











Na polu architektury danych nieliczne pojęcia powodują więcej zamieszania niż relacja wiele do wielu. Podczas projektowania diagramu encji i relacji (ERD) pojawia się sytuacja, w której jedna encja łączy się z wieloma wystąpieniami innej encji, a odwrotnie, co wymaga określonego podejścia strukturalnego. Systemy zarządzania bazami danych relacyjnymi nie wspierają bezpośrednio relacji wiele do wielu. Wymagają one struktury pośredniej w celu zachowania integralności danych i zapewnienia skutecznego zapytania. Niniejszy przewodnik omawia autorytatywne metody rozwiązywania tych relacji, zapewniając, że Twój model danych pozostaje wytrzymały, skalowalny i znormalizowany.
Niezależnie od tego, czy projektujesz system do rejestrów akademickich, zarządzania zapasami czy uprawnień użytkowników, zasady rozwiązywania tych kardynalności pozostają niezmienne. Zrozumienie podstawowych mechanizmów zapobiega przyszłym anomalii i upraszcza utrzymanie systemu. Przejdziemy dalej niż powierzchowne definicje, by przeanalizować wymagania strukturalne, zasady normalizacji oraz strategie implementacji, które definiują profesjonalne modelowanie danych.
🔍 Zrozumienie kardynalności w diagramach ERD
Kardynalność określa liczbową relację między encjami w bazie danych. Określa liczbę wystąpień jednej encji, które mogą lub muszą być powiązane z każdym wystąpieniem innej encji. W notacji diagramu ERD relacja ta często przedstawiana jest za pomocą linii łączących encje, gdzie „kłody” (crow’s feet) oznaczają stronę „wiele”, a linie proste lub pojedyncze kreski oznaczają stronę „jeden”.
Istnieją trzy podstawowe kardynalności:
- Jeden do jednego (1:1):Pojedynczy rekord w encji A jest powiązany z pojedynczym rekordem w encji B. Przykład: osoba i jej paszport.
- Jeden do wielu (1:M):Pojedynczy rekord w encji A jest powiązany z wieloma rekordami w encji B. Przykład: klient składający wiele zamówień.
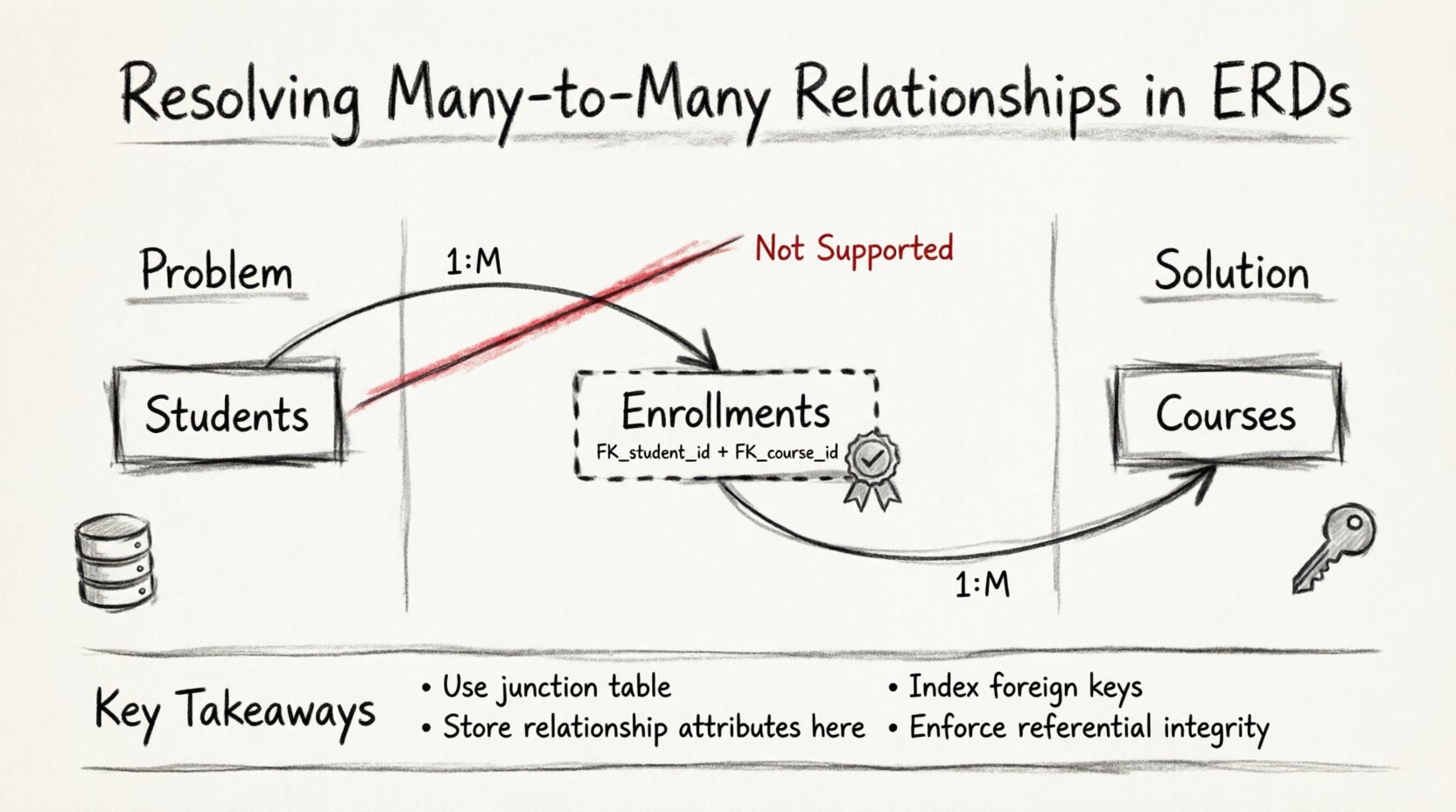
- Wiele do wielu (M:N):Wiele rekordów w encji A jest powiązanych z wieloma rekordami w encji B. Przykład: Studenci zapisujący się na wiele kursów, a kursy zawierające wielu studentów.
Podczas gdy relacje 1:1 i 1:M są proste w implementacji w fizycznym schemacie bazy danych, relacja M:N stwarza unikalne wyzwanie. Teoria relacyjna mówi, że komórka tabeli powinna zawierać tylko wartości atomowe. Bezpośrednie połączenie dwóch tabel, w którym pojedynczy wiersz w Tabeli A mógłby teoretycznie odnosić się do wielu wierszy w Tabeli B, narusza ten zasadę na poziomie fizycznym.
🚫 Dlaczego bezpośrednie relacje M:M failują w modelach relacyjnych
Model relacyjny, zaproponowany przez E.F. Codd, opiera się na pojęciu relacji (tabel), gdzie każda kolumna reprezentuje określony atrybut, a każdy wiersz – unikalne wystąpienie. Istnieją dwa główne powody, dla których bezpośrednią relację wiele do wielu nie można zrealizować w standardowej bazie danych relacyjnej:
- Brak wbudowanego wsparcia:Silniki baz danych nie pozwalają kolumnie klucza obcego na przechowywanie wielu wartości. Klucz obcy musi wskazywać na pojedynczy klucz główny w innej tabeli. Nie może wskazywać na listę kluczy.
- Anomalie wstawiania i usuwania:Jeśli spróbujesz przechowywać wiele identyfikatorów w jednej komórce (np. „Student_ID: 101, 102, 103”), naruszasz pierwszą postać normalną (1NF). Powoduje to, że zapytania, aktualizacje i usuwanie określonych relacji stają się obliczeniowo kosztowne i podatne na błędy.
W związku z tym, aby skutecznie przechowywać te dane, relacja musi być traktowana jako encja. Ta transformacja stanowi kluczową technikę rozwiązywania złożoności.
🧱 Technika 1: Encja pośrednicząca (tabela pośrednicząca)
Standardowym rozwiązaniem problemu relacji wiele do wielu jest utworzenie encji pośredniczącej, znanej również jako tabela pośrednicząca lub tabela mostowa. Tabela ta fizycznie znajduje się pomiędzy dwiema głównymi encjami i rozdziela bezpośrednią relację na dwie relacje jeden do wielu.
Gdy wprowadzisz tabelę pośredniczącą, oryginalna relacja M:N zostaje rozłożona na:
- Relację jeden do wielu między encją A a tabelą pośredniczącą.
- Relację jeden do wielu między encją B a tabelą pośredniczącą.
Struktura tabeli pośredniczącej:
- Klucze obce:Muszą zawierać co najmniej dwie kolumny kluczy obcych. Jedna odnosi się do klucza głównego encji A, a druga do klucza głównego encji B.
- Złożony klucz główny:Często kombinacja tych dwóch kluczy obcych stanowi klucz główny tabeli pośredniczącej. Zapewnia to, że określona para encji nie może być połączona więcej niż raz, chyba że relacja jest z natury wielowartościowa.
- Klucze zastępcze: W niektórych przypadkach do tabeli pośredniej dodawany jest unikalny identyfikator zwiększający się automatycznie. Jest to przydatne, jeśli relacja może mieć wiele wystąpień z różnymi atrybutami (np. uczeń może być zapisany na kursie wielokrotnie z różnymi ocenami w różnych latach).
Przykładowy scenariusz:
Rozważ system biblioteczny. KsiążkaKsiążka może być wypożyczana przez wieluCzytelników. CzytelnikCzytelnik może wypożyczać wieleKsiążek.
- Bez rozwiązania: Nie możesz bezpośrednio połączyć jednego wiersza książki z wieloma wierszami czytelników.
- Z rozwiązaniem: Utwórz tabelęDziennika_Wypożyczeńtabelę.
- TabelaDziennika_Wypożyczeń zawiera
ID_KsiążkiiID_Czytelnika.
Ta struktura pozwala bazie danych śledzić dokładnie, który czytelnik ma którą książkę w dowolnym momencie, bez duplikowania danych o książkach lub czytelnikach.
📝 Technika 2: Obsługa atrybutów w relacjach
Kluczowa różnica w modelowaniu ERD polega na tym, czy relacja między jednostkami zawiera własne dane. W prostym łączeniu relacja istnieje lub nie istnieje. Jednak w wielu sytuacjach z rzeczywistego świata relacja sama w sobie ma własności.
Na przykład w przypadkuProjektuiPracownika scenariusz, pracownik może pracować nad wieloma projektami, a projekt może mieć wielu pracowników. Ale relacja może obejmować:
- Rola:Czy pracownik jest programistą, projektantem czy menedżerem w tym konkretnym projekcie?
- Godziny przypisane:Ile godzin tygodniowo jest przypisanych do tego projektu?
- Data rozpoczęcia:Kiedy rozpoczęto tę przypisanie?
Jeśli traktujesz relację wyłącznie jako dwustanową flagę, utracisz te istotne dane. Tabela pośrednicząca staje się idealnym miejscem do przechowywania tych atrybutów.
Zasady implementacji:
- Nie przechowuj atrybutów relacji w encjach nadrzędnych. Nie należą one wyłącznie do projektu ani wyłącznie do pracownika.
- Umieść wszystkie dane specyficzne dla relacji w tabeli pośredniczącej.
- Upewnij się, że tabela pośrednicząca ma unikalny identyfikator (złożony lub zastępczy), aby umożliwić aktualizację tych atrybutów bez wpływu na encje nadrzędne.
Ten podejście zapewnia normalizację danych. Gdybyś dodał kolumnęRola do tabeliPracownik to spowodowałoby nadmiarowość, jeśli pracownik ma wiele ról w różnych projektach. Tabela pośrednicząca izoluje tę zmienność.
⚖️ Technika 3: Normalizacja i integralność danych
Rozwiązywanie relacji M:N nie polega tylko na łączeniu tabel; polega na przestrzeganiu zasad normalizacji w celu zapobiegania anomalii danych. Trzecia postać normalna (3NF) jest standardowym celem większości systemów transakcyjnych.
Wymagania trzeciej postaci normalnej (3NF):
- Tabela musi znajdować się w drugiej postaci normalnej (2NF).
- Wszystkie atrybuty niekluczowe muszą zależeć wyłącznie od klucza głównego.
Tworząc tabelę pośredniczącą, zapewnicasz, że dane relacji zależą od klucza złożonego tabeli pośredniczącej, a nie od kluczy poszczególnych encji. Usuwa to zależności przechodnie.
Integralność referencyjna:
Ograniczenia kluczy obcych są istotne w tabeli pośredniczącej. Wymuszają one następujące zasady:
- W
Book_IDw dzienniku wypożyczeń musi istnieć w tabeliKsiążkitabeli. - A
ID_Klientaw dzienniku wypożyczeń musi istnieć w tabeli Klienci tabela.
To zapobiega zanieczyszczeniu rekordów. Nie możesz zalogować zdarzenia wypożyczenia książki, która nie istnieje w katalogu. Silniki baz danych wymuszają to za pomocą CASCADE lub RESTRICT działań przy usuwaniu.
📊 Porównanie typów relacji
Wizualizacja różnic między typami relacji pomaga w wyborze odpowiedniej strategii modelowania. Poniższa tabela podsumowuje wymagania strukturalne i złożoność implementacji.
| Typ relacji | Realizacja fizyczna | Lokalizacja klucza podstawowego | Złożoność |
|---|---|---|---|
| Jeden do jednego (1:1) | Klucz obcy w jednej tabeli | Którakolwiek tabela | Niska |
| Jeden do wielu (1:M) | Klucz obcy w tabeli „wiele” | Tabela podstawowa | Średnia |
| Wiele do wielu (M:N) | Oddzielna tabela pośrednicząca | Tabela pośrednicząca (złożona) | Wysoka |
Jak pokazano, relacja M:N wymaga największego obciążenia strukturalnego. Jednak to obciążenie jest niezbędne dla integralności danych. Koszt dodatkowego połączenia podczas zapytania często przeważa koszt niezgodności danych w słabo zaprojektowanym schemacie.
🚀 Zdjęcia dotyczące wydajności
Dodanie tabeli pośredniczącej dodaje warstwę pośrednictwa do zapytań. Przy pobieraniu danych musisz łączyć trzy tabele zamiast dwóch. W systemach o dużym obciążeniu może to wpływać na wydajność, jeśli nie zostanie odpowiednio zarządzane.
- Indeksowanie: Każdy klucz obcy w tabeli pośredniczącej powinien być indeksowany. Pozwala to silnikowi bazy danych szybko znajdować wiersze dla określonego obiektu bez przeszukiwania całej tabeli pośredniczącej.
- Indeksy złożone: W niektórych przypadkach tworzenie indeksu na kombinacji obu kluczy obcych jest bardziej wydajne niż osobne indeksy. Umożliwia to zapytania filtrowane jednocześnie według obu obiektów.
- Odczyt vs. Zapis: Tabele pośredniczące są zazwyczaj ciężkie w zapisie, jeśli relacje są dynamiczne. Są ciężkie w odczycie podczas generowania raportów. Upewnij się, że strategia indeksowania wspiera dominującą metodę działania aplikacji.
⚠️ Powszechne pułapki i rozwiązania
Nawet doświadczeni modelerzy popełniają błędy przy rozwiązywaniu liczności. Znajomość powszechnych błędów może zaoszczędzić znaczną ilość czasu na refaktoryzacji w przyszłości.
1. Błąd „jednej kolumny”
Próba przechowywania wielu identyfikatorów w jednej kolumnie przy użyciu wartości rozdzielonych przecinkami (np. „1, 2, 3”). Narusza to zasady bazy danych i sprawia, że zapytania są niemożliwe bez funkcji parsowania ciągów. Zawsze używaj osobnego wiersza dla każdego wystąpienia relacji.
2. Nadmiarowe atrybuty
Kopiowanie atrybutów z encji nadrzędnych do tabeli pośredniczącej bez potrzeby. Jeśli atrybut należy do encji (np. imię ucznia), powinien znajdować się w tabeli ucznia, a nie w tabeli rejestracji. Umieszczaj tylko dane opisujące samą relację.
3. Ignorowanie możliwości wartości NULL
Definiowanie kluczy obcych jako dopuszczających wartości NULL, gdy powinny być wymagane. Jeśli relacja jest wymagana (np. zamówienie musi mieć klienta), klucz obcy nie powinien dopuszczać wartości NULL. To zapewnia stosowanie reguł biznesowych na poziomie bazy danych.
4. Cykliczne odniesienia
Tworzenie tabeli pośredniczącej, która odwołuje się do samej siebie bez potrzeby. Upewnij się, że tabela pośrednicząca łączy tylko dwa różne obiekty uczestniczące w relacji. Unikaj tworzenia pętli, które nie mają funkcjonalnego znaczenia.
🎨 Najlepsze praktyki wizualnej reprezentacji
Podczas dokumentowania diagramu ERD kluczowe jest jasność. Wizualna reprezentacja powinna natychmiast przekazać zrozumienie zakończonej struktury każdemu, kto analizuje schemat.
- Oznacz tabelę pośredniczącą: Nadaj tabeli opisową nazwę. Zamiast „Table3” użyj „Student_Course_Enrollment”.
- Wskazuj liczność: Jasno oznacz linie łączące tabelę pośredniczącą z encjami nadrzędnymi. Użyj znaku „kłosów” po stronie tabeli pośredniczącej, aby pokazać relację „wielu” z perspektywy encji nadrzędnej.
- Pokaż atrybuty: Jeśli tabela pośrednicząca ma atrybuty (np. „Ocena” lub „Data”), wyraźnie je wymień na schemacie. To podkreśla, że relacja jest bardziej niż tylko połączeniem.
- Używaj różnych stylów linii: Niektóre narzędzia modelowania pozwalają na używanie linii przerywanych dla relacji opcjonalnych i ciągłych dla wymaganych. Spójność w tym zakresie ułatwia zrozumienie.
🔄 Relacje rekurencyjne i M:N
Czasem relacja wiele do wielu istnieje w obrębie jednej encji. Na przykład, Pracownik może zarządzać wieloma innymi Pracownicy, a ci pracownicy mogą zarządzać innymi. Jest to relacja rekurencyjna M:N.
Rozwiązanie pozostaje takie samo jak w standardowej relacji M:N. Nadal tworzysz tabelę pośrednią, ale oba klucze obce w tej tabeli odnoszą się do klucza głównego tej samej encji.
- Encja: Pracownik
- Tabela pośrednia: Zarządzanie_Pracownikami
- FK1: ID_Kierownika (odnosi się do Pracownika)
- FK2: ID_Podwładnego (odnosi się do Pracownika)
Ta struktura pozwala na tworzenie złożonych hierarchii organizacyjnych bez naruszania zasad normalizacji. Umożliwia zapytania przemieszczające się przez wiele poziomów głębi zarządzania.
🛡️ Ograniczenia danych i zasady biznesowe
Ograniczenia techniczne nie wystarczają; zasady biznesowe muszą być stosowane. Tabela pośrednia stanowi naturalne miejsce na ich zastosowanie.
- Ograniczenia unikalności: Upewnij się, że określona relacja nie może zostać utworzona ponownie, chyba że jest to zamierzone. Na przykład student nie powinien być zapisany na tę samą część kursu dwukrotnie w tym samym semestrze. Ograniczenie unikalności na kombinację Student_ID i Course_ID zapewnia to.
- Ograniczenia sprawdzające: Weryfikuj dane numeryczne. Na przykład „Godziny_Przypisane” w tabeli pośredniej projektu muszą być większe od zera i mniejsze niż 40.
- Wyzwalacze: W złożonych systemach mogą być wymagane wyzwalacze do aktualizacji tabel podsumowujących. Jeśli tabela pośrednia ulegnie zmianie, tabela podsumowująca w encji nadrzędnej (np. „Łączna_Liczba_Projektów_Dla_Pracownika”) może wymagać automatycznej aktualizacji.
📈 Ewolucja modelu
Modele ewoluują wraz z zmianami wymagań. Relacja, która zaczyna się jako wiele do wielu, może uprościć się do jednego do wielu, jeśli zmieni się zasada biznesowa. Na przykład, jeśli polityka zmieni się tak, że student może być zapisany tylko na jeden kurs naraz, tabela pośrednia może zostać scalona z tabelą studenta.
Jednak zaczynanie od tabeli pośredniej jest zazwyczaj bezpieczniejsze. Pozwala na maksymalną elastyczność. Jeśli wymagania zmienią się później, umożliwiając wiele zapisów, schemat jest już przygotowany. Jeśli zacznie się od scalonej tabeli, później trzeba będzie przepisać kod.
📝 Podsumowanie kluczowych wniosków
Rozwiązywanie relacji wiele do wielu to podstawowa umiejętność projektowania baz danych. Wymaga tworzenia struktury pośredniej w celu zachowania integralności danych i wspierania skutecznych zapytań. Tabela pośrednia to standardowe rozwiązanie, które rozdziela złożone relacje na zarządzalne relacje jeden do wielu.
- Zawsze rozwiąż relację M:N: Nigdy nie próbuj przechowywać wielu kluczy obcych w jednym kolumnie.
- Używaj kluczy złożonych: Kombinacja kluczy obcych często pełni rolę unikalnego identyfikatora relacji.
- Przechowuj dane dotyczące relacji:Umieść atrybuty specyficzne dla połączenia w tabeli połączeniowej.
- Indeksuj klucze obce:Wydajność zależy od szybkich wyszukiwań wierszy w tabeli połączeniowej.
- Wymuszaj ograniczenia:Używaj ograniczeń unikalności i odwołań kluczy obcych, aby zapobiec nieprawidłowym danym.
Przestrzegając tych technik, zapewnicasz, że schemat bazy danych jest odporny na zmiany i w stanie radzić sobie z złożonymi interakcjami danych. Wkład w poprawne modelowanie w fazie projektowania przynosi korzyści pod względem utrzymywalności i wydajności na całym cyklu życia systemu.