











Construir uma infraestrutura de banco de dados robusta exige precisão em cada etapa do desenvolvimento. O Diagrama de Relacionamento de Entidades (ERD) serve como o projeto arquitetônico para essa estrutura. Ele define como as entidades de dados interagem, como as informações fluem e como a integridade é mantida ao longo de todo o ciclo de vida do sistema. Pular uma revisão minuciosa do ERD pode levar a refatorações custosas, corrupção de dados e gargalos de desempenho no futuro. Este guia fornece uma checklist detalhada e prática para validar seu esquema antes de comprometer-se com a implementação.
Arquitetos de bancos de dados e desenvolvedores devem abordar o design de esquemas com olhar crítico. O custo de corrigir um erro estrutural em produção é significativamente maior do que o esforço necessário para corrigi-lo na fase de design. Ao seguir um processo de revisão estruturado, as equipes garantem que o banco de dados resultante suporte a lógica de negócios, siga os princípios de normalização e permaneça escalável.
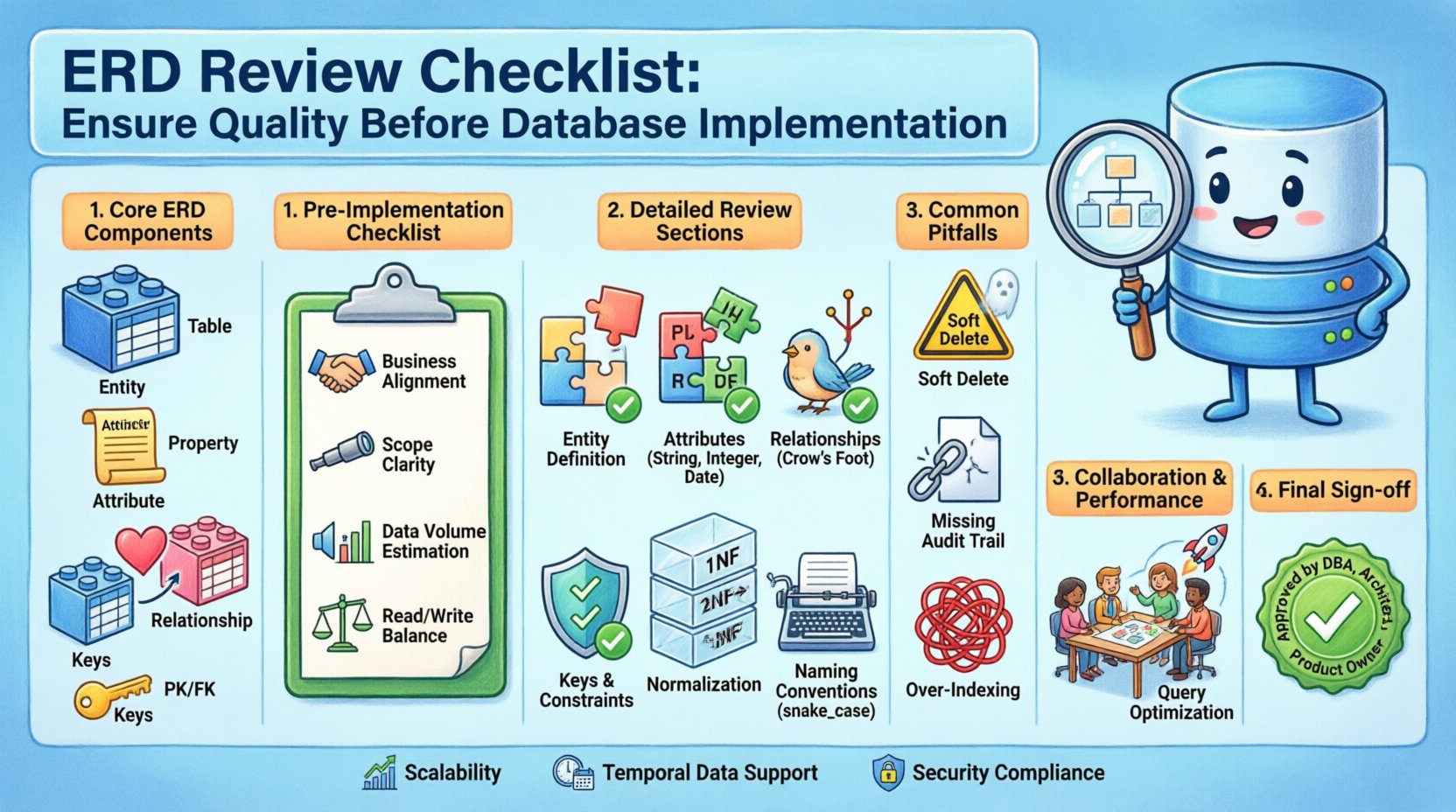
Compreendendo os Componentes Principais de um ERD 🔍
Antes de mergulhar na checklist, é essencial compreender os blocos fundamentais que compõem um Diagrama de Relacionamento de Entidades padrão. Esses componentes formam o vocabulário do seu modelo de dados.
- Entidades: Elas representam objetos ou conceitos do mundo real sobre os quais os dados são armazenados. Em um contexto relacional, entidades geralmente mapeiam para tabelas.
- Atributos: Elas descrevem as propriedades ou características de uma entidade. Elas mapeiam para colunas dentro de uma tabela.
- Relacionamentos: Elas definem as associações entre entidades. Elas indicam como os dados em uma tabela se conectam aos dados em outra.
- Cardinalidades e Chaves: A cardinalidade define a relação numérica entre entidades (por exemplo, um para um, muitos para muitos). As chaves garantem identificação única e conectividade.
Um ERD de alta qualidade deve expressar claramente esses elementos. A ambiguidade no diagrama se traduz diretamente em ambiguidade no código, levando a erros na implementação.
Etapas de Validação Pré-Implementação ✅
Antes de aplicar quaisquer itens específicos da checklist, o contexto geral do banco de dados deve estar alinhado com os requisitos de negócios. Esta fase garante que o modelo seja adequado ao propósito.
- Alinhamento com Requisitos de Negócio: Verifique se cada entidade e relacionamento mapeia para uma regra de negócios específica ou uma história de usuário.
- Definição do Escopo: Confirme os limites dos dados. Estamos projetando para uma única aplicação, um microserviço ou um armazém corporativo?
- Estimativa de Volume de Dados: Considere o volume esperado de registros. Isso influencia decisões sobre estratégias de indexação e particionamento.
- Proporção Leitura/Escrita: Compreenda o perfil de carga de trabalho. Uma aplicação com foco em leitura pode exigir desnormalização, enquanto um sistema com foco em escrita prioriza a integridade estrita.
Checklist Detalhada de Revisão de ERD 📝
Esta seção detalha os atributos técnicos específicos que exigem atenção. Use esta lista como ferramenta de verificação durante suas sessões de revisão de design.
1. Definição de Entidade e Tabela
Cada entidade no diagrama deve ser distinta e bem definida. Um erro comum é criar entidades sobrepostas que deveriam ser fundidas, ou dividir um único conceito em múltiplas tabelas desnecessariamente.
- Distinção: Garanta que cada tabela represente um conceito único. Evite tabelas que armazenem dados semelhantes para propósitos diferentes sem uma distinção clara.
- Granularidade: Verifique se as tabelas são muito granulares. A divisão excessiva pode levar a junções complexas e degradação de desempenho.
- Convenções de Nomeação:Verifique a consistência. As tabelas devem usar nomes no singular (por exemplo,
Clienteem vez deClientes) para alinhar com padrões de mapeamento orientados a objetos. - Metadados: Certifique-se de que os marcos de tempo de criação e modificação estejam incluídos em cada tabela para suportar auditoria e rastreamento da origem dos dados.
2. Atributos e Tipos de Dados
Atributos definem a natureza dos dados armazenados. Selecionar o tipo de dado correto é essencial para eficiência de armazenamento e desempenho de consultas.
- Tipos de Dados Principais: Certifique-se de que inteiros, strings e booleanos sejam usados corretamente. Evite usar strings para datas ou números.
- Restrições de Comprimento: Defina comprimentos máximos para campos de string. Isso evita o aumento excessivo de armazenamento e garante consistência durante a validação de entrada.
- Nulidade: Defina explicitamente se um campo pode ser nulo. A maioria dos campos não deve ser nula, a menos que a lógica de negócios permita.
- Valores Padrão: Verifique se valores padrão são necessários. Por exemplo, um campo de status pode ter como padrão ‘ativo’, em vez de exigir uma inserção inicial.
- Valores de Enumeração: Quando apropriado, use listas enumeradas para restringir valores. Isso evita a entrada de dados inválidos na fonte.
3. Relacionamentos e Cardinalidade
Relacionamentos são o que une o modelo de dados. Erros aqui levam a registros órfãos ou duplicação de dados.
| Tipo de Relacionamento | Descrição | Observação de Implementação |
|---|---|---|
| Um para Um (1:1) | Um registro na Tabela A está vinculado a exatamente um registro na Tabela B. | Normalmente implementado colocando a Chave Primária de A como Chave Estrangeira na B. |
| Um para Muitos (1:N) | Um registro na Tabela A está ligado a muitos registros na Tabela B. | Coloque a Chave Primária de A como Chave Estrangeira na B. |
| Muitos para Muitos (M:N) | Registros na A podem estar ligados a muitos na B, e vice-versa. | Requer uma tabela de junção que ligue as duas Chaves Primárias. |
- Verificação de Cardinalidade: Revise a notação em forma de bico de corvo ou equivalente para garantir que a direção da relação esteja correta.
- Opcionalidade: Distinga entre relacionamentos obrigatórios e opcionais. Uma restrição de chave estrangeira deve refletir se um registro relacionado deve existir.
- Relacionamentos Recursivos: Verifique tabelas que se referenciam a si mesmas (por exemplo, uma
Funcionáriotabela ligada a umGerenteID dentro da mesma tabela). - Dependências Circulares: Garanta que as relações não criem loops circulares que dificultem o carregamento ou consulta de dados.
4. Chaves e Restrições
Chaves são o mecanismo para unicidade e conexão. Sem chaves adequadas, a integridade dos dados colapsa.
- Chaves Primárias: Toda tabela deve ter uma Chave Primária. Ela deve ser única e nunca nula.
- Chaves de Substituição: Considere usar IDs gerados pelo sistema (chaves de substituição) em vez de chaves de negócio naturais. Isso evita que mudanças na lógica de negócios afetem a estrutura do banco de dados.
- Chaves Estrangeiras: Verifique se todas as chaves estrangeiras referenciam chaves primárias válidas nas tabelas pais.
- Restrições Únicas: Identifique campos que devem ser únicos (por exemplo, endereços de e-mail, números de conta) mas não são a chave primária.
- Restrições de Verificação: Procure regras lógicas que não possam ser impostas apenas pelos tipos de dados (por exemplo,
data_iniciodeve ser anterior adata_fim).
5. Normalização
A normalização reduz a redundância e melhora a integridade dos dados. Embora a sobre-normalização possa prejudicar o desempenho, a sub-normalização cria anomalias.
- Primeira Forma Normal (1FN): Garanta valores atômicos. Nenhum grupo repetido ou array dentro de uma única célula.
- Segunda Forma Normal (2FN): Garanta que todas as atribuições não-chave dependam totalmente da chave primária, e não apenas de parte dela.
- Terceira Forma Normal (3FN): Garanta que não haja dependências transitivas. Atribuições não-chave devem depender apenas da chave primária, e não de outras atribuições não-chave.
- Estratégia de Denormalização: Se o desempenho for uma preocupação, documente onde e por que a denormalização é aplicada. Isso deve ser uma decisão consciente, e não um esquecimento.
6. Convenções de Nomeação
A nomeação consistente reduz a carga cognitiva para os desenvolvedores e reduz a probabilidade de erros.
- Nomes de Tabelas: Use nomes no singular (por exemplo,
Pedido, e nãoPedidos). - Nomes de Colunas: Use snake_case para consistência (por exemplo,
criado_em). - Evite Palavras Reservadas: Garanta que nenhum nome de coluna entre em conflito com palavras-chave SQL (por exemplo,
usuário,ordem,grupo). - Clareza:Os nomes devem ser descritivos. Evite abreviações, a menos que sejam padrão na indústria.
Armadilhas Comuns para Evitar ⚠️
Mesmo designers experientes podem ignorar detalhes críticos. Estar ciente das armadilhas comuns ajuda a manter um esquema limpo.
- Ignorar exclusões suaves: Decida se os dados precisam ser excluídos permanentemente ou marcados logicamente como inativos. Um
is_deletedsinalizador geralmente é mais seguro do que a remoção física. - Faltam rastreamentos de auditoria: Certifique-se de que há um mecanismo para rastrear quem alterou os dados e quando. Isso é crucial para conformidade.
- Sobrecarga de índices:Adicionar muitos índices desacelera as operações de escrita. Revise os padrões de consulta para justificar a colocação dos índices.
- Valores codificados: Evite armazenar valores específicos, como códigos de país, como strings, se puderem ser mapeados para uma tabela de referência.
- Suposições Implícitas: Não assuma que um campo é opcional se a lógica de negócios o exigir. Documente as suposições com clareza.
Colaboração e Documentação 🤝
Um ERD não é apenas um artefato técnico; é uma ferramenta de comunicação. Deve ser compreendido por partes interessadas, e não apenas por administradores de banco de dados.
- Revisão por partes interessadas: Tenha analistas de negócios revisar o diagrama para confirmar que corresponde ao seu modelo mental do processo.
- Controle de Versão: Trate o ERD como código. Armazene-o em controle de versão para rastrear mudanças ao longo do tempo.
- Documentação: Inclua um dicionário de dados junto com o diagrama. Defina o significado de cada campo e sua faixa permitida.
- Gestão de Mudanças: Estabeleça um processo para modificar o esquema. As mudanças devem ser revisadas e aprovadas, e não aplicadas de forma espontânea.
Considerações de Desempenho 🚀
Embora o ERD seja lógico, ele deve atender a objetivos de desempenho físico. Algumas escolhas de design têm implicações diretas no desempenho.
- Complexidade de Junção:Minimize o número de junções necessárias para consultas comuns. Junções complexas podem sobrecarregar o otimizador de consultas.
- Prontidão para Particionamento: Projete tabelas levando em consideração o particionamento, caso o conjunto de dados seja esperado para crescer significativamente.
- Buscabilidade: Certifique-se de que os campos frequentemente pesquisados estejam indexados. Considere os requisitos de busca de texto completo para campos com grande volume de texto.
- Concorrência: Avalie estratégias de bloqueio. Ambientes com alta concorrência podem exigir níveis específicos de isolamento ou designs de tabela.
Critérios Finais de Aprovação 🏁
Antes de prosseguir com a implementação, o ERD deve atender a critérios específicos de aceitação. Isso garante uma transição suave do design para o desenvolvimento.
- Completude: Todas as entidades e relacionamentos exigidos pelo escopo estão presentes.
- Consistência: As convenções de nomeação e os tipos de dados são aplicados de forma uniforme.
- Integridade: As restrições de chave primária e estrangeira estão corretamente definidas.
- Clareza: O diagrama é legível e compreensível pela equipe de engenharia.
- Aprovação: Os principais interessados aprovaram o design.
Cumprir esta lista de verificação garante que a base de dados seja sólida. Isso reduz a dívida técnica e facilita ciclos de desenvolvimento mais suaves. Um ERD bem revisado é o primeiro passo rumo a uma arquitetura de dados resiliente.
Revisando o ERD para Escalabilidade Futura
Projetar para o presente é insuficiente. O modelo de dados deve acomodar o crescimento sem exigir uma reconstrução completa.
- Escalabilidade Horizontal: Considere como o shard pode afetar os relacionamentos. Chaves estrangeiras entre shards são complexas e frequentemente evitadas.
- Escalabilidade Vertical: Certifique-se de que os tipos de dados possam lidar com valores maiores. Por exemplo, usando
BIGINTem vez deINTpara contadores. - Bandeiras de Recursos: Projete tabelas para suportar bandeiras de recursos suaves. Isso permite que novas funcionalidades sejam ativadas ou desativadas sem alterações no esquema.
- Compatibilidade com Versões Anteriores: Planeje as migrações de esquema. A adição de colunas não deve quebrar consultas existentes.
Tratamento de Casos Especiais como Dados Temporais
O tempo é uma dimensão crítica no modelagem de dados. O tratamento correto do histórico é frequentemente negligenciado.
- Datas de Vigência: Para entidades que mudam ao longo do tempo, inclua datas de início e fim para rastrear o histórico.
- Fusos Horários: Armazene timestamps em UTC para evitar ambiguidade entre regiões.
- Instantâneos: Decida se instantâneos históricos são necessários. Isso pode exigir uma tabela de histórico separada.
- Tabelas Temporais: Algumas sistemas suportam tabelas temporais nativas. Avalie se isso se encaixa nas restrições arquitetônicas.
Segurança e Conformidade no Esquema
A segurança de dados começa no nível da tabela. A estrutura deve suportar requisitos de privacidade e proteção.
- Tratamento de Dados Pessoais (PII): Identifique campos de Informação Pessoalmente Identificável. Esses campos exigem criptografia ou mascaramento.
- Controle de Acesso: Projete papéis e permissões com base na sensibilidade dos dados definida no esquema.
- Criptografia em Repouso: Certifique-se de que o motor do banco de dados suporte criptografia para campos sensíveis.
- Políticas de Retenção: Defina campos que indicam quando os dados podem ser excluídos de acordo com requisitos legais.
Ao aplicar rigorosamente estas verificações, o banco de dados torna-se um ativo confiável, e não uma responsabilidade. O esforço investido na fase de revisão do ERD traz benefícios em manutenibilidade e desempenho.