










Projektowanie architektury bazy danych w środowisku wielodostępnym wymaga dokładnej analizy izolacji danych, skalowalności oraz kosztów utrzymania. Diagram relacji encji (ERD) pełni rolę projektu tych decyzji, określając sposób strukturyzowania danych między użytkownikami. Wybór odpowiedniego podejścia wpływa na wydajność, bezpieczeństwo oraz możliwość ewolucji systemu w czasie. Niniejszy przewodnik omawia główne wzorce architektoniczne, ich konsekwencje dla ERD oraz zalety i wady każdej strategii.
🔍 Zrozumienie wielodostępowości w modelowaniu danych
Wielodostępność pozwala jednemu egzemplarzowi oprogramowania obsługować wielu klientów, często nazywanych użytkownikami. W kontekście projektowania bazy danych, głównym wyzwaniem jest określenie sposobu rozdzielenia danych użytkowników przy jednoczesnym zachowaniu wydajności. ERD musi jasno odzwierciedlać te granice rozdzielenia.
- Użytkownik: Osoba lub organizacja korzystająca z systemu.
- Współdzielony system: Logika aplikacji oraz potencjalnie podstawowa infrastruktura.
- Izolacja danych: Zapewnienie, że jeden użytkownik nie może uzyskać dostępu do danych innego.
Wybory projektowe głównie dotyczą położenia granicy izolacji. Czy znajduje się ona na poziomie bazy danych, schematu czy wiersza? Każde z tych rozwiązań wymaga określonej struktury ERD.
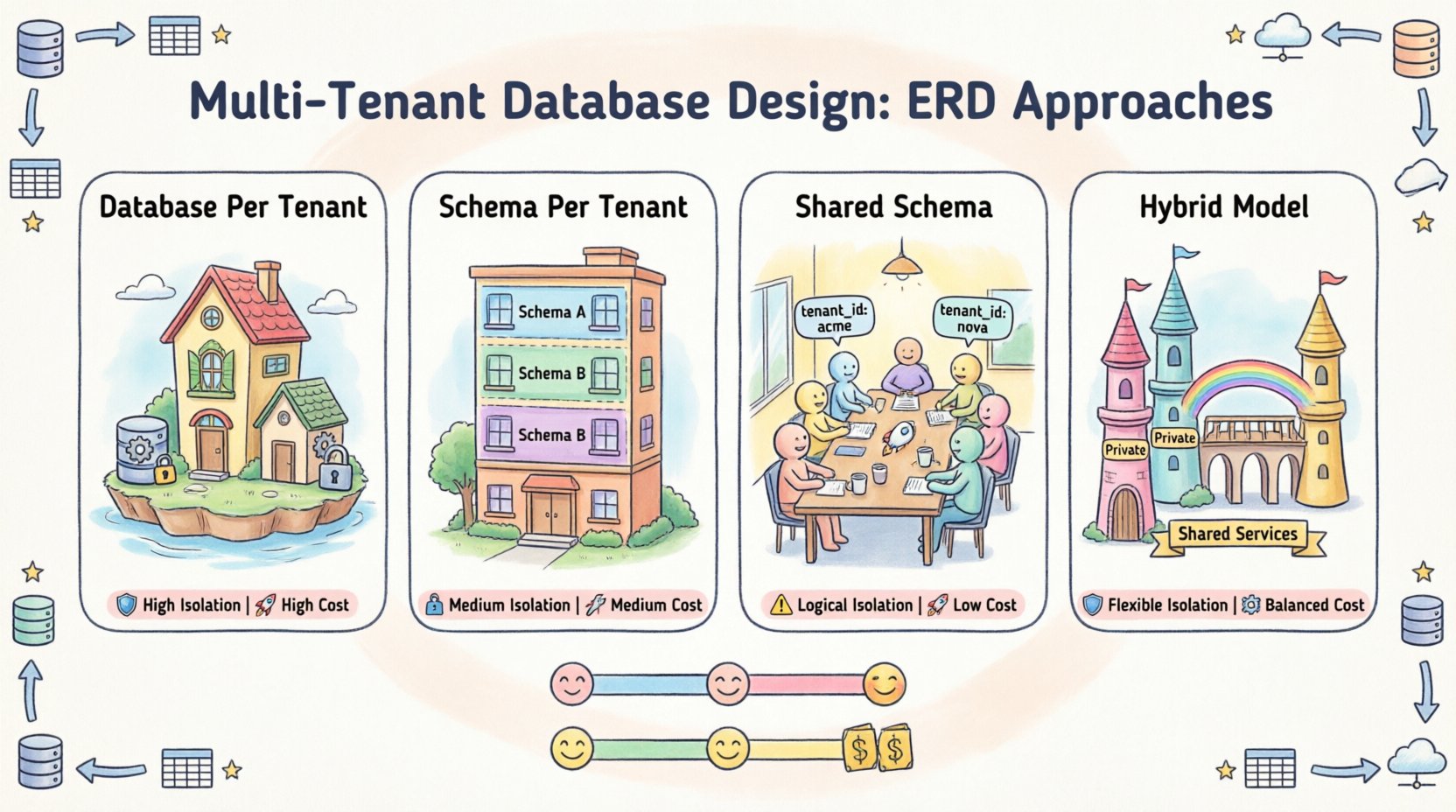
🏗️ Strategia 1: Baza danych na użytkownika
W tym modelu każdy użytkownik otrzymuje dedykowaną instancję bazy danych. Zapewnia to najwyższy poziom izolacji i bezpieczeństwa. Z punktu widzenia ERD schemat pozostaje identyczny we wszystkich bazach danych, ale fizyczne rozdzielenie jest bezwzględne.
📊 Struktura ERD
Diagram ERD dla bazy danych jednego użytkownika wygląda identycznie jak standardowy projekt dla jednego użytkownika. Nie ma potrzeby dodawania kolumnytenant_id ponieważ granica bazy danych sama w sobie pełni rolę filtra.
- Struktura tabeli: Tabele zawierają tylko dane dotyczące konkretnego użytkownika.
- Klucze obce: Standardowa integralność referencyjna obowiązuje bez uwzględniania użytkownika.
- Indeksy: Optymalizowane pod konkretny objętość danych danego użytkownika.
✅ Zalety
- Pełna izolacja: Naruszenie jednej bazy danych nie ma wpływu na inne.
- Dostosowanie: Modyfikacje schematu mogą być stosowane dla konkretnych użytkowników bez wpływu na innych.
- Wydajność: Brak konkurencji z innymi użytkownikami w tym samym puli połączeń lub I/O dysku.
❌ Wady
- Koszt: Wysokie koszty infrastruktury wynikające z wielu instancji.
- Konserwacja: Aktualizacje schematu wymagają wdrożenia do każdej instancji bazy danych.
- Złożoność: Zarządzanie połączeniami i koordynacją staje się trudne w skali.
🏗️ Strategia 2: Schemat na klienta
Ten podejście znajduje się pomiędzy dwoma poprzednimi. Każdy klient otrzymuje dedykowany schemat w tym samym serwerze bazy danych. Zmniejsza to obciążenie związane z zarządzaniem wieloma połączeniami do bazy danych, jednocześnie utrzymując oddzielność logiczną.
📊 Struktura ERD
ERD pozostaje zgodny z modelem jedno-klientowym, ale zmienia się przestrzeń nazw. Tabele istnieją w określonej przestrzeni nazw schematu, a nie w przestrzeni publicznej.
- Nazwy tabel: Standardowe konwencje nazewnictwa (np.
użytkownicy,zamówienia). - Nazwy schematów: Unikalne identyfikatory (np.
schemat_klient_a,schemat_klient_b). - Łączność: Aplikacja łączy się z konkretnym schematem dla aktywnego klienta.
✅ Zalety
- Izolacja: Silniejsza izolacja niż w modelach z wspólnym schematem.
- Zarządzanie: Łatwiejsze do zarządzania niż osobne instancje baz danych.
- Kopia zapasowa: Można przywrócić lub wykonać kopię zapasową poszczególnych schematów niezależnie.
❌ Wady
- Wykorzystanie zasobów: Nadal zużywa więcej zasobów niż w pełni współdzielony model.
- Złożoność zapytań: Agregowanie danych między użytkownikami wymaga dynamicznego przełączania schematu.
- Odchylenie schematu: Utrzymywanie synchronizacji schematów między wieloma użytkownikami jest pracochłonne.
🏗️ Strategia 3: Współdzielona baza danych, współdzielony schemat
To najpowszechniejszy sposób stosowany w aplikacjach SaaS. Wszyscy użytkownicy współdzielą tę samą bazę danych i te same tabele. Oddzielenie danych osiąga się logicznie za pomocą kolumny z unikalnym identyfikatorem.
📊 Struktura ERD
ERD musi jawnie zawierać kolumnętenant_id w każdej tabeli przechowującej dane specyficzne dla użytkownika. Ta kolumna działa jako klucz partycji.
- Tabele główne:
użytkownicy,zamówienia,produktywszystkie zawierają kolumnętenant_id. - Tabele współdzielone: Tabele takie jak
rolelubuprawnieniamogą być współdzielone przez wszystkich użytkowników. - Ograniczenia: Klucze obce mogą wymagać zakresu, aby zapewnić integralność referencyjną w kontekście użytkownika.
✅ Zalety
- Efektywność kosztów: Najniższe koszty infrastruktury.
- Utrzymanie: Zmiany schematu są natychmiast stosowane dla wszystkich użytkowników.
- Analiza: Łatwiej agregować dane do raportowania na poziomie całego systemu.
❌ Wady
- Złożone zapytania: Każde zapytanie wymaga filtrowania według
tenant_id. - Wydajność: Wysokie ryzyko zawieszenia, jeśli jeden użytkownik zużywa nadmierną ilość zasobów.
- Bezpieczeństwo: Wyższe ryzyko błędów logicznych prowadzących do ujawnienia danych.
🏗️ Strategia 4: Model hybrydowy
Model hybrydowy łączy elementy powyższych strategii. Na przykład wspólny schemat dla danych standardowych, ale dedykowany schemat dla wersji premium lub określonych użytkowników o wysokiej wartości.
📊 Struktura ERD
ERD staje się bardziej złożony, rozróżniając tabele wspólne i tabele specyficzne dla użytkownika.
- Tabele globalne: Przechowuj konfigurację lub współdzielone metadane.
- Tabele użytkownika: Przechowuj dane użytkownika z
tenant_idlub w osobnych schematach. - Łączenie: Operacje łączenia muszą uwzględniać zakres danych.
🛡️ Izolacja danych i rozważania dotyczące bezpieczeństwa
Niezależnie od wybranej strategii, izolacja danych jest najważniejsza. ERD musi wspierać mechanizmy zapobiegające przypadkowemu dostępowi do danych.
🔒 Bezpieczeństwo na poziomie wierszy
W modelu współdzielonej schematu można zdefiniować zasady bezpieczeństwa na poziomie wierszy (RLS). Silnik bazy danych ogranicza dostęp do wierszy, gdzieid_dostawcyzgodne jest z zautoryzowanym kontekstem.
- Realizacja:Zasady wymuszają sprawdzanie na każdym
SELECT,UPDATE, orazDELETEoperacji. - Zalety:Zapobiega błędom na poziomie aplikacji, które mogłyby spowodować wycieki danych.
- Wpływ na ERD: Wymaga jawnych
id_dostawcykolumn na wszystkich odpowiednich tabelach.
🔒 Ograniczenia kluczy obcych
Zapewnienie integralności referencyjnej między dostawcami może być trudne w modelach współdzielonych. Klucz obcy powinien idealnie nie wskazywać na tabelę obejmującą wiele dostawców, chyba że relacja jest jawnie globalna.
- Odwołanie do samego siebie: Jeśli tabela odwołuje się do samej siebie (np.
id_nadrzędne), toid_dostawcymusi być zgodne po obu stronach. - Globalne odwołania: Tabele takie jak
kategoriemogą być globalne, umożliwiając ich odwoływanie się przez dowolnego użytkownika.
⚡ Strategie wydajności i skalowania
Wraz ze wzrostem liczby użytkowników, wydajność staje się krytycznym zagadnieniem. Projekt ERD bezpośrednio wpływa na to, jak dobrze system się skaluje.
📈 Strategie indeksowania
Indeksy są kluczowe dla wydajności zapytań. W wspólnym schemacie,tenant_idkolumna powinna być częścią głównego klucza złożonego lub intensywnie indeksowana.
- Indeksy złożone:
(tenant_id, created_at)umożliwia skuteczne filtrowanie według użytkownika i czasu. - Indeksy częściowe:Indeksy mogą być tworzone tylko dla określonych warunków, co zmniejsza ich rozmiar.
- Unikaj:Indeksowanie kolumn, które nie pomagają w filtrowaniu użytkownika.
📦 Partycjonowanie
Partycjonowanie tabel może pomóc w zarządzaniu dużymi zestawami danych. Dane mogą być partycjonowane wedługtenant_idlub według zakresów czasowych w ramach użytkownika.
- Partycjonowanie zakresowe:Dzieli dane na podstawie zakresów dat.
- Partycjonowanie listowe:Dzieli dane na podstawie określonych identyfikatorów użytkowników.
- Zarządzanie:Partycje mogą być odłączane lub archiwizowane w celu poprawy wydajności.
🔧 Konserwacja i ewolucja schematu
Oprogramowanie się rozwija. Tabele muszą być dodawane, kolumny modyfikowane lub typy zmieniane. Wybrana architektura określa wysiłek potrzebny do tych zmian.
🔄 Aktualizacje schematu
- Wspólny schemat:Jeden skrypt migracji aktualizuje schemat dla wszystkich użytkowników. Jest to najprostsza droga.
- Baza danych na użytkownika: Skrypt migracji musi zostać wykonany dla każdej instancji bazy danych. Wymagana jest automatyzacja.
- Schematy na użytkownika: Podobne do bazy danych na użytkownika, ale zarządzane w ramach tej samej instancji.
📝 Zgodność wsteczna
Podczas modyfikacji ERD upewnij się, że zachowana jest zgodność wsteczna, aby uniknąć przestojów.
- Dodaj kolumny: Najpierw użyj kolumn z możliwością wartości null, następnie wypełnij dane, a następnie zrób kolumny niepuste.
- Usuń kolumny: Zmień nazwę kolumn przed ich usunięciem, aby zapobiec zmianom łamającym.
- Wersjonowanie: Rozważ wersjonowanie samego schematu, jeśli użytkownicy mogą wyłączyć aktualizacje.
📋 Porównanie podejść architektonicznych
| Cecha | Baza danych na użytkownika | Schemat na użytkownika | Współdzielony schemat |
|---|---|---|---|
| Izolacja | Wysoki | Średnie | Niski |
| Koszt | Wysoki | Średnie | Niski |
| Utrzymanie | Złożone | Średnie | Proste |
| Wydajność zapytań | Wysoki (bez filtrowania) | Średni | Zmienny (wymagane filtrowanie) |
| Złożoność ERD | Prosty (na bazę danych) | Prosty (na schemat) | Złożony (wymagane tenant_id) |
| Skalowalność | Pozioma | Pionowa | Pionowa/POzioma |
✅ Lista najlepszych praktyk
Zanim zakończysz projektowanie ERD dla systemu wielodostępowego, upewnij się, że spełnione są następujące kryteria.
- Zdefiniuj zakres użytkownika: Jasnieto zidentyfikuj, które dane należą do użytkownika, a które są globalne.
- Ujednolit nazewnictwo: Używaj spójnych zasad nazewnictwa dla
tenant_idkolumn we wszystkich tabelach. - Wymuszaj ograniczenia: Używaj ograniczeń bazy danych, aby zapobiec dostępowi do danych między użytkownikami tam, gdzie to możliwe.
- Zaplanuj odchody: Projektuj procesy dołączania i odłączania użytkowników (usunięcie danych lub archiwizacja).
- Testuj izolację: Regularnie testuj, aby upewnić się, że jeden użytkownik nie może uzyskać dostępu do danych innego użytkownika.
- Dokumentuj relacje: Jasnieto dokumentuj relacje kluczy obcych w dokumentacji ERD.
- Monitoruj wydajność: Skonfiguruj ostrzeżenia dla wolnych zapytań, które mogą wskazywać na problemy specyficzne dla użytkownika.
🧩 Obsługa przypadków granicznych
Scenariusze z rzeczywistego świata często wprowadzają złożoności, które standardowe diagramy ER nie pokrywają od razu.
🔄 Scalanie dzierżawców
Czasem dwóch dzierżawców łączy się w jednego. W wspólnym schemacie wymaga to przeniesienia wierszy z jednego tenant_id do drugiego. W modelu bazy danych na dzierżawcę wymaga to połączenia dwóch całych baz danych.
- Spójność danych: Upewnij się, że żadne dane nie zostaną utracone podczas scalania.
- Usuwanie duplikatów: Obsłuż duplikaty, które mogą pojawić się w wyniku scalania.
📉 Odrzucanie dzierżawców
Dzierżawcy opuszczają system. Decyzja o usunięciu danych lub ich archiwizacji wpływa na diagram ER.
- Miękkie usuwanie: Dodaj flagę
is_deletedaby zachować dane w celu zgodności z przepisami. - Twardy usuwanie: Usuń wiersze całkowicie. Upewnij się, że usunięcia kaskadowe są poprawnie skonfigurowane, aby uniknąć pozostawionych rekordów.
- Archiwizacja: Przenieś stare dane dzierżawcy do tabel przechowywania chłodnego, zachowując przy tym schemat.
🔗 Integracja z logiką aplikacji
Diagram ER nie jest wyspą. Musi bezproblemowo integrować się z warstwą aplikacji.
- Pośredniki: Użyj pośredników na poziomie aplikacji, aby wstrzyknąć
tenant_iddo każdego zapytania automatycznie. - Konfiguracja ORM: Skonfiguruj narzędzia mapowania obiektowo-relacyjnego, aby obsługiwać zakres dzierżawców.
- Projektowanie interfejsu API: Upewnij się, że punkty końcowe interfejsu API weryfikują kontekst dzierżawcy przed zwróceniem danych.
🎯 Ostateczne rozważania dotyczące projektowania
Wybieranie odpowiedniego projektu bazy danych dla środowiska wieloodbiornikowego to równowaga między izolacją a wydajnością. ERD działa jako umowa, która definiuje te granice. Nie ma jednego idealnego rozwiązania; wybór zależy od konkretnych wymagań dotyczących bezpieczeństwa, kosztów i skali. Zrozumienie skutków każdej strategii pozwala architektom tworzyć systemy wytrzymałe, skalowalne i bezpieczne.
Skupienie się na jasnych praktykach modelowania danych zapewnia, że system pozostaje utrzymywalny wraz ze wzrostem liczby odbiorców. Regularne przeglądy ERD pod kątem rzeczywistych wzorców użytkowania pomagają wykryć wąskie gardła lub luki bezpieczeństwa przed ich przekształceniem się w krytyczne problemy.
Na końcu celem jest projekt, który wspiera działalność biznesową bez naruszania integralności danych. Czynne planowanie na etapie ERD zapobiega kosztownemu przepisaniu kodu w przyszłości.