










Projektowanie solidnego modelu danych wymaga więcej niż tylko mapowania encji i relacji. Wymaga to zrozumienia, jak dane ewoluują z czasem. W tradycyjnych diagramach encji i relacji (ERD) często zapisujemy stan rekordu w jednym konkretnym momencie. Przechowujemy aktualną wartość pensji, aktywny status użytkownika lub najnowszą cenę produktu. Jednak analiza biznesowa i zgodność z przepisami często wymagają wiedzy nie tylko o tym, co jest prawdziwe teraz, ale także o tym, co było prawdziwe w przeszłości.
To właśnie tutaj wchodzi w grę modelowanie danych czasowych. Przekształca ono statyczny schemat w dynamiczny tracker historii. Integracja wymiarów czasu bezpośrednio do Twojego ERD zapewnia, że każdy zmiany jest zapisana, audytowalna i możliwa do zapytania bez utraty kontekstu, kiedy te zmiany miały miejsce. Ten przewodnik omawia techniki strukturalne wymagane do budowy systemów baz danych świadomych czasu.
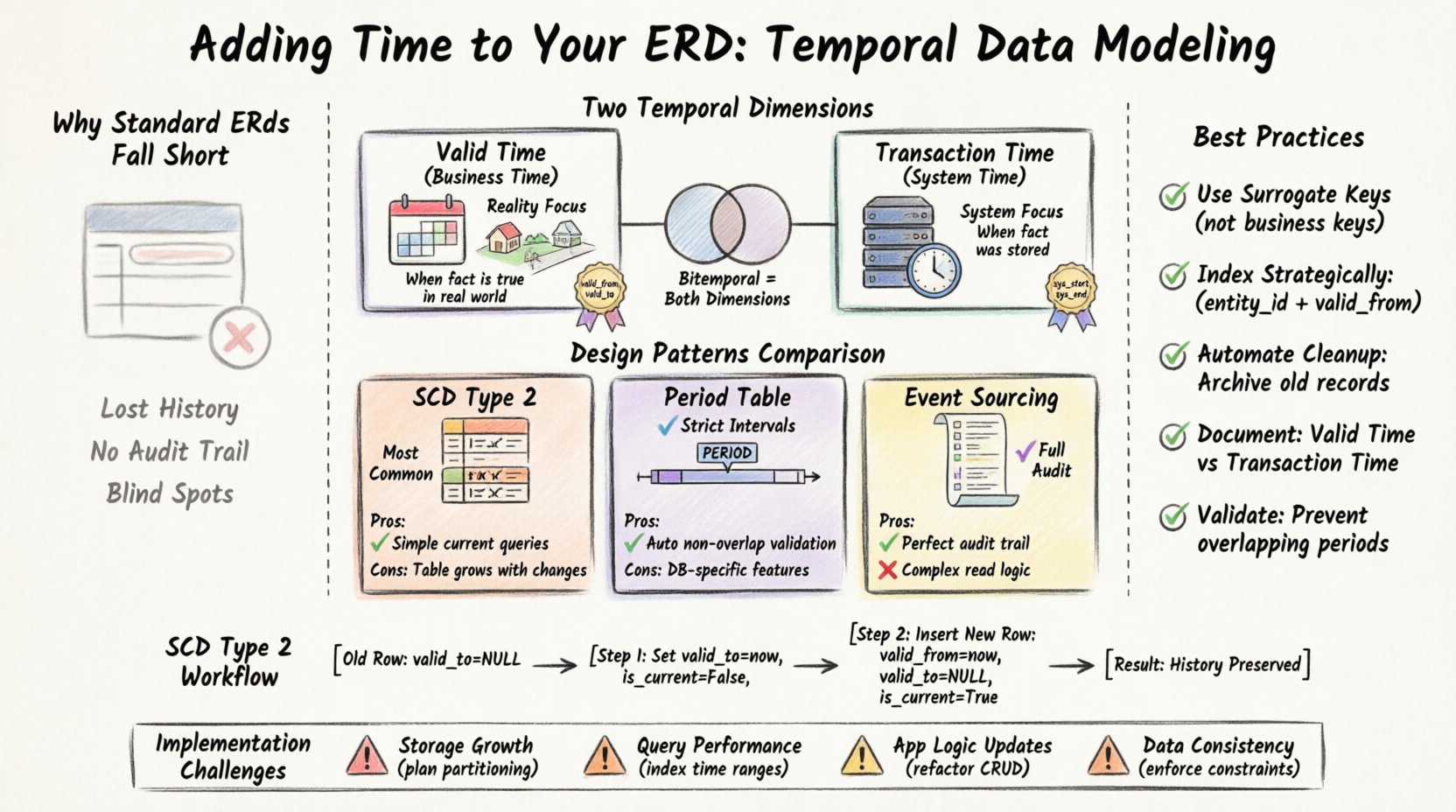
Dlaczego standardowe ERD są słabe w przypadku historii 📉
Klasyczne ERD skupiają się na obecnym stanie. Gdy rekord jest aktualizowany, poprzednia wartość jest zazwyczaj nadpisywana. Choć działa to dobrze w prostych systemach operacyjnych, tworzy znaczne puste miejsca w potrzebach analitycznych. Rozważ sytuację, w której musisz odtworzyć historię rozliczeń klienta przez ostatnie pięć lat. Standardowa tabela może pokazywać tylko aktualny adres lub aktualny poziom subskrypcji.
Bez modelowania czasowego napotykasz kilka wyzwań:
- Utrata kontekstu:Nie możesz określić, kiedy zmiana ceny naprawdę miała miejsce w świecie rzeczywistym, a kiedy została wprowadzona do systemu.
- Złożoność audytu:Tworzenie osobnej tabeli dziennika audytu wymaga ręcznej implementacji triggerów i dodaje obciążenie do każdej operacji zapisu.
- Trudność zapytań:Odtworzenie linii czasu często wymaga skomplikowanych łączeń lub samolinków, które są trudne do utrzymania i optymalizacji.
- Integralność danych:Bez jasnych ograniczeń czasowych łatwo przypadkowo nadpisać dane historyczne podczas aktualizacji masowych.
Wkładając czas bezpośrednio do schematu, przenosisz odpowiedzialność za śledzenie historii z logiki aplikacji do samego struktury danych.
Zrozumienie wymiarów czasowych ⏳
Aby skutecznie modelować czas, musisz rozróżnić różne sposoby istnienia czasu w bazie danych. Są dwa główne wymiary do rozważenia: Czas Prawdziwy i Czas Transakcji. Zrozumienie różnicy jest kluczowe dla wyboru odpowiedniej techniki modelowania.
1. Czas Prawdziwy (czas biznesowy)
Czas Prawdziwy reprezentuje okres, w którym fakt jest prawdziwy w świecie rzeczywistym. Jest niezależny od systemu bazy danych. Na przykład, jeśli dział pracownika zmienił się z sprzedaży na inżynierię 1 stycznia, Czas Prawdziwy dla przypisania do inżynierii zaczyna się tego dnia, niezależnie od tego, kiedy menedżer HR wpisał to do systemu.
- Skupienie:Rzeczywistość.
- Przypadek użycia:Raportowanie historyczne, audyt zgodności, odtwarzanie stanów przeszłych.
- Atrybuty:Zazwyczaj zaimplementowane z użyciem
valid_fromivalid_toznaczników czasu.
2. Czas Transakcji (czas systemowy)
Czas transakcji śledzi, kiedy fakt został zapisany w bazie danych. Jest zarządzany całkowicie przez system. Jeśli użytkownik edytuje rekord dzisiaj, czas transakcji zapisuje ten konkretny moment. Jeśli rekord zostanie usunięty, czas transakcji zapewnia, że system wie, kiedy przestał być widoczny w zbiorze aktywnym.
- Skupienie: Operacje systemowe.
- Przypadek użycia: Debugowanie problemów z danymi, zrozumienie stanu systemu w konkretnym momencie, możliwości cofnięcia zmian.
- Atrybuty: Zazwyczaj zarządzany automatycznie przez silnik bazy danych jako
sys_startisys_end.
3. Dane bitemporalne
Gdy potrzebujesz zarówno czasu ważności, jak i czasu transakcji, budujesz tabelę bitemporalną. Jest to najbardziej kompleksowa forma modelowania czasowego. Pozwala zadawać pytania takie jak: „Co system sądził za prawdziwe 1 marca 2023 roku w odniesieniu do rzeczywistego stanu świata 1 stycznia 2023 roku?”
Wzorce projektowe dla schematów świadomych czasu 🛠️
Istnieje kilka wzorców architektonicznych implementacji danych czasowych w modelu ERD. Wybór zależy od wzorców zapytań i ograniczeń pamięci.
Wzorzec Wymiaru Zmieniającego Się Powoli (SCD) Typ 2
Jest to najpowszechniejsza technika śledzenia historii w magazynach danych. Zamiast aktualizować wiersz, wstawiasz nowy wiersz z nowym identyfikatorem wersji. Stary wiersz oznaczany jest jako nieaktywny.
- Dodatkowy klucz:
surrogate_key(aby połączyć z nową wersją) iis_activeflaga. - Zalety: Proste zapytania do znalezienia bieżącego rekordu przy użyciu filtra.
- Wady: Tabela rośnie liniowo wraz z zmianami. Usunięcie wiersza wymaga aktualizacji wszystkich poprzednich wersji lub oznaczenia ich.
Wzorzec tabeli okresu
W tym podejściu czas jest przechowywany jako typ okresu zamiast dwóch oddzielnych kolumn. Jest to często wspierane bezpośrednio przez nowoczesne silniki baz danych. Zapewnia, że okresy się nie nakładają.
- Dodatkowy klucz: A
OKRESograniczenie typu danych. - Zalety: Automatyczne zapewnienie niezamieszczonych zakresów czasowych.
- Wady: Wymaga określonych funkcji bazy danych, które mogą nie być dostępne we wszystkich systemach.
Wzorzec źródła zdarzeń
Zamiast przechowywać bieżący stan, przechowujesz sekwencję zdarzeń. Stan jest odtwarzany poprzez ponowne odtworzenie tych zdarzeń. Jest to bardzo szczegółowe, ale może być kosztowne obliczeniowo podczas odczytu.
- Główna dodatkowa funkcja: Tabela dziennika tylko do dodawania.
- Zalety: Idealny ślad audytowy; dane nigdy nie są usuwane.
- Wady: Złożona logika odczytu; odtworzenie stanu nie jest natychmiastowe.
Sposób SCD Typ 2 szczegółowo 🔄
Dla większości aplikacji przedsiębiorstw SCD Typ 2 oferuje najlepszy kompromis między złożonością a użytecznością. Spójrzmy, jak to przejawia się w strukturze ERD.
Wyobraź sobie Klient encję. W standardowym modelu masz jedną wiersz na identyfikator klienta. W modelu czasowym masz wiele wierszy dla tego samego identyfikatora klienta, rozróżnionych według czasu.
Wymagane atrybuty:
identyfikator_klienta: Naturalny klucz biznesowy.identyfikator_wersji: Unikalny identyfikator dla każdego konkretnego rekordu.od_validności: Znacznik czasu, gdy ten rekord stał się obowiązujący.do_validności: Znacznik czasu, gdy ten rekord przestał być obowiązujący. Często ustawiany na NULL dla bieżącego rekordu.czy_bieżący: Flagi logiczne do szybkiego identyfikowania najnowszego stanu.
Gdy klient zmienia swój adres, nie aktualizujesz istniejącego wiersza. Zamiast tego wykonaj:
- Zaktualizuj
valid_toistniejącego wiersza adresu na bieżący znacznik czasu. - Ustaw
is_currentna False dla starego wiersza. - Wstaw nowy wiersz z nowym adresem.
- Ustaw
valid_fromna bieżący znacznik czasu. - Ustaw
valid_tona NULL. - Ustaw
is_currentna True.
Tabele okresów i prawidłowy czas 🗓️
Choć SCD Type 2 jest elastyczny, Tabele okresów oferują bardziej rygorystyczną definicję czasu. W tym modelu przedział czasu jest jednym atrybutem. Pomaga to zapobiegać błędom logicznym, w których valid_from jest większe niż valid_to.
Zastanów się nad poniższym schematem struktury dla Tabeli okresów:
| Nazwa kolumny | Typ | Opis |
|---|---|---|
entity_id |
UUID | Klucz podstawowy dla jednostki |
wartość_danych |
VARCHAR | Śledzony atrybut |
okres_czasu |
PERIOD(TIMESTAMP) | Początek i koniec ważności |
wersja_systemu |
INT | Numer kolejny dla wiersza |
Ta struktura zapewnia, że silnik bazy danych weryfikuje przedziały czasu przed wstawieniem. Jeśli spróbujesz wstawić rekord, który nakłada się na istniejący okres dla tej samej jednostki, operacja nie powiedzie się, chyba że została jawnie dozwolona.
Obsługa czasu transakcji 📝
Czas ważności mówi Ci, co było prawdą. Czas transakcji mówi Ci, kiedy to wiedziałeś. Czasem musisz wiedzieć, że baza danych uznawała fakt za prawdziwy, nawet jeśli ten fakt został później wykazany jako fałszywy w świecie rzeczywistym.
Na przykład użytkownik może wpisać nieprawidłowy adres. System zapisuje go z czasem transakcji. Później użytkownik go poprawia. Jeśli śledzisz tylko czas ważności, utracisz zapis o początkowym błędzie. Jeśli śledzisz czas transakcji, zachowasz historię wprowadzania danych przez system.
Wprowadzanie czasu transakcji zwykle polega na ukrywaniu kolumn z interfejsu użytkownika. Te kolumny są zarządzane przez silnik bazy danych. Podczas zapytania stanu „obecnego” system automatycznie filtruje rekordy, dla których czas transakcji wygasł (tj. rekord został usunięty).
Wyjaśnienie modelowania bitemporalnego ⚖️
Modelowanie bitemporalne łączy czas ważności i czas transakcji. Jest to standard złota w zakresie zgodności z przepisami i analizy forensycznej danych.
Skutki dla schematu:
- Potrzebujesz czterech kolumn związanych z czasem:
od_ważności,do_ważności,od_transakcji,do_transakcji. - Twoja strategia indeksowania musi uwzględniać obie wymiary.
- Twoje zapytania stają się bardziej złożone, często wymagając łączeń zakresowych.
Przykładowa logika zapytania:
Aby znaleźć stan rekordu takim, jakim był znany w konkretnym momencie, filtrować należy po czasie transakcji. Aby znaleźć stan świata w konkretnym momencie, filtrować należy po czasie ważności. Aby znaleźć stan świata takim, jakim system go rozumiał w konkretnym momencie, filtrować należy po obu.
Taki poziom szczegółowości jest istotny dla branż takich jak finanse, medycyna i usługi prawne, gdzie pochodzenie danych jest równie ważne jak same dane.
Wyzwania związane z wdrożeniem ⚠️
Dodanie czasu do diagramu ERD wprowadza złożoność, którą należy starannie zarządzać.
1. Nadmierne zużycie pamięci
Każda zmiana tworzy nowy wiersz. Przez lata tabela może znacznie wzrosnąć w rozmiarze w porównaniu do wersji bez czasu. Musisz planować zwiększone wymagania dotyczące pamięci. Podział na zakresy czasu (np. miesięczne lub roczne) to powszechna strategia utrzymania szybkich zapytań i łatwej konserwacji.
2. Wydajność zapytań
Filtrowanie według zakresów czasu jest zazwyczaj szybkie, jeśli indeksy są poprawnie skonfigurowane. Jednak odtworzenie stanów historycznych często wymaga łączenia wielu tabel. Zapytanie, które wcześniej trwało milisekundy, może trwać sekundy, jeśli obejmuje skanowanie tabeli historii z milionami wierszy.
3. Zmiany w logice aplikacji
Istniejący kod aplikacji zakładający pojedynczy wiersz na encję przestanie działać. Musisz przepisać wszystkie operacje CRUD w taki sposób, aby obsługiwały atrybuty czasu. Operacje wstawiania stają się aktualizacjami z logiką warunkową.
4. Spójność danych
Zapewnienie, żeod_validacji jest zawsze mniejsze niżdo_validacjiwymaga ograniczeń w bazie danych. Bez tych ograniczeń istnieje ryzyko utworzenia nieprawidłowych okresów czasu, które naruszają raportowanie historyczne.
Najlepsze praktyki utrzymania 🧹
Aby utrzymać model czasowy w dobrej kondycji, postępuj zgodnie z tymi wytycznymi.
- Używaj kluczy zastępczych: Zawsze używaj wewnętrznego identyfikatora dla tabeli historii, a nie klucza biznesowego. Pozwala to na zmianę klucza biznesowego bez naruszania integralności referencyjnej.
- Indeksuj strategicznie: Utwórz złożone indeksy na (
id_encji,od_validacji). Ułatwia wyszukiwanie aktualnych rekordów i zrzutów historycznych. - Automatyzuj czyszczenie: Wprowadź zasady archiwizacji. Jeśli rekord ma 10 lat, przenieś go do tabeli przechowywania zimnego (cold storage), aby utrzymać aktywną tabelę w minimalnym rozmiarze.
- Dokumentuj przepływ czasu: Jasną dokumentacją różnicy między czasem ważności a czasem transakcji w słowniku danych. Programiści muszą wiedzieć, który znacznik czasu dotyczy ich przypadku użycia.
- Weryfikuj nakładania się: Użyj ograniczeń bazy danych, aby zapobiec nakładaniu się okresów ważności dla tej samej jednostki.
Porównanie strategii czasowych
Wybór odpowiedniego modelu zależy od Twoich konkretnych potrzeb. Poniższa tabela podsumowuje kompromisy.
| Strategia | Złożoność | Koszt przechowywania | Szybkość zapytań | Najlepsze zastosowanie |
|---|---|---|---|---|
| SCD Typ 2 | Średnia | Średnia | Wysoka | Ogólne śledzenie historii działalności |
| Tabele okresów | Wysoka | Średnia | Wysoka | Streścię zgodność z przepisami |
| Bitemporalny | Bardzo wysoka | Wysoka | Średnia | Analiza kryminalistyczna, audyt systemu |
| Źródło zdarzeń | Wysoka | Bardzo wysoka | Niska (odczyt) | Odtwarzanie stanu, strumienie czasu rzeczywistego |
Ostateczne rozważania dla architektów danych
Zintegrowanie czasu w diagramie relacji encji to decyzja, która wpływa na cykl życia Twoich danych. Nie jest to jedynie korekta techniczna; to zmiana sposobu, w jaki postrzegasz informacje.
Kiedy projektujesz z myślą o czasie, przyznajesz, że dane nie są statyczne. Przepływają. Zmieniają się. Starsze. Budując te możliwości w fundamenty swojego schematu, zabezpieczasz swoje systemy przed koniecznością analizy retrospektywnej.
Zacznij od identyfikacji, które atrybuty w Twoim systemie naprawdę wymagają historii. Nie każda kolumna musi mieć znacznik czasu. Skup się na danych o wysokiej wartości, takich jak salda finansowe, przypisania personelu i ceny produktów. Zastosuj wzorce czasowe selektywnie, aby uniknąć niepotrzebnych nakładów.
Kiedy Twój system dojrzeje, możesz odkryć, że początkowy projekt wymaga doskonalenia. Modele danych czasowych są iteracyjne. Monitoruj wydajność zapytań i wzrost zużycia pamięci. Dostosuj strategie podziału i indeksowania wraz z rosnącą objętością danych historycznych.
Na końcu, ERD z uwzględnieniem czasu zapewnia jednoznaczny źródło prawdy, które szanuje przeszłość, jednocześnie spełniając potrzeby obecne. Gwarantuje, że gdy pojawią się pytania o „dlaczego” coś się wydarzyło, odpowiedź już znajduje się w Twojej bazie danych, czekając na pobranie.