











Na arquitetura intrincada do design de banco de dados, poucos conceitos desafiam os engenheiros tanto quanto a entidade auto-referenciada. Também conhecida como relacionamento recursivo, esse padrão permite que uma tabela se ligue a si mesma, possibilitando a modelagem de hierarquias e estruturas complexas dentro de um esquema plano. Compreender como implementar isso corretamente é crucial para manter a integridade dos dados e o desempenho das consultas.
Ao projetar um Diagrama de Relacionamento de Entidades (ERD), a maioria dos relacionamentos conecta duas entidades distintas. No entanto, dados do mundo real frequentemente exigem que uma única entidade se relacione com seu próprio tipo. Um gerente gerencia funcionários, uma categoria contém subcategorias e um produto pode fazer parte de um kit. Esses cenários exigem um relacionamento recursivo.
Este guia explora a mecânica, padrões de design e melhores práticas para lidar com entidades auto-referenciadas. Analisaremos como estruturar esses relacionamentos sem depender de ferramentas específicas, focando em princípios universais de banco de dados.
🧐 O que é uma Entidade Auto-Referenciada?
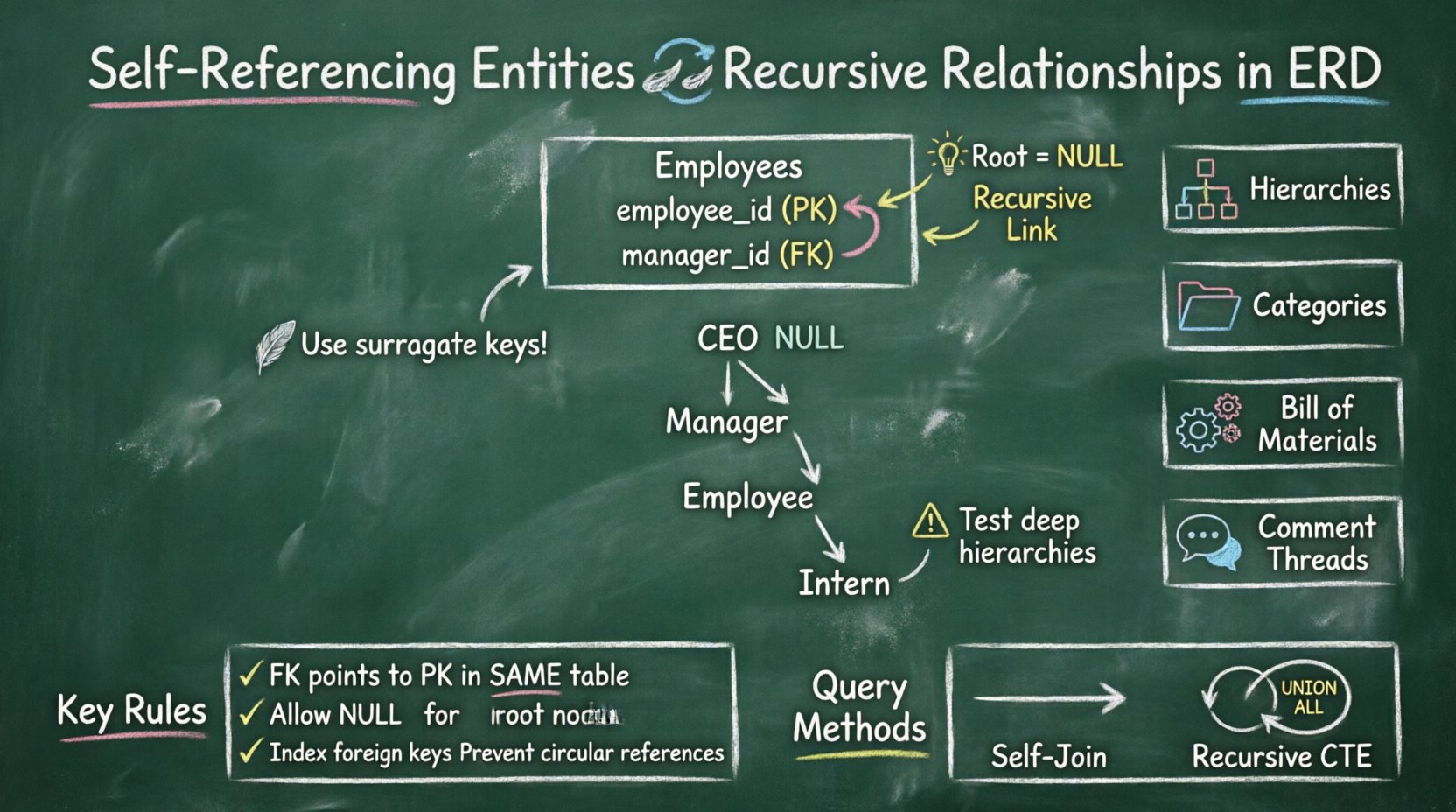
Uma entidade auto-referenciada ocorre quando uma chave estrangeira em uma tabela aponta para a chave primária da mesma tabela. Isso cria um loop em que linhas de dados dentro de uma única tabela podem referenciar outras linhas dentro dessa mesma tabela. É uma técnica fundamental para modelar estruturas de dados hierárquicas.
Características Principais:
- Tabela Única: O relacionamento existe inteiramente dentro de uma estrutura de tabela.
- Link Pai-Filho: Uma linha atua como pai, enquanto outra atua como filho.
- Tratamento de Valores Nulos: A raiz da hierarquia geralmente possui um valor nulo na coluna da chave estrangeira.
- Lógica Circular: Deve-se ter cuidado para evitar loops infinitos durante a recuperação de dados.
🏗️ Componentes Principais dos Relacionamentos Recursivos
Para implementar esse relacionamento de forma eficaz, componentes específicos do banco de dados devem estar alinhados. O design do esquema depende fortemente da interação entre chaves primárias e chaves estrangeiras.
🔑 A Chave Primária
Cada linha na tabela deve ter um identificador exclusivo. Este é o ponto de ancoragem. Quando uma linha referencia outra linha, faz isso armazenando o identificador exclusivo da linha pai.
- Deve ser estável. Alterar uma chave primária é uma operação complexa.
- Deve ser indexada para desempenho rápido de busca.
- Comumente, trata-se de um inteiro auto-incrementado ou um UUID.
🔗 A Chave Estrangeira
A coluna da chave estrangeira reside na mesma tabela que a chave primária. Ela armazena o valor da chave primária da linha pai. Essa coluna define a direção do relacionamento.
- Pode ser Nulo:Em uma hierarquia, o item de nível superior (a raiz) não possui pai. Portanto, esta coluna deve permitir valores nulos.
- Restrição: Uma restrição de chave estrangeira garante que o valor armazenado corresponda a uma chave primária existente na mesma tabela.
- Indexação: Embora nem sempre seja obrigatório, indexar a coluna da chave estrangeira acelera significativamente as consultas que percorrem a hierarquia.
📐 Visualização em um Diagrama de Relacionamento de Entidades
Ao desenhar um DER para representar uma entidade auto-referenciada, a notação pode ser confusa à primeira vista. Ferramentas padrão de DER usam linhas específicas para indicar a conexão.
Regras de Notação Visual:
- A caixa da entidade é desenhada apenas uma vez.
- Uma linha de relacionamento conecta a chave primária à chave estrangeira dentro da mesma caixa.
- A linha geralmente retorna à entidade, criando um círculo visual.
- Marcadores de cardinalidade (1:1, 1:M) são colocados na linha para indicar quantos filhos um pai pode ter.
Exemplo: Estrutura Organizacional
| Conceito | Descrição | Notação DER |
|---|---|---|
| Funcionário | A entidade sendo modelada | Caixa rotulada como “Funcionário” |
| Gerente | O papel que faz referência à mesma tabela | Linha do ID do Gerente para o ID do Funcionário |
| Linha de Relatório | A relação recursiva | Seta em laço |
| Nó Raiz | CEO ou chefe de nível superior | Valor nulo no ID do Gerente |
🌳 Casos de Uso Comuns para Dados Recursivos
Relações recursivas não são teóricas; elas resolvem problemas concretos na modelagem de dados. Aqui estão os cenários mais frequentes em que este padrão é aplicado.
1️⃣ Hierarquias Organizacionais
Toda empresa tem uma estrutura. Funcionários relatam a gerentes, que relatam a diretores, que relatam a vice-presidentes. Essa cadeia é uma estrutura de árvore clássica.
- Modelo de Dados: Uma tabela chamada “Funcionários”.
- Colunas:
id_funcionario,nome,id_gerente. - Lógica: O
id_gerentecoluna referenciaid_funcionario. - Benefício: Adicionar um novo funcionário requer apenas inserir uma linha. Não é necessário criar uma nova tabela para cada departamento.
2️⃣ Árvores de Categoria
Plataformas de e-commerce geralmente organizam produtos em categorias aninhadas. Eletrônicos > Computadores > Notebooks.
- Modelo de Dados: Uma tabela chamada “Categorias”.
- Colunas:
id_categoria,nome,id_pai. - Lógica: Uma categoria pode ter um pai, ou pode ser uma categoria raiz (id_pai é nulo).
- Benefício: Flexibilidade para adicionar quantas subcategorias forem necessárias sem alterar o esquema.
3️⃣ Lista de Materiais (BOM)
A fabricação frequentemente exige listas complexas de peças. Um carro é feito de motores, que são feitos de pistões. Às vezes, um pistão faz parte de um tipo de motor diferente.
- Modelo de Dados: Uma tabela chamada “Peças”.
- Colunas:
id_peca,descrição,id_ensamblagem. - Lógica: Uma peça pode ser um ensamblagem por si só, contendo outras peças.
- Benefício: Permite estruturas de fabricação em múltiplos níveis.
4️⃣ Fóruns de Comentários
Fóruns e blogs permitem que os usuários respondam a comentários. Um comentário pode ter um comentário pai ao qual está respondendo, ou pode ser um comentário independente.
- Modelo de Dados: Uma tabela chamada “Comentários”.
- Colunas:
id_comentario,id_usuario,conteúdo,id_comentario_pai. - Lógica: Uma resposta faz referência de volta ao ID do comentário original.
- Benefício: Suporta aninhamento infinito de discussões.
⚙️ Considerações de Implementação
Projetar o esquema é apenas o primeiro passo. Garantir que os dados se comportem corretamente sob diversas condições exige planejamento cuidadoso.
🛑 Prevenção de Referências Circulares
Um risco crítico em relacionamentos recursivos é criar um ciclo. Por exemplo, o Funcionário A gerencia o Funcionário B, e o Funcionário B gerencia o Funcionário A. Isso cria um loop infinito.
- Lógica do Aplicativo: Ao inserir ou atualizar dados, o aplicativo deve verificar a profundidade da hierarquia para garantir que nenhum ciclo seja formado.
- Restrições do Banco de Dados: Embora as restrições padrão do SQL não possam facilmente prevenir ciclos (pois verificam o estado atual, não o estado resultante), gatilhos podem ser usados em alguns sistemas para validar o caminho antes da gravação.
- Identificação da Raiz: Certifique-se de que cada árvore válida tenha exatamente um nó raiz (onde a chave estrangeira é nula).
📉 Tratamento de Valores Nulos
A raiz da hierarquia é o ponto de partida. Em um relacionamento recursivo padrão, a linha raiz tem um valor nulo na coluna da chave estrangeira.
- Consulta: Para encontrar todos os nós raiz, consulte as linhas onde a chave estrangeira é NULA.
- Valores Padrão: Não defina um valor padrão para a chave estrangeira se isso implicar um pai. Um valor padrão de 0 ou -1 pode ser enganoso e causar problemas de integridade de dados.
- Integridade: Certifique-se de que o motor do banco de dados permita valores NULOS na coluna da chave estrangeira. Uma restrição NOT NULL quebra o modelo de hierarquia.
📈 Desempenho e Indexação
À medida que os dados crescem, as consultas em estruturas recursivas podem ficar lentas. Uma consulta simples para encontrar todos os descendentes de um nó específico pode exigir muitos joins ou consultas recursivas.
Estratégias de Otimização:
- Indexar Chaves Estrangeiras: Crie um índice na coluna que armazena a referência ao pai. Isso acelera a busca por filhos.
- Caminhos Materializados: Alguns sistemas armazenam o caminho completo da hierarquia em uma coluna separada (por exemplo, “/1/5/12/20”). Isso permite uma filtragem mais rápida baseada em strings, embora exija atualizações em cada inserção.
- Conjuntos Aninhados: Um algoritmo alternativo que usa números esquerdo e direito para representar a profundidade. É mais rápido para recuperação, mas mais lento para inserção.
- Profundidade da Consulta: Limite a profundidade da recursão nas suas consultas. Loops infinitos podem fazer o motor do banco de dados travar se não forem limitados.
🔍 Consultando dados recursivos
Recuperar dados hierárquicos é mais complexo do que recuperar dados planos. JOINs padrão funcionam para um nível, mas múltiplos níveis exigem lógica especializada.
🔄 Autojunções
O método mais comum envolve juntar a tabela a si mesma. Você aplica um alias à tabela uma vez como pai e outra vez como filho.
- Um Nível:Junte a tabela a si mesma uma vez para obter o pai imediato.
- Múltiplos Níveis:Exige múltiplas junções, o que se torna desajeitado rapidamente.
- Desvantagem:O número de junções necessárias é igual à profundidade da hierarquia.
🔁 Expressões de Tabela Comum Recursivas (CTEs)
Bancos de dados modernos suportam CTEs recursivas. Isso permite que uma consulta execute um UNION ALL contra si mesma até que não haja mais linhas encontradas.
- Membro âncora: O ponto de partida da recursão (geralmente o nó raiz).
- Membro recursivo: A parte da consulta que junta o resultado de volta à tabela para encontrar o próximo nível.
- Terminação: A consulta para quando não são encontradas mais linhas correspondentes.
- Benefício: Manipula qualquer profundidade de hierarquia sem precisar conhecê-la antecipadamente.
🛡️ Integridade de dados e restrições
Manter a integridade de uma tabela auto-referenciada é vital. Se um pai for excluído, o que acontece com os filhos?
🗑️ Cascata de exclusão
Quando uma linha pai é removida, o banco de dados deve decidir como lidar com as linhas filhas.
- RESTRICT: Impede a exclusão do pai se filhos existirem. Isso preserva os dados, mas pode bloquear a limpeza necessária.
- CASCADE: Exclui todas as linhas filhas quando o pai é excluído. Isso é perigoso em hierarquias profundas, pois pode apagar grandes partes de dados acidentalmente.
- SET NULL: Define a chave estrangeira das linhas filhas como NULL, tornando-as novos nós raiz. Essa é geralmente a opção mais segura para preservar a estrutura dos dados.
- DEFINIR PADRÃO: Define a chave estrangeira para um valor padrão (por exemplo, uma categoria específica órfã).
🔒 Restrições de Atualização
Alterar a chave primária de uma linha pai é arriscado. Se você alterar o ID de um gerente, deve atualizar esse ID em todos os registros de funcionários que fazem referência a eles.
- Camada de Aplicação:Trate a atualização de forma transacional para garantir que todas as referências sejam atualizadas juntas.
- Gatilhos do Banco de Dados:Pode automatizar a propagação das alterações de ID, embora isso aumente a complexidade.
- Melhor Prática:Evite atualizar chaves primárias em estruturas recursivas sempre que possível. Use chaves surrogate (inteiros autoincrementáveis) em vez de chaves naturais (como códigos de funcionários).
🚧 Solução de Problemas Comuns
Mesmo com um projeto cuidadoso, problemas podem surgir durante o desenvolvimento e a manutenção.
❓ Como descubro a profundidade de uma árvore?
Para determinar o nível de uma linha específica, você deve percorrer da linha até a raiz. Conte o número de saltos.
- Abordagem de Consulta:Use uma consulta recursiva que conta as linhas enquanto avança para cima.
- Abordagem de Aplicação:Armazene a profundidade em uma coluna durante a inserção. Isso economiza tempo de consulta, mas exige manutenção.
❓ Como lidar com nós órfãos?
Nós órfãos são linhas onde a chave estrangeira aponta para um pai inexistente. Isso geralmente acontece devido a erros de programação ou erros de entrada manual de dados.
- Validação:Execute verificações periódicas de integridade para encontrar linhas onde a chave estrangeira não corresponde a nenhuma chave primária.
- Recuperação:Decida uma política: mova-os para uma categoria raiz, exclua-os ou marque-os para revisão.
❓ Degradação de desempenho com o tempo
À medida que a árvore cresce, as consultas que varrem toda a árvore ficam mais lentas.
- Armazenamento em Cache:Armazene em cache estruturas de hierarquia frequentemente acessadas na memória da aplicação.
- Arquivamento:Mova partes históricas ou inativas da hierarquia para tabelas de arquivamento.
- Particionamento: Se os dados forem massivos, particione a tabela pela categoria raiz.
📝 Resumo das Melhores Práticas
Para garantir uma implementação robusta de entidades auto-referenciadas, siga estas diretrizes.
- Use Chaves de Substituição:Prefira inteiros autoincrementais em vez de chaves de negócios para a chave primária.
- Permita Valores Nulos:Garanta que a coluna da chave estrangeira permita valores nulos para os nós raiz.
- Indexe Chaves Estrangeiras:Sempre indexe a coluna que contém a referência ao pai.
- Valide Ciclos:Implemente verificações para evitar referências circulares (A -> B -> A).
- Limite a Recursão:Limite a profundidade da recursão nas consultas para evitar estouros de pilha.
- Documente o Esquema:Marque claramente quais colunas são auto-referenciadas na sua documentação de ERD.
- Planeje a Exclusão:Defina regras claras para exclusões em cascata ou definição de nulos na remoção do pai.
- Teste Hierarquias Profundas:Teste suas consultas com pelo menos 10 níveis de profundidade para garantir que o desempenho se mantenha.
🔮 Considerações Futuras
A tecnologia de banco de dados continua evoluindo. Embora o conceito de uma entidade auto-referenciada permaneça constante, as ferramentas para gerenciá-la estão melhorando.
- Bancos de Dados de Grafos: Alguns sistemas modernos tratam relacionamentos como cidadãos de primeira classe. Eles lidam com caminhos recursivos nativamente, sem a complexidade do SQL.
- Suporte a JSON: Motores de banco de dados mais novos permitem armazenar dados hierárquicos em colunas JSON, o que pode simplificar o design do esquema para estruturas profundamente aninhadas.
- Melhorias em ORMs:Mapeadores Objeto-Relacional estão ficando melhores em lidar com relacionamentos recursivos automaticamente, reduzindo o código boilerplate.
Apesar desses avanços, a lógica central da relação recursiva permanece a mesma. Compreender os mecanismos subjacentes de chaves primárias, chaves estrangeiras e relacionamentos entre tabelas é essencial para qualquer profissional técnico que trabalhe com estruturas de dados.
Ao seguir esses princípios, você pode construir sistemas flexíveis o suficiente para lidar com hierarquias complexas, mantendo-se eficientes e mantíveis. A entidade auto-referenciada é uma ferramenta poderosa em seu arsenal de modelagem de dados, desde que seja usada com precisão e cuidado.