存在として扱います。再帰的なパスを、SQLの複雑さを伴わずにネイティブに処理できます。
- JSONサポート: 新しいデータベースエンジンでは、階層データをJSONカラムに格納できるため、深くネストされた構造のスキーマ設計を簡素化できます。
- ORMの改善: オブジェクトリレーショナルマッパーは、再帰的関係を自動的に処理する能力が向上しており、ボイラープレートコードを削減しています。
これらの進歩にもかかわらず、再帰的関係のコアロジックは同じままです。主キー、外部キー、テーブル関係の下層メカニズムを理解することは、データ構造を扱う技術者にとって不可欠です。
これらの原則に従うことで、複雑な階層を扱えるだけの柔軟性を持ちつつ、パフォーマンスと保守性を維持できるシステムを構築できます。自己参照エンティティは、正確かつ慎重に使用される限り、データモデリングの強力なツールです。