











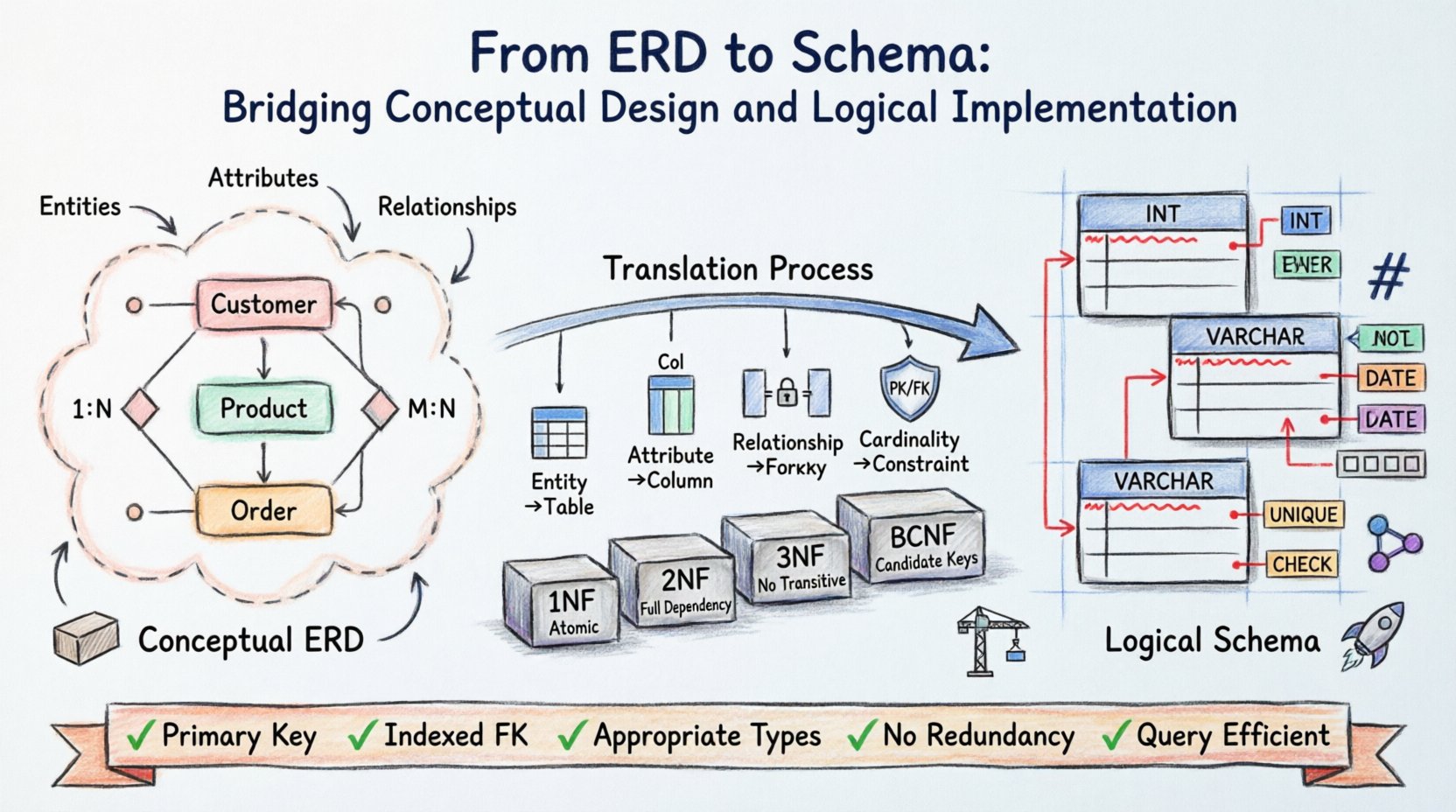
Architektura bazy danych zaczyna się od wizji. Zanim zostanie napisany pierwszy wiersz kodu, struktury danych muszą zostać ujęte koncepcyjnie, uporządkowane i zwalidowane. Diagram związków encji (ERD) pełni rolę projektu tej struktury, przekładając wymagania rzeczywistego świata na model wizualny. Jednak sam diagram nie przechowuje danych. Schemat logiczny to rzeczywista implementacja, która określa sposób fizycznego przechowywania, pobierania i zabezpieczania informacji.
Przejście od abstrakcyjnego ERD do konkretnego schematu wymaga precyzji. Obejmuje ono przyporządkowanie encji do tabel, relacji do kluczy oraz atrybutów do kolumn. Ten proces decyduje o integralności i wydajności całego systemu. Zrozumienie subtelności tej transformacji zapewnia, że baza danych pozostanie wytrzymała pod obciążeniem i elastyczna wobec przyszłych potrzeb.
Zrozumienie podstaw koncepcyjnych 🧱
Diagram związków encji działa na poziomie koncepcyjnym. Skupia się na „co”, a nie na „jak”. W tej fazie inwestorzy i architekci identyfikują kluczowe obiekty interesujące w zakresie domeny.
- Encje: Odnoszą się do różnych obiektów lub pojęć, takich jak Klient, Produkt lub Zamówienie.
- Atrybuty: Określają właściwości encji, takie jak Imię, Cena lub Data.
- Związki: Opisują sposób wzajemnego oddziaływania encji, np. Klient składający Zamówienie.
Na tym etapie ograniczenia techniczne są wtórne. Celem jest jasność. Jeśli model koncepcyjny jest niejasny, to powstały schemat będzie błędny. Powszechne błędy obejmują łączenie atrybutów z encjami lub nieprawidłowe określanie liczności.
Liczność i uczestnictwo
Jednym z najważniejszych aspektów projektowania ERD jest określenie liczności. Decyduje ono o ilościowym związku między encjami.
- Jeden do jednego (1:1): Jeden rekord w Tabeli A jest powiązany dokładnie z jednym rekordem w Tabeli B.
- Jeden do wielu (1:N): Jeden rekord w Tabeli A jest powiązany z wieloma rekordami w Tabeli B.
- Wiele do wielu (M:N): Wiele rekordów w Tabeli A jest powiązanych z wieloma rekordami w Tabeli B.
Ograniczenia uczestnictwa dalsze dopasowują ten model. Czy relacja jest obowiązkowa czy opcjonalna? Jeśli Klient musi złożyć Zamówienie, uczestnictwo jest obowiązkowe. Jeśli może istnieć bez Zamówienia, jest opcjonalne. Te różnice bezpośrednio wpływają na możliwość ustawienia wartości NULL w kolumnach schematu logicznego.
Schemat logiczny: implementacja strukturalna 🏗️
Schemat logiczny mostuje luki między teorią a fizycznym przechowywaniem danych. Choć ERD jest niezależny od platformy, schemat logiczny przygotowuje dane do konkretnych mechanizmów przechowywania. Ten warstwa wprowadza konkretne zasady dotyczące typów danych, ograniczeń i normalizacji.
W przeciwieństwie do modelu koncepcyjnego, schemat logiczny musi jawnie rozwiązywać kwestie integralności danych. Jest to osiągane poprzez klucze główne, klucze obce oraz ograniczenia unikalności. Te zasady zapobiegają powstawaniu zaniedbanych rekordów i zapewniają spójność relacji.
Zasady przekładania kluczy
Przekładanie kluczy z ERD do schematu wymaga ścisłego przestrzegania teorii relacyjnej.
- Klucze główne: Każda encja musi mieć unikalny identyfikator. W ERD często jest podkreślony. W schemacie staje się ograniczeniem PRIMARY KEY.
- Klucze obce: Relacje są realizowane za pomocą kluczy obcych. Relacja wiele do wielu zwykle wymaga tabeli pośredniej z dwoma kluczami obcymi w celu rozwiązania liczności.
- Klucze złożone: Jeśli encja opiera się na wielu atrybutach w celu unikalności, muszą one zostać połączone w definicji logicznej.
Mapowanie encji na tabele 🔄
Proces konwersji encji na tabelę jest prosty, ale wymaga dokładności. Każda encja zazwyczaj odpowiada jednej tabeli. Jednak złożone scenariusze mogą wymagać podziału lub łączenia.
Obsługa specjalizacji i generalizacji
Gdy encje dzielą wspólne atrybuty, mogą one być modelowane jako podklasy. Na przykład encjaVehicle może mieć podklasy takie jakCar iTruck.
Istnieją dwa główne podejścia do implementacji tego w schemacie:
- Dziedziczenie jednej tabeli: Wszystkie podklasy są przechowywane w jednej tabeli z kolumną rozróżnieniową. Zmniejsza to liczba połączeń, ale zwiększa liczbę wartości NULL.
- Dziedziczenie tabel klas: Każda podklasa otrzymuje własną tabelę połączoną z rodzicem za pomocą klucza obcego. Jest to bardziej znormalizowane, ale wymaga bardziej złożonych zapytań.
Mapowanie atrybutów
Atrybuty z ERD muszą zostać przypisane do definicji kolumn. Nie wszystkie atrybuty są bezpośrednio przekładane.
- Proste atrybuty: Są bezpośrednio mapowane na kolumny.
- Złożone atrybuty: Muszą zostać rozłożone na osobne kolumny (na przykład Adres dzieli się na Ulica, Miasto, Kod pocztowy).
- Atrybuty wielowartościowe: Nie mogą być przechowywane w jednej kolumnie. Wymagają osobnej tabeli połączonej kluczem obcym (na przykład numery telefonów dla użytkownika).
- Atrybuty pochodne: Są obliczane na podstawie innych danych (na przykład wiek z daty urodzenia). Często są pomijane w schemacie, aby uniknąć nadmiaru, chyba że optymalizacja wydajności jest krytyczna.
Głęboka analiza normalizacji 📊
Normalizacja to proces organizowania danych w celu zmniejszenia nadmiarowości i poprawy integralności. Przechodząc od ERD do schematu, projektanci muszą zapewnić, że model spełnia określone formy normalne.
Pierwsza forma normalna (1NF)
Tabela jest w 1NF, jeśli zawiera wartości atomowe. Żaden kolumna nie powinna zawierać listy lub zestawu wartości. Jeśli encja ma wiele wartości dla jednego atrybutu, należy utworzyć nową tabelę.
Drugą postać normalną (2NF)
2NF wymaga, aby tabela była w 1NF i nie miała częściowych zależności. Wszystkie atrybuty niekluczowe muszą zależeć od całego klucza podstawowego, a nie tylko od jego części. Jest to kluczowe dla tabel z kluczami złożonymi.
Trzecią postać normalną (3NF)
3NF wymaga, aby nie było zależności przechodnich. Atrybut niekluczowy nie powinien zależeć od innego atrybutu niekluczowego. Na przykład, jeśli Miasto zależy od Kod pocztowy, a Kod pocztowy zależy od ID klienta, Miasto powinien zostać przeniesiony do osobnej tabeli.
Postać normalna Boyce’a-Codda (BCNF)
BCNF to bardziej rygorystyczna wersja 3NF. Obsługuje przypadki, gdy tabela ma wiele kluczy kandydujących, a atrybut niekluczowy zależy od podzbioru tych kluczy.
| Postać normalna | Wymóg | Skupienie |
|---|---|---|
| 1NF | Wartości atomowe | Usunięcie powtarzających się grup |
| 2NF | Pełna zależność | Usunięcie częściowych zależności |
| 3NF | Brak zależności przechodnich | Usunięcie pośrednich zależności |
| BCNF | Zależność klucza kandydującego | Usunięcie nakładających się kluczy |
Typy danych i ograniczenia 🔒
Wybór odpowiedniego typu danych jest kluczowy dla efektywności przechowywania i wydajności zapytań. Diagram ER rzadko określa dokładne typy danych, pozostawiając to etapowi projektowania logicznego.
Liczba całkowita vs. Liczba dziesiętna
Liczby całkowite przechowują liczby całkowite i są szybsze przy obliczeniach. Typy liczbowe lub dziesiętne stosuje się do danych finansowych w celu zachowania dokładności. Używanie liczb całkowitych do walut może prowadzić do błędów zaokrąglenia.
Data i czas
Znaczniki czasu powinny rozróżniać czas UTC i lokalny. Przechowywanie dat jako ciągów znaków to częsty błąd, który uniemożliwia skuteczne sortowanie i filtrowanie. Używaj standardowych typów dat zapewniających silnik bazy danych.
Ograniczenia
Ograniczenia zapewniają stosowanie reguł biznesowych na poziomie bazy danych.
- NOT NULL: Zapewnia, że kolumna zawsze zawiera wartość.
- UNIQUE: Zapobiega powtarzaniu się wartości w kolumnie.
- CHECK: Weryfikuje dane względem określonego warunku (np. Wiek > 0).
- DEFAULT: Dostarcza wartości domyślnej, jeśli żadna inna nie została podana.
Typowe pułapki i weryfikacja ⚠️
Nawet przy solidnym planie mogą pojawić się błędy podczas wdrażania. Wczesne rozpoznanie tych pułapek oszczędza znaczną ilość czasu w przyszłości.
- Zbyt duża normalizacja: Tworzenie zbyt wielu tabel może spowodować spowolnienie i skomplikowanie zapytań. Dla obciążeń o dużej liczbie odczytów może być konieczne zredukowanie normalizacji.
- Słabe klucze: Używanie kluczy naturalnych (np. adresów e-mail) jako kluczy głównych jest ryzykowne. Mogą one ulec zmianie i powodować problemy łańcuchowe. Klucze zastępcze (ID z automatycznym inkrementowaniem) są często bezpieczniejsze.
- Brakujące indeksy: Klucze obce powinny być indeksowane. Bez nich łączenie tabel staje się węzłem zatyczki wydajności.
- Zależności cykliczne: Zapewnienie, że tabele nie tworzą pętli w relacjach, jest kluczowe dla utrzymania integralności referencyjnej.
Lista weryfikacji
Zanim zakończysz projektowanie schematu, przejdź przez tę listę weryfikacji:
- Czy każda tabela ma klucz główny?
- Czy wszystkie klucze obce są odpowiednio indeksowane?
- Czy typy danych są odpowiednie dla oczekiwanej objętości danych?
- Czy istnieją nadmiarowe kolumny, które można usunąć?
- Czy schemat wspiera wymagane zapytania efektywnie?
Względy dotyczące wydajności 🚀
Schemat logiczny nie dotyczy tylko poprawności; ma również znaczenie dla szybkości działania. Wraz ze wzrostem danych struktura musi radzić sobie z rosnącym obciążeniem.
Partycjonowanie
Duże tabele mogą być podzielone na mniejsze, łatwiejsze w obsłudze fragmenty. Można to zrobić poziomo (wg wierszy) lub pionowo (wg kolumn). Partycjonowanie pozwala zapytaniom uzyskiwać dostęp tylko do odpowiednich fragmentów danych.
Wzorce architektoniczne
Wzorce projektowe, takie jak sharding, rozprowadzają dane na wielu serwerach. Wymaga to dokładnego planowania w fazie projektowania logicznego, aby zapewnić, że powiązane dane pozostają razem tam, gdzie to możliwe.
Podsumowanie najlepszych praktyk ✅
Tworzenie schematu bazy danych to proces iteracyjny. Wymaga on równowagi między czystością teoretyczną a ograniczeniami praktycznymi.
- Dokumentuj wszystko:Utrzymuj jasną dokumentację łączącą elementy ERD z definicjami schematu.
- Kontrola wersji:Traktuj zmiany schematu jak kod. Używaj skryptów migracji do śledzenia zmian w czasie.
- Regularnie przeglądaj:Wraz z rozwojem potrzeb biznesowych, powinien zmieniać się również schemat. Zaprojektuj okresowe audyty, aby zapewnić zgodność z aktualnymi wymaganiami.
- Współpracuj:Zaangażuj deweloperów, analityków i stakeholderów na wczesnym etapie. Różne perspektywy ujawniają przypadki graniczne, które jeden projektant mógłby pominąć.
Przejście od diagramu encji-związków do schematu logicznego jest fundamentem inżynierii danych. Przekształca abstrakcyjne pomysły w funkcjonalny system. Przestrzegając zasad normalizacji, wybierając odpowiednie typy danych oraz przewidując potrzeby wydajności, otrzymamy bazę danych, która będzie niezawodnym fundamentem dla aplikacji.
Na końcu jakość schematu decyduje o długości życia systemu. Dobrze zaprojektowana struktura minimalizuje dług techniczny i ułatwia przyszły rozwój. Skup się na przejrzystości, integralności i skalowalności, aby tworzyć systemy, które wytrzymają próbę czasu.