











No cenário da arquitetura de dados, poucos conceitos geram mais confusão do que o relacionamento muitos para muitos. Ao projetar um Diagrama Entidade-Relacionamento (ERD), encontrar uma situação em que uma entidade se conecta a múltiplas instâncias de outra, e vice-versa, exige uma abordagem estrutural específica. Sistemas gerenciadores de bancos de dados relacionais não suportam nativamente associações diretas muitos para muitos. Eles exigem uma estrutura intermediária para manter a integridade dos dados e garantir consultas eficientes. Este guia explora os métodos autoritativos para resolver essas associações, assegurando que seu modelo de dados permaneça robusto, escalonável e normalizado.
Independentemente de você estar projetando um sistema para registros acadêmicos, gestão de estoque ou permissões de usuários, os princípios para resolver essas cardinalidades permanecem constantes. Compreender os mecanismos subjacentes evita anomalias futuras e simplifica a manutenção. Vamos além das definições superficiais para examinar os requisitos estruturais, regras de normalização e estratégias de implementação que definem a modelagem profissional de dados.
🔍 Compreendendo a Cardinalidade em ERDs
A cardinalidade define a relação numérica entre entidades em um banco de dados. Ela especifica o número de instâncias de uma entidade que podem ou devem estar associadas a cada instância de outra entidade. Na notação de ERD, isso é frequentemente representado por linhas que conectam entidades, com os pés de corvo indicando o lado “muitos” e linhas retas ou marcas simples indicando o lado “um”.
Existem três cardinalidades principais:
- Um para Um (1:1): Um único registro na Entidade A está relacionado a um único registro na Entidade B. Exemplo: Uma pessoa e sua passaporte.
- Um para Muitos (1:M): Um único registro na Entidade A está relacionado a múltiplos registros na Entidade B. Exemplo: Um cliente fazendo múltiplos pedidos.
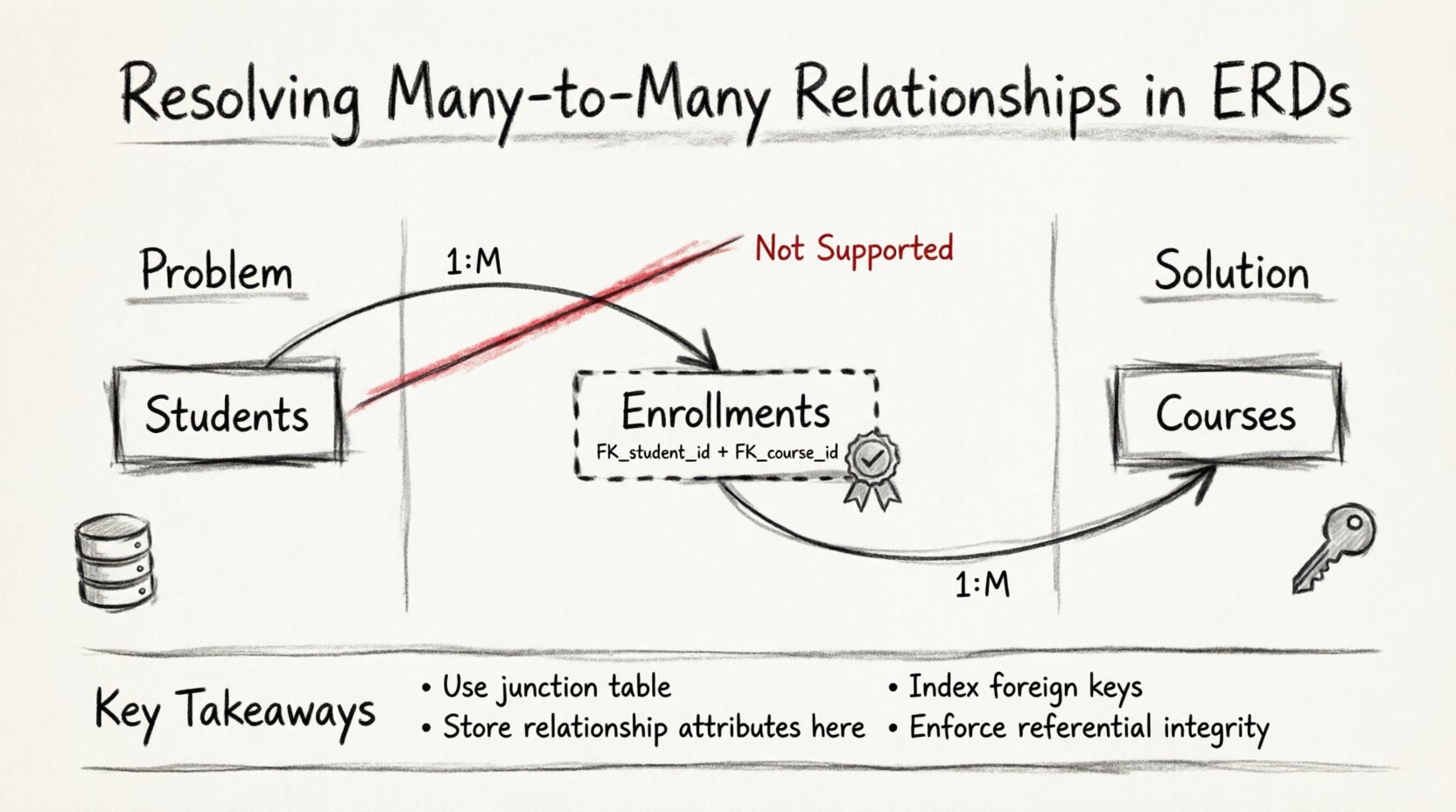
- Muitos para Muitos (M:N): Múltiplos registros na Entidade A estão relacionados a múltiplos registros na Entidade B. Exemplo: Alunos matriculados em múltias disciplinas, e disciplinas contendo múltiplos alunos.
Embora os relacionamentos 1:1 e 1:M sejam simples de implementar em um esquema físico de banco de dados, o relacionamento M:N apresenta um desafio único. A teoria relacional determina que uma célula de tabela deve conter apenas valores atômicos. Uma ligação direta entre duas tabelas onde uma única linha na Tabela A poderia teoricamente referenciar múltiplas linhas na Tabela B viola esse princípio na camada física.
🚫 Por que os Relacionamentos Diretos M:M Falham nos Modelos Relacionais
O modelo relacional, estabelecido por E.F. Codd, baseia-se no conceito de relações (tabelas) em que cada coluna representa um atributo específico e cada linha representa uma instância única. Existem duas razões principais pelas quais uma ligação muitos para muitos direta é impossível em um banco de dados relacional padrão:
- Falta de Suporte Nativo:Sistemas de gerenciamento de banco de dados não permitem que uma coluna de chave estrangeira contenha múltiplos valores. Uma chave estrangeira deve apontar para uma única chave primária em outra tabela. Ela não pode apontar para uma lista de chaves.
- Anomalias de Inserção e Exclusão:Se você tentar armazenar múltiplos IDs em uma única célula (por exemplo, “Student_ID: 101, 102, 103”), você cria uma violação da Primeira Forma Normal (1FN). Isso torna as consultas, atualizações e exclusões de relacionamentos específicos computacionalmente custosas e propensas a erros.
Consequentemente, para armazenar esses dados de forma eficiente, a própria relação deve ser tratada como uma entidade. Essa transformação é a técnica fundamental para resolver a complexidade.
🧱 Técnica 1: A Entidade Associativa (Tabela de Junção)
A solução padrão para resolver um relacionamento muitos para muitos é a criação de uma entidade associativa, comumente conhecida como tabela de junção ou tabela-ponte. Essa tabela está fisicamente entre as duas entidades principais e transforma a conexão direta em duas relações um para muitos.
Quando você introduz uma tabela de junção, a relação M:N original é decomposta em:
- Uma relação um para muitos entre a Entidade A e a Tabela de Junção.
- Uma relação um para muitos entre a Entidade B e a Tabela de Junção.
Estrutura de uma Tabela de Junção:
- Chaves Estrangeiras:Ela deve conter pelo menos duas colunas de chave estrangeira. Uma referencia a chave primária da Entidade A, e a outra referencia a chave primária da Entidade B.
- Chave Primária Composta:Freqüentemente, a combinação dessas duas chaves estrangeiras serve como chave primária para a tabela de junção. Isso garante que um par específico de entidades não possa ser vinculado mais de uma vez, a menos que a relação seja intrinsecamente multivalorada.
- Chaves de substituição:Em alguns casos, um ID único e autoincrementado é adicionado à tabela de junção. Isso é útil se a relação puder ter múltiplas instâncias com atributos diferentes (por exemplo, um aluno pode estar matriculado em um curso várias vezes com notas diferentes em anos diferentes).
Cenário de exemplo:
Considere um sistema de biblioteca. Um Livro pode ser emprestado por muitos Usuários. Um Usuário pode emprestar muitos Livros.
- Sem resolução: você não pode vincular diretamente uma linha de livro a múltiplas linhas de usuário.
- Com resolução: crie uma Registro_de_Emprestimo tabela.
- O Registro_de_Emprestimo contém
ID_LivroeID_Usuario.
Essa estrutura permite que o banco de dados rastreie exatamente qual usuário tem qual livro em qualquer momento, sem duplicar dados de livro ou usuário.
📝 Técnica 2: Manipulando atributos nas relações
Uma distinção crítica na modelagem de ERD é se a relação entre entidades carrega seus próprios dados. Em uma ligação simples, a conexão existe ou não existe. No entanto, em muitos cenários do mundo real, a própria relação possui propriedades.
Por exemplo, em um Projeto e Funcionário cenário, um funcionário pode trabalhar em múltiplos projetos, e um projeto tem múltiplos funcionários. Mas a relação pode incluir:
- Cargo: O funcionário é desenvolvedor, designer ou gerente neste projeto específico?
- Horas Alocadas: Quantas horas por semana são atribuídas a este projeto?
- Data de Início: Quando começou esta atribuição?
Se você tratar a relação meramente como uma bandeira binária, perderá esses dados essenciais. A tabela de junção torna-se o local perfeito para armazenar esses atributos.
Regras de Implementação:
- Não armazene atributos de relacionamento nas entidades pais. Eles não pertencem apenas ao Projeto, nem apenas ao Funcionário.
- Coloque todos os dados específicos do relacionamento na tabela de junção.
- Garanta que a tabela de junção tenha um identificador exclusivo (composto ou fictício) para permitir atualizações desses atributos sem afetar as entidades pais.
Esta abordagem garante a normalização de dados. Se você adicionasse um Cargo coluna na tabela de Funcionário tabela, criaria redundância se o funcionário tivesse múltiplos cargos em projetos diferentes. A tabela de junção isola essa variação.
⚖️ Técnica 3: Normalização e Integridade de Dados
Resolver relacionamentos M:N não é apenas sobre vincular tabelas; é sobre seguir princípios de normalização para prevenir anomalias de dados. A Terceira Forma Normal (3NF) é o objetivo padrão para a maioria dos sistemas transacionais.
Requisitos da Terceira Forma Normal (3NF):
- A tabela deve estar na Segunda Forma Normal (2NF).
- Todos os atributos não-chave devem depender apenas da chave primária.
Ao criar uma tabela de junção, você garante que os dados do relacionamento dependam da chave composta da tabela de junção, e não das chaves individuais das entidades. Isso elimina as dependências transitivas.
Integridade Referencial:
Restrições de chave estrangeira são essenciais na tabela de junção. Elas impõem as seguintes regras:
- Um
ID_Livrono registro de empréstimos deve existir na tabela de Livros tabela. - Um
ID_Patronono registro de empréstimos deve existir na tabela Patronos tabela.
Isso evita registros órfãos. Você não pode registrar um evento de empréstimo para um livro que não existe no catálogo. Motores de banco de dados impõem isso por meio de ações de CASCADE ou RESTRICT ações na exclusão.
📊 Comparação dos Tipos de Relacionamento
Visualizar as diferenças entre os tipos de relacionamento ajuda na seleção da estratégia de modelagem correta. A tabela abaixo resume os requisitos estruturais e a complexidade de implementação.
| Tipo de Relacionamento | Implementação Física | Localização da Chave Primária | Complexidade |
|---|---|---|---|
| Um para Um (1:1) | Chave estrangeira em uma tabela | Qualquer tabela | Baixa |
| Um para Muitos (1:M) | Chave estrangeira na tabela “muitos” | Tabela principal | Média |
| Muitos para Muitos (M:N) | Tabela de junção separada | Tabela de junção (composta) | Alta |
Como mostrado, o relacionamento M:N exige a maior sobrecarga estrutural. No entanto, essa sobrecarga é necessária para a integridade dos dados. O custo de uma junção extra durante uma consulta é frequentemente superado pelo custo da inconsistência de dados em um esquema mal modelado.
🚀 Considerações de Desempenho
Introduzir uma tabela de junção adiciona uma camada de indireção às suas consultas. Ao recuperar dados, você deve unir três tabelas em vez de duas. Em sistemas de alta volume, isso pode afetar o desempenho se não for gerenciado corretamente.
- Indexação:Cada chave estrangeira na tabela de junção deve ser indexada. Isso permite que o motor do banco de dados localize rapidamente as linhas para uma entidade específica sem escanear toda a tabela de junção.
- Índices compostos:Em alguns casos, criar um índice na combinação de ambas as chaves estrangeiras é mais eficiente do que índices separados. Isso suporta consultas que filtram por ambas as entidades simultaneamente.
- Leitura versus escrita:As tabelas de junção geralmente são intensivas em escrita se as relações forem dinâmicas. Elas são intensivas em leitura ao gerar relatórios. Certifique-se de que sua estratégia de indexação suporte o padrão de operação dominante da sua aplicação.
⚠️ Armadilhas comuns e soluções
Mesmo modeladores experientes cometem erros ao resolver cardinalidades. O conhecimento dos erros comuns pode poupar um tempo significativo de reestruturação posterior.
1. O erro da “coluna única”
Tentar armazenar múltiplos IDs em uma única coluna usando valores separados por vírgulas (por exemplo, “1, 2, 3”). Isso viola os princípios de banco de dados e torna a consulta impossível sem funções de análise de strings. Sempre use uma linha separada para cada instância de relacionamento.
2. Atributos redundantes
Copiar atributos das entidades pais para a tabela de junção sem necessidade. Se um atributo pertence à entidade (por exemplo, o nome de um aluno), ele pertence à tabela de Aluno, e não à tabela de Matrícula. Coloque apenas dados que descrevam o próprio link.
3. Ignorar a nulidade
Definir chaves estrangeiras como nulas quando deveriam ser obrigatórias. Se uma relação é obrigatória (por exemplo, um Pedido deve ter um Cliente), a chave estrangeira não deve permitir valores nulos. Isso impõe regras de negócios ao nível do banco de dados.
4. Referências circulares
Criar uma tabela de junção que se refere a si mesma desnecessariamente. Certifique-se de que a tabela de junção ligue apenas as duas entidades distintas envolvidas na relação. Evite criar loops que não tenham uma finalidade funcional.
🎨 Melhores práticas para representação visual
Ao documentar seu ERD, a clareza é fundamental. A representação visual deve transmitir imediatamente a estrutura resolvida para qualquer pessoa que leia o diagrama.
- Rotule a tabela de junção:Nomeie a tabela de forma descritiva. Em vez de “Table3”, use “Student_Course_Enrollment”.
- Indique a cardinalidade:Marque claramente as linhas que conectam a tabela de junção às entidades pais. Use o símbolo de pé de corvo no lado da tabela de junção para mostrar a relação “muitos” do ponto de vista da entidade pai.
- Mostre os atributos:Se a tabela de junção tiver atributos (como “Nota” ou “Data”), liste-os explicitamente no diagrama. Isso destaca que a relação é mais do que apenas uma ligação.
- Use estilos de linha diferentes:Alguns ferramentas de modelagem permitem linhas tracejadas para relações opcionais e linhas sólidas para relações obrigatórias. A consistência aqui ajuda na compreensão.
🔄 Relações recursivas e M:N
Ocasionalmente, uma relação muitos para muitos existe dentro de uma única entidade. Por exemplo, um Funcionário pode gerenciar múltiplos outros Funcionários, e esses funcionários podem gerenciar outros. Trata-se de uma relação recursiva M:N.
A resolução permanece a mesma que em uma relação M:N padrão. Você ainda cria uma tabela de junção, mas ambas as chaves estrangeiras nessa tabela referenciam a chave primária da mesma entidade.
- Entidade: Funcionário
- Tabela de Junção: Gestão_Funcionários
- FK1: ID_Gerente (Referencia Funcionário)
- FK2: ID_Subordinado (Referencia Funcionário)
Essa estrutura permite hierarquias organizacionais complexas sem violar as regras de normalização. Permite consultas que percorrem múltiplos níveis de profundidade gerencial.
🛡️ Restrições de Dados e Regras de Negócio
Restrições técnicas não são suficientes; as regras de negócio devem ser aplicadas. Uma tabela de junção fornece um local natural para aplicar essas regras.
- Restrições Únicas: Garanta que uma relação específica não possa ser criada duas vezes, a menos que intencional. Por exemplo, um aluno não deveria estar matriculado na mesma turma de curso duas vezes no mesmo semestre. Uma restrição única na combinação de Student_ID e Course_ID impõe isso.
- Restrições de Verificação: Valide dados numéricos. Por exemplo, as “Horas_Alocadas” em uma tabela de junção de projetos devem ser maiores que zero e menores que 40.
- Gatilhos: Em sistemas complexos, podem ser necessários gatilhos para atualizar tabelas de resumo. Se a tabela de junção mudar, uma tabela de resumo na entidade pai (por exemplo, “Total_Projetos_Por_Funcionário”) pode precisar ser atualizada automaticamente.
📈 Evolução do Modelo
Modelos evoluem conforme os requisitos mudam. Uma relação que começa como muitos para muitos pode se simplificar para um para muitos se uma regra de negócio mudar. Por exemplo, se uma política mudar de forma que um aluno só possa se matricular em um curso por vez, a tabela de junção pode ser mesclada de volta na tabela de alunos.
No entanto, começar com a tabela de junção geralmente é mais seguro. Ela oferece a máxima flexibilidade. Se o requisito mudar posteriormente para permitir múltiplas matrículas, o esquema já estará preparado. Se você começar com uma tabela mesclada, precisará refatorar posteriormente.
📝 Resumo dos Pontos Principais
Resolver relações muitos para muitos é uma habilidade fundamental no design de bancos de dados. Exige a criação de uma estrutura intermediária para manter a integridade dos dados e suportar consultas eficientes. A tabela de junção é a solução padrão, dividindo associações complexas em links um para muitos gerenciáveis.
- Sempre resolva M:N: Nunca tente armazenar múltiplas chaves estrangeiras em uma única coluna.
- Use chaves compostas: A combinação de chaves estrangeiras geralmente serve como identificador único para a relação.
- Armazene dados de relacionamento:Coloque atributos específicos para a ligação na tabela de junção.
- Indexe chaves estrangeiras:O desempenho depende de consultas rápidas nas linhas da tabela de junção.
- Impor restrições:Use restrições únicas e referências de chave estrangeira para evitar dados inválidos.
Ao seguir estas técnicas, você garante que seu esquema de banco de dados seja resistente a mudanças e capaz de lidar com interações de dados complexas. O esforço investido na modelagem adequada na fase de design traz benefícios em manutenibilidade e desempenho ao longo de toda a vida útil do sistema.