











W złożonej architekturze projektowania baz danych nieliczne pojęcia wyzwalają takie wyzwania dla inżynierów jak jednostka odnosząca się do siebie. Znaną również jako relacja rekurencyjna, ta konwencja pozwala tabeli na łączenie się z samą sobą, umożliwiając modelowanie hierarchii i złożonych struktur w płaskiej schemacie. Zrozumienie sposobu poprawnego jej implementacji jest kluczowe dla utrzymania integralności danych i wydajności zapytań.
Podczas projektowania diagramu relacji encji (ERD) większość relacji łączy dwa różne encje. Jednak dane z rzeczywistego świata często wymagają, by jedna encja odnosiła się do samej siebie. Menadżer zarządza pracownikami, kategoria zawiera podkategorie, a produkt może być częścią zestawu. Te sytuacje wymagają relacji rekurencyjnej.
Ten przewodnik bada mechanizmy, wzorce projektowania i najlepsze praktyki dotyczące obsługi jednostek odnoszących się do siebie. Przejrzymy, jak strukturalnie ułożyć te relacje bez oparcia się na konkretnych narzędziach programistycznych, skupiając się na uniwersalnych zasadach baz danych.
🧐 Co to jest jednostka odnosząca się do siebie?
Jednostka odnosząca się do siebie występuje, gdy klucz obcy w tabeli wskazuje na klucz główny tej samej tabeli. Powoduje to pętlę, w której wiersze danych w jednej tabeli mogą odnosić się do innych wierszy w tej samej tabeli. Jest to podstawowa technika modelowania struktur danych hierarchicznych.
Kluczowe cechy:
- Jedna tabela: Relacja istnieje całkowicie w jednej strukturze tabeli.
- Połączenie rodzic-dziecko: Jeden wiersz działa jako rodzic, a inny jako dziecko.
- Obsługa wartości null: Korzeń hierarchii zwykle ma wartość null w kolumnie klucza obcego.
- Logika cykliczna: Należy zachować ostrożność, aby zapobiec nieskończonym pętlom podczas pobierania danych.
🏗️ Podstawowe elementy relacji rekurencyjnych
Aby skutecznie zaimplementować tę relację, muszą być dopasowane określone składniki bazy danych. Projekt schematu zależy w dużej mierze od interakcji między kluczami głównymi a kluczami obcymi.
🔑 Klucz główny
Każdy wiersz w tabeli musi mieć unikalny identyfikator. Jest to punkt odniesienia. Gdy wiersz odnosi się do innego wiersza, robi to, zapisując unikalny identyfikator wiersza rodzica.
- Muszą być stabilne. Zmiana klucza głównego to skomplikowana operacja.
- Powinien być indeksowany, aby zapewnić szybkie wyszukiwanie.
- Zwykle jest to liczba całkowita zwiększająca się automatycznie lub UUID.
🔗 Klucz obcy
Kolumna klucza obcego znajduje się w tej samej tabeli co klucz główny. Przechowuje wartość klucza głównego wiersza rodzica. Ta kolumna określa kierunek relacji.
- Może być null: W hierarchii element najwyższego poziomu (korzeń) nie ma rodzica. Dlatego ta kolumna musi pozwalać na wartości null.
- Ograniczenie: Ograniczenie klucza obcego zapewnia, że przechowywana wartość odpowiada istniejącemu kluczowi głównemu w tej samej tabeli.
- Indeksowanie: Choć nie zawsze jest wymagane, indeksowanie kolumny klucza obcego znacznie przyspiesza zapytania przeszukujące hierarchię.
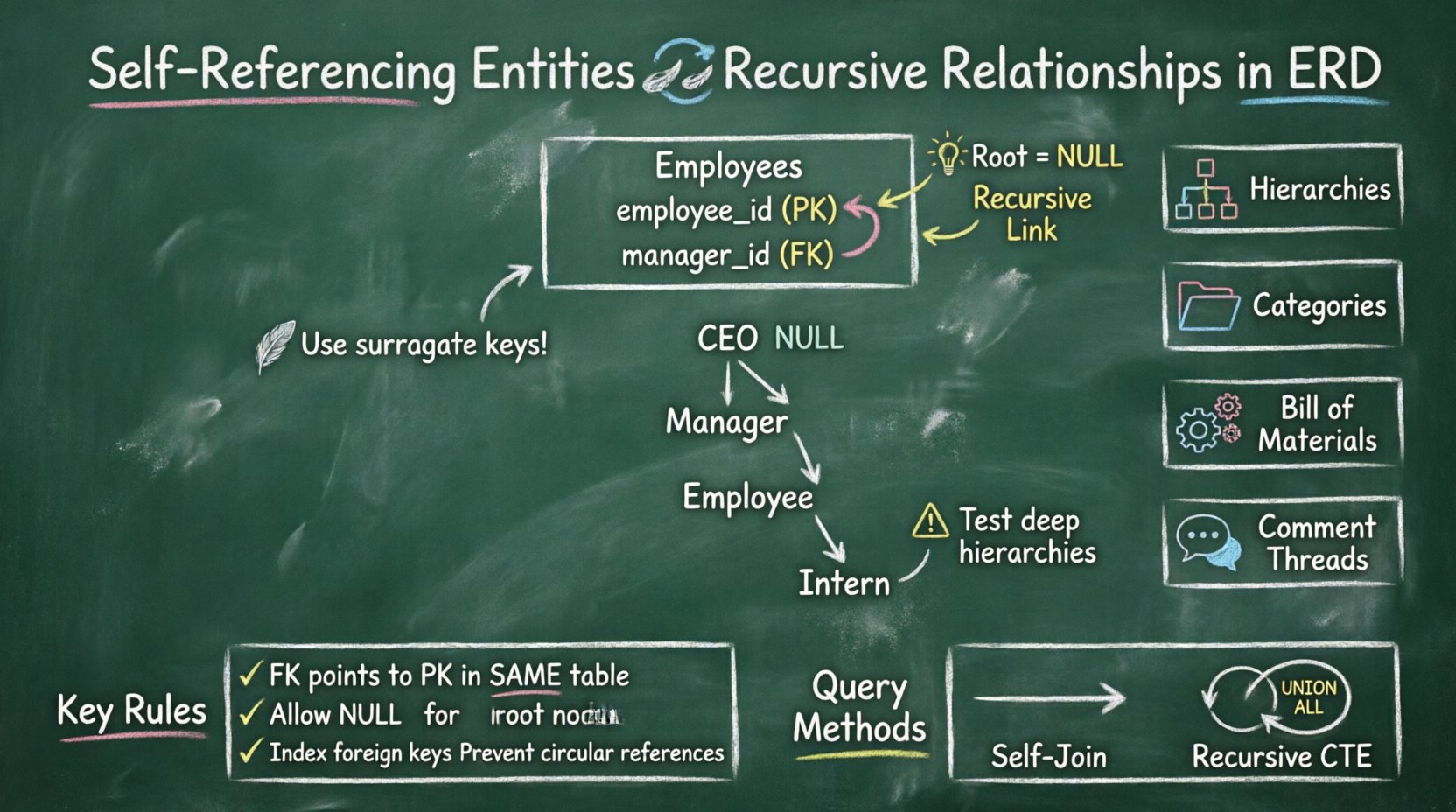
📐 Wizualizacja w diagramie relacji encji
Kiedy rysuje się diagram ERD w celu przedstawienia encji odwołującej się do samej siebie, notacja może być myląca na pierwszy rzut oka. Standardowe narzędzia ERD używają określonych linii do oznaczenia połączenia.
Zasady notacji wizualnej:
- Pole encji rysowane jest tylko raz.
- Linia relacji łączy klucz główny z kluczem obcym w tym samym polu.
- Linia często zakręca się z powrotem do encji, tworząc wizualny okrąg.
- Znaczniki liczności (1:1, 1:M) umieszczone są na linii, aby wskazać, ile dzieci może mieć rodzic.
Przykład: Struktura organizacyjna
| Koncepcja | Opis | Notacja ERD |
|---|---|---|
| Pracownik | Encja, która jest modelowana | Pole oznaczone jako „Pracownik” |
| Menadżer | Rola odnosząca się do tej samej tabeli | Linia od ID menadżera do ID pracownika |
| Linia raportowania | Relacja rekurencyjna | Zakrzywiony strzałka |
| Węzeł główny | CEO lub szef najwyższego szczebla | Wartość null w polu ID menadżera |
🌳 Typowe zastosowania danych rekurencyjnych
Relacje rekurencyjne nie są teoretyczne; rozwiązują rzeczywiste problemy w modelowaniu danych. Oto najczęściej występujące sytuacje, w których stosuje się ten wzorzec.
1️⃣ Hierarchie organizacyjne
Każda firma ma strukturę. Pracownicy raportują do menadżerów, którzy raportują do dyrektorów, którzy raportują do wiceprezesów. Ta łańcuchowość to klasyczna struktura drzewa.
- Model danych: Jedna tabela o nazwie „Pracownicy”.
- Kolumny:
employee_id,nazwa,manager_id. - Logika: Polecenie
manager_idkolumna odnosi się doemployee_id. - Zalety: Dodanie nowego pracownika wymaga jedynie wstawienia jednego wiersza. Nie ma potrzeby tworzenia nowej tabeli dla każdego działu.
2️⃣ Drzewa kategorii
Platformy e-commerce często organizują produkty w zagnieżdżonych kategoriach. Elektronika > Komputery > Laptopy.
- Model danych: Jedna tabela o nazwie „Kategorie”.
- Kolumny:
category_id,nazwa,parent_id. - Logika: Kategoria może mieć rodzica, albo może być kategorią główną (parent_id ma wartość null).
- Zalety: Elastyczność w dodawaniu dowolnej liczby podkategorii bez zmiany schematu.
3️⃣ Lista materiałów (BOM)
Wytwarzanie często wymaga skomplikowanych list części. Samochód składa się z silników, które są zbudowane z tłoków. Czasem tłok jest częścią innego typu silnika.
- Model danych: Jedna tabela o nazwie „Parts”.
- Kolumny:
part_id,opis,assembly_id. - Logika:Część może sama być zbiorem, zawierającym inne części.
- Zalety: Pozwala na struktury produkcyjne wielopoziomowe.
4️⃣ Wątki komentarzy
Forum i blogi pozwalają użytkownikom odpowiadać na komentarze. Komentarz może mieć komentarz nadrzędny, do którego się odnosi, albo może być samodzielny.
- Model danych: Jedna tabela o nazwie „Comments”.
- Kolumny:
comment_id,user_id,treść,parent_comment_id. - Logika:Odpowiedź łączy się z oryginalnym identyfikatorem komentarza.
- Zalety: Obsługuje nieskończoną głębokość zagnieżdżania dyskusji.
⚙️ Uwagi dotyczące implementacji
Projektowanie schematu to tylko pierwszy krok. Zapewnienie poprawnego zachowania danych w różnych warunkach wymaga dokładnego planowania.
🛑 Zapobieganie cyklicznym odwołaniom
Krytycznym ryzykiem w relacjach rekurencyjnych jest tworzenie cyklu. Na przykład pracownik A zarządza pracownikiem B, a pracownik B zarządza pracownikiem A. Powoduje to nieskończoną pętlę.
- Logika aplikacji: Podczas wstawiania lub aktualizowania danych aplikacja powinna sprawdzać głębokość hierarchii, aby upewnić się, że nie powstają cykle.
- Ograniczenia bazy danych: Choć standardowe ograniczenia SQL nie mogą łatwo zapobiegać cyklom (ponieważ sprawdzają stan aktualny, a nie stan końcowy), w niektórych systemach można użyć wyzwalaczy do weryfikacji ścieżki przed zapisem.
- Identyfikacja korzenia: Upewnij się, że każda poprawna struktura ma dokładnie jeden węzeł korzeniowy (gdzie klucz obcy ma wartość NULL).
📉 Obsługa wartości NULL
Korzeń hierarchii to punkt początkowy. W standardowej relacji rekurencyjnej wiersz korzeniowy ma wartość NULL w kolumnie klucza obcego.
- Zapytania: Aby znaleźć wszystkie węzły korzeniowe, zapytaj o wiersze, gdzie klucz obcy ma wartość NULL.
- Wartości domyślne: Nie ustawiaj wartości domyślnej dla klucza obcego, jeśli sugeruje to istnienie rodzica. Wartość domyślna 0 lub -1 może być myląca i prowadzić do problemów integralności danych.
- Integralność: Upewnij się, że silnik bazy danych pozwala na wartości NULL w kolumnie klucza obcego. Ograniczenie NOT NULL naruszy model hierarchii.
📈 Wydajność i indeksowanie
Wraz ze wzrostem danych zapytania dotyczące struktur rekurencyjnych mogą stać się powolne. Proste zapytanie w celu znalezienia wszystkich potomków konkretnego węzła może wymagać wielu połączeń lub zapytań rekurencyjnych.
Strategie optymalizacji:
- Indeksowanie kluczy obcych: Utwórz indeks na kolumnie przechowującej odniesienie do rodzica. Zwiększa to szybkość znajdowania dzieci.
- Zmaterializowane ścieżki: Niektóre systemy przechowują pełną ścieżkę hierarchii w osobnej kolumnie (np. “/1/5/12/20”). Pozwala to na szybsze filtrowanie oparte na ciągach znaków, choć wymaga aktualizacji przy każdym wstawieniu.
- Zestawy zagnieżdżone: Alternatywny algorytm wykorzystujący liczby lewe i prawe do reprezentacji głębokości. Jest szybszy przy pobieraniu, ale wolniejszy przy wstawianiu.
- Głębokość zapytania: Ogranicz głębokość rekursji w zapytaniach. Nieskończone pętle mogą spowodować awarię silnika bazy danych, jeśli nie zostaną ograniczone.
🔍 Wyszukiwanie danych rekurencyjnych
Pobieranie danych hierarchicznych jest bardziej złożone niż pobieranie danych płaskich. Standardowe JOIN-y działają tylko dla jednego poziomu, ale wiele poziomów wymaga specjalistycznej logiki.
🔄 Samozłączenia
Najczęściej stosowaną metodą jest złączenie tabeli z samą sobą. Aliaszujesz tabelę raz jako rodzica, a raz jako dziecko.
- Jeden poziom: Złącz tabelę z samą sobą raz, aby uzyskać bezpośredniego rodzica.
- Wiele poziomów: Wymaga wielu złączeń, które szybko stają się trudne do zarządzania.
- Wady: Liczba wymaganych złączeń równa się głębokości hierarchii.
🔁 Rekurencyjne wyrażenia tabelowe (CTEs)
Nowoczesne silniki baz danych obsługują rekurencyjne CTE. Pozwala to zapytaniu wykonywać UNION ALL względem samego siebie, aż nie zostaną znalezione żadne dodatkowe wiersze.
- Członek początkowy: Punkt początkowy rekursji (zazwyczaj węzeł główny).
- Członek rekurencyjny: Część zapytania, która łączy wynik z tabelą w celu znalezienia następnego poziomu.
- Zakończenie: Zapytanie kończy działanie, gdy nie zostaną znalezione żadne dodatkowe pasujące wiersze.
- Zalety: Obsługuje dowolną głębokość hierarchii bez konieczności z góry jej znanego.
🛡️ Integralność danych i ograniczenia
Zachowanie integralności tabeli z odniesieniami do samej siebie jest kluczowe. Jeśli usuniemy rodzica, co stanie się z dziećmi?
🗑️ Kasowanie kaskadowe
Gdy wiersz rodzica zostanie usunięty, baza danych musi zdecydować, jak obsłużyć wiersze dzieci.
- RESTRICT: Zapobiega usunięciu rodzica, jeśli istnieją dzieci. Zachowuje dane, ale może blokować konieczne czyszczenie.
- CASCADE: Usuwa wszystkie wiersze dzieci, gdy rodzic jest usunięty. Jest to niebezpieczne w głębokich hierarchiach, ponieważ może przypadkowo usunąć duże fragmenty danych.
- SET NULL: Ustawia klucz obcy dzieci na NULL, co czyni je nowymi węzłami głównymi. Jest to zazwyczaj najbezpieczniejsza opcja do zachowania struktury danych.
- Ustaw domyślnie: Ustawia klucz obcy na wartość domyślną (np. określoną kategorię sierotę).
🔒 Ograniczenia aktualizacji
Zmiana klucza głównego wiersza nadrzędnego jest ryzykowna. Jeśli zmienisz ID menedżera, musisz zaktualizować to ID we wszystkich rekordach pracowników, które na niego odnoszą się.
- Warstwa aplikacji: Obsłuż aktualizację transakcyjnie, aby upewnić się, że wszystkie odwołania są aktualizowane jednocześnie.
- Wyzwalacze bazy danych: Może automatyzować propagację zmian ID, choć dodaje to złożoności.
- Najlepsze praktyki: Unikaj aktualizowania kluczy głównych w strukturach rekurencyjnych, jeśli to możliwe. Używaj kluczy zastępczych (liczb całkowitych z autoinkrementacją) zamiast kluczy naturalnych (np. kodów pracowników).
🚧 Rozwiązywanie typowych problemów
Nawet przy starannym projekcie mogą pojawić się problemy podczas rozwoju i utrzymania.
❓ Jak znaleźć głębokość drzewa?
Aby określić poziom konkretnego wiersza, musisz przemierzyć drogę w górę od wiersza do korzenia. Policz liczbę przejść.
- Podejście zapytania: Użyj zapytania rekurencyjnego, które liczy wiersze w miarę poruszania się w górę.
- Podejście aplikacji: Przechowuj głębokość w kolumnie podczas wstawiania. Oszczędza to czas zapytania, ale wymaga utrzymania.
❓ Jak obsłużyć węzły sieroty?
Węzły sieroty to wiersze, w których klucz obcy wskazuje na niewystępujący rodzica. Zazwyczaj dzieje się to z powodu błędów lub błędów ręcznego wprowadzania danych.
- Weryfikacja: Uruchamiaj okresowe sprawdzanie integralności, aby znaleźć wiersze, w których klucz obcy nie odpowiada żadnemu kluczowi głównemu.
- Odzyskiwanie: Zdecyduj o polityce: przenieś je do kategorii głównej, usuń je lub oznacz do przeglądu.
❓ Degradacja wydajności w czasie
W miarę wzrostu drzewa zapytania skanujące całe drzewo stają się wolniejsze.
- Buforowanie: Buforuj często dostępną strukturę hierarchiczną w pamięci aplikacji.
- Archiwizacja: Przenieś historyczne lub nieaktywne części hierarchii do tabel archiwalnych.
- Partycjonowanie: Jeśli dane są ogromne, podziel tabelę według kategorii głównej.
📝 Podsumowanie najlepszych praktyk
Aby zapewnić solidną implementację encji samodzielnych, przestrzegaj tych zasad.
- Używaj kluczy zastępczych:Preferuj liczby całkowite zwiększane automatycznie przed kluczami biznesowymi dla klucza głównego.
- Zezwalaj na wartości NULL: Upewnij się, że kolumna klucza obcego pozwala na wartości NULL dla węzłów głównych.
- Indeksuj klucze obce: Zawsze indeksuj kolumnę przechowującą odniesienie do rodzica.
- Weryfikuj cykle: Zaimplementuj sprawdzanie, aby zapobiec odwołaniom cyklicznym (A -> B -> A).
- Ogranicz rekurencję: Ogranicz głębokość rekurencji w zapytaniach, aby zapobiec przepełnieniu stosu.
- Dokumentuj schemat: Jasno zaznacz, które kolumny są samodzielne w dokumentacji ERD.
- Zaplanuj usuwanie: Zdefiniuj jasne zasady dotyczące usuwania z kaskadą lub ustawiania wartości NULL przy usunięciu rodzica.
- Testuj głębokie hierarchie: Przetestuj swoje zapytania z co najmniej 10 poziomami głębi, aby upewnić się, że wydajność się utrzymuje.
🔮 Rozważania przyszłości
Technologia baz danych ciągle się rozwija. Choć koncepcja encji samodzielnej pozostaje stała, narzędzia do jej zarządzania się poprawiają.
- Bazy danych grafowych: Niektóre nowoczesne systemy traktują relacje jako obiekty pierwszej kategorii. Obsługują one ścieżki rekurencyjne naturalnie, bez złożoności SQL.
- Wsparcie dla JSON: Nowsze silniki baz danych pozwalają przechowywać dane hierarchiczne w kolumnach JSON, co może uprościć projektowanie schematu dla głęboko zagnieżdżonych struktur.
- Ulepszenia ORM: Mappery obiektowo-relacyjne stają się lepsze w automatycznym obsłudze relacji rekurencyjnych, zmniejszając ilość kodu szablonowego.
Mimo tych postępów, podstawowa logika relacji rekurencyjnej pozostaje taka sama. Zrozumienie mechanizmów kluczy głównych, kluczy obcych i relacji między tabelami jest niezbędne dla każdego specjalisty technicznego pracującego z strukturami danych.
Przestrzegając tych zasad, możesz budować systemy wystarczająco elastyczne, aby radzić sobie z złożonymi hierarchiami, jednocześnie pozostając wydajnymi i łatwymi do utrzymania. Encja samodzielna to potężne narzędzie w Twoim arsenale modelowania danych, pod warunkiem, że jest używana z precyzją i ostrożnością.